
Problem silosów danych jest jak artretyzm dla firm internetowych, ponieważ prawie wszyscy go doświadczają wraz z wiekiem. Firmy wchodzą w interakcje z klientami za pośrednictwem stron internetowych, aplikacji mobilnych, stron H5 i urządzeń końcowych. Z tego czy innego powodu trudno jest zintegrować dane ze wszystkich tych źródeł. Dane pozostają tam, gdzie są i nie mogą być ze sobą powiązane w celu dalszej analizy. W ten sposób powstają silosy danych. Im bardziej rozrasta się Państwa firma, tym bardziej zróżnicowane źródła danych o klientach będą Państwo posiadać i tym bardziej prawdopodobne jest, że znajdą się Państwo w pułapce silosów danych.
Dokładnie to dzieje się z firmą ubezpieczeniową, o której opowiem w tym poście. Do 2023 r. obsługiwała ona już ponad 500 milionów klientów i podpisała 57 miliardów umów ubezpieczeniowych. Kiedy zaczęli budować platformę danych klientów (CDP), aby pomieścić taki rozmiar danych, wykorzystali wiele komponentów.
Silosy danych w CDP
Podobnie jak większość platform danych, CDP 1.0 miał potok przetwarzania wsadowego i potok przesyłania strumieniowego w czasie rzeczywistym. Dane offline były ładowane za pośrednictwem zadań Spark do Impali, gdzie były oznaczane i dzielone na grupy. W międzyczasie Spark wysyłał je również do NebulaGraph w celu obliczenia OneID (omówione w dalszej części tego postu). Z drugiej strony, dane w czasie rzeczywistym były tagowane przez Flink, a następnie przechowywane w HBase, gotowe do zapytania.
Doprowadziło to do powstania w CDP warstwy obliczeniowej o dużej liczbie komponentów: Impala, Spark, NebulaGraph i HBase.
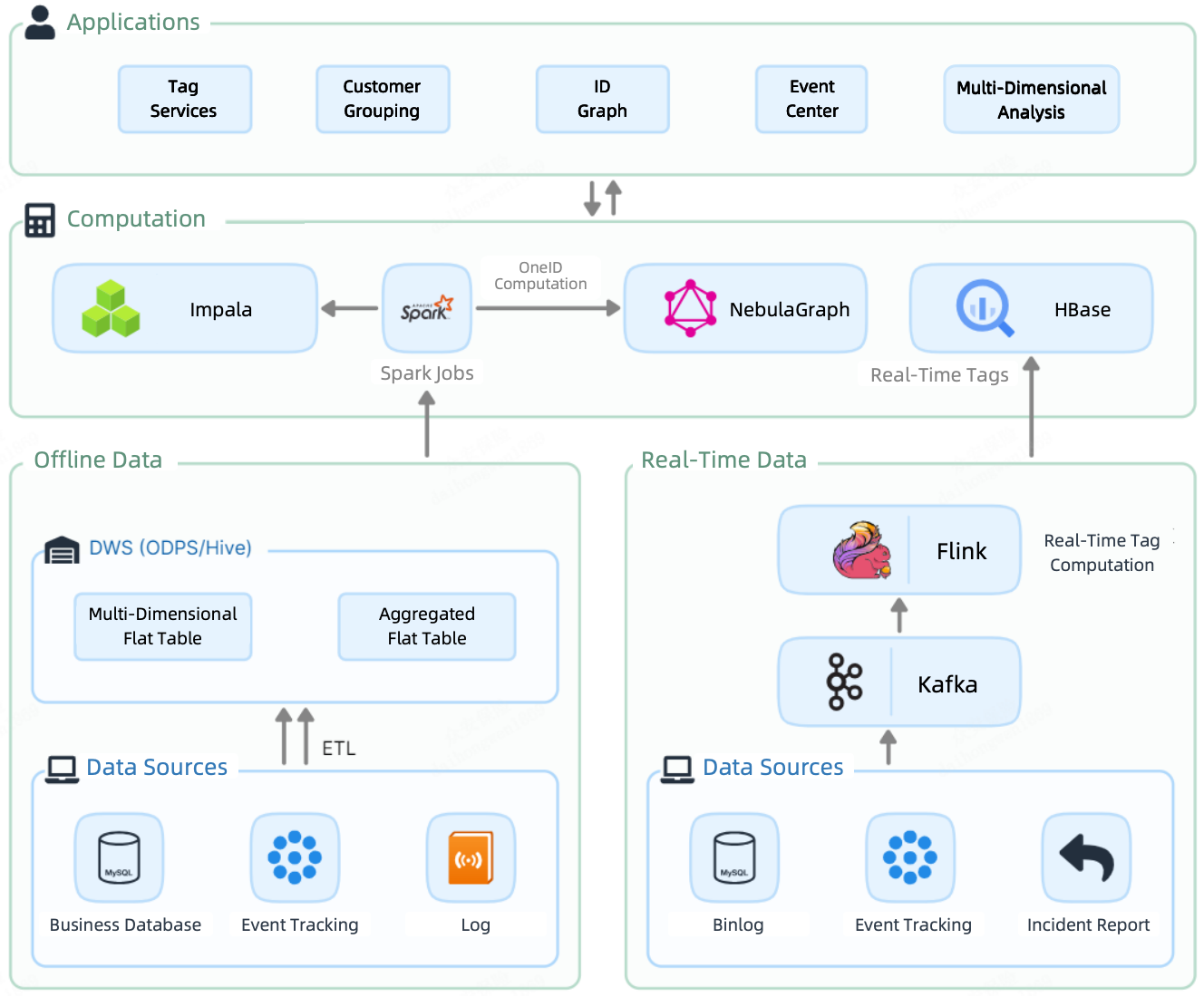
W rezultacie znaczniki offline, znaczniki czasu rzeczywistego i dane wykresu były rozproszone w wielu komponentach. Zintegrowanie ich w celu świadczenia dalszych usług związanych z danymi było kosztowne ze względu na nadmiarowe przechowywanie i nieporęczny transfer danych. Co więcej, ze względu na rozbieżności w pamięci masowej, musieli oni zwiększyć rozmiar klastra CDH i klastra NebulaGraph, zwiększając koszty zasobów i utrzymania.
CDP oparty na Apache Doris
W przypadku CDP 2.0 zdecydowano się wprowadzić ujednolicone rozwiązanie, aby uporządkować bałagan. W warstwie obliczeniowej CDP 2.0, Apache Doris zajmuje się przechowywaniem i obliczaniem danych zarówno w czasie rzeczywistym, jak i offline.
Aby pozyskać dane offline, wykorzystują Stream Load metoda. Ich 30-wątkowy test ingestion pokazuje, że może on wykonać ponad 300 000 upsertów na sekundę. Aby załadować dane w czasie rzeczywistym, używają kombinacji Flink-Doris-Connector i Stream Load. Ponadto, w raportowaniu w czasie rzeczywistym, gdzie muszą wyodrębnić dane z wielu zewnętrznych źródeł danych, wykorzystują one Multi-Catalog funkcja dla zapytań federacyjnych.
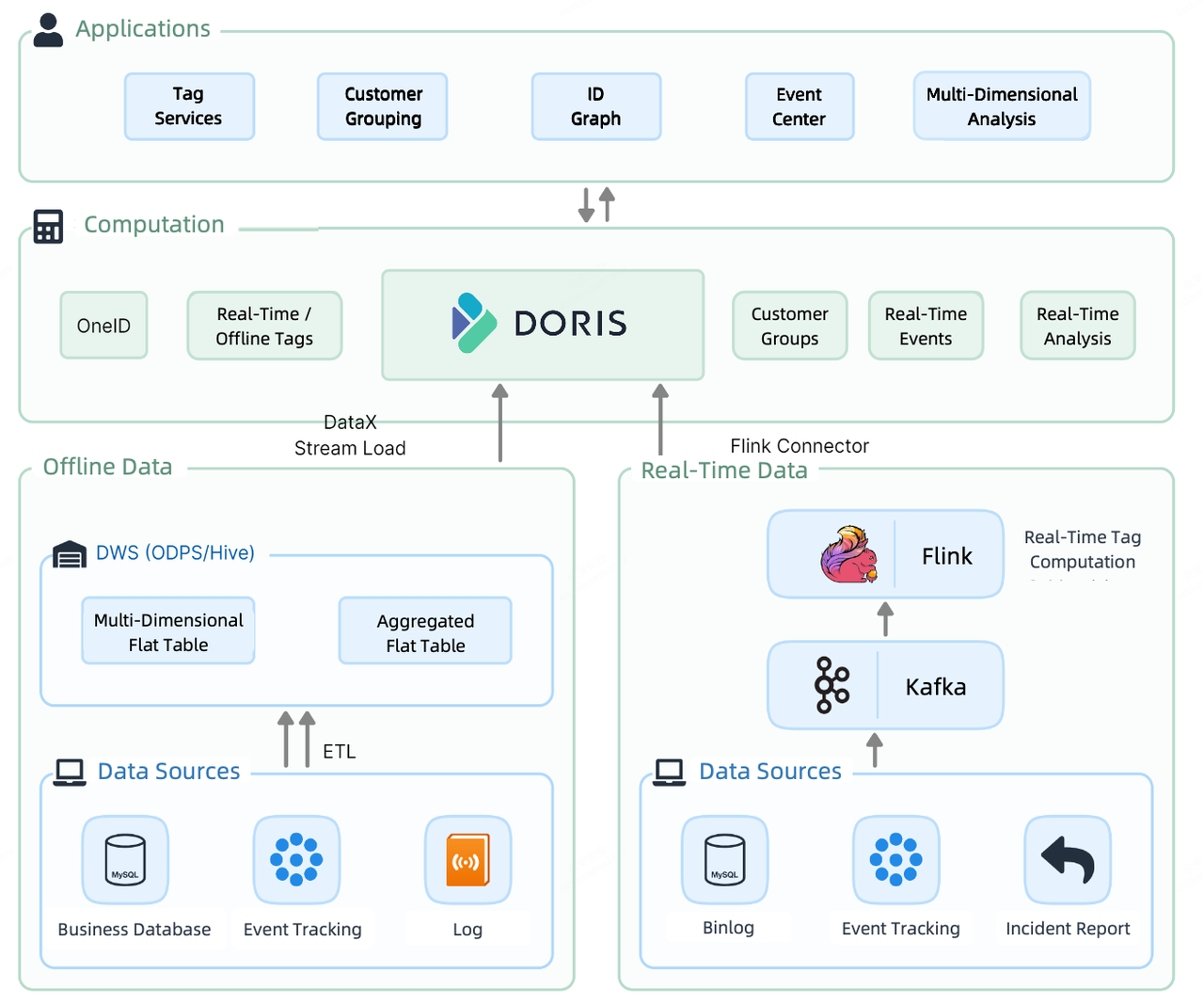
Przepływy pracy związane z analizą klientów w tym CDP wyglądają następująco. Najpierw sortują informacje o klientach, a następnie dołączają tagi do każdego klienta. Na podstawie tagów dzielą klientów na grupy w celu bardziej ukierunkowanej analizy i obsługi.
Następnie zagłębię się w te obciążenia i pokażę Państwu, jak Apache Doris je przyspiesza.
OneID
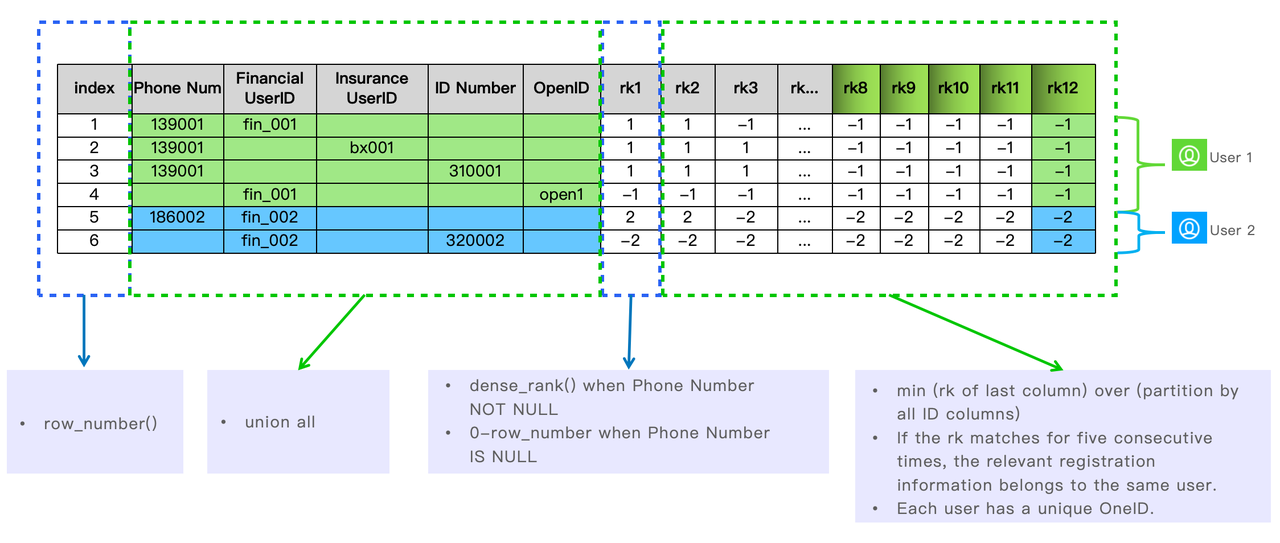
Czy kiedykolwiek zdarzyło się to Państwu, gdy posiadali Państwo różne systemy rejestracji użytkowników dla swoich produktów i usług? Mogą Państwo zebrać adres e-mail UserID A z jednej strony internetowej produktu, a później numer ubezpieczenia społecznego UserID B z innej. Następnie dowiadują się Państwo, że UserID A i UserID B w rzeczywistości należą do tej samej osoby, ponieważ korzystają z tego samego numeru telefonu.
Dlatego właśnie powstał pomysł OneID. Chodzi o to, aby zebrać informacje rejestracyjne użytkowników wszystkich linii biznesowych w jednej dużej tabeli w Apache Doris, posortować je i upewnić się, że każdy użytkownik ma unikalny OneID.
W ten sposób można dowiedzieć się, które informacje rejestracyjne należą do tego samego użytkownika, wykorzystując funkcje Apache Doris.
Usługi tagowania
Ten CDP zawiera informacje dotyczące 500 milionów klientów, którzy pochodzą z ponad 500 tabel źródłowych i są dołączone do ponad 2000 tagów łącznie.
Ze względu na aktualność, tagi można podzielić na tagi czasu rzeczywistego i tagi offline. Tagi czasu rzeczywistego są obliczane przez Apache Flink i zapisywane w płaskiej tabeli w Apache Doris, podczas gdy tagi offline są obliczane przez Apache Doris, ponieważ pochodzą z tabeli atrybutów użytkownika, tabeli biznesowej i tabeli zachowań użytkowników w Doris. Oto najlepsze praktyki firmy w zakresie tagowania danych:
1. Tagi offline
Podczas szczytów zapisu danych pełna aktualizacja może łatwo spowodować błąd OOM, biorąc pod uwagę ogromną skalę danych. Aby tego uniknąć, wykorzystano INSERT INTO SELECT funkcję Apache Doris i proszę włączyć częściową aktualizację kolumny. Pozwoli to znacznie zmniejszyć zużycie pamięci i utrzymać stabilność systemu podczas ładowania danych.
set enable_unique_key_partial_update=true;
insert into tb_label_result(one_id, labelxx)
select one_id, label_value as labelxx
from .....2. Znaczniki czasu rzeczywistego
Częściowa aktualizacja kolumn jest również dostępna dla tagów czasu rzeczywistego, ponieważ nawet tagi czasu rzeczywistego są aktualizowane w różnym tempie. Wszystko, co jest potrzebne, to ustawienie partial_columns na true.
curl --location-trusted -u root: -H "partial_columns:true" -H "column_separator:," -H "columns:id,balance,last_access_time" -T /tmp/test.csv http://127.0.0.1:48037/api/db1/user_profile/_stream_load3. Zapytania punktowe o wysokiej współbieżności
Przy obecnym rozmiarze działalności firma otrzymuje zapytania o tagi na poziomie współbieżności przekraczającym 5000 QPS. Aby zagwarantować wysoką wydajność, firma stosuje kombinację strategii. Po pierwsze, firma stosuje Przygotowane oświadczenie do wstępnej kompilacji i wstępnego wykonania SQL. Po drugie, dostrajają parametry dla Doris Backend i tabel, aby zoptymalizować przechowywanie i wykonywanie. Wreszcie, umożliwiają pamięć podręczną wierszy jako uzupełnienie zorientowanego na kolumny Apache Doris.
disable_storage_row_cache = false
storage_page_cache_limit=40%
enable_unique_key_merge_on_write = true
store_row_column = true
light_schema_change = true
4. Obliczanie tagów (Join)
W praktyce wiele usług tagowania jest implementowanych poprzez łączenie wielu tabel w bazie danych. Często obejmuje to więcej niż 10 tabel. Aby uzyskać optymalną wydajność obliczeń, przyjmują one metodę grupę kolokacji strategia w Doris.
Grupowanie klientów
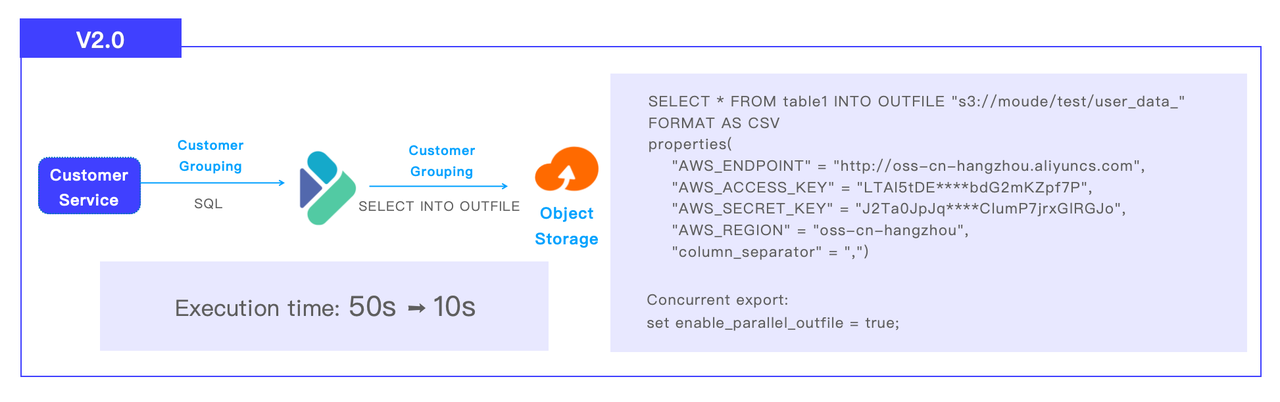
Potok grupowania klientów w CDP 2.0 wygląda następująco: Apache Doris otrzymuje SQL od obsługi klienta, wykonuje obliczenia i wysyła zestaw wyników do obiektowej pamięci masowej S3 za pośrednictwem SELECT INTO OUTFILE. Firma podzieliła swoich klientów na 1 milion grup. Zadanie grupowania klientów, które wcześniej zajmowało 50 sekund w Impali do ukończenia wystarczy teraz 10 sekund w Doris.
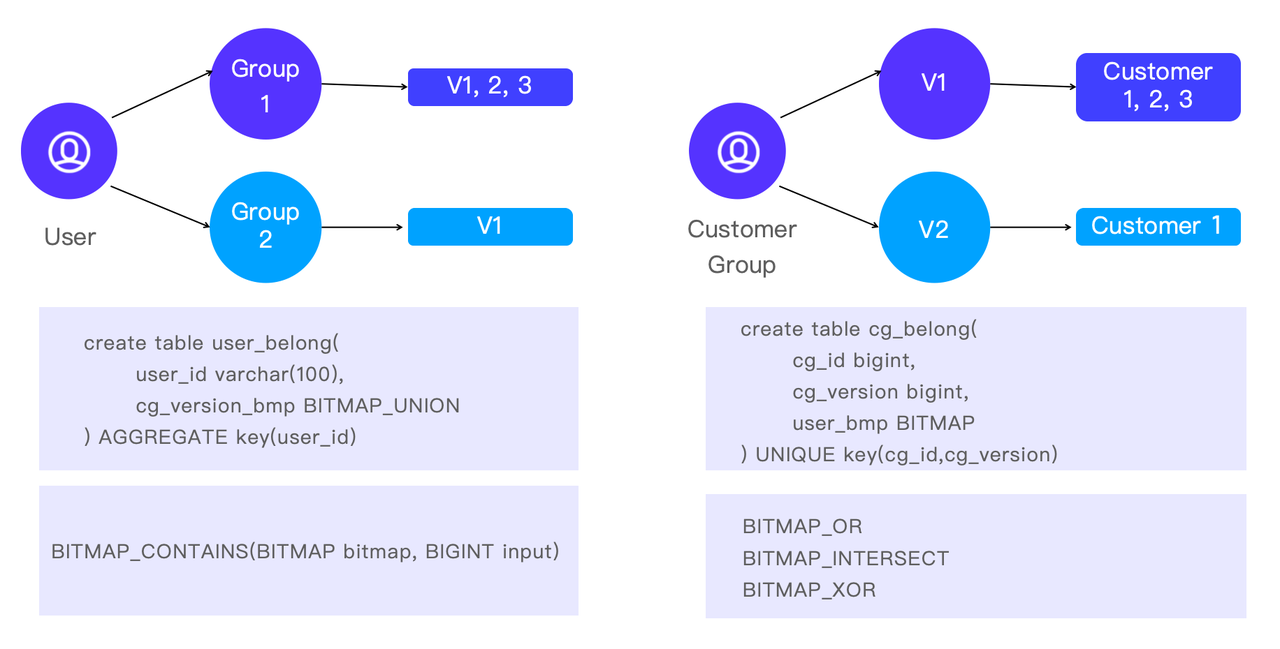
Oprócz grupowania klientów w celu dokładniejszej analizy, czasami przeprowadza się analizę w odwrotnym kierunku. Oznacza to, że celują w określonego klienta i dowiadują się, do jakich grup należy. Pomaga to analitykom zrozumieć charakterystykę klientów, a także sposób, w jaki różne grupy klientów nakładają się na siebie.
W Apache Doris jest to realizowane przez funkcje BITMAP: BITMAP_CONTAINS to szybki sposób na sprawdzenie, czy klient należy do określonej grupy, oraz BITMAP_OR, BITMAP_INTERSECT, oraz BITMAP_XOR są wyborami do analizy krzyżowej.
Wnioski
Od CDP 1.0 do CDP 2.0, firma ubezpieczeniowa przyjmuje Apache Doris, ujednoliconą hurtownię danych, aby zastąpić Spark+Impala+HBase+NebulaGraph. Zwiększa to wydajność przetwarzania danych poprzez rozbicie silosów danych i usprawnienie potoków przetwarzania danych. W CDP 3.0 chcą pogrupować swoich klientów, łącząc tagi czasu rzeczywistego i tagi offline w celu bardziej zróżnicowanej i elastycznej analizy. The Społeczność Apache Doris oraz VeloDB zespół będzie nadal wspierał Państwa podczas tej aktualizacji.