
Kolumna auto-increment jest podstawową funkcją jednowęzłowych transakcyjnych baz danych. Przypisuje ona unikalny identyfikator dla każdego wiersza w sposób, który wymaga najmniejszego ręcznego wysiłku ze strony użytkowników. Dzięki kolumnie automatycznego zwiększania w tabeli, za każdym razem, gdy do tabeli zostanie wstawiony nowy wiersz, zostanie mu przypisana następna dostępna wartość z sekwencji automatycznego zwiększania. Jest to zautomatyzowany mechanizm, który sprawia, że utrzymanie bazy danych jest łatwe i niezawodne.
Kolumna auto-increment jest podstawą wielu funkcji w bazach danych:
- Kodowanie słownika: Identyfikatory użytkowników i zamówień są często przechowywane jako ciągi znaków. Jednak ciągi nie są przyjazne dla precyzyjnego wykonywania zapytań deduplikacji. Aby uzyskać optymalną wydajność, powszechną praktyką jest kodowanie słownikowe ciągów, a następnie tworzenie mapy bitowej dla operacji agregacji. Rola kolumny autoinkrementacji w tym procesie polega na tym, że przyspiesza kodowanie słownikowe, a tym samym przyspiesza deduplikację ciągów znaków.
- Generowanie klucza głównego: Kolumna z autouzupełnianiem jest idealnym kandydatem na klucz podstawowy tabeli. Klucze podstawowe muszą być unikalne i niepuste, podczas gdy kolumny autoinkrementacji gwarantują unikalny identyfikator dla każdego wiersza.
- Szczegółowe aktualizacje danych: Aktualizacja tabel szczegółowych jest trudna, ale może być łatwa, jeśli doda się do niej tabelę z automatycznym zwiększaniem. Daje to każdemu rekordowi danych w bazie danych unikalny identyfikator, który może działać jako klucz podstawowy, a następnie aktualizacje danych mogą być wykonywane na podstawie klucza podstawowego.
- Wydajna paginacja: Paginacja jest często wymagana przy wyświetlaniu danych. Jest ona zazwyczaj implementowana przez
limitluboffset+order byw zapytaniach SQL. Jednak taka implementacja wymaga pełnego odczytu danych i sortowania, co nie ma większego sensu w zapytaniach z głęboką paginacją (tych z dużymi przesunięciami). W tym momencie z pomocą przychodzą kolumny auto-increment. Jak już wspomniałem, nadaje ona unikalny identyfikator każdemu wierszowi, więc maksymalny identyfikator ostatniej strony może być użyty jako warunek filtrowania dla następnej strony. W ten sposób można uniknąć wielu niepotrzebnych operacji skanowania danych i zwiększyć wydajność paginacji.
Pomysł automatycznego zwiększania kolumn jest intuicyjny, ale jeśli chodzi o rozproszone bazy danych, staje się inną grą, ponieważ musi uwzględniać transakcje globalne. Jako rozproszony DBMS, Apache Doris zapewnia innowacyjne i wydajne rozwiązanie automatycznego zwiększania, które nie szkodzi wydajności zapisu danych.
Składnia i użycie
Aby włączyć automatyczne zwiększanie kolumny w Doris, proszę dodać AUTO_INCREMENT do kolumny w instrukcji tworzenia tabeli (CREAT TABLE). Mogą Państwo określić wartość początkową dla kolumny autoinkrementacji poprzez AUTO_INCREMENT(start_value); jeśli nie, domyślną wartością początkową jest 1.
Na przykład, można utworzyć tabelę w folderze Duplicate Key model, w którym jedna z kolumn klucza jest kolumną z automatycznym zwiększaniem.
CREATE TABLE `demo`.`tbl` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`value` BIGINT NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);Oprócz kolumny klucza można również określić kolumnę wartości jako kolumnę automatycznego zwiększania wartości (przykład poniżej):
CREATE TABLE `demo`.`tbl` (
`uid` BIGINT NOT NULL,
`name` BIGINT NOT NULL,
`id` BIGINT NOT NULL AUTO_INCREMENT,
`value` BIGINT NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`uid`, `name`)
DISTRIBUTED BY HASH(`uid`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);AUTO_INCREMENT jest obsługiwana zarówno w modelu Duplicate Key, jak i w modelu Unique Key model. Użycie w tym ostatnim jest podobne.
Przeprowadzę Państwa przez resztę drogi na przykładzie poniższej tabeli:
CREATE TABLE `demo`.`tbl` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`name` varchar(65533) NOT NULL,
`value` int(11) NOT NULL
) ENGINE=OLAP
UNIQUE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);Po wprowadzeniu danych do tej tabeli przy użyciu pliku insert into oświadczenia, jeśli id nie ma określonej wartości w oryginalnym pliku danych, zostanie ona automatycznie wypełniona wartościami autouzupełniania.
mysql> insert into tbl(name, value) values("Bob", 10), ("Alice", 20), ("Jack", 30);
Query OK, 3 rows affected (0.09 sec)
{'label':'label_183babcb84ad4023_a2d6266ab73fb5aa', 'status':'VISIBLE', 'txnId':'7'}
mysql> select * from tbl order by id;
+------+-------+-------+
| id | name | value |
+------+-------+-------+
| 1 | Bob | 10 |
| 2 | Alice | 20 |
| 3 | Jack | 30 |
+------+-------+-------+
3 rows in set (0.05 sec)Podobnie, podczas pozyskiwania pliku danych test.csv przez Stream Load, plik id kolumna zostanie również automatycznie wypełniona automatycznie zwiększanymi wartościami.
test.csv:
Tom,40
John,50
curl --location-trusted -u user:passwd -H "columns:name,value" -H "column_separator:," -T ./test.csv http://{host}:{port}/api/{db}/tbl/_stream_load
select * from tbl order by id;
+------+-------+-------+
| id | name | value |
+------+-------+-------+
| 1 | Bob | 10 |
| 2 | Alice | 20 |
| 3 | Jack | 30 |
| 4 | Tom | 40 |
| 5 | John | 50 |
+------+-------+-------+
5 rows in set (0.04 sec)Obowiązujące scenariusze
1. Kodowanie słownika
W Apache Doris typ danych bitmapy i agregacje związane z bitmapą są implementowane za pomocą RoaringBitmap, co może zapewnić wysoką wydajność, zwłaszcza gdy kodowanie słownika generuje gęste wartości.
Jak wspomniano, kolumny z automatycznym zwiększaniem umożliwiają szybkie kodowanie słownika. Umieszczę Państwa w kontekście profilowania użytkownika, aby pokazać, jak to działa.
W celu analizy odsłon offline (PV) i unikalnych odwiedzających (UV), proszę przechowywać szczegóły w tabeli zachowań użytkowników:
CREATE TABLE `demo`.`dwd_dup_tbl` (
`user_id` varchar(50) NOT NULL,
`dim1` varchar(50) NOT NULL,
`dim2` varchar(50) NOT NULL,
`dim3` varchar(50) NOT NULL,
`dim4` varchar(50) NOT NULL,
`dim5` varchar(50) NOT NULL,
`visit_time` DATE NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`user_id`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 32
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);Proszę utworzyć tabelę słownikową w następujący sposób AUTO_INCREMENT:
CREATE TABLE `demo`.`dictionary_tbl` (
`user_id` varchar(50) NOT NULL,
`aid` BIGINT NOT NULL AUTO_INCREMENT
) ENGINE=OLAP
UNIQUE KEY(`user_id`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 32
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);Proszę załadować istniejące user_id do tabeli słownika i utworzyć mapowania z user_id na wartości całkowite.
insert into dictionary_tbl(user_id)
select user_id from dwd_dup_tbl group by user_id;Jeśli potrzebują Państwo załadować tylko przyrostowe user_id do tabeli słownika, można użyć następującego polecenia. W praktyce można również użyć polecenia Flink Doris Connector do zapisu danych.
insert into dictionary_tbl(user_id)
select dwd_dup_tbl.user_id from dwd_dup_tbl left join dictionary_tbl
on dwd_dup_tbl.user_id = dictionary_tbl.user_id where dwd_dup_tbl.visit_time '2023-12-10' and dictionary_tbl.user_id is NULL;Załóżmy, że mają Państwo wymiary analityczne jako dim1, dim3, dim5proszę utworzyć tabelę w Aggregate Key model w celu uwzględnienia wyników agregacji danych:
CREATE TABLE `demo`.`dws_agg_tbl` (
`dim1` varchar(50) NOT NULL,
`dim3` varchar(50) NOT NULL,
`dim5` varchar(50) NOT NULL,
`user_id_bitmap` BITMAP BITMAP_UNION NOT NULL,
`pv` BIGINT SUM NOT NULL
) ENGINE=OLAP
AGGREGATE KEY(`dim1`,`dim3`,`dim5`)
DISTRIBUTED BY HASH(`dim1`) BUCKETS 32
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);Proszę załadować zagregowane wyniki do tabeli:
insert into dws_agg_tbl
select dwd_dup_tbl.dim1, dwd_dup_tbl.dim3, dwd_dup_tbl.dim5, BITMAP_UNION(TO_BITMAP(dictionary_tbl.aid)), COUNT(1)
from dwd_dup_tbl INNER JOIN dictionary_tbl on dwd_dup_tbl.user_id = dictionary_tbl.user_id
group by dwd_dup_tbl.dim1, dwd_dup_tbl.dim3, dwd_dup_tbl.dim5;Następnie proszę wysłać zapytanie PV/UV za pomocą następującej instrukcji:
select dim1, dim3, dim5, bitmap_count(user_id_bitmap) as uv, pv from dws_agg_tbl;2. Szczegółowe aktualizacje danych
W Doris model Unique Key ma zastosowanie do przypadków użycia z częstymi aktualizacjami danych, podczas gdy model Duplicate Key jest przeznaczony do szczegółowego przechowywania danych bez wymagań dotyczących aktualizacji danych.
Jednak w rzeczywistości użytkownicy mogą czasami potrzebować zaktualizować swoje szczegółowe dane, co może być trudne do wdrożenia, ponieważ tabele danych nie mają unikalnych kolumn kluczy.
W takim przypadku mogą Państwo użyć kolumny z automatycznym zwiększaniem jako klucza głównego dla danych szczegółowych.
Na przykład instytucja finansowa prowadzi rejestr pożyczek klientów i zapisuje go w tabeli Duplicate Key, w której jeden użytkownik może mieć wiele rekordów pożyczek.
CREATE TABLE loan_records (
`user_id` VARCHAR(20) DEFAULT NULL COMMENT 'Customer ID',
`loan_amount` DECIMAL(10, 2) DEFAULT NULL COMMENT 'Amount of loan',
`interest_rate` DECIMAL(10, 2) DEFAULT NULL COMMENT 'Interest rate',
`loan_start_date` DATE DEFAULT NULL COMMENT 'Start date of the loan',
`loan_end_date` DATE DEFAULT NULL COMMENT 'End date of the loan',
`total_debt` DECIMAL(10, 2) DEFAULT NULL COMMENT 'Amount of debt'
) DUPLICATE KEY(`user_id`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);Załóżmy, że w ramach kampanii promocyjnej instytucja oferuje 10% zniżki na oprocentowanie dla swoich obecnych klientów. W związku z tym istnieje potrzeba aktualizacji tabeli interest_rate oraz total_debt w tabeli.
W tym celu można utworzyć tabelę unikalnego klucza dla tych samych danych, ale dodając do niej atrybut auto_id i ustawić je jako klucz podstawowy.
CREATE TABLE loan_records (
`auto_id` BIGINT NOT NULL AUTO_INCREMENT,
`user_id` VARCHAR(20) DEFAULT NULL COMMENT 'Customer ID',
`loan_amount` DECIMAL(10, 2) DEFAULT NULL COMMENT 'Amount of loan',
`interest_rate` DECIMAL(10, 2) DEFAULT NULL COMMENT 'Interest rate',
`loan_start_date` DATE DEFAULT NULL COMMENT 'Start date of the loan',
`loan_end_date` DATE DEFAULT NULL COMMENT 'End date of the loan',
`total_debt` DECIMAL(10, 2) DEFAULT NULL COMMENT 'Amount of debt'
) UNIQUE KEY(`auto_id`)
DISTRIBUTED BY HASH(`auto_id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);Teraz proszę wpisać kilka nowych rekordów do tabeli i zobaczyć, co się stanie. (Proszę zauważyć, że nie trzeba zapisywać w polu auto_id ).
INSERT INTO loan_records (user_id, loan_amount, interest_rate, loan_start_date, loan_end_date, total_debt) VALUES
('10001', 5000.00, 5.00, '2024-03-01', '2024-03-31', 5020.55),
('10002', 10000.00, 5.00, '2024-03-01', '2024-05-01', 10082.56),
('10003', 2000.00, 5.00, '2024-03-01', '2024-03-15', 2003.84),
('10004', 7500.00, 5.00, '2024-03-01', '2024-04-15', 7546.23),
('10005', 3000.00, 5.00, '2024-03-01', '2024-03-21', 3008.22),
('10002', 8000.00, 5.00, '2024-03-01', '2024-06-01', 8100.82),
('10007', 6000.00, 5.00, '2024-03-01', '2024-04-10', 6032.88),
('10008', 4000.00, 5.00, '2024-03-01', '2024-03-26', 4013.70),
('10001', 5500.00, 5.00, '2024-03-01', '2024-04-05', 5526.37),
('10010', 9000.00, 5.00, '2024-03-01', '2024-05-10', 9086.30);Proszę sprawdzić na stronie select * from loan_records i można zobaczyć, że unikalny identyfikator jest już wprowadzony dla każdego nowo nadanego rekordu:
mysql> select * from loan_records;
+---------+---------+-------------+---------------+-----------------+---------------+------------+
| auto_id | user_id | loan_amount | interest_rate | loan_start_date | loan_end_date | total_debt |
+---------+---------+-------------+---------------+-----------------+---------------+------------+
| 1 | 10001 | 5000.00 | 5.00 | 2024-03-01 | 2024-03-31 | 5020.55 |
| 4 | 10004 | 7500.00 | 5.00 | 2024-03-01 | 2024-04-15 | 7546.23 |
| 2 | 10002 | 10000.00 | 5.00 | 2024-03-01 | 2024-05-01 | 10082.56 |
| 3 | 10003 | 2000.00 | 5.00 | 2024-03-01 | 2024-03-15 | 2003.84 |
| 6 | 10002 | 8000.00 | 5.00 | 2024-03-01 | 2024-06-01 | 8100.82 |
| 8 | 10008 | 4000.00 | 5.00 | 2024-03-01 | 2024-03-26 | 4013.70 |
| 7 | 10007 | 6000.00 | 5.00 | 2024-03-01 | 2024-04-10 | 6032.88 |
| 9 | 10001 | 5500.00 | 5.00 | 2024-03-01 | 2024-04-05 | 5526.37 |
| 5 | 10005 | 3000.00 | 5.00 | 2024-03-01 | 2024-03-21 | 3008.22 |
| 10 | 10010 | 9000.00 | 5.00 | 2024-03-01 | 2024-05-10 | 9086.30 |
+---------+---------+-------------+---------------+-----------------+---------------+------------+
10 rows in set (0.01 sec)Proszę wykonać te dwie instrukcje SQL, aby zaktualizować interest_rate i total_debt, odpowiednio:
update loan_records set interest_rate = interest_rate * 0.9 where user_id <= 10005;
update loan_records set total_debt = loan_amount + (loan_amount * (interest_rate / 100) * DATEDIFF(loan_end_date, loan_start_date) / 365);Proszę ponownie sprawdzić, czy stare rekordy zostały zastąpione nowymi:
mysql> select * from loan_records order by auto_id;
+---------+---------+-------------+---------------+-----------------+---------------+------------+
| auto_id | user_id | loan_amount | interest_rate | loan_start_date | loan_end_date | total_debt |
+---------+---------+-------------+---------------+-----------------+---------------+------------+
| 1 | 10001 | 5000.00 | 4.50 | 2024-03-01 | 2024-03-31 | 5018.49 |
| 2 | 10002 | 10000.00 | 4.50 | 2024-03-01 | 2024-05-01 | 10075.21 |
| 3 | 10003 | 2000.00 | 4.50 | 2024-03-01 | 2024-03-15 | 2003.45 |
| 4 | 10004 | 7500.00 | 4.50 | 2024-03-01 | 2024-04-15 | 7541.61 |
| 5 | 10005 | 3000.00 | 4.50 | 2024-03-01 | 2024-03-21 | 3007.40 |
| 6 | 10002 | 8000.00 | 4.50 | 2024-03-01 | 2024-06-01 | 8090.74 |
| 7 | 10007 | 6000.00 | 5.00 | 2024-03-01 | 2024-04-10 | 6032.88 |
| 8 | 10008 | 4000.00 | 5.00 | 2024-03-01 | 2024-03-26 | 4013.70 |
| 9 | 10001 | 5500.00 | 4.50 | 2024-03-01 | 2024-04-05 | 5523.73 |
| 10 | 10010 | 9000.00 | 5.00 | 2024-03-01 | 2024-05-10 | 9086.30 |
+---------+---------+-------------+---------------+-----------------+---------------+------------+
10 rows in set (0.01 sec)3. Wydajna paginacja
Proszę sobie wyobrazić, że trzeba posortować dane w określonej kolejności, a następnie pobrać rekord nr 90 001 do rekordu nr 90 010. Oznacza to, że mają Państwo duże przesunięcie wynoszące 90 000. Nazywamy to zapytaniem z głęboką paginacją. Nawet jeśli wymaga Pan tylko zestawu wyników składającego się z 10 wierszy, system bazy danych nadal musi odczytać cały zestaw danych do pamięci i wykonać pełne sortowanie.
Aby uzyskać wyższą wydajność wykonywania zapytań z głęboką paginacją, można wykorzystać moc automatycznego zwiększania kolumn. Główną ideą jest zapisanie max_value z unique_value na poprzedniej stronie i proszę przesunąć predykaty w dół o where unique_value > max_value limit rows_per_page.
Na przykład podczas tworzenia tabeli włącza Pan kolumnę automatycznego zwiększania: unique_value, która nadaje każdemu wierszowi identyfikator.
CREATE TABLE `demo`.`records_tbl` (
`user_id` int(11) NOT NULL COMMENT "",
`name` varchar(26) NOT NULL COMMENT "",
`address` varchar(41) NOT NULL COMMENT "",
`city` varchar(11) NOT NULL COMMENT "",
`nation` varchar(16) NOT NULL COMMENT "",
`region` varchar(13) NOT NULL COMMENT "",
`phone` varchar(16) NOT NULL COMMENT "",
`mktsegment` varchar(11) NOT NULL COMMENT "",
`unique_value` BIGINT NOT NULL AUTO_INCREMENT
) DUPLICATE KEY (`user_id`, `name`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);W zapytaniach z paginacją, załóżmy, że każda strona wyświetla 100 wyników, w ten sposób można pobrać pierwszą stronę zestawu wyników.
select * from records_tbl order by unique_value limit 100;Proszę używać programów do rejestrowania maksymalnej unique_value w zwróconym wyniku. Załóżmy, że maksimum wynosi 99, można zapytać o dane z drugiej strony za pomocą następującej instrukcji:
select * from records_tbl where unique_value > 99 order by unique_value limit 100;Jeśli trzeba zapytać o dane z głębszej strony, na przykład strony 101, co oznacza, że trudno jest uzyskać maksimum unique_value bezpośrednio z poprzedniej strony, można użyć następującej instrukcji:
select user_id, name, address, city, nation, region, phone, mktsegment
from records_tbl, (select unique_value as max_value from records_tbl order by unique_value limit 1 offset 9999) as previous_data
where records_tbl.unique_value > previous_data.max_value
order by unique_value limit 100;Implementacja
Typowe bazy danych OLTP wykonują przyrostowe dopasowywanie identyfikatorów za pomocą mechanizmów transakcyjnych. Jednak w rozproszonym systemie baz danych opartym na MPP, takim jak Apache Doris, takie podejście może łatwo zadusić wydajność zapisu danych.
Dlatego Apache Doris 2.1 wprowadza innowacyjną implementację automatycznego zwiększania identyfikatorów. W zadaniu pozyskiwania danych, jeden z węzłów backendu (BE) będzie działał jako koordynator, który jest odpowiedzialny za alokację identyfikatorów auto-increment. Koordynator BE żąda zbiorczo zakresu identyfikatorów od front-endu (FE). FE upewnia się, że zakresy ID przydzielone każdemu BE nie pokrywają się, gwarantując w ten sposób unikalność ID.
Proces ten ilustruje poniższy rysunek. StreamLoad1 ma BE1 jako koordynatora. BE1 żąda partii identyfikatorów (zakres: 1-1000) od FE i buforuje je lokalnie. Po przydzieleniu wszystkich 1000 identyfikatorów BE1 zażąda nowej partii od FE. W tym samym czasie StreamLoad 2 wybiera BE3 jako koordynatora, a BE3 również żąda identyfikatorów z FE. Ponieważ identyfikatory 1-1000 zostały już przydzielone do BE1, FE przypisuje identyfikatory 1001-2000 do BE3.
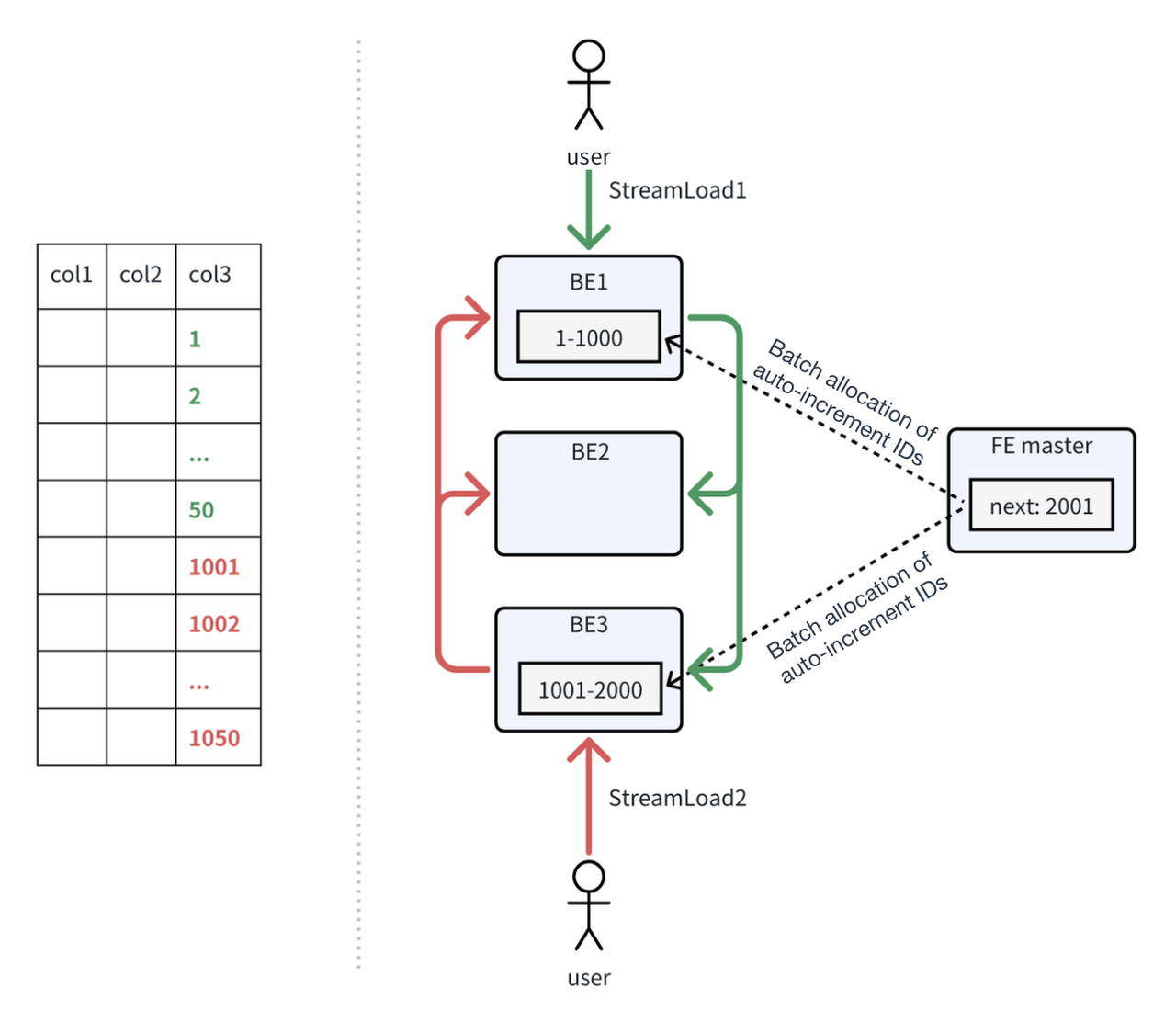
Załóżmy, że StreamLoad1 i StreamLoad2 zapisują po 50 nowych rekordów danych, a przypisane im identyfikatory automatycznego zwiększania będą miały wartości 1-50 i 1001-1050.
Załóżmy, że StreamLoad3 pojawi się później i wybierze BE1 jako koordynatora, BE1 przypisze identyfikatory zaczynające się od 51 do danych zapisanych przez StreamLoad3. Z punktu widzenia użytkownika, wiersze zapisane przez StreamLoad3 otrzymają mniejsze numery ID niż te zapisane przez StreamLoad2, mimo że StreamLoad2 poprzedza StreamLoad3 w czasie.
Proszę zauważyć
Proszę zwrócić uwagę na:
- Zakres gwarancji unikalności: Doris zapewnia, że wartości generowane w kolumnie autouzupełniania są unikalne w obrębie tabeli, ale dotyczy to tylko wartości automatycznie wypełnianych przez Doris. Jeśli użytkownik jawnie wstawi wartości do kolumny autouzupełniania, Doris nie może zagwarantować unikalności tych wartości.
- Gęstość i ciągłość wartości: Doris zapewnia, że wartości generowane przez kolumnę automatycznego zwiększania są gęste. Jednak ze względu na wydajność nie może zagwarantować, że automatycznie wypełniane wartości są ciągłe. Oznacza to, że w kolumnie autouzupełniania mogą wystąpić skoki wartości. Dodatkowo, ponieważ wartości autouzupełniania są wstępnie przydzielane i buforowane w BE, wielkość wartości autouzupełniania nie może odzwierciedlać kolejności importu danych.
Wnioski
AUTO_INCREMENT zapewnia większą stabilność i niezawodność Doris w przetwarzaniu danych na dużą skalę. Jeśli brzmi to jak coś, czego Państwo potrzebują, proszę pobrać Apache Doris i proszę ją wypróbować. W przypadku problemów, które napotkają Państwo po drodze, proszę dołączyć do nas w sekcji Społeczność programistów i użytkowników Apache Doris i chętnie Państwu pomożemy.