
Zapobieganie oszustwom finansowym to wyścig z czasem. Pod względem implementacji w dużej mierze zależy od mocy przetwarzania danych, zwłaszcza w przypadku dużych zbiorów danych. Dzisiaj podzielę się z Państwem przypadkiem użycia banku detalicznego z ponad 650 milionami klientów indywidualnych. Porównali oni komponenty analityczne, w tym Apache Doris, ClickHouse, Greenplum, Cassandra i Kylin. Po pięciu rundach wdrożeń i porównań opartych na 89 niestandardowych przypadkach testowych, zdecydowano się na Apache Doris, ponieważ zaobserwowano sześciokrotną szybkość zapisu i szybsze łączenie wielu tabel w Apache Doris w porównaniu do potężnego ClickHouse.
Omówię szczegółowo, w jaki sposób bank buduje swoją platformę zarządzania ryzykiem nadużyć w oparciu o Apache Doris i jak ona działa.
Platforma zarządzania ryzykiem nadużyć finansowych
W ramach tej platformy, 80% zapytań ad-hoc zwraca wyniki w czasie krótszym niż 2 sekundy, oraz 95% z nich jest ukończonych w czasie poniżej 5 sekund. Średnio rozwiązanie przechwytuje dziesiątki tysięcy podejrzanych transakcji każdego dnia i unika strat w wysokości milionów dolarów dla klientów banków.
Jest to przegląd całej platformy z perspektywy architektonicznej.
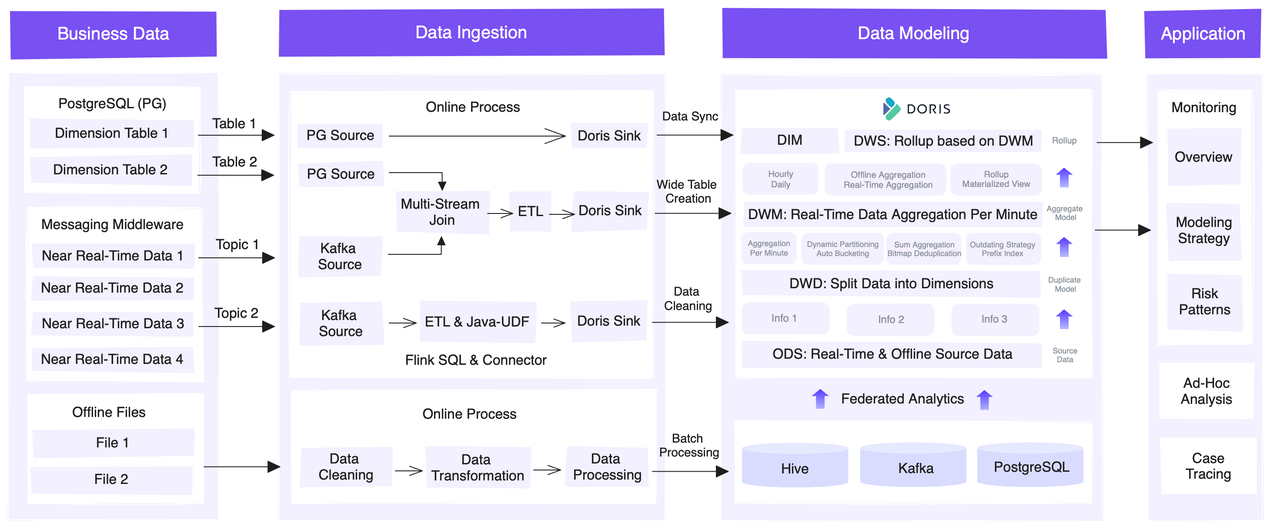
The dane źródłowe można z grubsza podzielić na kategorie:
- Dane wymiarowe: w większości przechowywane w PostgreSQL
- Dane transakcyjne w czasie rzeczywistym: oddzielone od różnych systemów zewnętrznych za pośrednictwem kolejek komunikatów Kafka
- Dane offline: bezpośrednio pobierane z systemów zewnętrznych do Hive, co ułatwia uzgadnianie danych
Dla pozyskiwanie danychW ten sposób gromadzone są trzy rodzaje danych źródłowych. Po pierwsze, wykorzystują JDBC Catalog do synchronizacji metadanych i danych użytkownika z PostgreSQL.
Dane transakcyjne muszą zostać połączone z danymi wymiarowymi w celu dalszej analizy. W związku z tym wykorzystują interfejs API SQL Flink do odczytu danych wymiarowych z PostgreSQL i danych transakcyjnych w czasie rzeczywistym z Kafka. Następnie we Flink wykonują wielostrumieniowe sprzężenia i generują szerokie tabele. Do odświeżania tabel wymiarów w czasie rzeczywistym wykorzystywany jest mechanizm Lookup Join, który dynamicznie wyszukuje i odświeża dane wymiarów podczas przetwarzania strumieni danych. Wykorzystują również Java UDF, aby zaspokoić swoje specyficzne potrzeby w ETL. Następnie zapisują dane w Apache Doris za pośrednictwem aplikacji Flink-Doris-Connector.
Dane offline są czyszczone, przekształcane i zapisywane w bazach Hive, Kafka i PostgreSQL, dla których Doris tworzy katalogi jako mapowania na podstawie ich Multi-Catalog w celu ułatwienia analizy federacyjnej. W tym procesie Hive Metastore umożliwia automatyczny dostęp i odświeżanie danych z Hive.
Pod względem modelowanie danych, używają Apache Doris jako hurtowni danych i stosują różne modele danych. modele danych dla różnych warstw. Każda warstwa agreguje lub zwija dane z poprzedniej warstwy z większą ziarnistością. Ostatecznie powstaje wysoce zagregowany Rollup lub Materialized View.
Teraz proszę pozwolić mi pokazać, jakie zadania analityczne są uruchamiane na tej platformie. W oparciu o skalę monitorowania i zaangażowania człowieka, zadania te można podzielić na raportowanie ryzyka w czasie rzeczywistym, analizę wielowymiarową, zapytania federacyjne i automatyczne ostrzeganie.
Raport ryzyka w czasie rzeczywistym
Jeśli chodzi o zapobieganie oszustwom, co zmniejsza skuteczność Państwa wysiłków w tym zakresie? Jest to niepełna ekspozycja na potencjalne zagrożenia i przedwczesna identyfikacja ryzyka. Właśnie dlatego ludzie zawsze chcą monitorowania i raportowania w czasie rzeczywistym.
Rozwiązanie banku opiera się na Apache Flink i Apache Doris. Po pierwsze, zebrano 17 wymiarów. Po oczyszczeniu, agregacji i innych obliczeniach wizualizują dane na pulpicie nawigacyjnym w czasie rzeczywistym.
Jeśli chodzi o skalaanalizuje przepływy pracy ponad 10 milionów klientów, 30 000 urzędników, 10 000 oddziałów i 1000 produktów.
Co do prędkość, bank przeszedł ewolucję od odświeżania danych następnego dnia do przetwarzania danych w czasie zbliżonym do rzeczywistego. Ukierunkowaną analizę można przeprowadzić w ciągu kilku minut zamiast godzin. Rozwiązanie obsługuje również skomplikowane zapytania ad-hoc w celu uchwycenia podstawowych zagrożeń poprzez monitorowanie działania modeli danych i reguł.
Wielowymiarowa analiza w celu identyfikacji zagrożeń
Śledzenie przypadków to kolejna powszechna praktyka zwalczania nadużyć finansowych. Bank posiada bibliotekę modeli nadużyć. W oparciu o modele oszustw analizują ryzyko związane z każdą transakcją i wizualizują wyniki w czasie zbliżonym do rzeczywistego, dzięki czemu ich pracownicy mogą w razie potrzeby podjąć szybkie działania.
W tym celu używają Apache Doris dla analizy wielowymiarowej przypadków. Sprawdzają wzorce transakcji, w tym źródła, typy i czas, aby uzyskać kompleksowy przegląd. Podczas tego procesu często muszą łączyć ponad 10 warunków filtrowania o różnych wymiarach. Jest to możliwe dzięki funkcji zapytanie ad-hoc możliwości Apache Doris. Zarówno dopasowywanie oparte na regułach, jak i dopasowywanie oparte na listach przypadków może być wykonywane w ciągu kilku sekund bez ręcznego wysiłku.
Sfederowane zapytania w celu zlokalizowania szczegółów ryzyka
Oprócz identyfikacji ryzyka dla każdej transakcji, bank otrzymuje również raporty o ryzyku od klientów. W takich przypadkach odpowiednia transakcja zostanie oznaczona jako “ryzykowna” i zostanie skategoryzowana i zarejestrowana w systemie biletowym. Etykiety zapewniają, że transakcje wysokiego ryzyka są niezwłocznie obsługiwane.
Problem polega na tym, że system biletowy jest przeciążony takimi danymi, więc nie jest w stanie bezpośrednio przedstawić wszystkich szczegółów ryzykownych transakcji. To, co należy zrobić, to powiązać bilety ze szczegółami transakcji, aby pracownicy banku mogli zlokalizować rzeczywiste ryzyko.
Jak to jest realizowane? Każdego dnia Apache Doris przegląda bilety przyrostowe i tabelę informacji podstawowych, aby uzyskać identyfikatory biletów, a następnie łączy identyfikatory biletów z danymi wymiarowymi przechowywanymi w sobie. Na koniec szczegóły zgłoszenia są prezentowane w interfejsie Doris. Cały ten proces trwa zaledwie kilka minut. To duża zmiana w porównaniu do dawnych czasów, kiedy trzeba było ręcznie wyszukiwać podejrzane transakcje.
Automatyczne ostrzeganie
W oparciu o Apache Doris, bank projektuje własne reguły, modele i strategie ostrzegania. System monitoruje, jak wszystko działa. Gdy wykryje sytuację zgodną z regułami ostrzegania, uruchomi alarm. Ustanowiono również mechanizm informacji zwrotnej w czasie rzeczywistym dla reguł ostrzegania, więc jeśli nowo dodana reguła spowoduje jakiekolwiek negatywne skutki, zostanie szybko dostosowana lub usunięta.
Do tej pory bank dodał do systemu prawie 100 reguł ostrzegawczych dla różnych rodzajów ryzyka. W ciągu ostatnich dwóch miesięcy, ponad 100 alarmów wydano z ponad 95% dokładnością w mniej niż 5 sekund po wystąpieniu sytuacji zagrożenia.
Wnioski
Aby uzyskać kompleksowe rozwiązanie w zakresie zwalczania nadużyć finansowych, bank prowadzi na pełną skalę monitorowanie i raportowanie w czasie rzeczywistym dla wszystkich przepływów danych. Następnie dla każdej transakcji analizuje wiele wymiarów, aby zidentyfikować ryzyko. W przypadku podejrzanych transakcji zgłoszonych przez klientów banku, wykonują oni zapytania federacyjne w celu uzyskania pełnych szczegółów. Ponadto mechanizm automatycznego ostrzegania jest zawsze na patrolu, aby chronić cały system. Są to różne rodzaje obciążeń analitycznych w tym rozwiązaniu. Wdrożenie ich opiera się na możliwościach Apache Doris, który jest hurtownią danych zaprojektowaną jako platforma typu “wszystko w jednym” dla różnych obciążeń. Jeśli próbują Państwo zbudować własne rozwiązanie antyfraudowe, to Deweloperzy open-source Apache Doris chętnie wymienią się z Państwem pomysłami.