
Potok wsadowy, moim zdaniem, nie zniknie. System nadal potrzebuje go do aplikacji analityki biznesowej i wizualizacji danych. Raporty te często wymagają przetwarzania znacznych ilości danych historycznych. Chociaż można rozważyć przetwarzanie iteracyjne, jest prawdopodobne, że wraz z postępem mocy obliczeniowej i algorytmów uczenia maszynowego zawsze będzie istniała potrzeba przebudowy modelu danych od podstaw.
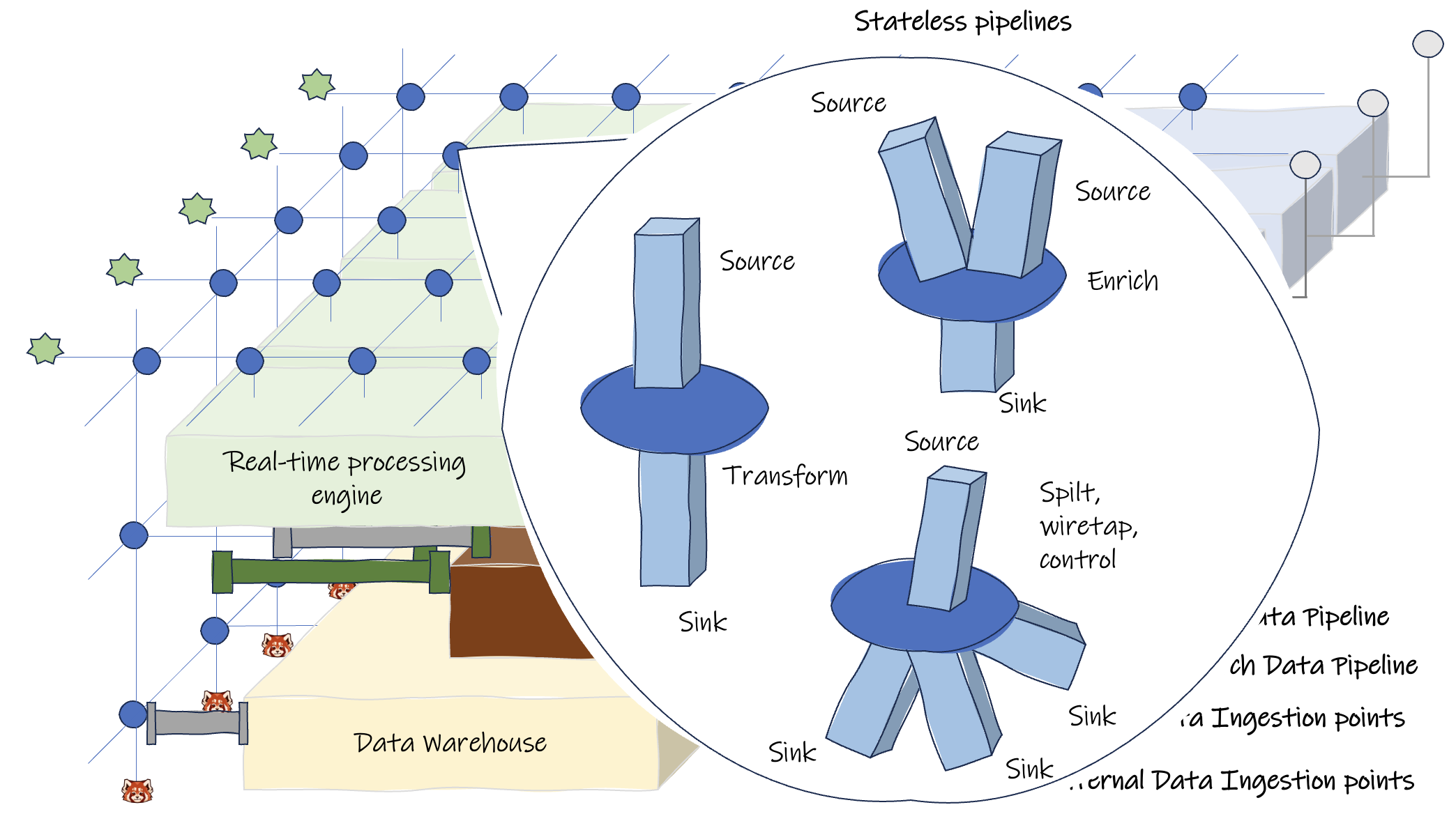
Takie podejście zapewni zwinność warstwy danych i pomoże rozwiązać wyzwania, które omówiliśmy w naszym artykule poprzedni post.
Trudności z dostępem do danych
- Inżynierowie danych mogą pobierać dane w czasie rzeczywistym, uzyskując dostęp do sieci strumieniowej i operacyjnej bazy danych.
- Posiadanie bardziej bezstanowego potoku, który zaspokaja specjalne wymagania dotyczące kształtu danych i może przetwarzać dane w miarę ich pojawiania się, wymaga mniej złożonego potoku.
- Maskowanie wrażliwych danych przed ich dystrybucją.
Hałaśliwe i brudne dane
- Weryfikacja danych pod kątem ich kształtu i kontekstu na bieżąco pozwala uniknąć przyszłych problemów.
- Kontrole duplikacji i niezgodności mogą być dystrybuowane do przetworzenia przed zapisaniem ich w hurtowni danych. Zapobiega to nieczystym danym.
Wydajność
- Wysoka przepustowość, niezawodność platforma streamingowa zdolna do szybkiego pobierania zdarzeń historycznych pozwala uniknąć przeciążenia potoku i wąskich gardeł procesu.
- Skalowanie za pomocą potoków bezstanowych i dystrybucja zadań w potokach stanowych może skalować się poziomo.
Rozwiązywanie problemów
- Dzięki modelowaniu i udostępnianiu danych z różnych strumieni, łatwiej jest wykrywać problemy poprzez monitorowanie i próbkowanie ich za pomocą alertów.
- Prostsze izolowanie problematycznych danych odnoszących się do potoków korzystających z tego samego punktu końcowego strumieniowania.
- Wstępnie oczyszczone dane przed ich wprowadzeniem do hurtowni danych.
Podsumowanie
Jeśli chodzi o generowanie zbiorów danych do uczenia modeli uczenia maszynowego, dane strumieniowe lepiej nadają się do ciągłego uczenia i testowania. Jednak przygotowanie zestawów danych do uczenia modeli ML z różnych typów magazynów danych, które zostały wprowadzone na przestrzeni lat, może stanowić wyzwanie. Wdrożenie sprawdzonej strategii dotyczącej danych może usprawnić kłopotliwe potoki danych w celu pozyskiwania danych w czasie rzeczywistym, wydajnego przetwarzania i płynnej integracji różnych systemów.
Następnie przeprowadzę Państwa przez przypadek użycia, w którym wdrażamy te strategie danych, aby wykorzystać generatywną sztuczną inteligencję do roszczenia ubezpieczeniowego. Wykorzystamy również Redpanda jako naszą platformę danych strumieniowych – prostszą, bardziej wydajną i opłacalną alternatywę dla Kafki. Ten przypadek użycia zostanie ładnie zapakowany w bezpłatny raport do pobrania (już wkrótce!), więc proszę zapisać się do naszego newslettera, aby dowiedzieć się o nim jako pierwszy.
W międzyczasie, jeśli mają Państwo pytania dotyczące tego tematu lub potrzebują wsparcia w rozpoczęciu pracy z Redpanda dla własnego przypadku użycia AI, mogą Państwo porozmawiać ze mną na czacie w sekcji Społeczność Redpanda na Slacku.