
Batch and Stream: Wprowadzenie
Batching to sprawdzone podejście do przetwarzania i pozyskiwania danych. Przetwarzanie wsadowe polega na pobraniu ograniczonych (skończonych) danych wejściowych, uruchomieniu na nich zadania w celu przetworzenia i wygenerowania pewnych danych wyjściowych. Sukces jest zazwyczaj mierzony przepustowością i jakością danych.
Zadania wsadowe mogą być uruchamiane sekwencyjnie i są zazwyczaj wykonywane zgodnie z harmonogramem. Ponieważ zadania wsadowe zazwyczaj wymagają gromadzenia danych w czasie i przetwarzania wielu danych jednocześnie, mogą one wprowadzać znaczne opóźnienia do systemu.
Z drugiej strony, przetwarzanie strumieniowe zużywa dane wejściowe i wytwarza dane wyjściowe w sposób ciągły. Zadania strumieniowe działają na “zdarzeniach”, krótko po ich wystąpieniu. Zdarzenia to małe, samodzielne, niezmienne obiekty zawierające szczegóły czegoś, co się wydarzyło. Zdarzenia te są często zarządzane przez brokera komunikatów, takiego jak Apache Kafka, gdzie są gromadzone, przechowywane i udostępniane konsumentom. Ten projekt rezygnuje z arbitralnego dzielenia danych według czasu, co pozwala na pozyskiwanie lub przetwarzanie danych w czasie zbliżonym do rzeczywistego.
Przetwarzanie strumieniowe wprowadza obawy związane z odpornością na błędy. W przeciwieństwie do procesu wsadowego, w którym dane wejściowe są skończone, a nieudane zadania można po prostu ponownie uruchomić, zadania strumieniowe działają na danych, które stale napływają. Różne frameworki przetwarzania strumieniowego przyjmują różne podejścia do tego problemu. Apache Flink okresowo generuje kroczące punkty kontrolne stanu i zapisuje je w trwałej pamięci masowej. W przypadku awarii procesy mogą zostać wznowione z punktu kontrolnego (zazwyczaj tworzonego co kilka sekund). Innym podejściem jest podzielenie zdarzeń na partie drugiej wielkości w procesie zwanym “mikrobatchingiem”. Apache Spark wykorzystuje tę technikę w swoim frameworku streamingowym.
Jak wybrać swój paradygmat
Podejmując decyzję o wdrożeniu potoków przetwarzania wsadowego lub potoków przetwarzania strumieniowego, należy zadać sobie dwa główne pytania.
Jakie są moje wymagania dotyczące opóźnień?
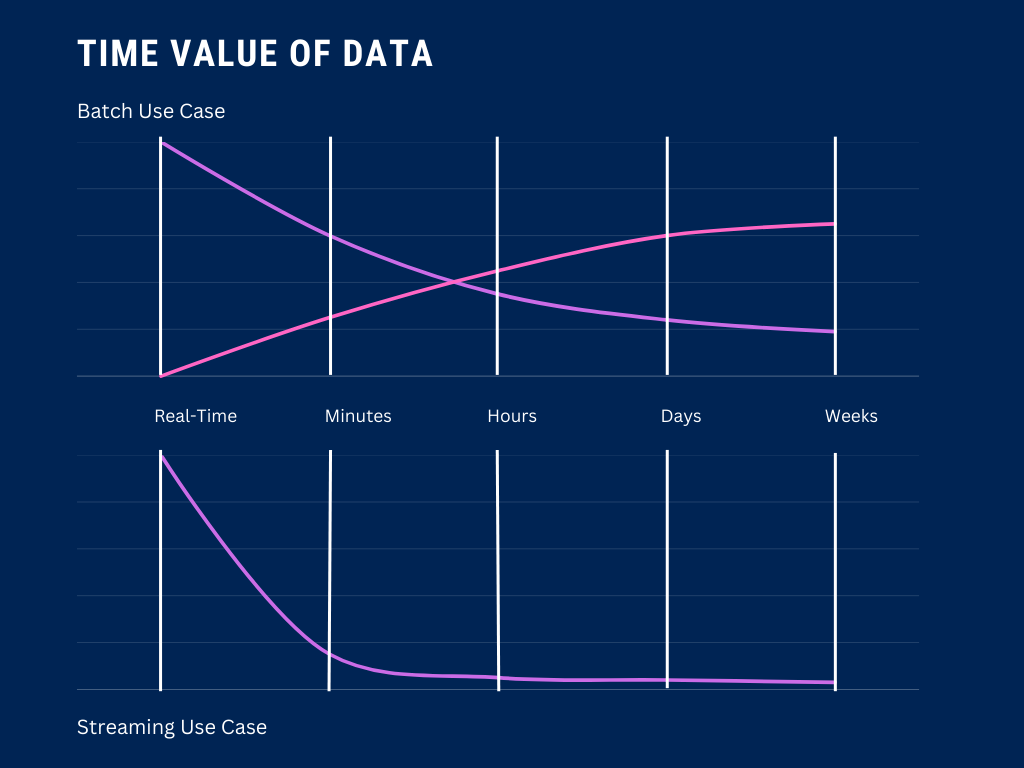
Aby zrozumieć, czy Państwa przypadek użycia może tolerować opóźnienia wprowadzane przez przetwarzanie wsadowe, warto zastanowić się nad wartością czasową danych. Jeśli wartość biznesowa danych spada w szybkim tempie w ciągu pierwszych kilku minut po ich emisji, przetwarzanie wsadowe nie powinno być Państwa pierwszym wyborem.
Prawda jest jednak taka, że większość procesów decyzyjnych nie odbywa się z sekundy na sekundę. Dlatego właśnie przetwarzanie wsadowe jest tak wszechobecne – niezależnie od tego, czy replikują Państwo bazę danych, tworzą raporty, czy aktualizują pulpity nawigacyjne, przetwarzanie wsadowe często wystarczy, aby wykonać zadanie.
Jakie zasoby są dostępne do budowy i utrzymania rurociągu?
Koszt jest ważnym czynnikiem w każdej architekturze. W chwili pisania tego tekstu, przetwarzanie wsadowe jest nadal bardziej opłacalne niż strumieniowe. Od optymalizacji zasobów po utrzymanie systemu i koszt wdrożenia, batch wygrywa pod względem przystępności cenowej.
Stream i Batch dla AI
Podczas tworzenia szkoleń i wdrażania własnych modeli sztucznej inteligencji, kwestia przetwarzania wsadowego lub strumieniowego nie jest już albo-albo. W tej sekcji zbadamy, w jaki sposób przetwarzanie wsadowe i strumieniowe współpracują ze sobą podczas fazy szkolenia i wdrażania.
Przetwarzanie wsadowe jest idealne podczas początkowego procesu szkolenia – zazwyczaj istnieje wiele danych historycznych, które należy pozyskać i przetworzyć. Po zakończeniu wstępnego szkolenia przetwarzanie strumieniowe jest doskonałym paradygmatem do trenowania modeli na danych w czasie rzeczywistym. Pozwala to na bardziej adaptacyjne, dynamiczne modele, które ewoluują wraz z napływem nowych danych.
Po wdrożeniu modelu wnioskowanie wsadowe może być wykorzystywane do przeprowadzania wnioskowania na dużych zbiorach danych, takich jak dzienne prognozy sprzedaży lub miesięczne oceny ryzyka. Streaming, z drugiej strony, może być wykorzystywany do wnioskowania w czasie rzeczywistym, co jest niezbędne do zadań takich jak wykrywanie anomalii i silniki rekomendacji w czasie rzeczywistym.
Oba paradygmaty odgrywają rolę w szkoleniu, wdrażaniu i utrzymywaniu wysokiej jakości modeli sztucznej inteligencji. Opanowanie obu jest niezbędne dla praktyków danych, których zadaniem jest wewnętrzne tworzenie aplikacji AI.
Wnioski
Wybierając między strumieniem a wsadem dla swoich potoków danych, należy poświęcić wystarczająco dużo czasu na zebranie wymagań, analizę dostępnych zasobów i zrozumienie potrzeb interesariuszy. To powinno ostatecznie zadecydować, które podejście Państwo wybiorą.
W Airbyte używamy paradygmatu przetwarzania wsadowego do przenoszenia Państwa danych. Jeśli chcą Państwo dowiedzieć się więcej, proszę zapoznać się z tym artykułem artykuł na temat CDC o tym, jak zsynchronizować magazyny danych.