W dzisiejszym krajobrazie opartym na danych, firmy z różnych branż nieustannie poszukują sposobów na uzyskanie przewagi konkurencyjnej. Jednym z najpotężniejszych narzędzi, jakimi dysponują, jest szeregi czasowe Prognozowanie, technika, która pozwala organizacjom przewidywać przyszłe trendy na podstawie danych historycznych. Od finansów po opiekę zdrowotną, prognozowanie szeregów czasowych zmienia sposób, w jaki firmy opracowują strategie i podejmują decyzje.
Prognozowanie szeregów czasowych obejmuje analizę punktów danych zebranych lub zarejestrowanych w określonych odstępach czasu. W przeciwieństwie do danych statycznych, dane szeregów czasowych są chronologiczne, często wykazując wzorce, takie jak trendy i sezonowość. Metody prognozowania wykorzystują te wzorce do przewidywania przyszłych wartości, zapewniając wgląd, który jest nieoceniony w planowaniu i strategii.
Prognozowanie sprzedaży
Firmy zajmujące się handlem detalicznym wykorzystują prognozowanie szeregów czasowych do przewidywania przyszłej sprzedaży. Analizując dane dotyczące sprzedaży w przeszłości, mogą przewidywać popyt, optymalizować zapasy i planować kampanie marketingowe.
Analiza rynku akcji
Analitycy finansowi wykorzystują prognozowanie szeregów czasowych do przewidywania cen akcji i trendów rynkowych. Pomaga to inwestorom podejmować świadome decyzje dotyczące kupna lub sprzedaży aktywów.
Prognozowanie pogody
Meteorolodzy wykorzystują prognozowanie szeregów czasowych do przewidywania wzorców pogodowych. Dane te mają kluczowe znaczenie dla rolnictwa, gotowości na wypadek katastrof i codziennego planowania.
Planowanie zasobów opieki zdrowotnej
Szpitale i kliniki wykorzystują prognozowanie do przewidywania napływu pacjentów. Pomaga to w zarządzaniu zasobami, takimi jak personel, łóżka i materiały medyczne.
Prognozowanie zużycia energii
Firmy użyteczności publicznej wykorzystują prognozowanie szeregów czasowych do przewidywania zapotrzebowania na energię. Umożliwia to efektywne zarządzanie sieciami energetycznymi i alokację zasobów.
Techniki prognozowania obejmują:
- Analiza statystyczna
- Algorytmy uczenia maszynowego, takie jak ARIMA
- Sieci neuronowe (RNN): LSTM
Sieci LSTM są wyspecjalizowane sieci neuronowe które obsługują sekwencje danych. W przeciwieństwie do zwykłych sieci neuronowych typu feedforward, LSTM mają pętle, które pozwalają na utrzymywanie się informacji, co czyni je idealnymi do zadań, w których kontekst w czasie ma kluczowe znaczenie. Każda komórka LSTM składa się z trzech części: bramki wejściowej, bramki zapominania i bramki wyjściowej, które regulują przepływ informacji, umożliwiając sieci selektywne zachowywanie lub zapominanie informacji w czasie.
Więcej szczegółów można znaleźć w filmie “Długa pamięć krótkotrwała (LSTM), jasno wyjaśniona.”
W tym samouczku skupimy się na analizie LSTM pojedynczej odmiany. Wkrótce opublikuję podejście do implementacji analizy wielowymiarowej.
Kod główny
Importowanie bibliotek
import tensorflow as tf
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from keras.preprocessing.sequence import TimeseriesGenerator as TSG
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from tensorflow.keras.models import load_model
from tensorflow.keras.callbacks import ModelCheckpoint
import tensorflow.keras.optimizers as optimizers
import seaborn as sns
import statsmodels.api as smŁadowanie danych z pliku CSV, są to dane sprzedaży napojów. Następnie proszę zaktualizować kolumny Unnamed: 0 na date. Proszę przekonwertować wpisy w pliku date z ciągów znaków (lub dowolnego innego formatu, w którym mogą się znajdować) na datetime obiektów. Funkcja range generuje ciąg liczb zaczynający się od 1 i kończący się na całkowitej liczbie wpisów w kolumnie DataFrame (włącznie). Sekwencja ta jest następnie przypisywana do nowej kolumny o nazwie sequence.
import pandas as pd
# Load data from a CSV file into a DataFrame
dfc = pd.read_csv('sales_beverages.csv')
# Rename the column from 'Unnamed: 0' to 'date'
dfc = dfc.rename(columns={"Unnamed: 0": "date"})
# Convert the 'date' column from a string type to a datetime type to facilitate date manipulation
dfc["date"] = pd.to_datetime(dfc["date"])
# Add a new column called 'sequence' which is a sequence of integers from 1 to the number of rows in the DataFrame
# This sequence helps in identifying the row number or providing a simple ordinal index
dfc["sequence"] = range(1, len(dfc) + 1)
# Display the modified DataFrame
dfc
| DATA | Sales_Beverages | Sekwencja | |
| 0 | 2016-01-02 | 250510.0 | 1 |
|---|---|---|---|
| 1 | 2016-01-03 | 299177.0 | 2 |
| 2 | 2016-01-04 | 217525.0 | 3 |
| 3 | 2016-01-05 | 187069.0 | 4 |
| 4 | 2016-01-06 | 170360.0 | 5 |
| … | … | … | … |
| 586 | 2017-08-11 | 189111.0 | 587 |
| 587 | 2017-08-12 | 182318.0 | 588 |
| 588 | 2017-08-13 | 202354.0 | 589 |
| 589 | 2017-08-14 | 174832.0 | 590 |
| 590 | 2017-08-15 | 170773.0 | 591 |
591 wierszy × 3 kolumny
Eksploracja danych
print('Number of Samples = {}'.format(dfc.shape[0]))
print('Training X Shape = {}'.format(dfc.shape))
print('Index of data set:\n', dfc.columns)
print(dfc.info())
print('\nMissing values of data set:\n', dfc.isnull().sum())
print('\nNull values of data set:\n', dfc.isna().sum())
# Generate a complete range of dates from the min to max
all_dates = pd.date_range(start=dfc['date'].min(), end=dfc['date'].max(), freq='D')
# Find missing dates by checking which dates in 'all_dates' are not in 'df['date']'
missing_dates = all_dates.difference(dfc['date'])
# Display the missing dates
print("Missing dates are ", missing_dates)
Number of Samples = 591 Training X Shape = (591, 3) Index of data set: Index(['date', 'sales_BEVERAGES', 'sequence'], dtype="object") <class 'pandas.core.frame.DataFrame'> RangeIndex: 591 entries, 0 to 590 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 date 591 non-null datetime64[ns] 1 sales_BEVERAGES 591 non-null float64 2 sequence 591 non-null int64 dtypes: datetime64[ns](1), float64(1), int64(1) memory usage: 14.0 KB None Missing values of data set: date 0 sales_BEVERAGES 0 sequence 0 dtype: int64 Null values of data set: date 0 sales_BEVERAGES 0 sequence 0 dtype: int64 Missing dates are DatetimeIndex(['2016-12-25'], dtype="datetime64[ns]", freq=None)
Proszę podzielić kolumny z datami na poszczególne jednostki, takie jak rok, miesiąc, data i dzień tygodnia, aby zrozumieć, czy w danych sprzedaży występuje jakiś wzorzec.
year: Roczna część datymonth: Miesięczna część datyday: Dzień miesiącaday_of_week: Nazwa dnia tygodnia (np. poniedziałek, wtorek)day_of_week_num: Numeryczna reprezentacja dnia tygodnia (od 0 dla poniedziałku do 6 dla niedzieli)
# Extract year, month, day, and day of the week
dfc['year'] = dfc['date'].dt.year
dfc['month'] = dfc['date'].dt.month
dfc['day'] = dfc['date'].dt.day
dfc['day_of_week'] = dfc['date'].dt.day_name()
dfc['day_of_week_num'] = dfc['date'].dt.dayofweek Macierz korelacji jest obliczana dla wybranych kolumn (year, month, day, day_of_week_num, oraz sales_BEVERAGES). Ta macierz mierzy liniowe zależności między tymi zmiennymi, co może pomóc w zrozumieniu, w jaki sposób różne składniki daty wpływają na sprzedaż napojów.
# Calculate correlation matrix
correlation_matrix = dfc[['year', 'month', 'day', 'day_of_week_num', 'sales_BEVERAGES']].corr()
# Print the correlation matrix
#print(correlation_matrix)
# Set up the matplotlib figure
plt.figure(figsize=(10, 8))
# Draw the heatmap
sns.heatmap(correlation_matrix, annot=True, fmt=".2f", cmap='coolwarm', cbar=True)
# Add a title and format it
plt.title('Heatmap of Correlation Between Date Components and Sales')
# Show the plot
plt.show()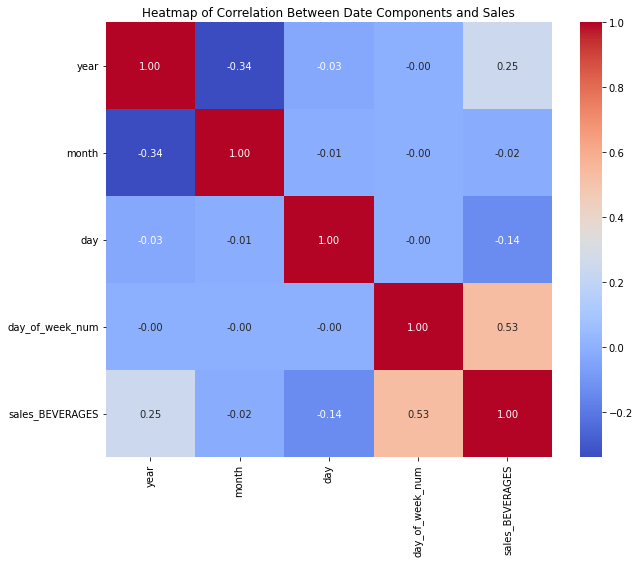 Powyższy kod pokazuje silną korelację między sprzedażą a dniami tygodnia oraz między sprzedażą a latami. Narysujmy odpowiednie wykresy, aby zweryfikować różnice.
Powyższy kod pokazuje silną korelację między sprzedażą a dniami tygodnia oraz między sprzedażą a latami. Narysujmy odpowiednie wykresy, aby zweryfikować różnice.
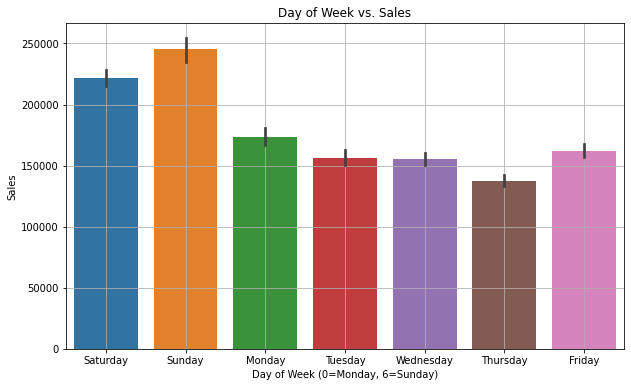
Dzień tygodnia a sprzedaż
plt.figure(figsize=(10, 6))
sns.barplot(x='day_of_week', y='sales_BEVERAGES', data=dfc)
plt.title('Day of Week vs. Sales')
plt.xlabel('Day of Week (0=Monday, 6=Sunday)')
plt.ylabel('Sales')
plt.grid(True)
plt.show()
Rok a sprzedaż
plt.figure(figsize=(10, 6))
sns.lineplot(x='year', y='sales_BEVERAGES', data=dfc, marker="o")
plt.title('Year vs. Sales')
plt.xlabel('Year')
plt.ylabel('Sales')
plt.grid(True)
plt.show()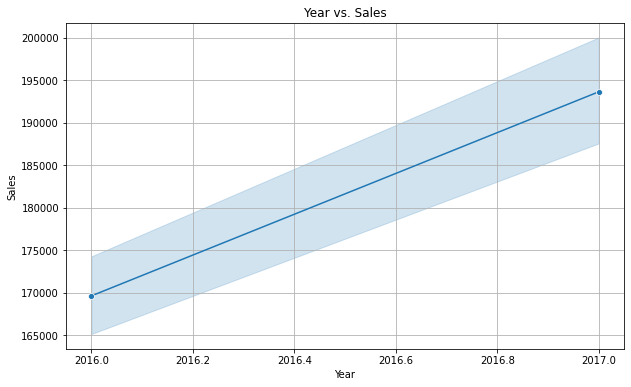
Wyraźnie widać, że sprzedaż jest wysoka w weekendy i mniejsza w czwartki. Ponadto roczna sprzedaż rośnie z każdym rokiem. Jest to trend liniowy, co oznacza, że nie ma wielu odchyleń.
Proszę również szybko zweryfikować zmienność w kombinacji rok-miesiąc.
dfc['month_year'] = dfc['date'].dt.to_period('M')
plt.figure(figsize=(16, 8))
sns.barplot(x='month_year', y='sales_BEVERAGES', data=dfc)
plt.title('Month vs. Sales')
plt.xlabel('Month-Year')
plt.ylabel('Sales')
plt.grid(True)
plt.show()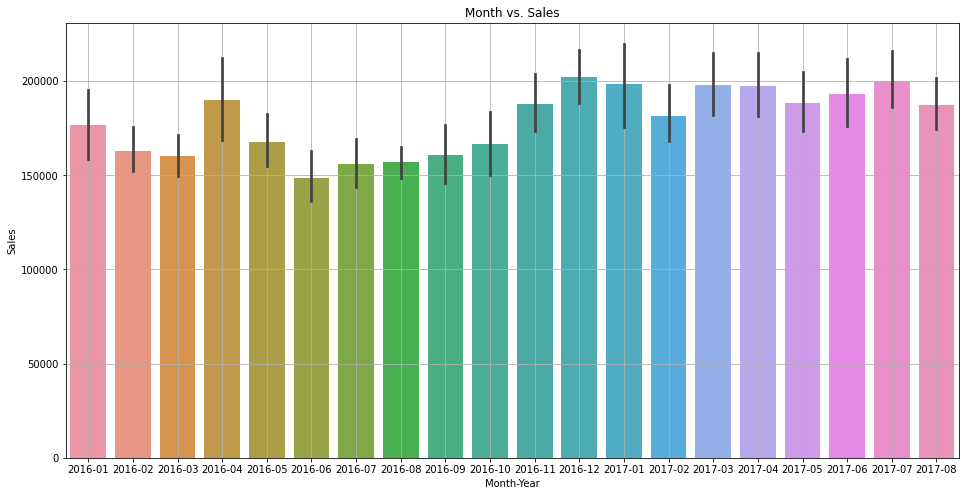
Ze względu na ograniczoną ilość danych nie jest to zbyt jasne, ale wydaje się, że sprzedaż jest wyższa w grudniu i styczniu.
Obliczanie średniej sprzedaży na rok
#Evaluate the average sales of the year on monthly bais.
a = dfc[dfc['year'].isin([2016,2017])].groupby(["year", "month"]).sales_BEVERAGES.mean().reset_index()
plt.figure(figsize=(10, 6))
sns.lineplot(data=a, x='month', y='sales_BEVERAGES', hue="year", marker="o")
# Enhance the plot with titles and labels
plt.title('Average Sales for 2016 and 2017')
plt.xlabel('Month')
plt.ylabel('Average Sales')
plt.legend(title="Year")
plt.grid(True)
# Show the plot
plt.show()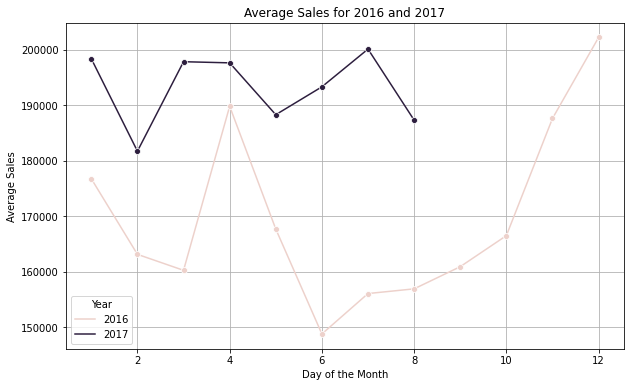
ACF vs PACF (nie wymagane dla LSTM jako takiego)
Ten krok jest zwykle używany z modelem ARIMA, ale mimo to zapewni Państwu dobrą widoczność wokół rozmiaru okna używanego później.
fig, ax = plt.subplots(1,2,figsize=(15,5))
sm.graphics.tsa.plot_acf(dfc.sales_BEVERAGES, lags=365, ax=ax[0], title = "AUTOCORRELATION\n")
sm.graphics.tsa.plot_pacf(dfc.sales_BEVERAGES, lags=180, ax=ax[1], title = "PARTIAL AUTOCORRELATION\n")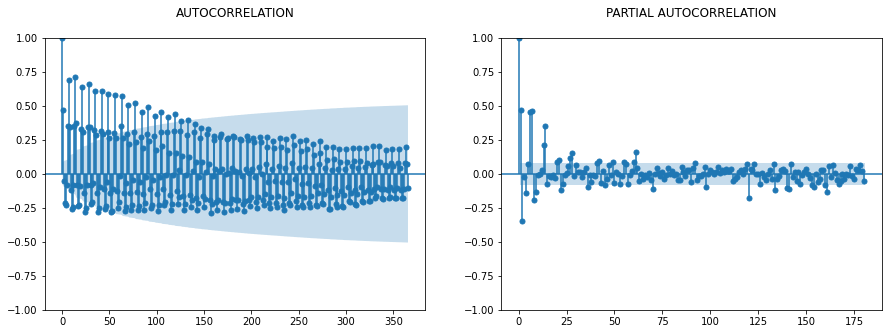
Proszę wybrać podzbiór danych do analizy trendu. Proszę pobrać tylko sales_BEVERAGAESponieważ w tym ćwiczeniu przeprowadzimy analizę pojedynczej zmiennej:
df1=dfc[["date",'sales_BEVERAGES']]
df1.head() date sales_BEVERAGES
0 2016-01-02 250510.0
1 2016-01-03 299177.0
2 2016-01-04 217525.0
3 2016-01-05 187069.0
4 2016-01-06 170360.0Ta linia przedstawia wykres sales_BEVERAGES kolumnę z df1, zaczynając od drugiego elementu (index 1) do końca. Wykluczenie pierwszego punktu danych ([1:]) służy do uniknięcia określonych wartości odstających.
Spowoduje to filtrowanie df1 aby uwzględnić tylko wiersze, w których sales_BEVERAGES jest większa niż 20 000. Ponownie wymagany jest krok w celu usunięcia wartości odstających.
plt.plot(df1['sales_BEVERAGES'][1:])
df1=df1[df1['sales_BEVERAGES']>20000]
df2=df1['sales_BEVERAGES'][1:]
df2.shapeMinMaxScaler
MinMaxScaler pochodzi z biblioteki sklearn.preprocessing i służy do skalowania danych w df2 series. Jest to krok wstępnego przetwarzania w zadaniach analizy danych i uczenia maszynowego, zwłaszcza podczas pracy z sieciami neuronowymi, ponieważ pomaga normalizować dane w określonym zakresie, zazwyczaj [0, 1].
X skalowane = X max -X min /X-X min
Jest on używany tutaj w celu poprawy procesu zbieżności. Wiele algorytmów uczenia maszynowego które wykorzystują zejście gradientowe jako technikę optymalizacji (np. regresja liniowa, regresja logistyczna, sieci neuronowe) zbiegają się szybciej, gdy cechy są skalowane. Jeśli zakres jednej cechy jest o rzędy wielkości większy niż innych, może ona zdominować funkcję celu i sprawić, że model nie będzie w stanie skutecznie uczyć się na podstawie innych cech.
scaler=MinMaxScaler()
scaler.fit(df2.values.reshape(-1, 1))# Convert the PeriodIndex to DateTimeIndex if necessary
df2=scaler.transform(df2.values.reshape(-1, 1))
Nie korzystałem z poniższej funkcji, ale mimo to zamieściłem ją wraz z krótkim wyjaśnieniem. Zamiast niej użyłem generatora szeregów czasowych, chociaż oba wykonają to samo zadanie. Mogą Państwo użyć dowolnej z nich. Funkcja jest przeznaczona do konwersji Pandas DataFrame na pary wejście-wyjście (X, y) do wykorzystania w modelach uczenia maszynowego, w szczególności tych obejmujących dane szeregów czasowych, takich jak LSTM.
window_size: Liczba całkowita wskazująca liczbę kroków czasowych w każdej sekwencji wejściowej, domyślnie 5df_as_npkonwertuje Pandas DataFrame na tablicę NumPy, aby ułatwić operacje numeryczne i cięcie.- Utworzone zostaną dwie listy:
Xdo przechowywania sekwencji wejściowych iydo przechowywania odpowiednich etykiet (danych wyjściowych).
Iteruje po tablicy NumPy, zaczynając od pierwszego indeksu do długości tablicy pomniejszonej o wartość window_size. Zapewnia to, że każda sekwencja wejściowa i odpowiadająca jej wartość wyjściowa mogą zostać przechwycone bez wychodzenia poza granice. Dla każdej iteracji wyodrębnia sekwencję o długości window_size z tablicy i dołącza ją do X. Ta sekwencja służy jako jedna próbka wejściowa. Wartość wyjściowa (etykieta) odpowiadająca każdej sekwencji wejściowej jest następną wartością bezpośrednio po sekwencji w DataFrame. Wartość ta jest dołączana do y.
Przykład:
X=[1,2,3,4,5], y=6
X=[2,3,4,5,6], y=7
X=[3,4,5,6,7], y=8
X=[4,5,6,7,8], y=9
i tak dalej…
def df_to_X_y(df, window_size=5):
df_as_np = df.to_numpy()
X = []
y = []
for i in range(len(df_as_np)-window_size):
row = [[a] for a in df_as_np[i:i+window_size]]
X.append(row)
label = df_as_np[i+window_size]
y.append(label)
return np.array(X), np.array(y)WINDOW_SIZE = 5
X1, y1 = df_to_X_y(df2, WINDOW_SIZE)
X1.shape, y1.shape
print(y1)[143636. 152225. 227854. 263121. 157869. 136315. 132266. 120609. 141955.
220308. 251345. 158492. 136240. 143371. 115821. 135214. 204449. 231483.
141976. 128256. 129324. 113870. 137022. 209541. 245481. 182638. 154284.
149974. 134005. 167256. 207438. 152830. 133559. 157846. 154782. 132974.
144742. 190061. 219933. 166667. 150444. 142628. 124212. 146081. 203285.
234842. 153189. 134845. 137272. 120695. 137555. 208705. 229672. 158195.
179419. 170183. 135577. 152201. 227024. 245308. 155266. 132163. 137198.
119723. 141062. 201038. 223273. 144170. 135828. 147195. 121907. 143712.
202664. 216151. 148126. 130755. 148247. 149854. 149515. 182196. 195375.
143196. 130183. 129972. 129134. 178237. 247315. 280881. 168081. 146023.
145034. 122792. 149302. 209669. 236767. 146607. 134193. 138348. 115020.
136320. 186935. 308788. 303298. 301533. 249845. 213186. 191154. 233084.
238503. 148627. 135431. 136526. 114193. 146007. 232805. 282785. 181088.
161856. 154805. 135208. 155813. 233769. 193033. 167064. 142775. 146886.
125988. 138176. 206787. 247562. 159437. 135697. 133039. 120632. 140732.
198856. 235966. 146066. 118786. 119655. 118074. 173865. 169401. 210425.
154183. 189942. 144778. 136640. 136752. 200698. 237485. 143265. 122148.
123561. 103888. 120510. 177120. 209344. 145511. 122071. 130428. 117386.
138623. 201641. 188682. 156605. 144562. 130519. 110900. 127196. 186097.
211047. 143453. 120127. 120697. 111342. 163624. 221451. 240162. 171926.
141837. 141899. 117203. 137729. 186086. 205290. 148417. 127538. 120720.
108521. 139563. 191821. 206438. 148214. 123942. 128434. 115017. 129281.
178923. 188675. 148783. 124377. 132795. 107270. 133460. 191957. 216431.
180546. 152668. 145874. 128160. 148293. 193330. 206605. 157126. 137263.
138205. 135983. 164500. 166578. 180725. 158646. 147799. 147254. 127986.
150082. 187625. 211220. 155457. 142435. 141334. 124207. 134789. 176165.
197233. 147156. 133625. 145155. 147069. 181079. 238510. 261398. 183848.
164550. 154897. 123746. 138299. 206418. 235684. 145080. 122882. 121120.
116264. 143598. 200090. 235321. 141236. 132262. 129414. 110130. 136138.
192610. 221098. 143488. 122181. 123595. 112182. 142867. 251375. 279121.
172823. 146150. 146410. 120057. 143269. 202566. 247109. 153350. 125318.
129236. 111697. 138234. 197333. 258559. 151406. 129897. 127212. 124603.
144526. 192343. 241561. 142098. 124323. 128716. 120153. 136370. 194747.
232250. 148589. 182070. 215033. 180293. 193535. 208685. 270422. 187162.
166081. 164618. 129184. 150597. 222661. 291398. 165265. 160177. 181322.
138887. 167311. 220970. 278158. 172392. 151843. 157465. 133102. 170648.
223057. 263835. 177635. 140124. 164748. 178953. 185360. 255126. 297968.
182323. 207703. 178510. 140546. 163758. 209125. 260947. 168443. 148518.
159319. 146315. 169151. 226210. 270298. 196844. 194254. 198153. 198308.
226894. 236331. 227027. 177554. 192477. 186177. 240693. 243518. 4008.
335235. 243422. 211239. 175975. 189393. 261820. 297197. 186203. 171274.
164531. 145461. 174206. 252034. 301353. 199820. 184129. 176227. 144535.
162192. 264633. 299512. 191891. 167718. 160219. 125294. 156006. 226837.
257357. 155191. 165171. 192241. 155016. 173306. 256450. 265030. 171537.
156490. 161764. 132978. 164050. 220696. 255490. 169350. 129329. 147599.
137081. 156814. 246049. 213733. 167601. 157364. 148629. 149845. 182391.
230937. 168924. 165020. 212594. 204522. 180400. 186437. 257990. 276118.
169456. 157163. 150271. 147502. 177393. 245596. 288397. 178705. 163684.
173812. 164418. 188890. 259101. 297490. 192579. 172289. 167424. 153886.
182043. 257097. 284616. 188293. 164975. 177997. 136349. 188660. 336063.
264738. 188774. 184424. 181898. 153189. 171158. 228604. 262298. 170621.
163715. 171716. 177420. 179465. 216599. 233163. 175805. 158029. 149701.
144429. 169675. 236707. 285611. 175184. 161949. 164587. 143934. 180469.
250534. 249008. 303807. 200529. 188754. 149629. 161279. 233814. 287104.
166843. 145619. 147196. 135028. 154026. 244193. 206986. 179114. 169098.
165675. 133381. 161718. 227900. 280849. 169143. 151437. 153706. 136779.
212870. 212127. 254132. 171962. 158403. 174304. 166771. 204402. 278488.
339352. 214773. 184706. 181931. 152212. 178063. 242234. 311184. 176821.
158624. 158633. 142765. 181072. 250214. 245520. 179095. 173553. 154251.
125467. 160086. 218486. 263497. 166889. 140339. 143776. 136268. 170346.
271027. 297619. 199766. 173857. 170074. 150965. 178964. 232222. 262375.
179826. 162466. 158262. 149968. 181719. 246513. 283097. 193199. 170182.
163361. 163747. 183117. 229380. 245466. 188077. 160403. 156176. 141686.
191922. 249085. 274030. 195504. 215546. 204566. 156806. 187818. 225481.
250784. 179419. 160636. 153010. 156449. 189111. 182318. 202354. 174832.
170773.]TimeSeriesGenerator
The TimeseriesGenerator narzędzie z biblioteki Keras w TensorFlow jest potężnym narzędziem do generowania partii danych czasowych. Narzędzie to jest szczególnie przydatne podczas pracy z problemami przewidywania sekwencji obejmującymi dane szeregów czasowych. Ma to na celu uproszczenie tworzenia instancji TimeseriesGenerator dla danego zbioru danych.
Parametry
data: Zestaw danych używany do generowania sekwencji wejściowychtargets: Zbiór danych zawierający cele (lub etykiety) dla każdej sekwencji wejściowej; W wielu zadaniach prognozowania szeregów czasowych cele są takie same jak dane, ponieważ próbują Państwo przewidzieć następną wartość w tej samej serii.length: Liczba kroków czasowych w każdej sekwencji wejściowej (określona przezn_input).batch_size: Liczba sekwencji do zwrócenia na partię (tutaj ustawiona na 1, co oznacza, że generator daje jedną parę wejście-cel na partię).
Zalety
Korzystanie z TimeseriesGenerator oferuje kilka korzyści:
- Wydajność pamięci: Generuje partie danych w locie, a zatem jest bardziej wydajny pod względem pamięci niż wstępne generowanie i przechowywanie wszystkich możliwych sekwencji.
- Łatwość użycia: Bezproblemowo integruje się z modelami Keras, szczególnie podczas korzystania z procedur uczenia modeli, takich jak
fit_generator. - Elastyczność: Może obsługiwać różne długości sekwencji wejściowych i może łatwo dostosować się do różnych horyzontów prognozy.
def ts_generator(dataset,n_input):
generator=TSG(dataset,dataset,length=n_input,batch_size=1)
return generator#Number of steps to use for predicting the next step
WINDOW_SIZE = 30
#This defines the number of features, in our case it is one and it should be sames as the count of neurons in the Dense Layer
n_features=1
generator=ts_generator(df2,WINDOW_SIZE)Podany fragment kodu iteruje po sekwencji TimeseriesGenerator zbierając i agregując wszystkie partie do dwóch dużych tablic NumPy: X_val dla danych wejściowych i y_val dla celów.
X_val,y_val=generator[0]
for i in range(len(generator)):
X2, Y2 = generator[i]
print("X:", X2)
#print("Y:", type(Y))
X_val = np.vstack((X_val, X2))
y_val = np.vstack((y_val, Y2))
X_val=X_val[1:]
y_val=y_val[1:]
X_val=X_val.reshape(X_val.shape[0],WINDOW_SIZE,n_features)
y_val=y_val.flatten()
print(X_val.shape)
print(y_val)Proszę podzielić ten zbiór danych na zestawy treningowe, walidacyjne i testowe w oparciu o procent całkowitej długości zbioru danych.
#l_percent is set to 85%, marking the cutoff for the training set.
#h_percent is set to 90%, marking the end of the validation set and the beginning of the test set.
l_percent=0.85
h_percent=0.90
#l_cnt is the index at 85% of df2, used to separate the training set from the validation set.
#h_cnt is the index at 90% of df2, used to separate the validation set from the testing set.
l_cnt=round(l_percent * len(df2))
h_cnt=round(h_percent * len(df2))
#Splits for dataset creation
val_sales,val_target=X_val[l_cnt:h_cnt],y_val[l_cnt:h_cnt]
train_sales,train_target=X_val[:l_cnt],y_val[:l_cnt]
test_sales,test_traget=X_val[h_cnt:],y_val[h_cnt:]
print(val_sales.shape,val_target.shape,train_sales.shape,train_target.shape,test_sales.shape,test_traget.shape)
(30, 30, 1) (30,) (502, 30, 1) (502,) (29, 30, 1) (29,)
Konfiguracja modelu głębokiego uczenia przy użyciu Keras (backend TensorFlow) dla zadania prognozowania szeregów czasowych
Poniższy kod konfiguruje model głębokiego uczenia przy użyciu Keras (backend TensorFlow) dla zadania prognozowania szeregów czasowych, integrując wywołania zwrotne w celu lepszego zarządzania treningiem i definiując sieć neuronową opartą na LSTM.
Konfiguracja wywołań zwrotnych
EarlyStopping: Zatrzymuje szkolenie, gdy monitorowana metryka przestanie się poprawiać po określonej liczbie epok (cierpliwość = 50); Pomaga to uniknąć nadmiernego dopasowania i oszczędza zasoby obliczeniowe.ReduceLROnPlateau: Zmniejsza szybkość uczenia się, gdy metryka przestała się poprawiać, co może prowadzić do dokładniejszego dostrojenia modeli. Zmniejsza współczynnik uczenia się o współczynnik 0,25 po osiągnięciu plateau wydajności przez 25 epok, przy minimalnym współczynniku uczenia ustawionym na 1e-9 (0,000000001).ModelCheckpoint: Zapisuje model po każdej epoce, ale tylko wtedy, gdy jest najlepszy do tej pory (pod względem strat na zestawie walidacyjnym). Zapisuje tylko wagi do katalogu o nazwiemodel/, co pomaga zarówno zaoszczędzić miejsce, jak i potencjalnie uniknąć problemów, gdy architektura modelu zmienia się, ale skrypt treningowy nie.
Konfiguracja warstwy
Layer1: Pierwsza warstwa LSTM ma 128 jednostek i zwraca sekwencje. Oznacza to, że zwróci pełną sekwencję do następnej warstwy, a nie tylko dane wyjściowe ostatniego kroku czasowego. Ta konfiguracja jest często używana podczas układania warstw LSTM. Wykorzystuje ona aktywację ReLU i zawiera dropout i recurrent dropout o wartości 0,2, aby przeciwdziałać nadmiernemu dopasowaniu.Layer2: Druga warstwa LSTM ma 64 jednostki i nie zwraca sekwencji, co wskazuje, że jest to ostatnia warstwa LSTM i zwraca dane wyjściowe tylko z ostatniego kroku czasowego. Podobnie jak pierwsza warstwa LSTM, wykorzystuje ona aktywację ReLU z ustawieniami dropout i recurrent dropout.Layer3: Gęsta warstwa z 64 jednostkami działa jako w pełni połączona warstwa sieci neuronowej następująca po warstwach LSTM w celu interpretacji cech wyodrębnionych z sekwencji.Layer4: Ostatnia gęsta warstwa z pojedynczą jednostką jest typowa dla zadań regresji w szeregach czasowych, gdzie przewiduje się pojedynczą wartość ciągłą.
Zwykle funkcja ReLU jest używana z warstwami LSTM, ale widziałem lepsze wyniki z warstwami LSTM. tanh w analizie wstępnej, więc uwzględniłem to.
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
callbacks = [
EarlyStopping(patience=20, verbose=1),
ReduceLROnPlateau(factor=0.25, patience=10, min_lr=0.000000001, verbose=1),
ModelCheckpoint('model/', verbose=1, save_best_only=True, save_weights_only=True)
]
model=Sequential()
model.add(LSTM(128,activation='tanh',dropout=0.2, recurrent_dropout=0.2,return_sequences=True,input_shape=(WINDOW_SIZE,n_features)))
model.add(LSTM(64, activation= 'tanh', dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(64))
model.add(Dense(n_features))
model.summary()Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_16 (LSTM) (None, 30, 128) 66560
lstm_17 (LSTM) (None, 64) 49408
dense_15 (Dense) (None, 64) 4160
dense_16 (Dense) (None, 1) 65
=================================================================
Total params: 120193 (469.50 KB)
Trainable params: 120193 (469.50 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Proszę skompilować model Keras z określonymi ustawieniami optymalizatora, funkcji straty i metryk oceny.
Optymalizator
optimizers.Adam(lr=.000001): Określa on optymalizator Adam ze współczynnikiem uczenia (lr) równym 0,000001. Adam to adaptacyjny algorytm optymalizacji współczynnika uczenia, który stał się domyślnym optymalizatorem dla wielu typów sieci neuronowych, ponieważ łączy najlepsze właściwości algorytmów AdaGrad i RMSProp w celu obsługi rzadkich gradientów w zaszumionych problemach.- Współczynnik uczenia: Ustawienie współczynnika uczenia na bardzo małą wartość, np. 0,000001, sprawia, że uczenie modelu wykonuje mniejsze kroki w celu aktualizacji wag, co może prowadzić do bardzo powolnej zbieżności. Ta niska wartość jest używana, gdy trzeba precyzyjnie dostroić model lub podczas uczenia modelu, w którym większe kroki mogą spowodować przekroczenie minimów w procesie uczenia.
Funkcja straty
loss="mse": Ustawia funkcję straty na średni błąd kwadratowy (MSE), który jest powszechnie stosowany w zadaniach regresji. MSE oblicza średnią kwadratową różnicę między szacowanymi wartościami a rzeczywistą wartością, dzięki czemu jest wrażliwy na wartości odstające, ponieważ kwadratuje błędy.
# Compile the model
#cp1 = ModelCheckpoint('model/', save_best_only=True)
model.compile(optimizer=optimizers.Adam(lr=.000001), loss="mse", metrics = ['mean_squared_error'])Określa sposób przeprowadzania szkolenia, w tym zestawy danych do wykorzystania, liczbę epok szkoleniowych i wszelkie wywołania zwrotne, które należy zastosować podczas procesu szkolenia.
epochs=200: Liczba cykli, w których model przejdzie przez cały zestaw danych szkoleniowych.
model.fit(train_sales, train_target, validation_data=(val_sales, val_target) ,epochs=200, callbacks=callbacks)Epoch 1/200 16/16 [==============================] - 1s 72ms/step - loss: 0.0055 - mean_squared_error: 0.0055 - val_loss: 0.0110 - val_mean_squared_error: 0.0110 Epoch 2/200 16/16 [==============================] - 2s 98ms/step - loss: 0.0063 - mean_squared_error: 0.0063 - val_loss: 0.0067 - val_mean_squared_error: 0.0067 Epoch 3/200 16/16 [==============================] - 1s 71ms/step - loss: 0.0062 - mean_squared_error: 0.0062 - val_loss: 0.0119 - val_mean_squared_error: 0.0119 Epoch 4/200 16/16 [==============================] - 1s 71ms/step - loss: 0.0058 - mean_squared_error: 0.0058 - val_loss: 0.0097 - val_mean_squared_error: 0.0097
training_loss_per_epoch: Pobiera stratę treningową dla każdej epoki z obiektu historii modelu. Strata szkoleniowa jest miarą tego, jak dobrze model pasuje do danych szkoleniowych, zmniejszając się z czasem, gdy model się uczy.validation_loss_per_epoch: Podobnie, w tym miejscu pobierana jest strata walidacyjna dla każdej epoki. Utrata walidacyjna mierzy, jak dobrze model działa na nowym, niewidocznym zestawie danych (zestaw danych walidacyjnych), co pomaga monitorować nadmierne dopasowanie.- Overfitting: Jeśli strata szkoleniowa nadal maleje, ale strata walidacyjna zaczyna rosnąć, może to oznaczać, że model jest nadmiernie dopasowany do danych szkoleniowych.
- Niedopasowanie: Jeśli zarówno straty treningowe, jak i walidacyjne pozostają wysokie, może to sugerować, że model jest niedopasowany i nie uczy się odpowiednio na podstawie danych treningowych.
- Wczesne zatrzymanie: Badając te krzywe, można również podejmować decyzje o zastosowaniu wczesnego zatrzymania w celu zatrzymania szkolenia w optymalnym punkcie, zanim model zostanie nadmiernie dopasowany.
training_loss_per_epoch=model.history.history['loss']
validation_loss_per_epoch=model.history.history['val_loss']
plt.plot(range(len(training_loss_per_epoch)),training_loss_per_epoch)
plt.plot(range(len(validation_loss_per_epoch)),validation_loss_per_epoch)load_model to funkcja z Keras, która pozwala załadować kompletny model zapisany w formacie Keras TensorFlow. Obejmuje to nie tylko architekturę modelu, ale także jego wyuczone wagi i konfigurację uczenia (strata, optymalizator).
from tensorflow.keras.models import load_model
model1=load_model('model/')Pobieranie dat z oryginalnej ramki DataFrame, aby ustawić ją w przewidywaniach pod kątem widoczności. Ponieważ używamy okna o rozmiarze 30, pierwsze dane wyjściowe / cel / prognoza zostaną wygenerowane po window_size. W związku z tym proszę manipulować datami dla wszystkich trzech zestawów danych.
Poniższy kod ma na celu wyodrębnienie określonych zakresów dat z DataFrame w celu dostosowania ich do odpowiednich zestawów danych szkoleniowych, walidacyjnych i testowych. Jest to szczególnie przydatne, gdy chcą Państwo śledzić lub analizować wyniki w czasie lub powiązać je z określonymi zdarzeniami lub zmianami odzwierciedlonymi przez daty.
date_df=df1[df1['sales_BEVERAGES']>20000]
date_df.count()
####Fetching the dates from the df1 for the train dataset
train_date=date_df['date'][WINDOW_SIZE - 1:l_cnt + WINDOW_SIZE - 1]
print(train_date.count())
####Fetching the dates from the df1 for the val dataset
val_date=date_df['date'][l_cnt + WINDOW_SIZE - 1:h_cnt + WINDOW_SIZE - 1:]
print(val_date.count())
u_date=h_cnt + 1 + WINDOW_SIZE -1
test_date=df1['date'][h_cnt + WINDOW_SIZE - 1: ]
test_date.count()Dane treningowe Wartość rzeczywista a wartość przewidywana
#This function is used to generate predictions from your pre-trained model on the train_sales dataset.
train_predictions = model1.predict(train_sales).flatten()
# Applies the inverse transformation to the scaled predictions to bring them back to their original scale.
train_pred=scaler.inverse_transform(train_predictions.reshape(-1, 1))
t=scaler.inverse_transform(train_target.reshape(-1, 1))
#print(train_pred.shape)
#Creating a dataframe with Actual and predictions
train_results = pd.DataFrame(data={'Train Predictions':train_pred.flatten(), 'Actuals':t.flatten(),'dt':train_date })
train_results.tail(20)16/16 [==============================] - 0s 14ms/step (502, 1)
| Trenowanie przewidywań | Rzeczywiste | dt | |
|---|---|---|---|
| 512 | 195323.593750 | 171962.000000 | 2017-05-29 |
| 513 | 164753.343750 | 158403.000000 | 2017-05-30 |
| 514 | 155985.328125 | 174304.000000 | 2017-05-31 |
| 515 | 153953.828125 | 166771.000000 | 2017-06-01 |
| 516 | 184015.109375 | 204402.000000 | 2017-06-02 |
| 517 | 246616.375000 | 278488.000000 | 2017-06-03 |
| 518 | 251735.953125 | 339352.000000 | 2017-06-04 |
| 519 | 187089.109375 | 214773.000000 | 2017-06-05 |
| 520 | 169009.390625 | 184706.000000 | 2017-06-06 |
| 521 | 160138.390625 | 181931.000000 | 2017-06-07 |
| 522 | 158093.562500 | 152212.000000 | 2017-06-08 |
| 523 | 186708.203125 | 178063.015625 | 2017-06-09 |
| 524 | 254521.234375 | 242234.000000 | 2017-06-10 |
| 525 | 263513.468750 | 311184.000000 | 2017-06-11 |
| 526 | 191338.093750 | 176820.984375 | 2017-06-12 |
| 527 | 168676.562500 | 158624.000000 | 2017-06-13 |
| 528 | 158633.203125 | 158633.000000 | 2017-06-14 |
| 529 | 153251.765625 | 142765.000000 | 2017-06-15 |
| 530 | 180730.171875 | 181071.984375 | 2017-06-16 |
| 531 | 251409.359375 | 250214.000000 | 2017-06-17 |
Poniżej znajduje się graficzna reprezentacja rzeczywistych i przewidywanych wartości danych treningowych dla pierwszych 100 wskaźników:
plt.plot(train_results['dt'][:100],train_results['Train Predictions'][:100],label="pred")
plt.plot(train_results['dt'][:100],train_results['Actuals'][:100],label="Actual")
plt.legend()
plt.xticks(rotation=45)
plt.plot(figsize=(18,10))
plt.show()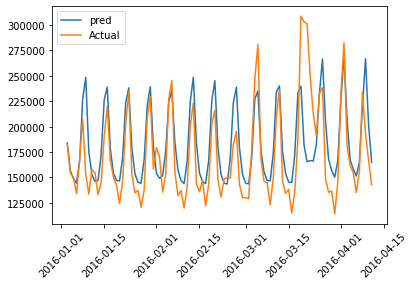
Dane walidacyjne Wartość rzeczywista a wartość przewidywana
##This function is used to generate predictions from your pre-trained model on the validation dataset.
val_predictions = model1.predict(val_sales).flatten()
# Applies the inverse transformation to the scaled predictions to bring them back to their original scale.
val_pred=scaler.inverse_transform(val_predictions.reshape(-1, 1))
v=scaler.inverse_transform(val_target.reshape(-1, 1))
print(val_pred.shape)
#Creating a dataframe with Actual and predictions
val_results = pd.DataFrame(data={'Val Predictions':val_pred.flatten(), 'Actuals':v.flatten(),'dt':val_date })
val_results.head()1/1 [==============================] - 0s 62ms/step (30, 1)
| Val Predictions | Rzeczywiste | dt | |
|---|---|---|---|
| 532 | 265612.906250 | 245519.984375 | 2017-06-18 |
| 533 | 186157.468750 | 179094.984375 | 2017-06-19 |
| 534 | 167559.578125 | 173553.000000 | 2017-06-20 |
| 535 | 158167.000000 | 154251.000000 | 2017-06-21 |
| 536 | 155162.000000 | 125467.000000 | 2017-06-22 |
Poniżej znajduje się graficzne przedstawienie rzeczywistych i przewidywanych wartości danych walidacyjnych:
plt.plot(val_results['dt'],val_results['Val Predictions'],label="pred")
plt.plot(val_results['dt'],val_results['Actuals'],label="Actual")
plt.legend()
plt.xticks(rotation=45)
plt.plot(figsize=(18,10))
plt.show()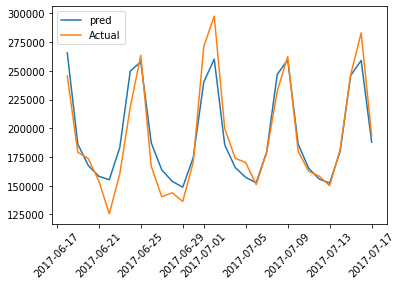
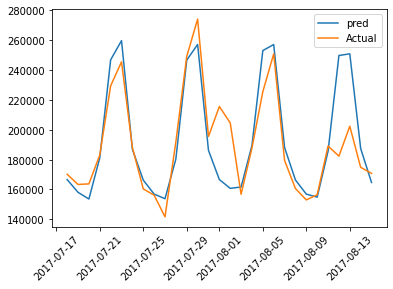
Dane testowe Wartość rzeczywista a wartość przewidywana
#This function is used to generate predictions from your pre-trained model on the test dataset.
test_predictions = model1.predict(test_sales).flatten()
# Applies the inverse transformation to the scaled predictions to bring them back to their original scale.
test_pred=scaler.inverse_transform(test_predictions.reshape(-1, 1))
te=scaler.inverse_transform(test_traget.reshape(-1, 1))
print(test_pred.shape)
#Creating a dataframe with Actual and predictions
test_results = pd.DataFrame(data={'Test Predictions':test_pred.flatten(), 'Actuals':te.flatten(),'dt':test_date })
test_results.head()1/1 [==============================] - 0s 35ms/step (29, 1)
| Przewidywania testowe | Rzeczywiste | dt | |
|---|---|---|---|
| 562 | 166612.140625 | 170182.000000 | 2017-07-18 |
| 563 | 158095.812500 | 163361.000000 | 2017-07-19 |
| 564 | 153619.515625 | 163747.000000 | 2017-07-20 |
| 565 | 181217.421875 | 183117.015625 | 2017-07-21 |
| 566 | 246784.828125 | 229380.000000 | 2017-07-22 |
plt.plot(test_results['dt'],test_results['Test Predictions'],label="pred")
plt.plot(test_results['dt'],test_results['Actuals'],label="Actual")
plt.legend()
plt.xticks(rotation=45)
plt.plot(figsize=(18,10))
plt.show()