
W stale ewoluującym krajobrazie branży usług finansowych (FSI) organizacje stoją przed wieloma wyzwaniami, które utrudniają ich podróż w kierunku transformacji opartej na sztucznej inteligencji. Starsze systemy, rygorystyczne przepisy, silosy danych i brak elastyczności stworzyły chaotyczne środowisko, które potrzebuje bardziej efektywnego sposobu wykorzystywania i udostępniania danych w całej organizacji.
W tej dwuczęściowej serii zagłębię się w moje osobiste obserwacje, przełamię dominujące problemy w FSI i dokładnie przeanalizuję czynniki hamujące postęp. Podkreślę również potrzebę integracji starszych systemów, poruszania się w ścisłym otoczeniu regulacyjnym i rozbijania silosów danych, które utrudniają sprawność i utrudniają podejmowanie decyzji opartych na danych.
Na koniec przedstawię sprawdzone podejście do strategii danych, w którym przyjęcie technologii strumieniowego przesyłania danych pomoże organizacjom zmodernizować ich potoki danych – umożliwiając pozyskiwanie danych w czasie rzeczywistym, wydajne przetwarzanie i płynną integrację różnych systemów. Jeśli są Państwo zainteresowani praktycznym przypadkiem użycia, który pokazuje wszystko w akcji, proszę zwrócić uwagę na nasz nadchodzący raport.
Zanim jednak przejdziemy do rozwiązania, proszę zacząć od zrozumienia problemu.
Złożoność, chaos i dylematy związane z danymi
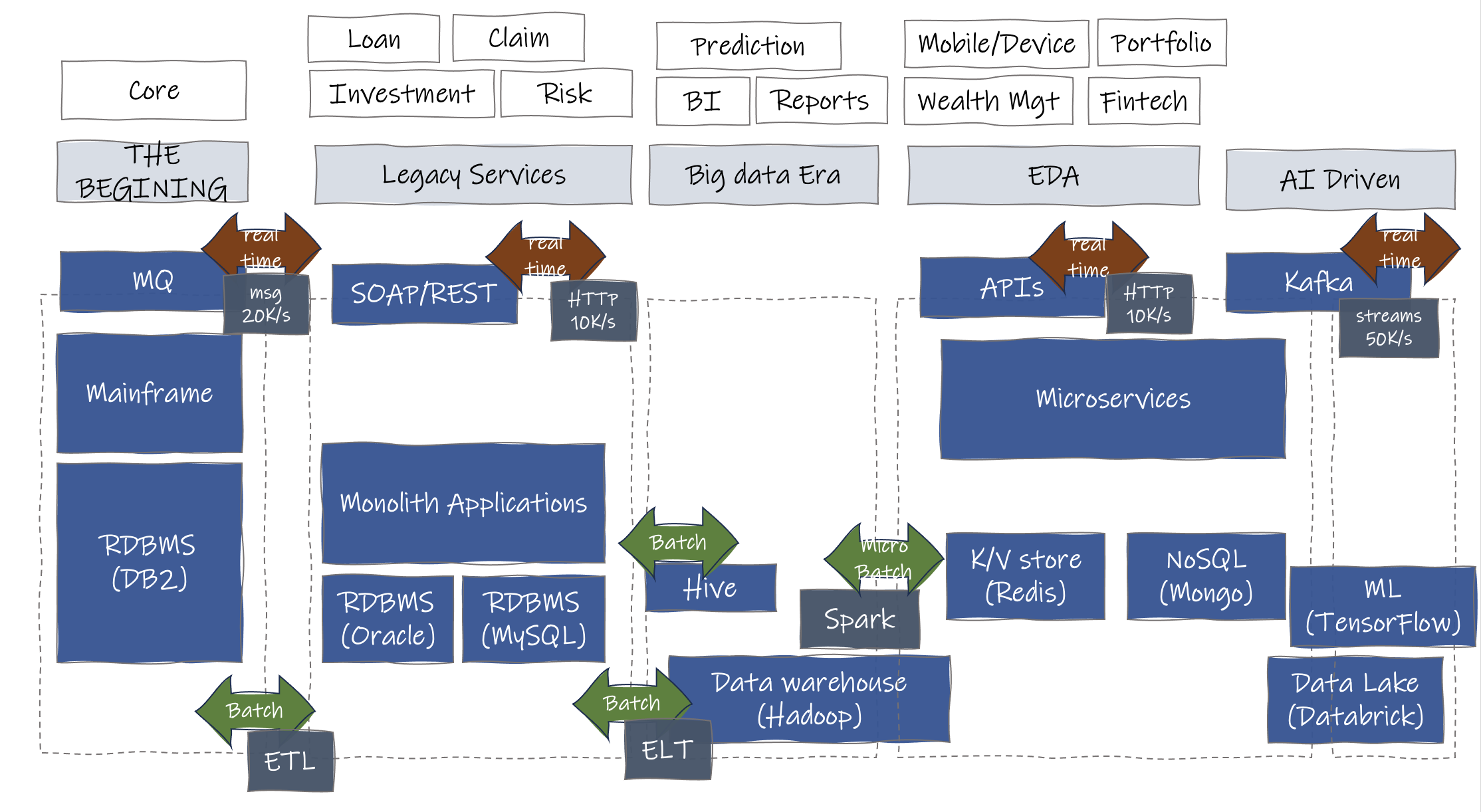
Wchodzenie do większych instytucji finansowych często ujawnia fascynujący wgląd: postęp technologiczny trwający dwie dekady, który rozwija się na moich oczach. Podstawowa działalność nadal opiera się na systemach mainframe działających w języku COBOL, podczas gdy drugorzędna warstwa usług działa jako brama dostępu do rdzenia i rozszerzenia oferty usług, których nie można wykonać w systemie podstawowym.
Dane są w dużej mierze grupowane i poddawane nocnym procesom ETL w celu ułatwienia transferu między tymi warstwami. Dostęp do danych w czasie rzeczywistym stanowi wyzwanie, wymagając wielu prób i zapytań przez bramę nawet w celu prostej aktualizacji statusu.
Tworzone są hurtownie danych, służące jako miejsca zrzutu danych poprzez ETL, gdzie prawie połowa danych pozostaje niewykorzystana. Narzędzia Business Intelligence (BI) wyodrębniają, przekształcają i analizują dane, aby zapewnić cenny wgląd w decyzje biznesowe i projektowanie produktów. Przetwarzanie wsadowe i rozproszone przeważają ze względu na ogromną ilość danych do przetworzenia, co skutkuje silosami danych i opóźnionym odzwierciedleniem zmieniających się trendów.
W ostatnich latach pojawiły się bardziej zwinne podejścia, z przesunięciem danych w kierunku binarnych formatów klucz-wartość w celu lepszej skalowalności w chmurze. Jednak ze względu na złożoność architektury, transfery danych między usługami uległy zwielokrotnieniu, co prowadzi do wyzwań związanych z utrzymaniem integralności danych. Ponadto innowacje te są przeznaczone głównie dla nowych projektów, pozostawiając programistom i użytkownikom wewnętrznym konieczność poruszania się po wielu pętlach w systemie w celu wykonania zadań.
Firmy również płacą cenę za powolne innowacje i napotykają wysokie koszty przy wdrażaniu nowych zmian. Jest to szczególnie prawdziwe w przypadku inicjatyw opartych na sztucznej inteligencji, które wymagają znacznej ilości danych i szybkiego działania. W związku z tym kilka wyzwań wypływa na powierzchnię i utrudnia postęp, sprawiając, że FSI coraz trudniej jest dostosować się i przygotować na przyszłość.
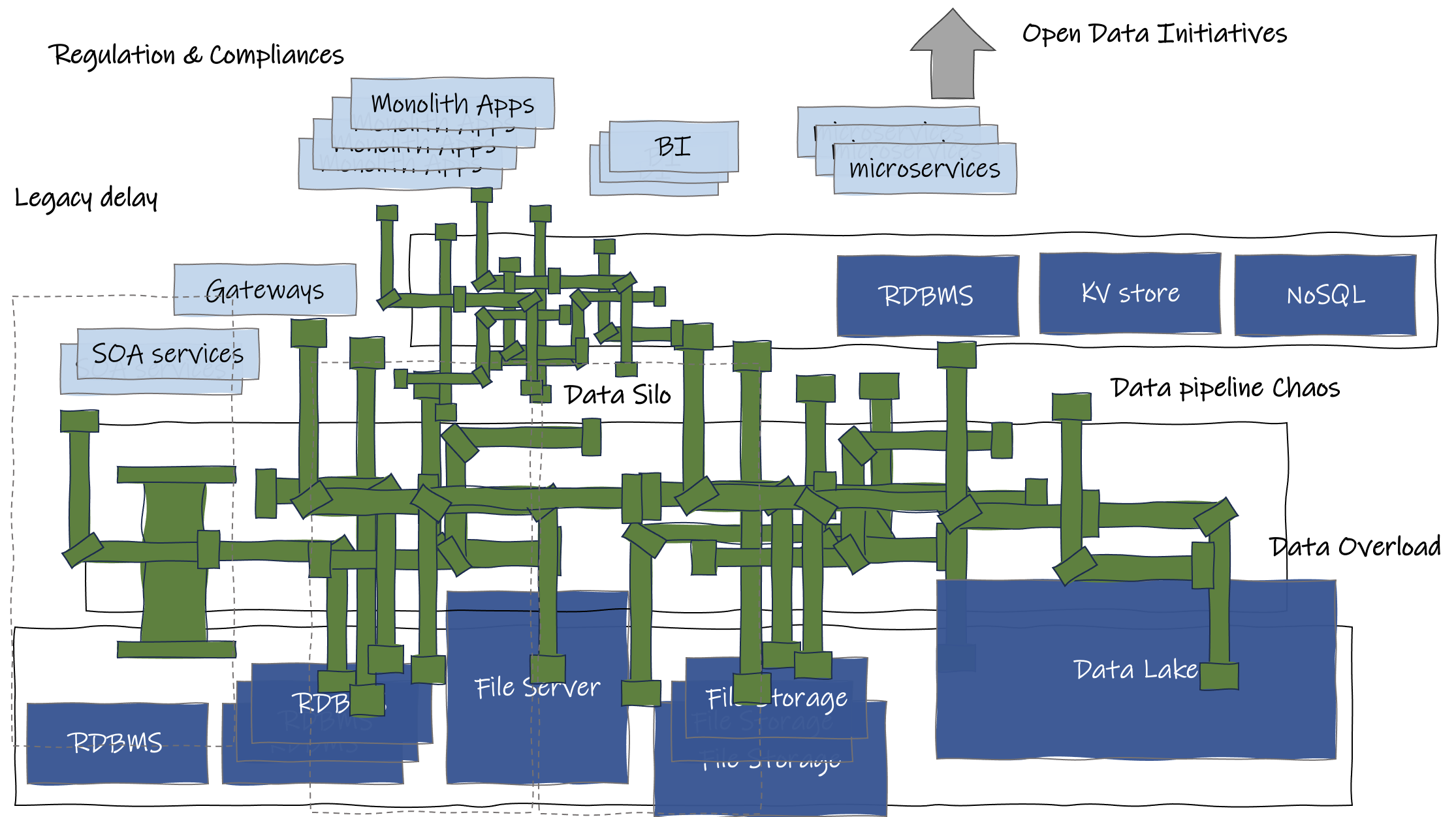
Oto zestawienie tych wyzwań i idealny stan dla FSI.
| Rzeczywistość | Stan idealny | |
|---|---|---|
|
Silosy danych |
Zdecentralizowany charakter operacji finansowych lub położenie geograficzne zespołu. Poszczególne działy lub jednostki biznesowe utrzymują własne dane i systemy, które zostały wdrożone na przestrzeni lat, co skutkuje izolacją danych i utrudnia współpracę. Było już kilka prób przełamania silosów, a rozwiązania w jakiś sposób przyczyniły się do jednego z wielu poniższych problemów (tj. chaosu w potoku danych). |
Skonsolidowany widok danych w całej organizacji. Możliwość szybkiego przeglądania i pobierania danych w razie potrzeby. |
|
Starsze systemy |
FSI często zmagają się ze starszymi systemami, które funkcjonują od wielu lat. Systemom tym zazwyczaj brakuje zdolności do szybkiego dostosowywania się do zmian. W rezultacie dostęp do danych z tych starszych systemów i podejmowanie w związku z nimi działań może być czasochłonne, prowadząc do opóźnień, a czasem wręcz uniemożliwiając dobre wykorzystanie najnowszych danych. |
Synchronizacja danych ze starymi systemami i zmodernizowane potoki ETL. Migracja i wycofanie się ze starego procesu. |
|
Przeciążenie danymi |
Ogromne ilości danych pochodzących z różnych źródeł, w tym transakcji, interakcji z klientami, danych rynkowych i innych, mogą być przytłaczające, utrudniając wydobycie cennych spostrzeżeń i uzyskanie przydatnych informacji. Często prowadzi to do wysokich rachunków za przechowywanie, a dane nie są w pełni wykorzystywane przez większość czasu. |
Zmiana infrastruktury w celu przyjęcia większej ilości danych, planowana strategia przechowywania danych oraz bardziej opłacalny sposób bezpiecznego zabezpieczania i przechowywania danych z wystarczającym planem awaryjnym i odzyskiwania danych. |
|
Chaos w potoku danych |
Zarządzanie potokami danych w ramach FSI może być złożonym przedsięwzięciem. Przy licznych źródłach danych, formatach i punktach integracji, potok danych może stać się fragmentaryczny i chaotyczny. Niespójne formaty danych, niekompatybilne systemy i ręczne procesy mogą wprowadzać błędy i nieefektywności, co utrudnia zapewnienie płynnego przepływu danych i utrzymanie ich jakości. |
Katalog danych to scentralizowane repozytorium, które służy jako kompleksowy system inwentaryzacji i zarządzania metadanymi dla zasobów danych organizacji. Zmniejszenie redundancji, poprawa wydajności, usprawnienie przepływu danych oraz wprowadzenie automatyzacji, monitorowania i regularnej kontroli. |
|
Inicjatywy otwartych danych |
Wraz z rosnącą potrzebą współpracy partnerskiej i rządowych projektów otwartych API, FSI stoi przed wyzwaniem dostosowania swoich praktyk w zakresie danych. Rośnie zapotrzebowanie na bezpieczne i płynne udostępnianie danych partnerom zewnętrznym i podmiotom rządowym. FSI muszą ustanowić ramy i procesy ułatwiające wymianę danych przy jednoczesnym zapewnieniu prywatności, bezpieczeństwa i zgodności z przepisami. |
Bezpieczne i dobrze zdefiniowane interfejsy API dostępu do danych, które zapewniają interoperacyjność danych dzięki wspólnym standardom. Dodatkowo, kontrola wersji i dostępu do punktów dostępu. |
Jak widać, istnieje wiele przeszkód dla FSI próbujących wkroczyć w świat sztucznej inteligencji. Przyjrzyjmy się teraz różnym potokom danych wykorzystywanym przez organizacje do przenoszenia danych z punktu A do B oraz wyzwaniom, przed którymi stoi wiele zespołów.
Zrozumienie potoków danych typu Batch, Micro-Batch i Real-Time
Istnieje wiele różnych sposobów przenoszenia danych. Aby zachować prostotę, podzielę dziś najpopularniejsze potoki na trzy kategorie:
- Batch
- Micro-batch
- Czas rzeczywisty
1. Rurociągi wsadowe
Są one zwykle używane podczas przetwarzania dużych ilości danych w zaplanowanych “kawałkach” na raz – często w przetwarzaniu nocnym, okresowych aktualizacjach danych lub raportowaniu wsadowym. Potoki wsadowe dobrze nadają się do scenariuszy, w których natychmiastowe przetwarzanie danych nie jest kluczowe, a wynikiem jest zwykle raport, jak w przypadku profili inwestycyjnych i roszczeń ubezpieczeniowych.
Główne wady obejmują opóźnienia w przetwarzaniu, potencjalnie nieaktualne wyniki, złożoność skalowalności, zarządzanie sekwencjami zadań, kwestie alokacji zasobów i ograniczenia w dostarczaniu wglądu w dane w czasie rzeczywistym. Byłem świadkiem, jak klient z branży ubezpieczeniowej uciekał w nocy przez okno, aby uruchomić partie z powodu ogromnej ilości danych, które wymagały przetworzenia (aktualizacja składek, szczegóły inwestycji, dokumenty, prowizje agentów itp.)
Przetwarzanie równoległe lub map-reduce to kilka technik pozwalających skrócić czas, ale wprowadzają one również złożoność, ponieważ obie równoległe wymagają od programisty zrozumienia dystrybucji danych, zależności danych i umiejętności manewrowania między nimi. mapą oraz zmniejszyć funkcji.
2. Mikropotoki
Mikropotoki wsadowe to odmiana potoków wsadowych, w których dane są przetwarzane w mniejszych, częstszych partiach w regularnych odstępach czasu, co zapewnia mniejsze opóźnienia i świeższe wyniki. Są one powszechnie wykorzystywane do analizy transakcji finansowych, analizy strumienia kliknięć, systemów rekomendacji, gwarantowania emisji i przewidywania rezygnacji klientów.
Wyzwania związane z potokami mikropartii obejmują zarządzanie kompromisem między częstotliwością przetwarzania a wykorzystaniem zasobów, obsługę potencjalnych niespójności danych w mikropartiach oraz radzenie sobie z narzutem inicjowania częstych zadań przetwarzania przy jednoczesnym zachowaniu wydajności i niezawodności.
3. Potoki czasu rzeczywistego
Te potoki przetwarzają dane natychmiast po ich wpłynięciu. Oferują minimalne opóźnienia i są niezbędne w aplikacjach wymagających natychmiastowych reakcji, takich jak analityka w czasie rzeczywistym, wykrywanie oszustw transakcyjnych, monitorowanie krytycznych systemów, interaktywne doświadczenia użytkowników, ciągłe szkolenie modeli i przewidywanie w czasie rzeczywistym.
Jednak potoki czasu rzeczywistego napotykają wyzwania, takie jak obsługa wysokiej przepustowości, utrzymywanie konsekwentnie niskich opóźnień, zapewnianie poprawności i spójności danych, zarządzanie skalowalnością zasobów w celu dostosowania do różnych obciążeń oraz radzenie sobie z potencjalnymi złożonościami integracji danych – z których wszystkie wymagają solidnych projektów architektonicznych i starannego wdrożenia, aby zapewnić dokładne i terminowe wyniki.
Podsumowując, oto ważne informacje o wszystkich trzech potokach w jednej tabeli.
| Batch | Mikro partia | Czas rzeczywisty | |
|---|---|---|---|
|
Cadence |
Zaplanowane dłuższe interwały |
Zaplanowane krótkie interwały |
Czas rzeczywisty |
|
Rozmiar danych |
Duży |
Małe zdefiniowane fragmenty |
Duże |
|
Skalowanie |
Pionowe |
Poziomo |
Poziomo |
|
Opóźnienie |
Wysokie (godziny/dni) |
Średni (sekundy) |
Niski (milisekundy) |
|
Magazyn danych |
Hurtownia danych, Jezioro danych, Bazy danych, Pliki |
Rozproszony system plików, Hurtownie danych, Bazy danych |
Systemy przetwarzania strumieniowego, jeziora danych, bazy danych |
|
Technologie open source |
Apache Hadoop, Map-reduce |
Apache Spark™ |
Apache Kafka®, Apache Flink® |
|
Przykłady zastosowań branżowych |
Przenoszenie plików (skanowanie podpisów klientów) i przesyłanie danych z komputera mainframe w celu uzyskania podstawowych danych bankowych lub podstawowych informacji o polisach ubezpieczeniowych. Duże zbiory danych dla uczenia maszynowego. |
Przygotowywanie raportów biznesowych w czasie zbliżonym do rzeczywistego i potrzeba wykorzystania danych z dużych zbiorów danych, takich jak generowanie przeglądów zarządzania ryzykiem dla inwestycji. Codzienna analiza trendów rynkowych. |
Wykrywanie transakcji/fraudów w czasie rzeczywistym, natychmiastowe zatwierdzanie roszczeń, monitorowanie krytycznych systemów i obsługa chatbota klienta. |
Na marginesie, niektórzy mogą kategoryzować potoki jako ETL lub ELT.
- ETL (Extract, Transform, and Load) przekształca dane na oddzielnym serwerze przetwarzania przed przeniesieniem ich do hurtowni danych.
- ELT (Extract, Load, and Transform) przekształca dane w hurtowni danych, zanim trafią one do miejsca docelowego.
W zależności od miejsca docelowego danych, jeśli trafiają one do jeziora danych, większość potoków wykonuje ELT. Natomiast w przypadku źródła danych, takiego jak hurtownia danych lub baza danych, ponieważ wymaga ono przechowywania danych w bardziej ustrukturyzowany sposób, zobaczy Pan więcej ETL. Moim zdaniem wszystkie trzy potoki powinny wykorzystywać obie techniki do konwersji danych do pożądanego stanu.
Typowe wyzwania związane z pracą z potokami danych
Potoki danych są rozproszone w różnych działach, a zespoły IT wdrażają je przy użyciu różnych technologii i platform. Z mojego własnego doświadczenia w pracy z inżynierami danych na miejscu, oto kilka typowych wyzwań związanych z pracą z potokami danych:
Trudności z dostępem do danych
- Dane nieustrukturyzowane mogą być trudne. Brak metadanych utrudnia zlokalizowanie pożądanych danych w repozytorium (takich jak korespondencja klientów, e-maile, dzienniki czatów, dokumenty prawne).
- Niektóre narzędzia lub platformy do analizy danych mogą mieć ścisłe wymagania dotyczące formatu danych wejściowych, co stwarza trudności w konwersji danych do wymaganego formatu. Tak więc wiele złożonych potoków przekształca logikę (i to w dużej ilości).
- Rygorystyczne środki bezpieczeństwa i zgodność z przepisami mogą wprowadzić dodatkowe kroki i złożoność w uzyskiwaniu dostępu do niezbędnych danych. (Dane osobowe umożliwiające identyfikację, dokumentacja medyczna dotycząca roszczeń).
Hałaśliwe, “brudne” dane
- Jeziora danych są podatne na takie problemy, jak duplikaty danych.
- Trwałość zepsutych lub nieaktualnych danych w systemie może zagrozić dokładności i niezawodności modeli sztucznej inteligencji i spostrzeżeń.
- Błędy podczas wprowadzania danych nie zostały wychwycone i przefiltrowane. (największa strata czasu na rozwiązywanie problemów związanych z przetwarzaniem danych)
- Niezgodności danych między różnymi zestawami danych i niespójności w danych. (Nieprawidłowe raporty i błędy potoku)
Wydajność
- Duże ilości danych, brak wydajnej pamięci masowej i mocy obliczeniowej.
- Metody pobierania danych, takie jak interfejsy API, w których żądanie i odpowiedź nie są idealne do pozyskiwania dużych ilości danych.
- Lokalizacja odpowiednich danych w systemie i miejsce ich przechowywania ma duży wpływ na częstotliwość przetwarzania danych, a także opóźnienia i koszty ich pobierania.
Widoczność danych (zarządzanie danymi i metadane)
- Nieodpowiednie metadane skutkują brakiem jasności co do dostępności, własności i wykorzystania zasobów danych.
- Trudno jest określić istnienie i dostępność określonych danych, co utrudnia ich efektywne wykorzystanie i analizę.
Rozwiązywanie problemów
-
Identyfikacja niespójności, rozwiązywanie problemów z jakością danych lub usuwanie awarii przetwarzania danych może być czasochłonne i złożone.
Podczas procesu przeprojektowywania struktury danych dla sztucznej inteligencji, zarówno predykcyjnej, jak i generatywnej, zajmę się głównymi bolączkami inżynierów danych, a także pomogę rozwiązać niektóre z największych wyzwań nękających obecnie FSI.
Prowadzenie FSI od punktu A do AI
Patrząc przez pryzmat danych, świat oparty na sztucznej inteligencji można podzielić na dwie podstawowe kategorie: wnioskowanie i uczenie maszynowe. Dziedziny te różnią się pod względem wymagań i wykorzystania danych.
- Uczenie maszynowe wymaga kompleksowych zbiorów danych pochodzących ze źródeł historycznych, operacyjnych i w czasie rzeczywistym, umożliwiając szkolenie dokładniejszych modeli. Włączenie danych w czasie rzeczywistym do zbioru danych ulepsza model i ułatwia zwinne i inteligentne systemy.
- Wnioskowanie nadaje priorytet skupieniu się na czasie rzeczywistym, wykorzystując modele generowane przez uczenie maszynowe do reagowania na przychodzące zdarzenia, zapytania i żądania.
Zbudowanie generatywnego modelu sztucznej inteligencji jest dużym przedsięwzięciem. W przypadku FSI sensowne jest ponowne wykorzystanie istniejącego modelu (foundation model) z pewnym dopracowaniem w określonych obszarach, aby dopasować go do Państwa przypadku użycia. “Dopracowanie” będzie wymagało od Państwa dostarczenia wysokiej jakości zbioru danych o dużej objętości. Stare powiedzenie wciąż jest prawdziwe: śmieci na wejściu, śmieci na wyjściu. Jeśli dane nie są wiarygodne, nieuchronnie skończy się to niewiarygodną sztuczną inteligencją.
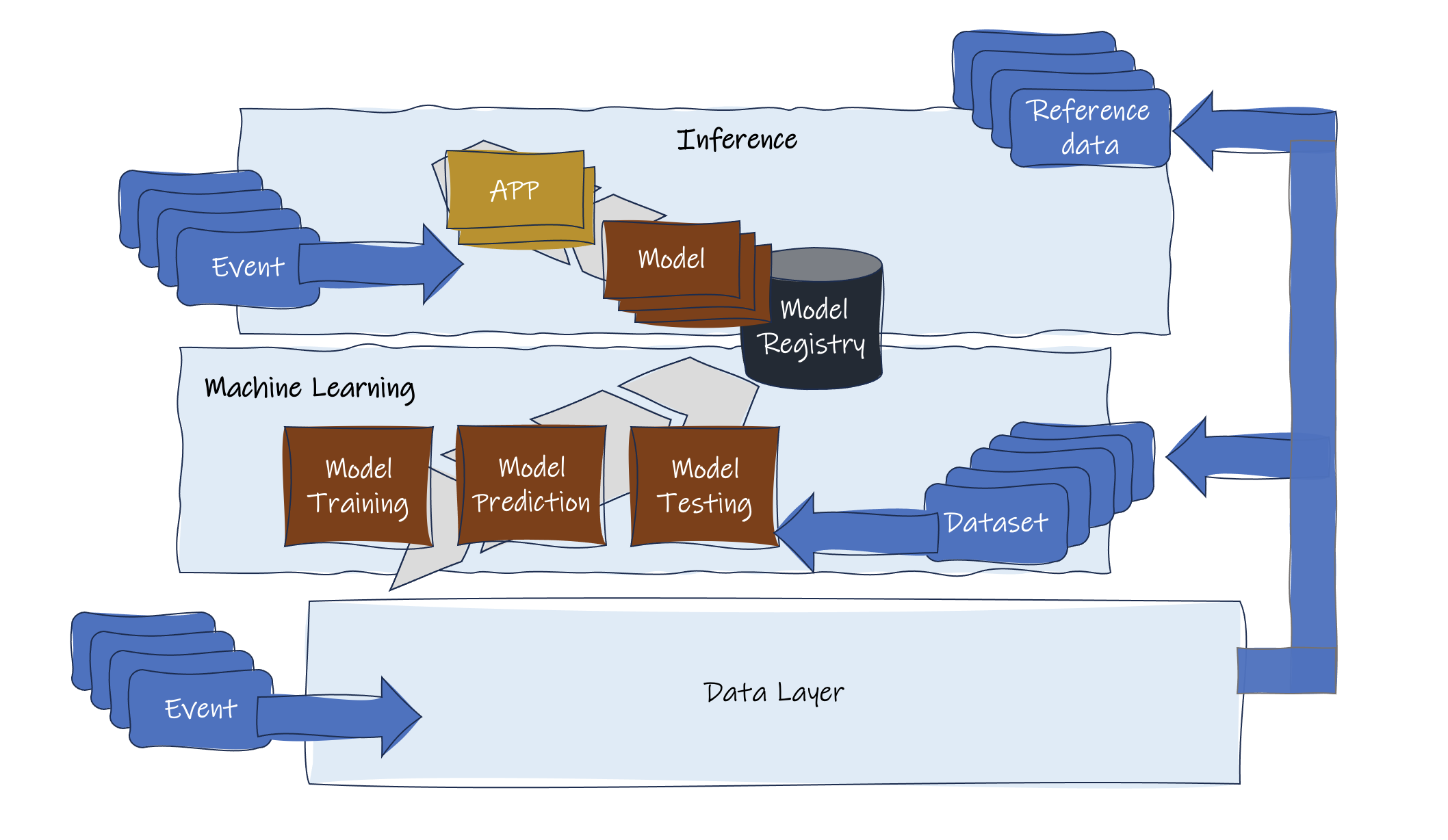
Moim zdaniem, aby przygotować się na najlepszy możliwy wynik AI, kluczowe jest stworzenie następujących podstaw:
- Infrastruktura danych: Potrzebują Państwo solidnej struktury o niskim opóźnieniu i wysokiej przepustowości do przesyłania i przechowywania ogromnych ilości danych finansowych w celu wydajnego pozyskiwania, przechowywania, przetwarzania i wyszukiwania danych. Powinna ona obsługiwać przetwarzanie rozproszone i w chmurze oraz priorytetowo traktować opóźnienia w sieci, koszty przechowywania i bezpieczeństwo danych.
- Jakość danych: Aby zapewnić lepsze dane do określenia modelu, najlepiej jest przejść przez procesy czyszczenia, normalizacji, de-duplikacji i walidacji danych w celu usunięcia niespójności, błędów i nadmiarowości.
Gdybym powiedział, że istnieje proste rozwiązanie, byłbym albo wyjątkowym geniuszem zdolnym do rozwiązywania światowych kryzysów, albo jawnie kłamał. Biorąc jednak pod uwagę złożoność, jaką już mamy, najlepiej jest skupić się na generowaniu zbiorów danych wymaganych dla ML i usprawnić dane potrzebne do fazy wnioskowania w celu podejmowania decyzji. Następnie można stopniowo rozwiązywać problemy spowodowane nadmierną dezorganizacją obecnych danych. Zajmowanie się jedną domeną na raz, rozwiązywanie w pierwszej kolejności problemów użytkowników biznesowych i brak nadmiernych ambicji to najszybsza droga do sukcesu.
Ale zostawimy to na następny post.
Podsumowanie
Wdrożenie strategii danych w branży usług finansowych może być skomplikowane ze względu na takie czynniki, jak starsze systemy i konsolidacja innych firm. Wprowadzenie sztucznej inteligencji do tej mieszanki może stanowić wyzwanie dla wydajności, a niektóre firmy mogą mieć trudności z przygotowaniem danych do aplikacji uczenia maszynowego.
W moim następnym poście przedstawię Państwu sprawdzone podejście do strategii danych, aby usprawnić kłopotliwe potoki danych w celu pozyskiwania danych w czasie rzeczywistym, wydajnego przetwarzania i płynnej integracji różnych systemów.