
Lekki i otwarty protokół przesyłania wiadomości IoT MQTT został szerzej przyjęty w różnych branżach. W tym wpisie na blogu omówiono istotne trendy rynkowe dla MQTT: wdrożenia w chmurze i w pełni zarządzane usługi, zarządzanie danymi dzięki ujednoliconej przestrzeni nazw i Sparkplug B, debaty MQTT vs. OPC-UA oraz integrację z Apache Kafka w celu przetwarzania danych OT/IT w czasie rzeczywistym.

Szczyt MQTT w Monachium
W grudniu 2023 roku wziąłem udział w MQTT Summit Connack. Sponsorem wydarzenia była firma HiveMQ. Program obejmował różnych ekspertów branżowych. Rozmowy dotyczyły przemysłowych wdrożeń IoT, ujednoliconej przestrzeni nazw, Sparkplug B, bezpieczeństwa i zarządzania flotą oraz przypadków użycia Kafki w połączeniu z MQTT, takich jak połączone pojazdy lub inteligentne miasta (moje wystąpienie).
Z przyjemnością spotkałem wielu przedstawicieli społeczności MQTT, niezależnych konsultantów i dostawców oprogramowania. Dowiedziałem się wiele o adopcji MQTT w prawdziwym świecie, najlepszych praktykach i kilku kompromisach Sparkplug B. Poniższe sekcje podsumowują moje trendy dla MQTT z tego wydarzenia w połączeniu z doświadczeniami, które miałem w tym roku na spotkaniach z klientami na całym świecie.
Specjalne podziękowania dla Kudzai Manditereza z HiveMQ za zorganizowanie tego wspaniałego wydarzenia z udziałem wielu międzynarodowych uczestników z różnych branż:
Co to jest MQTT?
MQTT to skrót od Message Queuing Telemetry Transport. MQTT to lekki i otwarty protokół przesyłania wiadomości przeznaczony dla małych czujników i urządzeń mobilnych z dużymi opóźnieniami lub zawodnymi sieciami. IBM pierwotnie opracował MQTT pod koniec lat 90-tych, a później stał się otwartym standardem.
MQTT opiera się na modelu publikuj/subskrybuj, w którym urządzenia (lub klienci) komunikują się za pośrednictwem centralnego brokera wiadomości. Kluczowymi komponentami MQTT są:
- Klient: Urządzenie lub aplikacja, która łączy się z brokerem MQTT w celu wysyłania lub odbierania wiadomości.
- Broker: Centralny węzeł zarządzający komunikacją między klientami. Odbiera wiadomości od klientów publikujących i kieruje je do klientów subskrybujących na podstawie tematów.
- Temat: Hierarchiczny ciąg znaków, który działa jako etykieta dla wiadomości. Klienci subskrybują tematy, aby otrzymywać wiadomości i publikować wiadomości do określonych tematów.
Kiedy używać MQTT
Model publikowania/subskrybowania pozwala na wydajną komunikację między urządzeniami. Gdy klient publikuje wiadomość do określonego tematu, wszyscy inni klienci subskrybujący ten temat otrzymują wiadomość. Oddziela to nadawcę i odbiorcę, umożliwiając skalowalny i elastyczny system komunikacji.
Standard MQTT jest znany ze swojej prostoty, niskiego wykorzystania przepustowości i obsługi niewiarygodnych sieci. Te cechy sprawiają, że dobrze nadaje się do zastosowań Internetu rzeczy (IoT), gdzie urządzenia często mają ograniczone zasoby i mogą działać w trudnych warunkach sieciowych. Dobre implementacje MQTT zapewniają skalowalną i niezawodną platformę dla projektów IoT.
MQTT zyskał szerokie zastosowanie w różnych branżach do wdrożeń IoT, automatyki domowej i innych scenariuszy wymagających lekkiej i wydajnej komunikacji.
W kolejnych sekcjach omówię następujące cztery trendy rynkowe dla MQTT. Mają one ogromny wpływ na przyjęcie i podjęcie decyzji o wyborze MQTT:
- MQTT w chmurze publicznej
- Zarządzanie danymi dla MQTT
- Debaty MQTT vs. OPC-UA
- MQTT i Apache Kafka dla przetwarzania danych OT/IT
Trend 1: MQTT w chmurze publicznej
Większość firm ma strategię opartą na chmurze. Proszę przejść na rozwiązania bezserwerowe! Skupienie się na problemach biznesowych, szybsze wprowadzanie produktów na rynek i elastyczna infrastruktura to tego konsekwencje.
Istnieją dojrzałe usługi MQTT w chmurze. W Confluent dużo pracujemy z HiveMQ. Połączenie to zapewnia nawet w pełni zarządzaną integrację między obiema ofertami chmurowymi.
To powiedziawszy, nie wszystko może lub powinno trafić do (publicznej) chmury. Bezpieczeństwo, opóźnienia i koszty często sprawiają, że preferowaną lub obowiązkową opcją jest wdrożenie w centrum danych lub na brzegu sieci (np. w inteligentnej fabryce). Architektury hybrydowe umożliwiają połączenie obu opcji w celu zbudowania najbardziej opłacalnej, ale także niezawodnej i bezpiecznej infrastruktury IoT.
Automatyzacja i bezpieczeństwo to typowe czynniki blokujące chmurę publiczną
Kluczem do sukcesu, zwłaszcza w architekturach hybrydowych, jest automatyzacja i zarządzanie flotą za pomocą CI/CD i GitOps do zarządzania wieloma klastrami. Wiele projektów wykorzystuje Kubernetes jako natywną infrastrukturę chmurową dla brzegu sieci i chmury prywatnej. Jednak w chmurze publicznej pierwszą opcją powinna być zawsze w pełni zarządzana usługa (jeśli pozwalają na to wymogi bezpieczeństwa i inne).
Proszę zachować ostrożność przy wdrażaniu w pełni zarządzanych usług MQTT w chmurze: Wsparcie dla MQTT nie zawsze jest jednakowe u różnych dostawców usług w chmurze. Wielu dostawców nie implementuje całego protokołu, pomija funkcje i wymaga ograniczeń użytkowania. HiveMQ napisał świetny artykuł pokazujący to. Artykuł jest nieco przestarzały (i oczywiście opiniotwórczy, jako konkurencyjny dostawca MQTT). Ale bardzo dobrze pokazuje, jak niektórzy dostawcy zapewniają oferty, które są dalekie od dobrego rozwiązania chmurowego MQTT.
Najtrudniejszym problemem związanym z przyjęciem MQTT w chmurze publicznej jest bezpieczeństwo! Proszę dokładnie sprawdzić wymagania na wczesnym etapie. Opóźnienia, dostępność lub określone funkcje zwykle nie stanowią problemu. Wdrożenie i integracja muszą być zgodne ze strategią chmury. Ponieważ przemysłowe projekty IoT zawsze muszą zawierać jakąś historię brzegową, jest to trudniejsza dyskusja niż w przypadku projektów sprzedażowych lub marketingowych.
Trend 2: Zarządzanie danymi dla MQTT
Zarządzanie danymi ma kluczowe znaczenie w całym przedsiębiorstwie. Z perspektywy IoT i MQTT dwa główne tematy to ujednolicona przestrzeń nazw jako koncepcja i Sparkplug B jako technologia.
Ujednolicona przestrzeń nazw dla przemysłowego IoT
W kontekście Przemysłowego Internetu Rzeczy (IIoT), ujednolicona przestrzeń nazw (UNS) zazwyczaj odnosi się do znormalizowanego i spójnego sposobu nazywania i organizowania urządzeń, danych i zasobów w ramach sieci przemysłowej lub ekosystemu. Celem jest zapewnienie spójnej struktury nazewnictwa, która ułatwia interoperacyjność, udostępnianie danych i zarządzanie urządzeniami i systemami IIoT.
Termin Unified Namespace (w przemysłowym IoT) został wymyślony i spopularyzowany przez Walker Reynolds, ekspert i twórca treści dla Industrial IoT.
Koncepcje ujednoliconej przestrzeni nazw
Oto kilka kluczowych aspektów ujednoliconej przestrzeni nazw w przemysłowym IoT:
- Nazewnictwo urządzeń: Urządzenia w środowisku IIoT mogą pochodzić od różnych producentów i mieć różne funkcje. Ujednolicona przestrzeń nazw zapewnia spójne nazewnictwo urządzeń, ułatwiając administratorom, aplikacjom i innym urządzeniom ich identyfikację i interakcję z nimi.
- Nazewnictwo i tagowanie danych: IIoT wiąże się z generowaniem i wymianą ogromnych ilości danych. Ujednolicona przestrzeń nazw obejmuje znormalizowane konwencje nazewnictwa i mechanizmy tagowania punktów danych, zmiennych lub atrybutów powiązanych z urządzeniami. Spójność ta ma kluczowe znaczenie dla aplikacji, które muszą uzyskiwać dostęp do danych i interpretować je na różnych urządzeniach.
- Interoperacyjność: Ujednolicona przestrzeń nazw promuje interoperacyjność, zapewniając wspólne ramy dla urządzeń i systemów do komunikacji. Gdy urządzenia i aplikacje stosują te same konwencje nazewnictwa, łatwiej jest zintegrować nowe urządzenia z istniejącymi systemami lub wymienić komponenty bez powodowania zakłóceń.
- Bezpieczeństwo i kontrola dostępu: Dobrze zdefiniowana przestrzeń nazw przyczynia się do bezpieczeństwa, umożliwiając skuteczne mechanizmy kontroli dostępu. Zasady bezpieczeństwa mogą być wdrażane w oparciu o znormalizowane nazwy i hierarchie, zapewniając, że tylko upoważnione podmioty mogą uzyskać dostęp do określonych urządzeń lub danych.
- Zarządzanie i skalowalność: W środowiskach przemysłowych na dużą skalę posiadanie ujednoliconej przestrzeni nazw upraszcza zarządzanie urządzeniami i zasobami. Pozwala to na skalowalne rozwiązania, w których nowe urządzenia mogą być dodawane lub wymieniane bez konieczności znacznej rekonfiguracji.
- Semantyczna interoperacyjność: Poza samym nazewnictwem, ujednolicona przestrzeń nazw może obejmować definicje i standardy semantyczne. Pomaga to w osiągnięciu interoperacyjności semantycznej, zapewniając, że urządzenia i systemy rozumieją znaczenie i kontekst wymienianych danych.
Ogólnie rzecz biorąc, ujednolicona przestrzeń nazw w przemysłowym IoT polega na ustanowieniu wspólnej i znormalizowanej struktury nazewnictwa urządzeń, danych i zasobów, zapewniając podstawę dla wydajnych, bezpiecznych i skalowalnych wdrożeń IIoT. Organizacje normalizacyjne i konsorcja branżowe często odgrywają rolę w opracowywaniu i promowaniu tych standardów, aby zapewnić powszechne przyjęcie i kompatybilność w różnych ekosystemach przemysłowych.
Sparkplug B: Interoperacyjność i ustandaryzowana komunikacja dla tematów i ładunków MQTT
Unified Namespace to teoretyczna koncepcja interoperacyjności. Standardową implementacją wymuszania struktury ładunku jest Sparkplug B. Jest to specyfikacja stworzona w Eclipse Foundation i przekształcona później w standard ISO.
Sparkplug B zapewnia zestaw konwencji do organizowania danych i definiowania wspólnego języka dla urządzeń do wymiany informacji. Oto przykład przykład HiveMQ obrazujący, w jaki sposób ujednolicona przestrzeń nazw ułatwia komunikację między urządzeniami, systemami i witrynami:
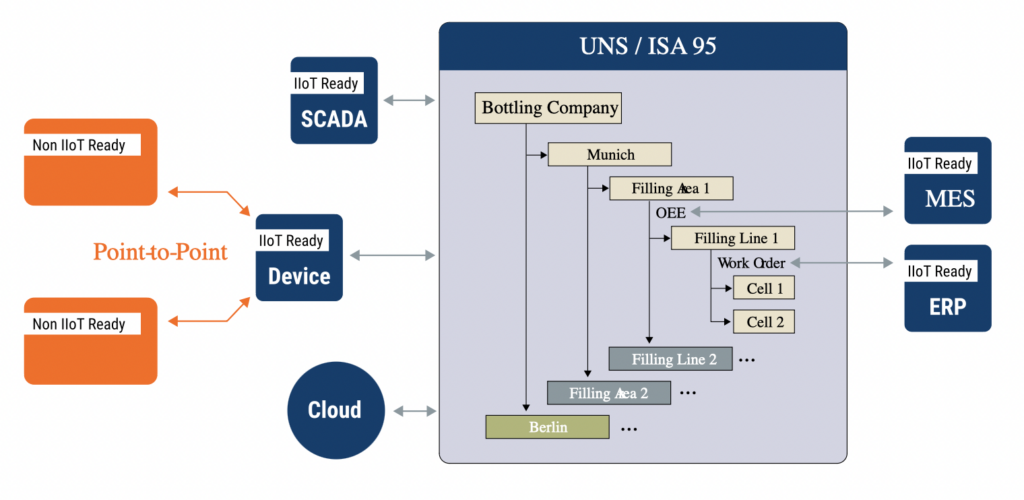 Źródło: HiveMQ
Źródło: HiveMQ
Kluczowe cechy Sparkplug B obejmują:
- Struktura ładunku: Sparkplug B definiuje określony format ładunku wiadomości MQTT. Format ten obejmuje pola na informacje, takie jak znaczniki czasu, typy danych i wartości. Ta znormalizowana struktura ładunku zapewnia, że urządzenia mogą konsekwentnie rozumieć i interpretować wymieniane dane.
- Przestrzeń nazw tematu: Specyfikacja definiuje ustandaryzowaną przestrzeń nazw tematów dla komunikatów MQTT. Pomaga to w organizowaniu i kategoryzowaniu wiadomości, ułatwiając urządzeniom odkrywanie i subskrybowanie odpowiednich informacji.
- Akty urodzenia i zgonu: Sparkplug B wprowadza koncepcję certyfikatów “narodzin” i “śmierci” dla urządzeń. Gdy urządzenie przechodzi w tryb online, wysyła certyfikat narodzin z informacjami o sobie. I odwrotnie, gdy urządzenie przechodzi w tryb offline, wysyła certyfikat śmierci. Mechanizm ten pomaga w monitorowaniu stanu urządzeń w sieci IIoT.
- Zarządzanie stanem: Specyfikacja obejmuje funkcje zarządzania stanem urządzeń. Urządzenia mogą publikować swój bieżący stan, a inne urządzenia mogą subskrybować otrzymywanie aktualizacji. Pomaga to w utrzymaniu zsynchronizowanego widoku stanów urządzeń w całej sieci.
Sparkplug B ma na celu zwiększenie interoperacyjności, skalowalności i wydajności wdrożeń IIoT poprzez zapewnienie znormalizowanej struktury komunikacji MQTT w środowiskach przemysłowych. Jego przyjęcie może uprościć integrację różnych urządzeń i systemów w ekosystemie przemysłowym, promując płynną komunikację i wymianę danych.
Ograniczenia Sparkplug B
Sparkplug B ma kilka ograniczeń, takich jak:
Proszę zrozumieć zalety i wady Sparkplug B. Jest on idealny dla niektórych przypadków użycia. Ale powyższe ograniczenia są blokadami dla niektórych innych. W szczególności, tylko obsługa QoS 0 jest ogromnym ograniczeniem dla krytycznych przypadków użycia.
Trend 3: Debaty MQTT vs. OPC-UA
MQTT ma wiele zalet w porównaniu z innymi protokołami przemysłowymi. Jednak OPC-UA to kolejny standard w przestrzeni IoT, który zyskuje co najmniej taką samą popularność na rynku jak MQTT. Debata na temat wyboru odpowiedniego standardu IoT jest kontrowersyjna, często kierowana emocjami i opiniami, i nadal jest absolutnie ważna do omówienia.
OPC-UA (Open Platform Communications Unified Architecture) to protokół komunikacyjny machine-to-machine dla automatyki przemysłowej. Umożliwia on płynną i bezpieczną komunikację oraz wymianę danych pomiędzy urządzeniami i systemami w różnych środowiskach przemysłowych.
OPC UA stał się powszechnie przyjętym standardem w dziedzinie automatyki przemysłowej i sterowania, zapewniając podstawę dla bezpiecznej i interoperacyjnej komunikacji między urządzeniami, maszynami i systemami. Jego otwarty charakter i wsparcie ze strony organizacji branżowych przyczyniają się do jego szerokiego zastosowania w różnych aplikacjach, od produkcji i kontroli procesów po zarządzanie energią i nie tylko.
Jeśli spojrzeć na obietnice MQTT i OPC-UA, wiele się pokrywa:
- Skalowalność
- Niezawodny
- W czasie rzeczywistym
- Otwarte
- Standaryzacja
Wszystkie z nich są prawdziwe dla obu standardów. Mimo to istnieją kompromisy. Nie rozpocznę tutaj wojny płomieni. Proszę wyszukać “MQTT vs. OPC-UA”. Znajdą Państwo wiele wpisów na blogach, artykułów i filmów. Większość z nich jest bardzo opiniotwórcza (i często napędzana przez dostawcę). W rzeczywistości branża szeroko przyjęła zarówno MQTT, jak i OPC-UA.
I chociaż powyższe cechy mogą być prawdziwe dla obu standardów w ogóle, szczegóły mają znaczenie dla konkretnych wdrożeń. Na przykład, jeśli spróbuje Pan połączyć wiele sterowników PLC Siemens S3 za pośrednictwem OPC-UA, szybko zda Pan sobie sprawę, że liczba równoległych połączeń nie jest tak skalowalna, jak mówi specyfikacja standardu OPC-UA.
Kiedy wybrać MQTT vs. OPC-UA?
Wyraźnym zaleceniem jest rozpoczęcie od problemu biznesowego, a nie technologii. Proszę ocenić oba standardy i ich implementacje, obsługiwane interfejsy, usługi chmurowe dostawców itp. Następnie proszę wybrać odpowiednią technologię.
Oto, czego używam jako uproszczonej zasady, jeśli muszą Państwo rozpocząć dyskusję techniczną:
- MQTT: Przypadki użycia dla podłączonych urządzeń IoT, pojazdów i innych interfejsów z obsługą lekkiej infrastruktury, dużej liczby połączeń i/lub złych sieci.
- OPC-UA: Przypadki użycia w automatyce przemysłowej do łączenia ciężkiego sprzętu, sterowników PLC, systemów SCADA, rejestratorów danych itp.
To tylko ogólna zasada. Sytuacja się zmienia. Nowoczesne sterowniki PLC i inny sprzęt dodają obsługę wielu protokołów, aby być bardziej elastycznym. Ale w dzisiejszych czasach i tak rzadko mają Państwo wybór, ponieważ określony sprzęt, urządzenia lub pojazdy obsługują tylko jeden lub drugi protokół. I nadal mogą być Państwo zadowoleni: W przeciwnym razie trzeba użyć innej platformy IIoT, aby połączyć się z zastrzeżonymi starszymi protokołami, takimi jak S3, Modbus itp.
Problemy MQTT i OPC-UA
Kilka dodatkowych problemów, z których zdałem sobie sprawę podczas różnych rozmów z klientami na całym świecie w ostatnich kwartałach:
- Teoretycznie MQTT i OPC-UA dobrze ze sobą współpracują, tzn. MQTT jest podstawowym protokołem transportowym dla OPC-UA. Nie widziałem tego jeszcze w prawdziwym świecie (brak dowodów statystycznych, tylko moje osobiste doświadczenie). Ale to, co widzę, to połączenie OPC-UA do integracji ostatniej mili ze sterownikiem PLC, a następnie przekazywanie danych do innych odbiorców za pośrednictwem MQTT. Wszystko w jednej bramie, zwykle zastrzeżonej platformie IoT.
- OPC-UA definiuje wiele podstandardów dla różnych branż lub przypadków użycia. W teorii jest to świetne rozwiązanie. W praktyce widzę to bardziej jak piekło WS-* w świecie usług internetowych SOAP/WSDL, gdzie większość projektów przeniosła się na znacznie prostsze architektury HTTP/REST. Podobnie, większość integracji z OPC-UA wykorzystuje proste, niestandardowe klienty w Javie lub innych językach programowania – ponieważ narzędzia nie obsługują złożonych standardów.
- Sprzedawcy IoT przedstawiają w marketingu wszelkie możliwe scenariusze integracji. Jestem zdumiony, że platformy MQTT i OPC-UA bezpośrednio integrują się z systemami MES i ERP, takimi jak SAP, oraz dowolną hurtownią danych i jeziorem danych, takimi jak Google Big Query, Snowflake lub Databricks. Ale to tylko teoria. Czy naprawdę powinni Państwo to robić? I czy kiedykolwiek próbował Pan podłączyć SAP ECC do MQTT lub OPC-UA? Powodzenia z technicznego, a jeszcze trudniej z organizacyjnego punktu widzenia. Czy chcą Państwo ścisłego połączenia i komunikacji punkt-punkt między światem OT a ERP? W większości przypadków dobrze jest mieć wyraźny rozdział pomiędzy różnymi jednostkami biznesowymi, domenami i przypadkami użycia. Proszę wybrać odpowiednie narzędzie i architekturę korporacyjną; nie tylko dla POC i pierwszego rurociągu, ale dla całej długoterminowej strategii i wizji.
Ostatni punkt prowadzi mnie do kolejnego rosnącego trendu: Połączenie MQTT dla obciążeń IoT / OT i strumieniowego przesyłania danych z Apache Kafka w celu integracji ze światem IT.
Trend 4: MQTT i Apache Kafka dla przetwarzania danych OT/IT
W przeciwieństwie do MQTT, Apache Kafka NIE jest platformą IoT. Zamiast tego, Kafka jest platformą do strumieniowego przesyłania zdarzeń i wykorzystuje podstawę architektury sterowanej zdarzeniami dla różnych przypadków użycia w różnych branżach. Zapewnia skalowalną, niezawodną i elastyczną platformę czasu rzeczywistego do przesyłania wiadomości, przechowywania, integracji danych i przetwarzania strumieniowego. Apache Kafka i MQTT to idealne połączenie dla wielu przypadków użycia IoT.
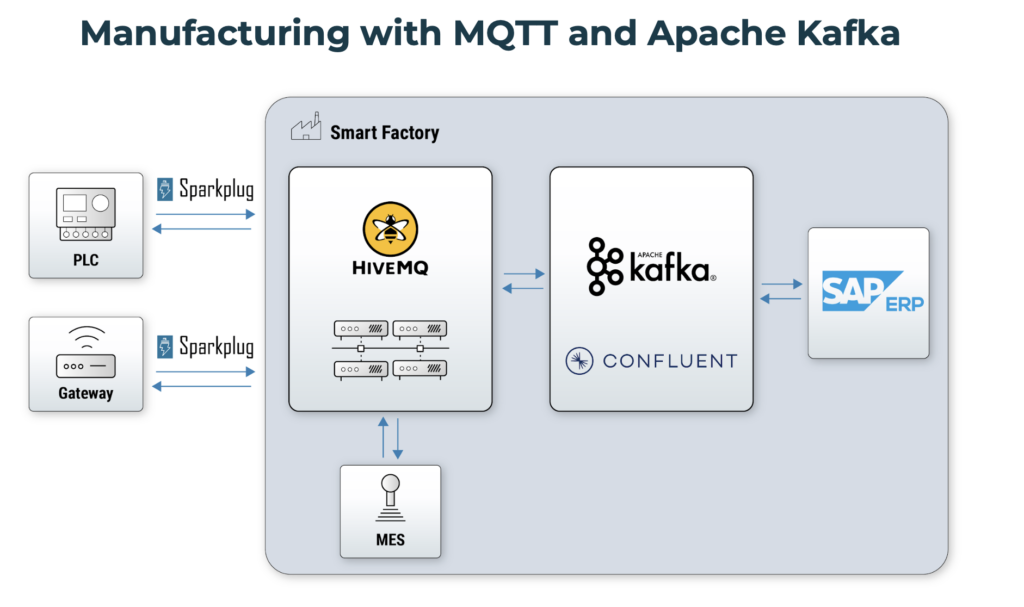
Przyjrzyjmy się zaletom i wadom obu technologii z perspektywy IoT.
Wady i zalety MQTT
Zalety MQTT:
- Lekki
- Zbudowany dla tysięcy połączeń
- Obsługiwane wszystkie języki programowania
- Zbudowany dla scenariuszy słabej łączności / dużych opóźnień
- Wysoka skalowalność i dostępność (w zależności od implementacji brokera) – standard ISO
- Najpopularniejszy protokół IoT (konkurujący z OPC UA)
Wady MQTT:
- Przyjęcie głównie w przypadkach użycia IoT
- Tylko pub/sub, nie przetwarzanie strumieniowe
- Brak ponownego przetwarzania zdarzeń
Wady i zalety Apache Kafka
Zalety Kafki:
- Przetwarzanie strumieniowe, nie tylko pub/sub
- Wysoka przepustowość
- Duża skala
- Wysoka dostępność
- Długoterminowe przechowywanie i buforowanie
- Ponowne przetwarzanie zdarzeń
- Dobra integracja z resztą przedsiębiorstwa
Wady Kafki:
- Nie zbudowany dla dziesiątek tysięcy połączeń
- Wymaga stabilnej sieci i dobrej infrastruktury
- Brak funkcji specyficznych dla IoT, takich jak podtrzymywanie przy życiu, ostatnia wola lub testament.
Przypadki użycia, architektury i studia przypadków dla MQTT i Kafka
Napisałem serię blogów o MQTT w połączeniu z Apache Kafka z wieloma szczegółami technicznymi i rzeczywistymi studiami przypadków z różnych branż.
Pierwszy wpis na blogu bada związek między MQTT i Apache Kafka. Pozostałe cztery wpisy na blogu omawiają różne przypadki użycia, architektury i wdrożenia referencyjne.
- Część 1 – Przegląd: Związek między Kafka i MQTT, zalety i wady, architektury
- Część 2 – Połączone pojazdy: MQTT i Kafka w prywatnej chmurze na Kubernetes; przypadek użycia: zdalna kontrola i sterowanie samochodem
- Część 3 – Produkcja: MQTT i Kafka na krawędzi w inteligentnej fabryce; przypadek użycia: Dwukierunkowa integracja OT-IT z Sparkplug B pomiędzy PLC, bramami IoT, Data Historian, MES, ERP, Data Lake, itp.
- Część 4 – Usługi mobilne: MQTT i Kafka wykorzystujące bezserwerową infrastrukturę chmury; przypadek użycia: Usługa przewidywania korków z wykorzystaniem uczenia maszynowego
- Część 5 – Inteligentne miasto: MQTT na brzegu połączony z w pełni zarządzaną Kafką w chmurze publicznej; przypadek użycia: Inteligentne kierowanie ruchem poprzez łączenie i korelowanie różnych usług 1. i 3. strony.
Poniższa prezentacja pochodzi z mojego wystąpienia na MQTT Summit. Omawia ona różne przypadki użycia i architektury referencyjne dla MQTT i Apache Kafka:
[pvfw-embed viewer_id=”5956″ width=”100%” height=”800″]
Jeśli mają Państwo słabą sieć, dziesiątki tysięcy klientów lub potrzebują lekkiego rozwiązania do przesyłania wiadomości opartego na push, to MQTT jest właściwym wyborem. Gdzie indziej, Kafka, potężna platforma strumieniowania zdarzeń, jest prawdopodobnie właściwym wyborem do przesyłania wiadomości w czasie rzeczywistym, integracji danych i przetwarzania danych. W wielu przypadkach zastosowań IoT architektura łączy obie technologie. Nawet w przestrzeni przemysłowej, różne projekty wykorzystują Kafkę do takich zastosowań jak budowanie natywnego dla chmury historyka danych lub rmonitorowanie stanu w czasie rzeczywistym i konserwacja predykcyjna.
Zarządzanie danymi dla MQTT za pomocą Sparkplug i Kafka (i nie tylko)
Unified Namespace i konkretna implementacja ze Sparkplug B doskonale nadają się do zarządzania danymi w obciążeniach IoT z MQTT. W podobny sposób Schema Registry definiuje umowy dotyczące danych dla potoków danych Apache Kafka.
Schema Registry powinien być podstawą każdego projektu Kafka! Kontrakty danych (aka schematy, podobne do Swagger w interfejsach API REST/HTTP) wymuszają dobrą jakość danych i interoperacyjność między niezależnymi mikrousługami w ekosystemie Kafka. Każda jednostka biznesowa i jej produkty danych mogą wybrać dowolną technologię lub API. Jednak udostępnianie danych innym działa tylko przy dobrej (wymuszonej) jakości danych.
Widzą Państwo problem: Każda technologia wykorzystuje własną technologię zarządzania danymi. Jeśli doda Pan swoje ulubione jezioro danych, doda Pan kolejną koncepcję, taką jak Apache Iceberg, aby zdefiniować tabele danych dla systemów przechowywania danych analitycznych. I to jest w porządku! Każdy pakiet zarządzania danymi jest zoptymalizowany pod kątem obciążeń i wymagań. Zarządzanie danymi podstawowymi w całej firmie nie sprawdziło się w ciągu ostatnich dwóch dekad, ponieważ każda kategoria oprogramowania ma inne wymagania.
Dlatego jednym z wyraźnych trendów, które widzę, jest strategia zarządzania danymi w całym przedsiębiorstwie w różnych systemach (z technologiami takimi jak Collibra lub Azure Purview). Mają one otwarte interfejsy i integrują się z określonymi umowami dotyczącymi danych, takimi jak Sparkplug B dla MQTT, Schema Registry dla Kafki, Swagger dla aplikacji HTTP/REST lub Iceberg dla jezior danych. Proszę nie próbować rozwiązywać całej strategii zarządzania danymi w całym przedsiębiorstwie za pomocą jednej technologii. To się nie uda! Widzieliśmy to już wcześniej…
Starsze sterowniki PLC (S7, Modbus, BACnet itp.) z MQTT lub Kafka?
MQTT i Kafka umożliwiają niezawodne i skalowalne potoki danych typu end-to-end między IoT a systemami IT. Przynajmniej, jeśli mogą Państwo korzystać z nowoczesnych interfejsów API i standardów. Większość dzisiejszych projektów IoT to wciąż projekty typu brownfield. Wiele starszych sterowników PLC, systemów SCADA i archiwizatorów danych obsługuje tylko zastrzeżone protokoły, takie jak Siemens S7, Modbus, BACnet itp.
MQTT lub Kafka nie obsługują tych starszych protokołów od razu po wyjęciu z pudełka. Wymagane jest inne oprogramowanie pośredniczące. Zazwyczaj przedsiębiorstwa wybierają w tym celu dedykowaną platformę IoT. Oznacza to większe koszty i złożoność, a także wolniejsze projekty.
W świecie Kafki, Apache PLC4X jest świetną opcją open-source, jeśli chcą Państwo zbudować platformę IoT. nowoczesnego, natywnego dla chmury historyka danych z Kafką. Framework zapewnia integrację z wieloma starszymi protokołami. Oferuje również konektor Kafka Connect. Głównym problemem jest brak oficjalnego wsparcia producenta. Firmy nie mogą kupić wsparcia w modelu biznesowym 24/7 dla aplikacji o znaczeniu krytycznym. A to zazwyczaj stanowi blokadę dla wszelkich wdrożeń przemysłowych.
Ponieważ MQTT jest tylko brokerem komunikatów pub/sub, nie może pomóc w integracji starszych protokołów. HiveMQ próbuje rozwiązać to wyzwanie za pomocą nowego frameworka o nazwie HiveMQ Edge: Oparty na oprogramowaniu przemysłowy konwerter protokołów brzegowych. Jest to młody projekt, który dopiero raczkuje. Rdzeń jest open source. Pierwszym obsługiwanym protokołem jest Modbus. Uważam, że jest to doskonała strategia produktowa. Mam nadzieję, że projekt zyska na popularności i będzie ewoluował w kierunku obsługi wielu innych starszych technologii IIoT w celu modernizacji hali produkcyjnej. Projekt faktycznie obsługuje również OPC-UA. Zobaczymy, jak duże będzie zapotrzebowanie na tę funkcję.
Przyjęcie MQTT i Sparkplug rośnie z roku na rok dla przypadków użycia IoT
W świecie IoT, MQTT i OPC UA ugruntowały swoją pozycję jako otwarte i niezależne od platformy standardy wymiany danych w zastosowaniach przemysłowych IoT i Industry 4.0. Strumieniowe przesyłanie danych za pomocą Apache Kafka to centrum danych do integracji i przetwarzania ogromnych ilości danych w dowolnej skali w czasie rzeczywistym. “Trinity of Data Streaming in IoT bada połączenie MQTT, OPC-UA i Apache Kafka.” bardziej szczegółowo.
Przyjęcie MQTT rośnie z roku na rok wraz z potrzebą bardziej skalowalnej, niezawodnej i otwartej komunikacji IoT między urządzeniami, sprzętem, pojazdami i zapleczem IT. Najlepszymi punktami MQTT są zawodne sieci, lekka (ale niezawodna i skalowalna) komunikacja i infrastruktura oraz łączność z tysiącami urządzeń.
Dojrzewające trendy, takie jak Unified Namespace ze Sparkplug B, w pełni zarządzane usługi w chmurze i połączone wykorzystanie z Apache Kafka sprawiają, że MQTT jest jednym z najbardziej istotnych standardów IoT w branżach takich jak produkcja, motoryzacja, lotnictwo, logistyka i inteligentne miasta.
Proszę jednak nie dać się zwieść obrazkom architektonicznym i teorii. Na przykład, większość diagramów dla MQTT i Sparkplug pokazuje integrację z ERP (np. SAP) i Data Lake (np. Snowflake). Czy naprawdę powinni Państwo integrować się bezpośrednio ze świata OT z platformą analityczną? W większości przypadków odpowiedź brzmi “nie” ze względu na koszty, oddzielenie jednostek biznesowych, kwestie prawne i inne powody. To właśnie tutaj połączenie MQTT i Kafka (lub innej platformy integracyjnej) jest najlepszym rozwiązaniem.
Jak obecnie wykorzystują Państwo MQTT i Sparkplug? Jakie są przypadki użycia? Czy łączą je Państwo z innymi technologiami, takimi jak Apache Kafka, w celu zapewnienia kompleksowej integracji w potoku OT/IT? Proszę proszę połączyć się na LinkedIn i proszę dyskutować! Dołącz do społeczności streamingu danych i bądź na bieżąco z nowymi wpisami na blogu dzięki subskrybując mój newsletter.