
Generatywna sztuczna inteligencja (GenAI) umożliwia zaawansowane przypadki użycia sztucznej inteligencji i innowacje, ale także zmienia wygląd architektury korporacyjnej. Duże modele językowe (LLM), wektorowe bazy danych i generowanie rozszerzonego wyszukiwania (RAG) wymagają nowych wzorców integracji danych i najlepszych praktyk inżynierii danych. Strumieniowe przesyłanie danych za pomocą Apache Kafka i Apache Flink jest kluczem do pozyskiwania i zarządzania przychodzącymi zestawami danych w czasie rzeczywistym na dużą skalę, łączenia różnych baz danych i platform analitycznych oraz oddzielania niezależnych jednostek biznesowych i produktów danych. W tym wpisie na blogu omówiono możliwe architektury, przykłady i kompromisy między strumieniowaniem zdarzeń a tradycyjnymi interfejsami API typu żądanie-odpowiedź i bazami danych.

Przypadki użycia dla Apache Kafka i GenAI
Generatywna sztuczna inteligencja (GenAI) to silnik sztucznej inteligencji nowej generacji do przetwarzania języka naturalnego (NLP), generowania obrazów, optymalizacji kodu i innych zadań. Pomaga w wielu projektach w świecie rzeczywistym w zakresie automatyzacji usług, konwersacji z klientem za pomocą chatbota, moderowania treści w sieciach społecznościowych i wielu innych przypadkach użycia.
Apache Kafka stała się dominującą warstwą orkiestracji w tych platformach uczenia maszynowego do integracji różnych źródeł danych, przetwarzania na dużą skalę i wnioskowania o modelach w czasie rzeczywistym.
Strumieniowe przesyłanie danych za pomocą Kafki zasila już wiele infrastruktur i oprogramowania GenAI. Możliwe są bardzo różne scenariusze:
- Strumieniowanie danych jako struktura danych dla całej infrastruktury uczenia maszynowego
- Ocena punktowa modelu z przetwarzaniem strumieniowym w celu przewidywania i generowania treści w czasie rzeczywistym
- Generowanie potoków danych strumieniowych z tekstem wejściowym, mową lub obrazami
- Czas rzeczywisty szkolenia online dużych modeli językowych
Przeanalizowałem te przypadki użycia, w tym rzeczywiste przykłady, takie jak Expedia, BMW i Tinder, w poście na blogu “Apache Kafka jako Mission Critical Data Fabric dla GenAI.”
Poniżej przedstawiono konkretną architekturę połączenia dużych modeli językowych (LLM), rozszerzonego generowania wyszukiwania (RAG) z wektorowymi bazami danych i wyszukiwaniem semantycznym oraz strumieniowego przesyłania danych za pomocą Apache Kafka i Flink.
Dlaczego generatywna sztuczna inteligencja różni się od tradycyjnych architektur uczenia maszynowego
Uczenie maszynowe (ML) pozwala komputerom znaleźć ukryte informacje bez konieczności programowania, gdzie szukać. Nazywa się to uczeniem modelu, procesem wsadowym analizującym duże zbiory danych. Wynikiem jest plik binarny, model analityczny.
Aplikacje stosują te modele do nowych zdarzeń przychodzących w celu prognozowania. Nazywa się to scoringiem modelu i może odbywać się w czasie rzeczywistym lub wsadowo poprzez osadzenie modelu w aplikacji lub poprzez wykonanie wywołania API żądanie-odpowiedź do serwera modelu (który wdrożył model).
LLM i GenAI mają jednak inne wymagania i wzorce w porównaniu do tradycyjnych procesów ML, co mój były kolega Michael Drogalis wyjaśnił na dwóch prostych, przejrzystych diagramach.
Tradycyjne predykcyjne uczenie maszynowe ze złożoną inżynierią danych
Predykcyjna sztuczna inteligencja tworzy prognozy. Dedykowane modele. Szkolenie offline. W ten sposób uczyliśmy się maszyn przez ostatnią dekadę.
W tradycyjnym ML większość pracy związanej z inżynierią danych ma miejsce w czasie tworzenia modelu. Inżynieria cech i szkolenie modeli wymagają dużej wiedzy i wysiłku:
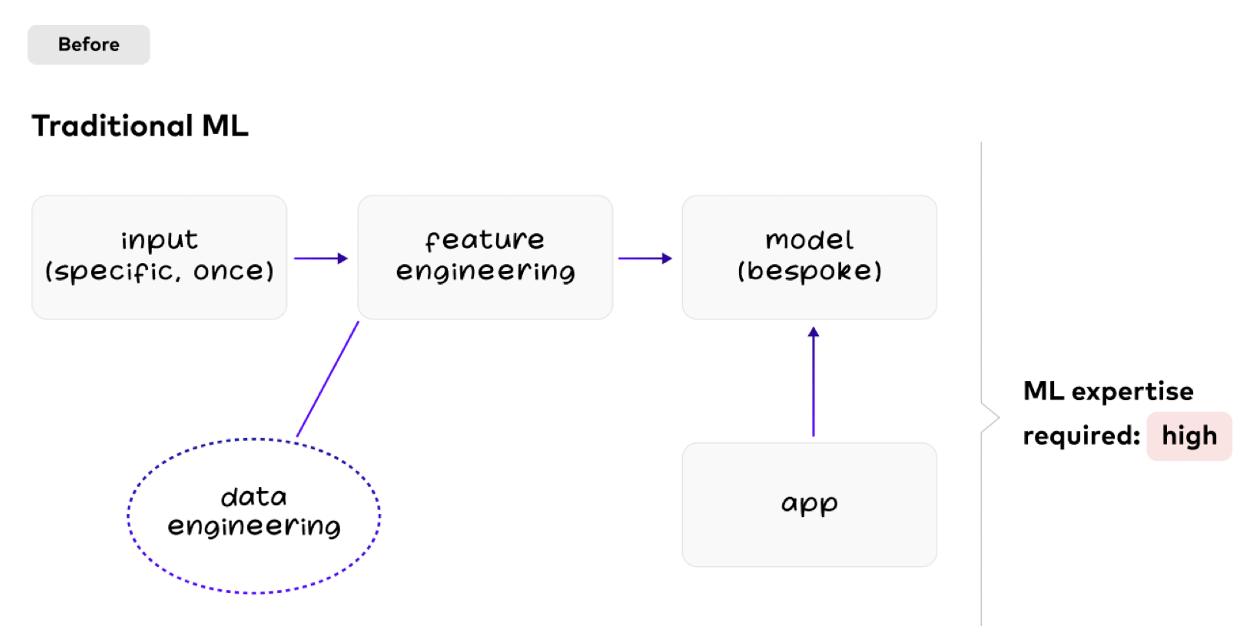
Nowe przypadki użycia wymagają nowego modelu zbudowanego przez inżynierów danych i naukowców zajmujących się danymi.
Demokratyzacja sztucznej inteligencji dzięki generatywnej sztucznej inteligencji wykorzystującej duże modele językowe (LLM)
Generatywna sztuczna inteligencja (GenAI) tworzy treści. Modele wielokrotnego użytku. Uczenie się w kontekście.
Jednak w przypadku dużych modeli językowych inżynieria danych odbywa się przy każdym zapytaniu. Różne aplikacje ponownie wykorzystują ten sam model:
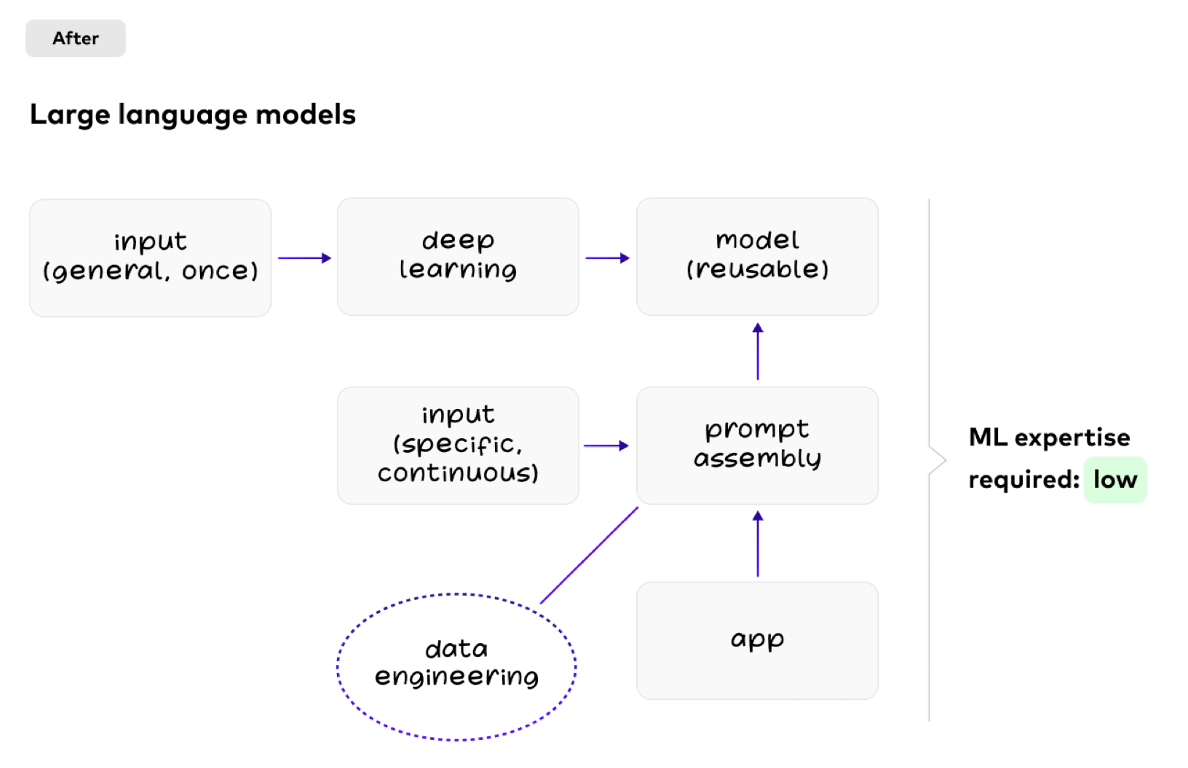
Wyzwania związane z dużymi modelami językowymi dla przypadków użycia GenAI
Duże modele językowe (LLM) są wielokrotnego użytku. Umożliwia to demokratyzację sztucznej inteligencji, ponieważ nie każdy zespół potrzebuje specjalistycznej wiedzy w tym zakresie. Zamiast tego do korzystania z istniejących LLM wystarczy niewielka wiedza z zakresu sztucznej inteligencji.
Istnieje jednak kilka ogromnych kompromisów związanych z LLM:
- Drogie szkolenia: LLM, takie jak ChatGPT, kosztują miliony dolarów w zasobach obliczeniowych (nie obejmuje to wymaganej wiedzy specjalistycznej do zbudowania modelu).
- Dane statyczne: LLM są “zamrożone w czasie”, co oznacza, że model nie posiada aktualnych informacji.
- Brak wiedzy o domenie: LLM zazwyczaj uczą się na podstawie publicznych zbiorów danych. W związku z tym inżynierowie danych pobierają dane z sieci WWW i wprowadzają je do szkolenia modelu. Przedsiębiorstwa muszą jednak używać LMM we własnym kontekście, aby zapewnić wartość biznesową.
- Głupota: LLM nie są inteligentne jak ludzie. Na przykład ChatGPT nie potrafi nawet policzyć liczby słów w zdaniu, które mu się poda.
Wyzwania te powodują tak zwane halucynacje…
Unikanie halucynacji w celu generowania wiarygodnych odpowiedzi
Halucynacje, tj. odpowiedzi oparte na zgadywaniu, są konsekwencją, a LLM nie mówi Panu, że zmyśla rzeczy. Halucynacja to zjawisko, w którym model sztucznej inteligencji generuje treści, które nie są oparte na rzeczywistych danych lub informacjach, ale tworzą całkowicie fikcyjne lub nierealistyczne wyniki. Halucynacje mogą wystąpić, gdy model generatywny, taki jak generator tekstu lub obrazu, generuje treści, które nie są spójne, oparte na faktach lub istotne dla danych wejściowych lub kontekstu. Te halucynacje mogą objawiać się jako tekst, obrazy lub inne rodzaje treści, które wydają się wiarygodne, ale są całkowicie sfabrykowane przez model.
Halucynacje mogą być problematyczne w generatywnej sztucznej inteligencji, ponieważ mogą prowadzić do generowania mylących lub fałszywych informacji.
Z tych powodów pojawił się nowy wzorzec projektowy dla generatywnej sztucznej inteligencji: Retrieval Augmented Generation (RAG). Przyjrzyjmy się najpierw tej nowej najlepszej praktyce, a następnie zbadajmy, dlaczego strumieniowanie danych za pomocą technologii takich jak Apache Kafka i Flink jest podstawowym wymogiem dla architektur korporacyjnych GenAI.
Semantyczne wyszukiwanie i pobieranie danych rozszerzonej generacji (RAG)
Wiele aplikacji obsługujących GenAI jest zgodnych z wzorcem projektowym Retrieval Augmented Generation (RAG), aby połączyć LLM z dokładnym i aktualnym kontekstem. Zespół stojący za Pinecone, w pełni zarządzaną wektorową bazą danych, posiada świetne wyjaśnienie przy użyciu tego diagramu:
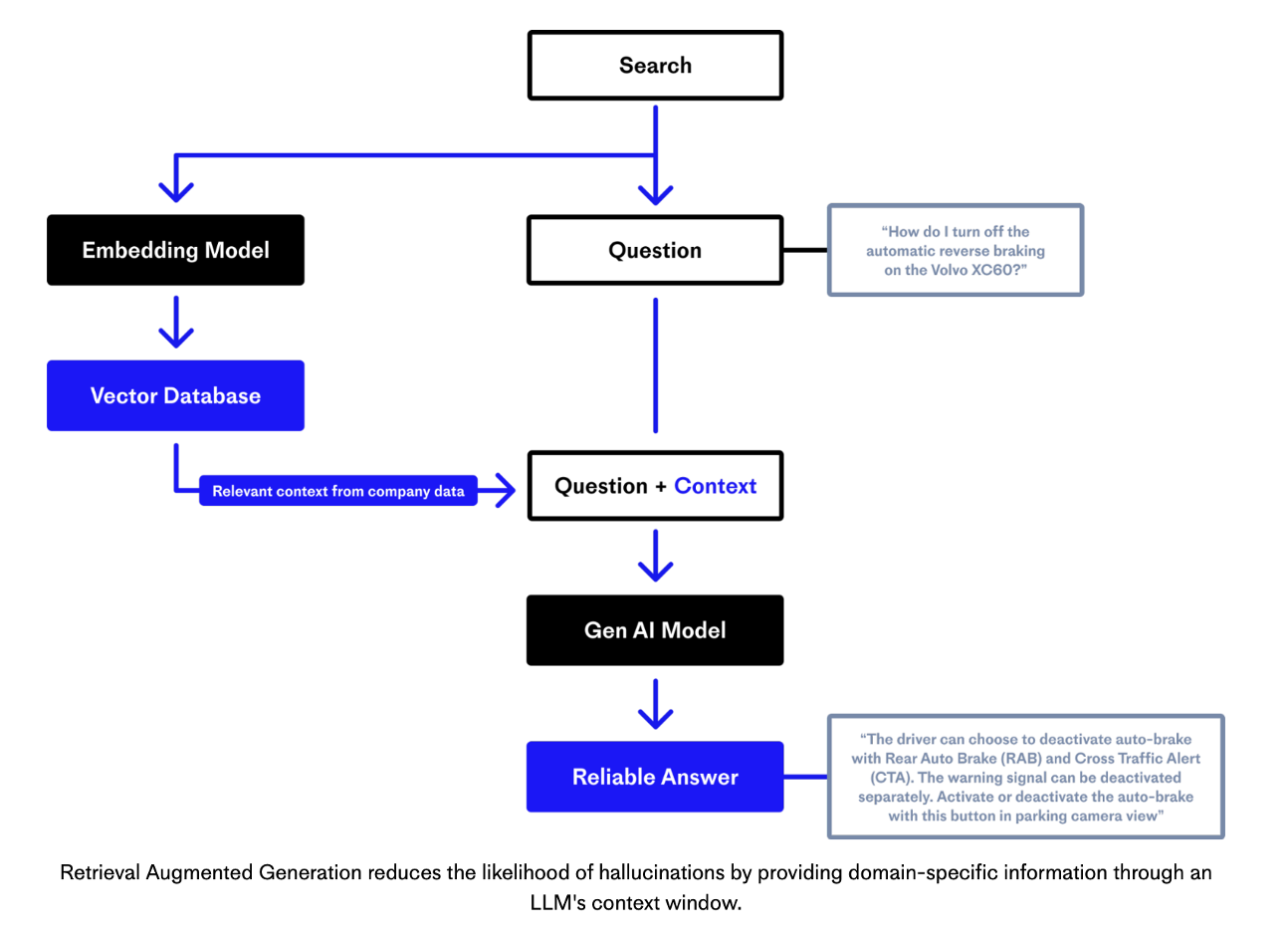 Źródło: Pinecone
Źródło: Pinecone
Na wysokim poziomie RAG składa się zazwyczaj z dwóch oddzielnych etapów. Pierwszym z nich jest etap rozszerzania danych, w którym różne (często nieustrukturyzowane) dane operacyjne są dzielone na fragmenty, a następnie tworzone są osadzenia przy użyciu modelu osadzania. Osadzenia są indeksowane w wektorowej bazie danych. Wektorowa baza danych jest narzędziem umożliwiającym wyszukiwanie semantyczne w celu znalezienia odpowiedniego kontekstu dla podpowiedzi, które nie wymagają dokładnego dopasowania słów kluczowych.
Po drugie, następuje etap wnioskowania, w którym model GenAI otrzymuje pytanie i kontekst w celu wygenerowania wiarygodnej odpowiedzi (bez halucynacji). RAG nie aktualizuje osadzeń, ale pobiera odpowiednie informacje, aby wysłać je do LLM wraz z podpowiedzią.
Wektorowe bazy danych dla wyszukiwania semantycznego z osadzeniami
Wektorowa baza danych, znana również jako wektorowa pamięć masowa lub indeks wektorowy, to rodzaj bazy danych, która została specjalnie zaprojektowana do wydajnego przechowywania i wyszukiwania danych wektorowych. W tym kontekście dane wektorowe odnoszą się do zbiorów wektorów numerycznych, które mogą reprezentować szeroki zakres typów danych, takich jak osadzenia tekstu, obrazów, dźwięku lub innych danych strukturalnych lub nieustrukturyzowanych. Wektorowe bazy danych są przydatne w aplikacjach związanych z uczeniem maszynowym, wyszukiwaniem danych, systemami rekomendacji, wyszukiwaniem podobieństw i nie tylko.
Wektorowe bazy danych doskonale sprawdzają się w wyszukiwaniu podobieństw, często nazywanym wyszukiwaniem semantycznym. Mogą one szybko znaleźć wektory, które są podobne lub bliskie danemu wektorowi zapytania w oparciu o różne wskaźniki podobieństwa, takie jak podobieństwo cosinusowe lub odległość euklidesowa.
Wektorowa baza danych nie jest (koniecznie) oddzielną kategorią baz danych. Gradient Flow wyjaśnia jego najlepsze praktyki dla Retrieval Augmented Generation:
“Wyszukiwanie wektorowe nie jest już ograniczone do wektorowych baz danych. Wiele systemów zarządzania danymi – w tym PostgreSQL – obsługuje teraz wyszukiwanie wektorowe. W zależności od konkretnego zastosowania, mogą Państwo znaleźć system, który spełni Państwa konkretne potrzeby. Czy priorytetem jest wyszukiwanie w czasie zbliżonym do rzeczywistego lub przesyłanie strumieniowe? Proszę sprawdzić ofertę Rockset. Czy korzystają już Państwo z grafu wiedzy? Obsługa wyszukiwania wektorowego przez Neo4j oznacza, że Państwa wyniki RAG będą łatwiejsze do wyjaśnienia i wizualizacji”.
Aby zapoznać się z innym konkretnym przykładem, proszę spojrzeć na samouczek MongoDB dla “Building Generative AI Applications Using MongoDB: Harnessing the Power of Atlas Vector Search and Open Source Models[Tworzenie generatywnych aplikacji sztucznej inteligencji przy użyciu MongoDB: Wykorzystanie możliwości wyszukiwania wektorowego Atlas i modeli open source]..” Istnieją różne opcje połączenia wektorowej bazy danych dla przypadków użycia GenAI z Apache Kafka. Poniżej przedstawiono możliwą architekturę w świecie sterowanym zdarzeniami.
Architektura sterowana zdarzeniami: Data Streaming + Vector DB + LLM
Aplikacje sterowane zdarzeniami mogą sprawić, że oba etapy Retrieval Augment Generation (RAG), rozszerzanie danych i wnioskowanie o modelu będą bardziej efektywnie wdrażane. Strumieniowe przesyłanie danych za pomocą Apache Kafka i Apache Flink umożliwia spójną synchronizację danych w dowolnej skali (w czasie rzeczywistym, jeśli aplikacja lub baza danych może to obsłużyć) oraz przetwarzanie danych (= strumieniowe ETL).
Poniższy diagram przedstawia architekturę korporacyjną wykorzystującą strumieniowe przesyłanie danych sterowane zdarzeniami w celu pozyskiwania i przetwarzania danych w całym potoku GenAI:
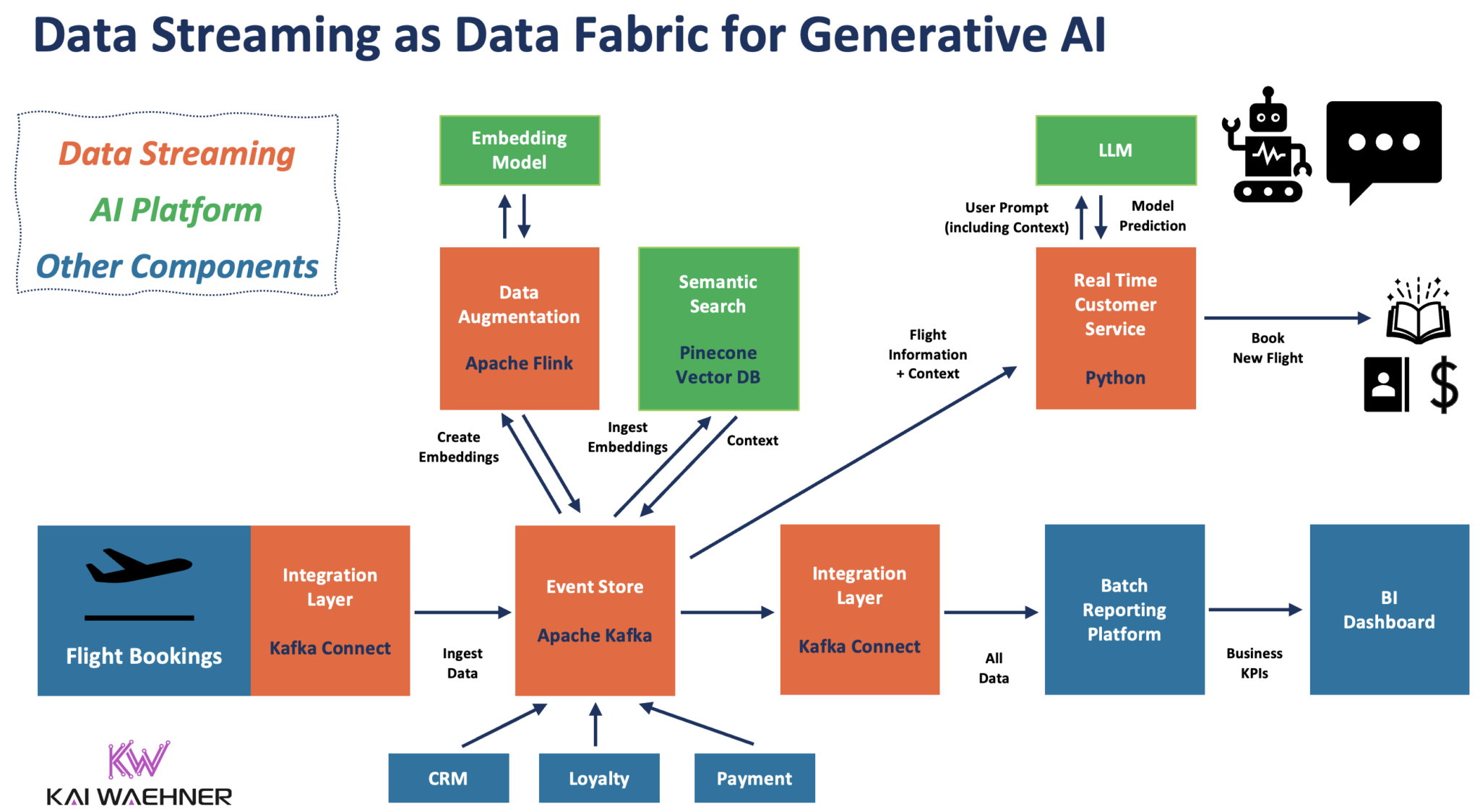
Ten przykład wykorzystuje strumieniowe przesyłanie danych do pozyskiwania rezerwacji lotów i zmian w czasie rzeczywistym do magazynu zdarzeń Kafka w celu późniejszego przetwarzania za pomocą technologii GenAI. Flink wstępnie przetwarza dane przed wywołaniem modelu osadzania w celu wygenerowania osadzeń dla wektorowej bazy danych. Równolegle aplikacja do obsługi klienta w czasie rzeczywistym zbudowana w języku Python wykorzystuje wszystkie istotne dane kontekstowe (np. dane lotu, dane klienta, osadzenia itp.), aby wyświetlić duży model językowy. LLM tworzy wiarygodną prognozę, np. zalecenie zmiany rezerwacji pasażera na inny lot.
W większości scenariuszy korporacyjnych całe przetwarzanie odbywa się za zaporą sieciową przedsiębiorstwa ze względów bezpieczeństwa i prywatności danych. LLM można nawet zintegrować z systemami transakcyjnymi, takimi jak system rezerwacji, w celu wykonania zmiany rezerwacji i przekazania wyników do odpowiednich aplikacji i baz danych.
Żądanie-odpowiedź z API vs. strumieniowanie danych sterowane zdarzeniami
W idealnym świecie wszystko opiera się na zdarzeniach i strumieniowym przesyłaniu danych. Rzeczywisty świat jest inny. W związku z tym wywołania API z żądaniem-odpowiedzią za pomocą HTTP/REST lub SQL są całkowicie w porządku w niektórych częściach architektury korporacyjnej. Ponieważ Kafka naprawdę oddziela systemy, każda aplikacja wybiera własny paradygmat komunikacji i szybkość przetwarzania. Dlatego ważne jest, aby zrozumieć Kompromisy między HTTP/REST API i Apache Kafka.
Kiedy używać Request-Response z Apache Kafka? – Decyzja ta jest często podejmowana w oparciu o kompromisy, takie jak opóźnienie, oddzielenie lub bezpieczeństwo. Jednak w przypadku dużych LLM sytuacja się zmienia. Ponieważ szkolenie LLM jest bardzo kosztowne, ponowne wykorzystanie istniejących LLM ma kluczowe znaczenie. Osadzenie LLM w aplikacji Kafka Streams lub Flink nie ma większego sensu w przeciwieństwie do innych modeli zbudowanych przy użyciu algorytmów takich jak drzewa decyzyjne, klastrowanie, a nawet małe sieci neuronowe.
Podobnie, modele augmentacyjne są zwykle integrowane poprzez wywołanie RPC/API. Poprzez osadzenie go w mikrousłudze Kafka Streams lub zadaniu Flink, model augmentacji staje się ściśle powiązany. A eksperci hostują ich dziś wiele, ponieważ ich obsługa i optymalizacja nie jest trywialna.
Rozwiązania hostujące modele LLM i augmentacji zazwyczaj zapewniają jedynie interfejs RPC, taki jak HTTP. Prawdopodobnie zmieni się to w przyszłości, ponieważ żądanie-odpowiedź jest anty-wzorcem dla danych strumieniowych. Doskonałym przykładem ewolucji serwerów modeli jest Seldon, zapewniający w międzyczasie natywny interfejs Kafka. Więcej informacji na temat serwerów typu żądanie-odpowiedź vs. serwerów strumieniowych znajdą Państwo w artykule Strumieniowe uczenie maszynowe z natywnym wdrożeniem modelu Kafka.
Bezpośrednia integracja między LLM a resztą przedsiębiorstwa
Podczas pisania tego artykułu, OpenAI ogłosiło GPT do tworzenia niestandardowych wersji ChatGPT, które łączą instrukcje, dodatkową wiedzę i dowolną kombinację umiejętności. W przypadku zastosowań korporacyjnych najbardziej interesującą funkcją jest to, że deweloperzy mogą połączyć GPT OpenAI ze światem rzeczywistym, tj. innymi aplikacjami, bazami danych i usługami w chmurze:
“Oprócz korzystania z naszych wbudowanych możliwości, można również definiować niestandardowe akcje, udostępniając GPT jeden lub więcej interfejsów API. Podobnie jak wtyczki, akcje umożliwiają GPT integrację danych zewnętrznych lub interakcję ze światem rzeczywistym. Proszę połączyć GPT z bazami danych, podłączyć je do e-maili lub uczynić z nich asystenta zakupów. Można na przykład zintegrować bazę danych ofert podróży, podłączyć skrzynkę e-mail użytkownika lub ułatwić zamówienia e-commerce”.
Kompromisy związane z bezpośrednią integracją to ścisłe sprzężenie i komunikacja punkt-punkt. Jeśli korzystają już Państwo z Kafki, rozumieją Państwo wartość tego rozwiązania. projektowanie oparte na domenie z prawdziwym oddzieleniem.
Wreszcie, publiczne interfejsy API GenAI i LLM mają słabą strategię bezpieczeństwa i zarządzania. W miarę pojawiania się danych AI i wzrostu liczby integracji punkt-punkt, dostęp do danych, ich pochodzenie i wyzwania związane z bezpieczeństwem eskalują.
Strumieniowe przesyłanie danych za pomocą Kafki, Flink i GenAI w praktyce
Po dużej ilości teorii przyjrzyjmy się konkretnemu przykładowi, wersji demonstracyjnej i rzeczywistemu studium przypadku łączącemu strumieniowanie danych z GenAI:
- Przykład: Flink SQL + OpenAI API
- Demo: ChatGPT 4 + Confluent Cloud + MongoDB Atlas dla RAG i wyszukiwania wektorowego
- Historia sukcesu: Elemental Cognition – Platforma AI czasu rzeczywistego zasilana przez Confluent Cloud
Przykład: Flink SQL + OpenAI API
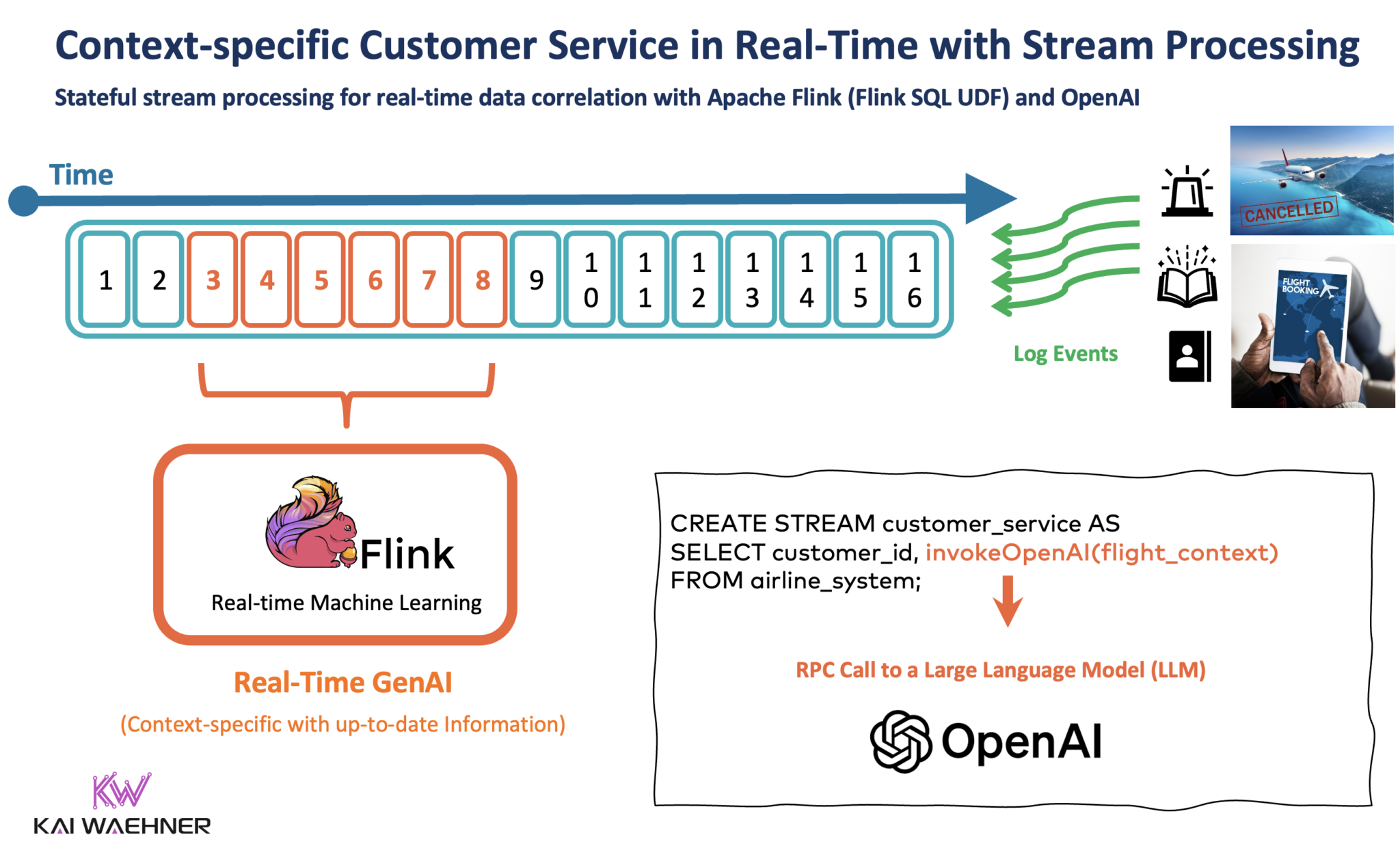
Przetwarzanie strumieniowe za pomocą Kafki i Flink umożliwia korelację danych w czasie rzeczywistym i danych historycznych. Doskonałym przykładem, zwłaszcza dla generatywnej sztucznej inteligencji, jest obsługa klienta dostosowana do kontekstu. Pozostajemy przy przykładzie linii lotniczych i odwołanych lotów.
Stanowy procesor strumieniowy pobiera istniejące informacje o kliencie z CRM, platformy lojalnościowej i innych aplikacji, koreluje je z zapytaniem od klienta do chatbota i wykonuje wywołanie RPC do LLM.
Poniższy diagram wykorzystuje Apache Flink z funkcją Flink SQL User Defined Function (UDF). Zapytanie SQL przekazuje wstępnie przetworzone dane do interfejsu API OpenAI w celu uzyskania wiarygodnej odpowiedzi. Odpowiedź jest wysyłana do innego tematu Kafka, z którego korzystają dalsze aplikacje, np. w celu zmiany rezerwacji biletów, aktualizacji platformy lojalnościowej, a także przechowywania danych w jeziorze danych w celu późniejszego przetwarzania wsadowego i analizy.
Demo: ChatGPT 4 + Confluent Cloud + MongoDB Atlas dla RAG i Vector Search
Mój kolega Britton LaRoche stworzył fantastyczne demo detaliczne pokazujące połączenie Kafki do integracji i przetwarzania danych oraz MongoDB do przechowywania i semantycznego wyszukiwania wektorowego. D-ID, platforma do tworzenia wideo AI, upiększa demo, zastępując interfejs wiersza poleceń wizualnymi awatarami AI.
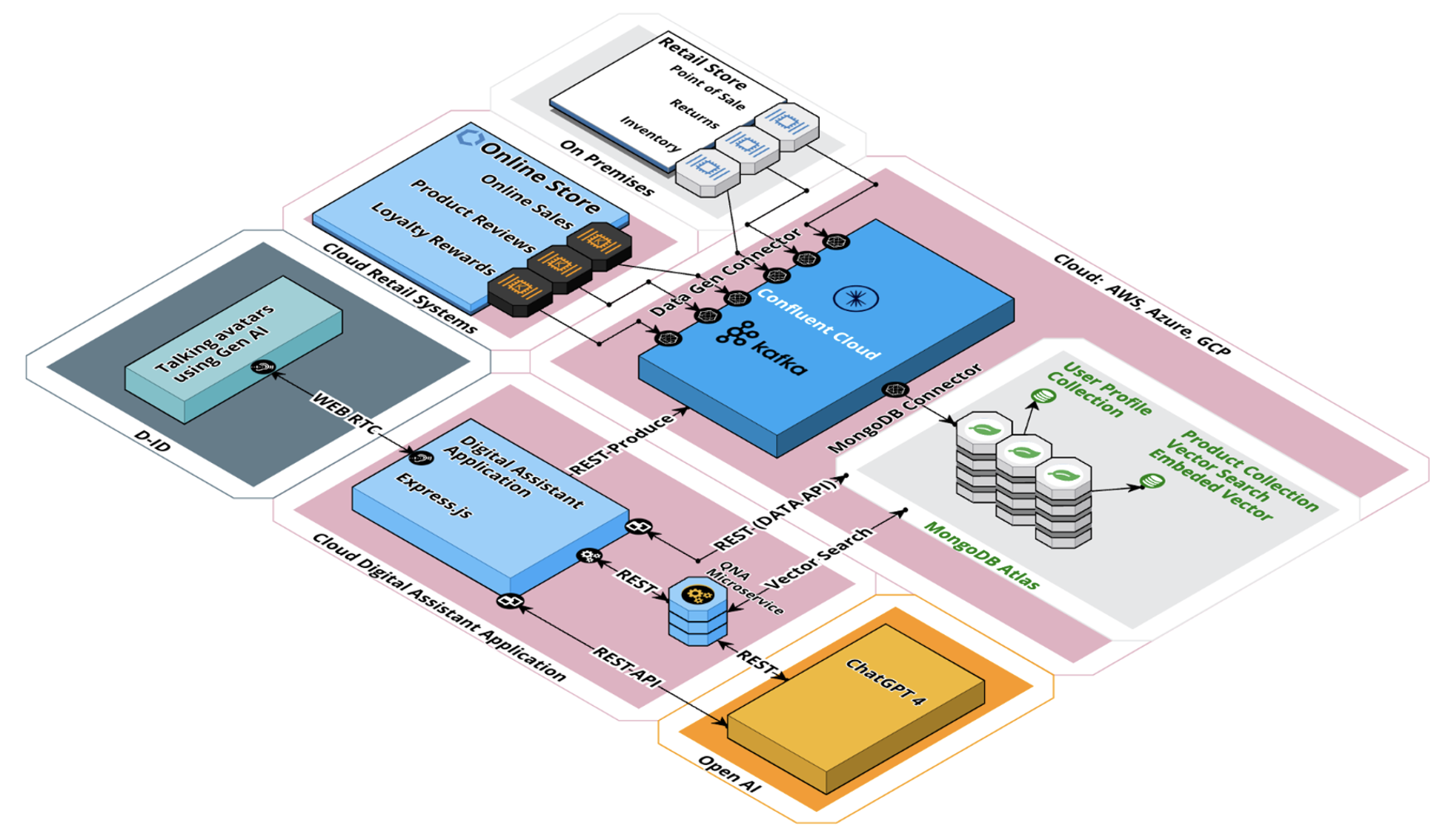
W pełni zarządzane i głęboko zintegrowane usługi Confluent Cloud i MongoDB Atlas pozwalają nam skupić się na budowaniu logiki biznesowej.
Architektura różni się od mojego powyższego przykładu strumieniowania opartego na zdarzeniach. Rdzeniem jest nadal Kafka, aby naprawdę oddzielić aplikacje. Większość usług jest zintegrowana za pośrednictwem interfejsów API typu żądanie-odpowiedź. Jest to proste, dobrze zrozumiałe i często wystarczająco dobre. W późniejszym czasie można łatwo migrować do wzorców opartych na zdarzeniach przy użyciu interfejsu API Python Kafka, przechwytywania danych zmian (CDC) z Kafki, osadzania LangChain Python UDF w Apache Flink lub korzystania z interfejsu asynchronicznego, takiego jak AsyncAPI.
Poniżej znajduje się krótkie, pięciominutowe demo przeprowadzające Państwa przez demo z RAG i wyszukiwaniem semantycznym przy użyciu MongoDB Atlas, Confluent jako centrum integracji i D-ID jako interfejsu komunikacyjnego z użytkownikiem końcowym:
Historia sukcesu: Elemental Cognition – platforma GenAI czasu rzeczywistego oparta na Kafce i Confluent Cloud
Dr David Ferrucci, znany badacz sztucznej inteligencji i wynalazca przełomowej technologii IBM Watson, założył Elemental Cognition w 2015 roku. Firma wykorzystuje GenAI do przyspieszenia i usprawnienia podejmowania krytycznych decyzji, w których liczy się zaufanie, precyzja i przejrzystość.
Technologia Elemental Cognition może być stosowana w różnych branżach i przypadkach użycia. Główne cele to opieka zdrowotna / nauki przyrodnicze, zarządzanie inwestycjami, inteligencja, logistyka i planowanie oraz centra kontaktowe.
Platforma AI rozwija odpowiedzialną i przejrzystą sztuczną inteligencję, która pomaga rozwiązywać problemy i dostarczać wiedzę, którą można zrozumieć i której można zaufać.
Podejście Elemental Cognition łączy różne strategie sztucznej inteligencji w nowatorskiej architekturze, która pozyskuje i analizuje wiedzę czytelną dla człowieka w celu wspólnego i dynamicznego rozwiązywania problemów. Rezultatem jest bardziej przejrzyste i efektywne kosztowo dostarczanie eksperckiej inteligencji do rozwiązywania problemów w aplikacjach konwersacyjnych i odkrywczych.
Confluent Cloud zasila platformę AI, aby umożliwić skalowalne wykorzystanie danych w czasie rzeczywistym i integracji danych. Polecam zapoznać się z ich strona internetowa aby zapoznać się z różnymi imponującymi przypadkami użycia.

Apache Kafka jako centralny układ nerwowy dla architektury korporacyjnej GenAI
Generatywna sztuczna inteligencja (GenAI) wymaga zmian w architekturze korporacyjnej AI/ML. Modele rozszerzone, LLM, RAG z wektorowymi bazami danych i wyszukiwanie semantyczne wymagają integracji danych, korelacji i oddzielenia. Streaming danych z Kafka i Flink jest tutaj, aby pomóc.
Wiele aplikacji i baz danych wykorzystuje komunikację typu żądanie-odpowiedź z interfejsami REST/HTTP, SQL lub innymi. Jest to całkowicie w porządku. Proszę wybrać odpowiednią technologię i warstwę integracji dla swoich produktów danych i aplikacji. Proszę jednak zadbać o spójność danych.
Strumieniowe przesyłanie danych za pomocą Apache Kafka i Apache Flink umożliwia programistom i inżynierom danych skupienie się na problemach biznesowych w ich produktach danych lub projektach integracyjnych, ponieważ naprawdę oddziela różne domeny. Integracja z Kafką jest możliwa za pomocą HTTP, interfejsów API Kafki, AsyncAPI, CDC z bazy danych, interfejsów SaaS i wielu innych opcji.
Kafka umożliwia połączenie systemów z dowolnym paradygmatem komunikacji. Jego magazyn zdarzeń udostępnia dane w milisekundach (nawet w ekstremalnych skalach), ale także utrwala dane dla wolniejszych aplikacji niższego szczebla i odtwarza dane historyczne. Serce siatki danych musi bić w czasie rzeczywistym. Dotyczy to każdej dobrej architektury korporacyjnej. GenAI nie jest inna.
Jak tworzy Pan konwersacyjną sztuczną inteligencję, chatboty i inne aplikacje GenAI wykorzystujące Apache Kafka? Czy zbudował Pan RAG w czasie rzeczywistym z Flink i Vector Database, aby zapewnić odpowiedni kontekst dla LLM? Proszę proszę połączyć się na LinkedIn i proszę dyskutować! Proszę być na bieżąco z nowymi wpisami na blogu subskrybując mój newsletter.