
Proszę rozważyć scenariusz, w którym fragment danych jest modyfikowany u źródła – jakie ma to konsekwencje dla innych systemów zależnych od niego? Jak przekazać niezbędne zmiany interesariuszom? I odwrotnie, jak zapobiegać zmianom, które mogłyby zakłócić działanie systemu?
Posiadanie solidnego planu zarządzania dryfem danych jest niezbędne. Firmy potrzebują systemów danych, które działają płynnie i pozostają spójne, nawet pomimo zmian w źródle danych. Ponadto potrzebne są mechanizmy oceny i podejmowania decyzji o zmianach, zapewniające płynne działanie dla wszystkich zaangażowanych w dane.
Ten samouczek pokaże Państwu, w jaki sposób narzędzia takie jak Apache Kafka®, Apache Kafka Connect i wbudowana funkcjonalność rejestru schematów dostarczana przez Karapacemoże pomóc firmom kontrolować dryf danych. Wyjaśni również, jak odmówić lub zezwolić na zmiany w zależności od potrzeb biznesowych.
Dlaczego Apache Kafka i dlaczego rejestr schematów?
Apache Kafka jest powszechnie stosowany jako centrum danych zaplecza, umożliwiając firmom przenoszenie danych obsługiwanych przez niezawodną, szybką i skalowalną technologię. Apache Kafka zapewnia korzyści płynące z oddzielenia producentów i konsumentów danych, umożliwiając producentom niezawodne wysyłanie danych bez konieczności martwienia się o to, czy konsumenci są gotowi do odczytu lub czy są wystarczająco szybcy, aby nadążyć za przepustowością.
Domyślnie Apache Kafka nie narzuca ani nie weryfikuje struktury danych. Wiadomości są przesyłane i pobierane w dowolnym formacie uzgodnionym przez producenta i konsumenta. Prosta umowa zewnętrzna jest jednak często niewystarczająca w złożonych systemach, w których te same informacje muszą być ponownie wykorzystane przez wielu konsumentów z różnych części firmy. Apache Kafka musi nie tylko zapewnić, że konsumenci mogą pobierać dane, ale także nadać im sens, nawet jeśli struktura wiadomości zmienia się nieznacznie w czasie.
W tym miejscu do gry wkracza funkcjonalność rejestru schematów włączona przez Karapace: sposób na oddzielenie struktury wiadomości od jej treści oraz metoda weryfikacji, czy aktualizacje struktury danych nie zepsują dalszych odbiorców informacji. Dzięki Karapace możemy zdefiniować strukturę każdego tematu, wraz z poziomem zgodności określającym, które zmiany struktury danych są dozwolone lub odrzucane.
W kolejnych sekcjach zbadamy, w jaki sposób rejestr schematów może być używany w połączeniu z Apache Kafka® Connect, zarówno jako źródło, jak i zlew, w celu sprawdzenia zmian struktury danych i propagowania ich, jeśli spełniają wymagania zgodności.
Ogólna architektura
Aby zasymulować typowy przepływ danych w firmie, wykorzystamy PostgreSQL® jako nasze źródło, służące jako nasza transakcyjna baza danych. Wyodrębnianie z niej danych będzie wymagało użycia Apache Kafka, Apache Kafka Connect i konektora źródłowego Debezium, umożliwiając proces przechwytywania danych zmian w czasie rzeczywistym. Gdy dane znajdą się w Apache Kafka, wykorzystamy zintegrowaną integrację z Karapace do przechowywania schematu danych i oceny zmian pod kątem zgodności. Wreszcie, wyniki naszych zmian danych pojawią się w bazie danych MySQL i wiadrze Amazon S3, odzwierciedlając dwa przypadki użycia: analitykę działową i długoterminowe przechowywanie danych.
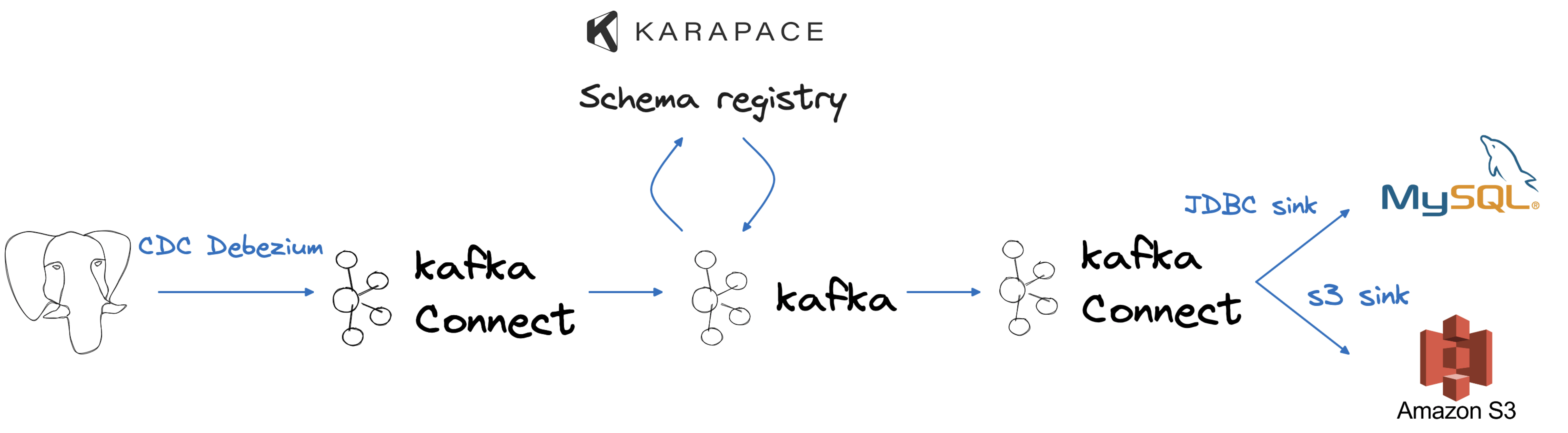
Rys. 1. Architektura Kafka Connect
Możemy utworzyć cały przepływ za pomocą Aiven’s interfejs wiersza poleceń. Proszę również zainstalować psql. Proszę uruchomić następujące polecenia:
avn service create demo-drift-postgresql -t pg --cloud aws-eu-west-1 -p free-1-5gb
avn service create demo-drift-mysqldb -t mysql --cloud aws-eu-west-1 -p free-1-5gb
avn service create demo-drift-kafka \
-t kafka \
--cloud aws-eu-west-1 \
-p business-4 \
-c kafka.auto_create_topics_enable=true \
-c kafka_connect=true \
-c kafka_rest=true \
-c schema_registry=truePowyższe trzy polecenia zostaną uruchomione:
- Baza danych Aiven dla PostgreSQL o nazwie
demo-drift-postgresqlwaws-eu-west-1w chmurze, korzystając z bezpłatnej warstwy Aiven - Baza danych Aiven dla MySQL o nazwie
demo-drift-mysqlwaws-eu-west-1w chmurze, korzystając z bezpłatnej warstwy Aiven - Usługa Aiven dla Apache Kafka® o nazwie
demo-drift-kafkawaws-eu-west-1regionie chmury przy użyciu Aivenbusiness-4plan i włączanie:- Automatyczne tworzenie tematów
- Apache Kafka Connect, działający na tych samych węzłach co Apache Kafka
- Interfejsy API REST Kafka
- Funkcjonalność Kafka Schema Registry obsługiwana przez Karapace
Możemy poczekać na utworzenie powyższych usług:
avn service wait demo-drift-postgresql
avn service wait demo-drift-kafka
avn service wait demo-drift-mysqldbTworzenie źródłowego zbioru danych w PostgreSQL
Pierwszym krokiem w podróży po danych będzie baza danych PostgreSQL, działająca jako firmowy backend transakcyjny. W tej sekcji połączymy się z bazą danych i dołączymy niektóre dane. Aby się połączyć, możemy użyć wstępnie zbudowanego polecenia Aiven CLI (które wymaga psql do zainstalowania lokalnie):
avn service cli demo-drift-postgresqlPo nawiązaniu połączenia możemy utworzyć podstawowy USERS tabelę i dołączyć kilka danych:
CREATE TABLE USERS (ID SERIAL PRIMARY KEY, USERNAME VARCHAR, HERO BOOLEAN);
INSERT INTO USERS (USERNAME, HERO)
VALUES ('Spiderman', TRUE), ('Flash', TRUE), ('Joker', FALSE), ('Batman', TRUE);Zmiana przechwytywania danych z PostgreSQL na Apache Kafka
Po naśladowaniu systemu OLTP (Online Transaction Processing), możemy teraz utworzyć potok przechwytywania danych zmian, umożliwiający nam śledzenie USERS tabelę w Apache Kafka. Skonfigurujemy przepływ CDC przy użyciu pliku Debezium connector i następujący plik konfiguracyjny, który nazwiemy cdc-deb.json. Proszę pamiętać o zastąpieniu wartości takich jak <DATABASE_HOST> w poniższym przykładzie.
{
"name": "pg-source-users",
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.server.name": "sourcepg",
"database.hostname": "<DATABASE_HOST>",
"database.port": "<DATABASE_PORT>",
"database.user": "avnadmin",
"database.password": "<POSTGRESQL_PASSWORD>",
"database.dbname": "defaultdb",
"plugin.name": "pgoutput",
"slot.name": "myslot1",
"publication.name": "mypub1",
"publication.autocreate.mode": "filtered",
"database.sslmode": "require",
"table.include.list": "public.users",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "https://<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>",
"key.converter.basic.auth.credentials.source": "USER_INFO",
"key.converter.schema.registry.basic.auth.user.info": "avnadmin:<SCHEMA_REGSITRY_PASSWORD>",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "https://<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>",
"value.converter.basic.auth.credentials.source": "USER_INFO",
"value.converter.schema.registry.basic.auth.user.info": "avnadmin:<SCHEMA_REGISTRY_PASSWORD>"
}W powyższym konektorze definiujemy:
-
Konektor Debezium PostgreSQL w sekcji
connector.classparametr -
Ustawienia połączenia PostgreSQL w zestawie parametrów
database.*Parametry, Możemy uzyskać listę potrzebnych parametrów za pomocą następującego wywołania:avn service get demo-drift-postgresql --format '{service_uri_params}' -
Nazwa wtyczki replikacji PostgreSQL, nazwa slotu, nazwa publikacji i tryb. Możemy wcześniej utworzyć slot i publikację w PostgreSQL lub zlecić konektorowi utworzenie ich dla nas.
-
Lista tabel do uwzględnienia w replikacji (
public.users) -
Wykorzystanie funkcji rejestru schematu Avro i Apache Kafka zarówno dla kluczy wiadomości, jak i wartości. Możemy pobrać potrzebne parametry połączenia (
<KAFKA_HOST>,<SCHEMA_REGISTRY_PORT>,<SCHEMA_REGISTRY_PASSWORD>)avn service get demo-drift-kafka --json | jq -r '.connection_info.schema_registry_uri'Powyższe polecenie zgłosi identyfikator URI rejestru schematu Kafka w postaci:
https://avnadmin:<SCHEMA_REGISTRY_PASSWORD>@<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT> -
Po zastąpieniu wartości zastępczych w pliku, możemy utworzyć konektor za pomocą następującego wywołania, gdzie
cdc-deb.jsonto plik zawierający ustawienia konektora:
avn service connector create demo-drift-kafka @cdc-deb.jsonProszę sprawdzić dane w Kafka
Po uruchomieniu konektora możemy użyć kcat aby sprawdzić dane w Apache Kafka.
Aby uzyskać kcat aby połączyć się z naszą usługą Kafka, a także pobrać niezbędne certyfikaty SSL, proszę uruchomić:
avn service connection-info kcat demo-drift-kafka -WNastępnie możemy pobrać plik avnadmin hasło z:
avn service user-list --format '{password}' --project devrel-francesco demo-drift-kafkaNa koniec możemy przyjąć, że kcat i użyć go do sprawdzenia danych. Musimy dodać kilka parametrów, aby wyjaśnić, co chcemy odczytać:
-Caby powiedzieć mu, aby działał jako konsument,-t sourcepg.public.usersaby powiedzieć mu, z którego tematu ma czytać,-s avroaby powiedzieć mu, aby używał Avro, i-r https://avnadmin:<SCHEMA_REGISTRY_PWD>@<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>aby powiedzieć mu, gdzie znajduje się rejestr schematów
Łącząc to wszystko razem, uruchomione polecenie powinno wyglądać następująco:
kcat -b <KAFKA_HOST>:<KAFKA_PORT> \
-X security.protocol=SSL \
-X ssl.ca.location=ca.pem \
-X ssl.key.location=service.key \
-X ssl.certificate.location=service.cert \
-s avro \
-r https://avnadmin:<SCHEMA_REGISTRY_PWD>@<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT> \
-C -t sourcepg.public.usersPowinniśmy zobaczyć te same cztery wiersze, które wstawiliśmy wcześniej, pojawiające się w standardowym formacie Debezium:
{"id": 1}{"before": null, "after": {"Value": {"id": 1, "username": {"string": "Spiderman"}, "hero": {"boolean": true}}}, "source": {"version": "1.9.7.aiven", "connector": "postgresql", "name": "sourcepg", "ts_ms": 1692017248192, "snapshot": {"string": "true"}, "db": "defaultdb", "sequence": {"string": "[null,\"235090528\"]"}, "schema": "public", "table": "users", "txId": {"long": 1036}, "lsn": {"long": 235090528}, "xmin": null}, "op": "r", "ts_ms": {"long": 1692017248487}, "transaction": null}
{"id": 2}{"before": null, "after": {"Value": {"id": 2, "username": {"string": "Flash"}, "hero": {"boolean": true}}}, "source": {"version": "1.9.7.aiven", "connector": "postgresql", "name": "sourcepg", "ts_ms": 1692017248192, "snapshot": {"string": "true"}, "db": "defaultdb", "sequence": {"string": "[null,\"235090528\"]"}, "schema": "public", "table": "users", "txId": {"long": 1036}, "lsn": {"long": 235090528}, "xmin": null}, "op": "r", "ts_ms": {"long": 1692017248493}, "transaction": null}
{"id": 3}{"before": null, "after": {"Value": {"id": 3, "username": {"string": "Joker"}, "hero": {"boolean": false}}}, "source": {"version": "1.9.7.aiven", "connector": "postgresql", "name": "sourcepg", "ts_ms": 1692017248192, "snapshot": {"string": "true"}, "db": "defaultdb", "sequence": {"string": "[null,\"235090528\"]"}, "schema": "public", "table": "users", "txId": {"long": 1036}, "lsn": {"long": 235090528}, "xmin": null}, "op": "r", "ts_ms": {"long": 1692017248494}, "transaction": null}
{"id": 4}{"before": null, "after": {"Value": {"id": 4, "username": {"string": "Batman"}, "hero": {"boolean": true}}}, "source": {"version": "1.9.7.aiven", "connector": "postgresql", "name": "sourcepg", "ts_ms": 1692017248192, "snapshot": {"string": "last"}, "db": "defaultdb", "sequence": {"string": "[null,\"235090528\"]"}, "schema": "public", "table": "users", "txId": {"long": 1036}, "lsn": {"long": 235090528}, "xmin": null}, "op": "r", "ts_ms": {"long": 1692017248494}, "transaction": null}Proszę sprawdzić definicję danych w Karapace
Po utworzeniu konektora przy użyciu Avro i rejestru schematów Karapace, możemy sprawdzić definicję schematu dla tematu. Domyślnie, podczas korzystania z Kafka Connect z rejestrem schematów, generowane są dwa schematy o nazwach <TOPIC_NAME>-value i <TOPIC_NAME>-key do przechowywania definicji schematu odpowiednio dla wartości i klucza.
Możemy uzyskać listę schematów zdefiniowanych w Karapace za pomocą:
curl https://avnadmin:<SCHEMA_REGISTRY_PASSWORD>@<KAFKA_HOST>:<KAFKA_PORT>/subjectsKtóry zwraca dane wyjściowe podobne do:
["sourcepg.public.users-key","sourcepg.public.users-value"]Powyżej znajdują się nazwy dwóch schematów dla tematu Debezium. Każda nazwa jest konkatenacją wartości database.server.name parametru (sourcepg), schemat i nazwę tabeli (public.users) i albo key lub value sufiks.
Możemy sprawdzić, które wersje posiadamy dla sourcepg.public.users-key topic with:
curl -X GET https://avnadmin:<SCHEMA_REGISTRY_PASSWORD>@<KAFKA_HOST>:<KAFKA_PORT>/subjects/sourcepg.public.users-key/versionsDane wyjściowe powinny pokazywać wersję 1 jest dostępna.
Aby sprawdzić definicję schematu sourcepg.public.users-key wersja 1 możemy użyć następującego polecenia:
curl -X GET https://avnadmin:<SCHEMA_REGISTRY_PASSWORD>@<KAFKA_HOST>:<KAFKA_PORT>/subjects/sourcepg.public.users-key/versions/1Dane wyjściowe pokazują wszystkie pola zawarte w kluczu, w tym pole id i name zdefiniowaliśmy w oryginalnej tabeli PostgreSQL.
{
"id": 1,
"schema": "{\"connect.name\":\"sourcepg.public.users.Key\",\"fields\":[{\"default\":0,\"name\":\"id\",\"type\":{\"connect.default\":0,\"type\":\"int\"}}],\"name\":\"Key\",\"namespace\":\"sourcepg.public.users\",\"type\":\"record\"}",
"subject": "sourcepg.public.users-key",
"version": 1
}Przesyłanie danych do MySQL
Teraz, gdy mamy już dane w Apache Kafka, skonfigurujmy konsumenta danych, aby zademonstrować, w jaki sposób rozwiązanie zarządza dryfem. Początkowym konsumentem będzie baza danych MySQL. Możemy ustanowić przepływ za pomocą dedykowanego złącza JDBC sink i następującego kodu zapisanego w mysql_jdbc_sink.json.
{
"name": "cdc-sink-mysql",
"connector.class": "io.aiven.connect.jdbc.JdbcSinkConnector",
"topics": "sourcepg.public.users",
"transforms": "extract",
"connection.url": "jdbc:mysql://<MYSQL_HOST>:<MYSQL_PORT>/<MYSQL_DB_NAME>?ssl-mode=REQUIRED",
"connection.user": "avnadmin",
"connection.password": "<MYSQL_PASSWORD>",
"table.name.format": "users_mysql",
"insert.mode": "upsert",
"pk.mode": "record_key",
"pk.fields": "id",
"auto.create": "true",
"auto.evolve": "true",
"transforms": "extract",
"transforms.extract.type": "io.debezium.transforms.ExtractNewRecordState",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "https://<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>",
"key.converter.basic.auth.credentials.source": "USER_INFO",
"key.converter.schema.registry.basic.auth.user.info": "avnadmin:<SCHEMA_REGISTRY_PASSWORD>",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "https://<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>",
"value.converter.basic.auth.credentials.source": "USER_INFO",
"value.converter.schema.registry.basic.auth.user.info": "avnadmin:<SCHEMA_REGISTRY_PASSWORD>"
}W powyższym konektorze definiujemy:
-
Złącze zlewu JDBC w pliku
connector.classparametr -
Ustawienia połączenia MySQL w
connection.urlMożemy uzyskać parametry do skompilowania adresu URL i danych uwierzytelniających za pomocą następującego wywołaniaavn service get demo-drift-mysqldb --format '{service_uri_params}' -
Nazwą tabeli docelowej będzie
users_mysqlz trybem upsert (proszę zobaczyćinsert.mode), wstawiając lub aktualizując istniejące wiersze na podstawie wartościid(proszę zobaczyćpk.modeorazpk.fieldsparametry) -
Tabela zostanie utworzona automatycznie, jeśli nie istnieje (
"auto.create": "true") i będzie ewoluować zgodnie ze zmianami w temacie Apache Kafka ("auto.evolve": "true"). Będzie to kluczem do propagacji dryfu do technologii niższego szczebla (w tym przypadku MySQL). -
Transformacja o nazwie
extractaby pobrać i propagować status wiersza po zmianie z formatu Debezium -
Wykorzystanie funkcji rejestru schematu Avro i Apache Kafka zarówno dla kluczy wiadomości, jak i wartości. Możemy pobrać potrzebne parametry połączenia (
<KAFKA_HOST>,<SCHEMA_REGISTRY_PORT>,<SCHEMA_REGISTRY_PASSWORD>)avn service get demo-drift-kafka --json | jq -r '.connection_info.schema_registry_uri'Powyższe polecenie dostarczy uri rejestru schematu Kafka w postaci:
https://avnadmin:<SCHEMA_REGISTRY_PASSWORD>@<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>
Po zastąpieniu wartości zastępczych możemy utworzyć konektor za pomocą następującego wywołania, gdzie cdc-deb.json jest plikiem zawierającym ustawienia konektora:
avn service connector create demo-drift-kafka @mysql_jdbc_sink.jsonMożemy zweryfikować status złącza za pomocą:
avn service connector status demo-drift-kafka cdc-sink-mysqlPowyższe polecenie powinno pokazać złącze w RUNNING state
Proszę sprawdzić dane w MySQL
Po uruchomieniu powyższego konektora możemy przejść do MySQL, aby sprawdzić dane. Aby uzyskać parametry połączenia, możemy ponownie wpisać następujące polecenie:
avn service get demo-drift-mysqldb --format '{service_uri_params}'A następnie połączyć się za pomocą następującego polecenia, zastępując symbole zastępcze. Proszę zwrócić uwagę na brak spacji między znakami -p a hasłem.
mysql -u avnadmin \
-P <MYSQL_PORT> \
-h <MYSQL_HOST> \
-D defaultdb \
-p<MYSQL_PASSWORD>Następnie możemy sprawdzić dane za pomocą:
select * from users_mysql;Tabela wygląda następująco users_mysql po table.name.format w konektorze. Dane powinny być zgodne z tym, co mamy w PostgreSQL.
+----+-----------+------+
| id | username | hero |
+----+-----------+------+
| 1 | Spiderman | 1 |
| 2 | Flash | 1 |
| 3 | Joker | 0 |
| 4 | Batman | 1 |
+----+-----------+------+Jeśli sprawdzimy strukturę tabeli describe users_mysql, możemy zobaczyć, że hero została zmapowana do kolumny TINYINT w MySQL.
+----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+-------+
| id | int | NO | PRI | 0 | |
| username | varchar(256) | YES | | NULL | |
| hero | tinyint | YES | | NULL | |
| points | int | YES | | NULL | |
+----------+--------------+------+-----+---------+-------+Let’s Talk Drift
Do tej pory zbudowaliśmy dość tradycyjny potok danych. Teraz wprowadźmy pewne zmiany w oryginalnej strukturze danych w PostgreSQL, aby naśladować dryf.
Dodawanie kolumny
W terminalu podłączonym do bazy danych PostgreSQL proszę wykonać następujące polecenie, aby dodać kolumnę POINTS integer column:
ALTER TABLE USERS ADD COLUMN POINTS INT;Nic nie dzieje się natychmiast w docelowej tabeli MySQL po wykonaniu DDL w PostgreSQL. Struktura i dane USERS_MYSQL pozostają takie same.
Proszę teraz zmienić dane w PostgreSQL, używając następującej instrukcji update:
UPDATE USERS SET POINTS = CASE WHEN USERNAME = 'Batman' then 5 else 10 end;W MySQL proszę wykonać:
SELECT * FROM users_mysql;Możemy zobaczyć efekt na tabeli MySQL points w czasie zbliżonym do rzeczywistego:
+----+-----------+------+--------+
| id | username | hero | points |
+----+-----------+------+--------+
| 1 | Spiderman | 1 | 10 |
| 2 | Flash | 1 | 10 |
| 3 | Joker | 0 | 10 |
| 4 | Batman | 1 | 5 |
+----+-----------+------+--------+Jak wspomniano w definicji złącza zlewu, "auto.create": "true" umożliwia automatyczne utworzenie tabeli, jeśli nie istnieje, oraz "auto.evolve": "true" umożliwia ewolucję tabeli w przypadkach, gdy dołączane są nowe kolumny danych.
Usuwanie kolumny
A co z usuwaniem kolumn? Proszę to przetestować! Upuśćmy to samo points kolumnę, którą właśnie dodaliśmy z terminala PostgreSQL:
ALTER TABLE USERS DROP COLUMN POINTS;Jeśli ponownie wykonamy nasze poprzednie zapytanie w MySQL:
SELECT * FROM users_mysql;Widzimy, że kolumna nie jest usuwana w MySQL, struktura pliku users_mysql jest taka sama i points kolumna jest nadal wypełniona.
+----+-----------+------+--------+
| id | username | hero | points |
+----+-----------+------+--------+
| 1 | Spiderman | 1 | 10 |
| 2 | Flash | 1 | 10 |
| 3 | Joker | 0 | 10 |
| 4 | Batman | 1 | 5 |
+----+-----------+------+--------+Ma to sens, ponieważ dalsze aplikacje mogą używać kolumny points kolumny. Nieoczekiwany i nieobsługiwany spadek kolumny może mieć katastrofalne skutki dla dalszych potoków danych. Ryzyko polega jednak na radzeniu sobie z zaktualizowanymi informacjami, ponieważ points kolumna została usunięta z PostgreSQL i dlatego nie można jej zaktualizować.
Zmiana typu kolumny
A co ze zmianą typu kolumny? Zmiana typu kolumny może być konieczna w przypadkach, takich jak ten przykład, gdy chcemy migrować z kolumny BOOLEAN do VARCHAR dla HERO kolumny. Proszę wykonać poniższe polecenie w PostgreSQL:
ALTER TABLE USERS ALTER COLUMN HERO TYPE VARCHAR;Tak jak poprzednio, nic się nie dzieje z instrukcją DDL, ale kiedy próbujemy dodać dane przy użyciu nowej instrukcji VARCHAR typ kolumny:
INSERT INTO USERS (USERNAME, HERO) VALUES ('Panda', 'middle');Wstawianie idzie dobrze PostgreSQL zgodnie z oczekiwaniami, ale konektor źródłowy Debezium ulega awarii z następującym błędem:
ERROR "Caused by: org.apache.kafka.common.config.ConfigException: Failed to access Avro data from topic sourcepg.public.users : Incompatible schema, compatibility_mode=BACKWARD reader union lacking writer type: RECORD; error code: 409"
Backwards compatibility, old schema type is boolean (with null), new schema type is string... incompatibleDzieje się tak, ponieważ schemat jest przechowywany w Karapace z rozszerzeniem BACKWARDS ustawienie zgodności. The BACKWARDS zapewnia, że konsumenci korzystający ze starszej definicji schematu mogą korzystać ze zdarzeń utworzonych przy użyciu bieżącego schematu. Zmiana z BOOLEAN na VARCHAR może uniemożliwić starym konsumentom prawidłowe przeanalizowanie informacji, więc nie jest to dozwolone, a łącznik kończy się niepowodzeniem.
Zmiana poziomu zgodności
Na potrzeby tego przykładu proszę usunąć atrybut BACKWARDS i pozwólmy na propagację wszystkich zmian w systemie źródłowym. Ustawimy kompatybilność na NONE pozwoli to na propagację wszystkich zmian do tematu Apache Kafka.
Najpierw sprawdzamy domyślny poziom zgodności usługi Apache Kafka z:
avn service schema configuration demo-drift-kafkaTo pokazuje BACKWARD jako ustawienie domyślne. To samo ustawienie domyślne jest stosowane do sourcepg.public.users-value temat, który możemy sprawdzić:
avn service schema subject-configuration demo-drift-kafka \
--subject sourcepg.public.users-valueAby zmienić poziom zgodności na NONE zarówno dla klucza, jak i wartości, proszę uruchomić następujące polecenia:
avn service schema subject-configuration-update demo-drift-kafka \
--subject sourcepg.public.users-value \
--compatibility NONE
avn service schema subject-configuration-update demo-drift-kafka \
--subject sourcepg.public.users-key \
--compatibility NONETeraz, jeśli ponownie uruchomimy zadanie konektora Debezium Source 0 z:
avn service connector restart-task demo-drift-kafka pg-source-users 0Widzimy, że złącze źródłowe uruchamia się ponownie poprawnie. Używanie avn service connector status demo-drift-kafka pg-source-users pokazuje złącze w RUNNING stanie:
{
"status": {
"state": "RUNNING",
"tasks": [
{
"id": 0,
"state": "RUNNING",
"trace": ""
}
]
}
}Złącze zlewu JDBC do MySQL nie działa. Działa avn service connector status demo-drift-kafka cdc-sink-mysql zwraca błąd:
Caused by: org.apache.kafka.connect.errors.ConnectException: java.sql.SQLException: java.sql.BatchUpdateException: Incorrect integer value: 'middle' for column 'hero' at row 1
java.sql.SQLException: Incorrect integer value: 'middle' for column 'hero' at row 1Błąd wskazuje, że konektor próbował wstawić nową wartość (środkową) do kolumny z liczbą całkowitą. Oznacza to, że proces automatycznej ewolucji nie zmienił struktury wcześniej istniejącej kolumny.
Aby to potwierdzić, możemy wykonać describe users_mysql na bazie danych MySQL i sprawdzić, czy kolumna bohatera pozostaje tinyint.
W dokumentacji złącza zlewu JDBC, parametr auto.evolution sekcja mówi:
- Konektor nie usuwa kolumn.
- Konektor nie zmienia typów kolumn.
- Konektor nie dodaje ograniczeń kluczy podstawowych.
Mówiliśmy już o tym, że automatyczne usuwanie kolumn jest niebezpiecznym działaniem. To samo dotyczy automatycznej zmiany typów kolumn, ponieważ dalsze aplikacje mogą polegać na funkcjach, które działają specjalnie na określonych typach kolumn. Dlatego modyfikacja typu kolumny powinna być traktowana jako zmiana przerywająca, prawidłowo powodując awarię złącza zlewu.
Co z celami nierelacyjnymi? Przykład AWS S3
Opisany powyżej scenariusz jest jednym z bardziej rygorystycznych scenariuszy pod względem ewolucji danych. Zarówno źródło, jak i cel są relacyjnymi bazami danych ze ścisłymi definicjami typu kolumny. W tym drugim przykładzie zatopimy dane w kubełku S3, w którym struktura danych nie jest z góry zdefiniowana.
Możemy utworzyć łącznik zlewu do S3 z następującym plikiem konfiguracyjnym JSON przechowywanym w pliku o nazwie s3_sink.json
{
"name": "s3sink",
"connector.class": "io.aiven.kafka.connect.s3.AivenKafkaConnectS3SinkConnector",
"aws.access.key.id": "<AWS_SECRET_ID>",
"aws.secret.access.key": "<AWS_SECRET_ACCESS>",
"aws.s3.bucket.name": ">AWS_BUCKET_NAME>",
"aws.s3.region": "<AWS_REGION>",
"topics": "sourcepg.public.users",
"format.output.type": "json",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "https://<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>",
"key.converter.basic.auth.credentials.source": "USER_INFO",
"key.converter.schema.registry.basic.auth.user.info": "avnadmin:<SCHEMA_REGISTRY_PASSWORD>",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "https://<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>",
"value.converter.basic.auth.credentials.source": "USER_INFO",
"value.converter.schema.registry.basic.auth.user.info": "avnadmin:<SCHEMA_REGISTRY_PASSWORD>",
"transforms": "extract",
"transforms.extract.type": "io.debezium.transforms.ExtractNewRecordState"
}Gdzie:
- Zbiór
aws.*parametry odnoszą się do tajemnic związanych z S3, jak wyszczególniono w dokumencie dokumentacja wymagań wstępnych konektora. - The
topicsParametr definiuje źródło informacji (w szczególności parametrsourcepg.public.userstopic). - The
format.output.typeParametr określa sposób przechowywania danych (w tym przypadku jakojson). - The
key.converterorazvalue.converterumożliwiają konektorowi pobieranie informacji o schemacie z Karapace. - Parametry
transformssekcja umożliwia wyodrębnienie wartości po zmianie z formatu Debezium.
Powyższy konektor możemy uruchomić z:
avn service connector create demo-drift-kafka @s3_sink.jsonJeśli sprawdzimy dane w S3, powinniśmy zobaczyć dokument w buckecie zawierający wszystkie zmiany zaimplementowane w PostgreSQL.
[
{"value":{"id":1,"username":"Spiderman","hero":true}},
{"value":{"id":2,"username":"Flash","hero":true}},
{"value":{"id":3,"username":"Joker","hero":false}},
{"value":{"id":4,"username":"Batman","hero":true}},
{"value":{"id":1,"username":"Spiderman","hero":true,"points":10}},
{"value":{"id":2,"username":"Flash","hero":true,"points":10}},
{"value":{"id":3,"username":"Joker","hero":false,"points":10}},
{"value":{"id":4,"username":"Batman","hero":true,"points":5}},
{"value":{"id":5,"username":"Panda","hero":"middle"}}
]Dane wyjściowe z przepływu CDC -> Kafka -> S3 obejmują wszystkie zdarzenia. Ze względu na ustawienie trybu zgodności Debezium na NONE, każda zmiana jest pomyślnie zapisywana w Kafce. Co więcej, ponieważ S3 nie wymusza określonej struktury danych, wszystkie zmiany, niezależnie od tego, czy dotyczą nowych, czy usuniętych kolumn, zostały zapisane w docelowym buckecie w formacie JSON.
Zakończenie usług
Jeśli postępowali Państwo zgodnie z tym samouczkiem i chcą usunąć usługi używane do testowania, można uruchomić poniższe polecenia:
avn service terminate demo-drift-postgresql --force
avn service terminate demo-drift-kafka --force
avn service terminate demo-drift-mysqldb --forcePodsumowanie
Dryf danych i schematów musi być zarządzany w scenariuszach, w których wielu konsumentów chce uzyskać dostęp do zmian zachodzących w systemie źródłowym. Apache Kafka i rejestr schematów Karapace zapewniają metodę propagacji zgodnych zmian i zabraniają ich łamania poprzez zatrzymanie potoku. Proszę zwrócić szczególną uwagę na usuwanie kolumn, ponieważ nie są one automatycznie propagowane do systemów docelowych (zwłaszcza jeśli celem jest inna relacyjna baza danych) i mogą powodować problemy z aktualizacją danych w usuniętych kolumnach.
Podsumowując, w jaki sposób propagowane są zmiany:
| Działanie | Status | Opis |
|---|---|---|
| Proszę dodać kolumnę | ✅ | Propaguje w dół rzeki, jeśli auto.evolve jest ustawiony na true. |
| Proszę usunąć kolumnę | ⚠️ | Nie propaguje się w dół w przypadku spadku do relacyjnej bazy danych. Możliwe użycie nieaktualnych danych dla usuniętej kolumny. |
| Zmiana typu danych | ⚠️ | Zależy od zmiany, ustawień zgodności i technologii docelowej. Nie propagowane w przypadku JDBC sink. |
Podsumowanie zgodności rejestru schematów:
BACKWARDSumożliwia zatrzymanie potoku przed wprowadzeniem danych do Kafki, ponieważ zmiany naruszające nie zostaną uwzględnione w temacieNONEpozwala kontynuować pozyskiwanie danych, ale może zepsuć potoki danych niższego szczebla, jeśli technologia niższego szczebla jest relacyjna lub ma precyzyjną definicję kolumny, a ewolucja nie jest prosta.