
Gdy dane są analizowane i przetwarzane w czasie rzeczywistym, mogą przynieść wgląd i przydatne informacje natychmiast lub z bardzo niewielkim opóźnieniem od momentu ich zebrania. Zdolność do gromadzenia, obsługi i przechowywania danych generowanych przez użytkowników w czasie rzeczywistym ma kluczowe znaczenie dla wielu aplikacji w dzisiejszym środowisku opartym na danych.
Istnieją różne sposoby na podkreślenie znaczenia analizy danych w czasie rzeczywistym, takie jak podejmowanie decyzji w odpowiednim czasie, przetwarzanie danych IoT i czujników, poprawa obsługi klienta, proaktywne rozwiązywanie problemów, wykrywanie oszustw i bezpieczeństwo itp. Wychodząc naprzeciw wymaganiom różnorodnych scenariuszy przetwarzania danych w czasie rzeczywistym, Apache Kafka ugruntował swoją pozycję jako niezawodna i skalowalna platforma strumieniowania zdarzeń.
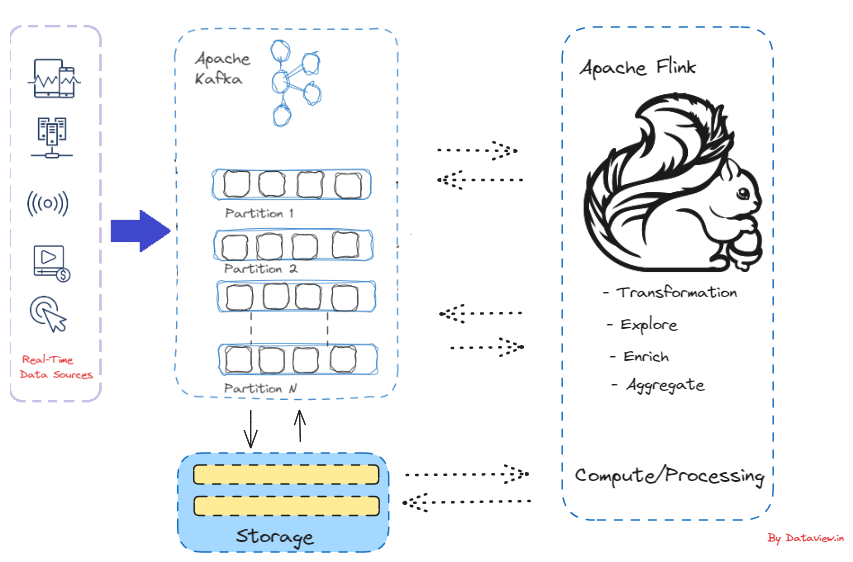
W skrócie, proces gromadzenia danych w czasie rzeczywistym jako strumieni zdarzeń ze źródeł zdarzeń, takich jak bazy danych, czujniki i aplikacje programowe, znany jest jako strumieniowanie zdarzeń. Z myślą o przetwarzaniu i analizie danych w czasie rzeczywistym, Apache Flink jest potężnym programem typu open source. Oferuje on spójną i skuteczną platformę do zarządzania ciągłymi strumieniami danych w sytuacjach, w których kluczowe znaczenie ma szybki wgląd i minimalne opóźnienie przetwarzania.
Przyczyny lepszej współpracy między Apache Flink i Kafka
- Apache Flink dołączył do Inkubatora Apache w 2014 roku i od momentu jego powstania, Apache Kafka konsekwentnie wyróżnia się jako jeden z najczęściej używanych konektorów dla Apache Flink. Jest to tylko silnik przetwarzania danych, który może być połączony z logiką przetwarzania, ale nie zapewnia żadnego mechanizmu przechowywania danych. Ponieważ Kafka zapewnia podstawową warstwę do przechowywania danych strumieniowych, Flink może służyć jako warstwa obliczeniowa dla Kafki, zasilając aplikacje i potoki czasu rzeczywistego.
- Apache Flink od lat zapewnia pierwszorzędne wsparcie dla tworzenia aplikacji opartych na Kafce. Wykorzystując liczne usługi i zasoby oferowane przez ekosystem Kafka, aplikacje Flink są w stanie wykorzystać Kafkę zarówno jako źródło, jak i zlew. Avro, JSON i Protobuf to tylko kilka powszechnie używanych formatów, które Flink obsługuje natywnie.
- Apache Kafka okazała się szczególnie odpowiednia dla Apache Flink. W przeciwieństwie do alternatywnych systemów, takich jak ActiveMQ, RabbitMQ itp., Kafka oferuje możliwość trwałego przechowywania strumieni danych w nieskończoność, umożliwiając konsumentom równoległe odczytywanie strumieni i odtwarzanie ich w razie potrzeby. Jest to zgodne z modelem przetwarzania rozproszonego Flink i spełnia kluczowy wymóg mechanizmu odporności na błędy Flink.
- Kafka może być używana przez aplikacje Flink zarówno jako źródło, jak i zlew, wykorzystując wiele narzędzi i usług dostępnych w ekosystemie Kafka. Flink oferuje natywną obsługę powszechnie używanych formatów, takich jak Avro, JSON i Protobuf, podobnie jak Kafka.
- Inne zewnętrzne systemy mogą być połączone z API tabel Flink i programami SQL w celu odczytu i zapisu tabel wsadowych i strumieniowych. Dostęp do danych przechowywanych w systemach zewnętrznych, takich jak system plików, baza danych, kolejka komunikatów lub magazyn klucz-wartość, jest możliwy dzięki źródłu tabeli. W przypadku Kafki jest to nic innego jak para klucz-wartość. Zdarzenia są dodawane do tabeli Flink w podobny sposób, w jaki są dołączane do tematu Kafka. Temat w klastrze Kafka jest mapowany na tabelę we Flink. We Flink każda tabela jest równa strumieniowi zdarzeń, które opisują modyfikacje dokonywane w tej konkretnej tabeli. Tabela jest automatycznie aktualizowana, gdy odwołuje się do niej zapytanie, a jej wyniki są materializowane lub emitowane.
Wnioski
Podsumowując, dzięki połączeniu Apache Flink i Apache Kafka możemy tworzyć niezawodne, skalowalne potoki przetwarzania danych w czasie rzeczywistym o niskim opóźnieniu, z odpornością na błędy i gwarancjami przetwarzania dokładnie raz. Dla firm, które chcą natychmiast ocenić i uzyskać wgląd w dane strumieniowe, ta kombinacja stanowi potężną opcję.
Dziękujemy Państwu za przeczytanie tego artykułu. Jeśli uważasz, że ta treść jest wartościowa, proszę rozważyć polubienie i udostępnienie.