
Uwaga wstępna: Współautorami tego artykułu są Federico Trotta oraz Karin Wolok.
Wprowadzenie
Przetwarzanie strumieniowe to rozproszony paradygmat obliczeniowy, który wspiera gromadzenie, przetwarzanie i analizę dużych i ciągłych strumieni danych w celu uzyskania wglądu w czasie rzeczywistym.
Ponieważ żyjemy w świecie, w którym coraz więcej danych “rodzi się” jako strumienie, umożliwiając analitykom wydobywanie spostrzeżeń w czasie rzeczywistym w celu szybszego podejmowania decyzji biznesowych, chcieliśmy zaproponować delikatne wprowadzenie do tego tematu.
Spis treści
- Definiowanie i rozumienie przetwarzania strumieniowego
- Obliczanie danych w przetwarzaniu strumieniowym
- Transformacje w przetwarzaniu strumieniowym
- Przypadki użycia przetwarzania strumieniowego
- Jak radzić sobie z przetwarzaniem strumieniowym: wprowadzenie do strumieniowych baz danych i systemów
- Wnioski
Definiowanie i rozumienie przetwarzania strumieniowego
Przetwarzanie strumieniowe to paradygmat programowania, który postrzega strumienie – zwane również “sekwencjami zdarzeń w czasie” – jako centralne obiekty wejściowe i wyjściowe obliczeń:
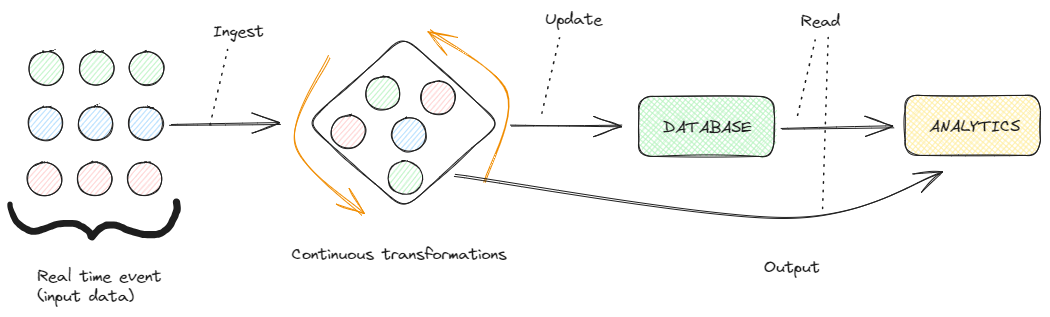
Przetwarzanie strumieniowe. Obraz autorstwa Federico Trotta
W przeciwieństwie do tradycyjnego przetwarzanie wsadowe – które obsługuje dane w kawałkach – przetwarzanie strumieniowe pozwala nam pracować z danymi jako ciągłym przepływem, dzięki czemu idealnie nadaje się do scenariuszy, w których natychmiastowość i szybkość reakcji mają fundamentalne znaczenie:
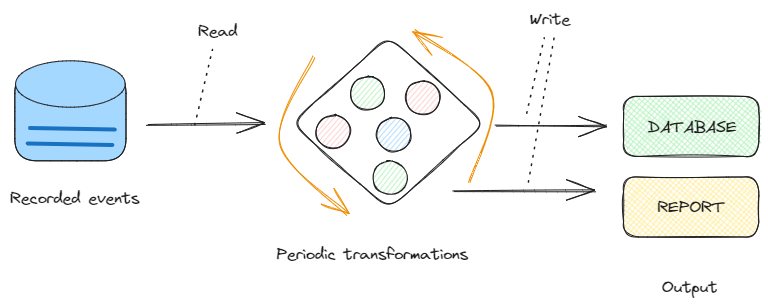
Przetwarzanie wsadowe. Obraz autorstwa Federico Trotta.
Tak więc przetwarzanie strumieniowe oznacza obliczanie i przetwarzanie danych w ruchu i w czasie rzeczywistym.
Jest to ważne w dzisiejszym świecie, ponieważ większość danych “rodzi się” jako ciągłe strumienie:
Strumień danych. Obraz autorstwa Federico Trotta
Pomyślmy o takich przypadkach, jak zdarzenia z czujników, aktywność użytkowników na stronie internetowej lub transakcje finansowe.
Czujniki, na przykład, stale zbierają dane ze środowiska, w którym są zainstalowane w czasie rzeczywistym. Zapewnia to aplikacje do monitorowania pogody, automatyki przemysłowej, urządzeń IoT i wielu innych.
Ponadto, jeśli myślimy o stronach internetowych, możemy powiedzieć, że są to platformy, na których użytkownicy dynamicznie angażują się w różne działania, takie jak klikanie, przewijanie, pisanie i inne. Te interakcje, które są generowane w sposób ciągły, są przechwytywane w czasie rzeczywistym w celu analizy zachowań użytkowników, poprawy komfortu użytkowania i wprowadzania dostosowań w odpowiednim czasie, aby wspomnieć tylko o kilku działaniach.
Na rynkach finansowych transakcje odbywają się dziś szybko i w sposób ciągły. Ceny akcji, wartości walut i inne wskaźniki finansowe stale się zmieniają i wymagają przetwarzania danych w czasie rzeczywistym w celu podejmowania szybkich decyzji.
Celem przetwarzania strumieniowego jest więc szybka analiza, filtrowanie, przekształcanie lub ulepszanie danych w czasie rzeczywistym.
Po przetworzeniu dane są przekazywane do aplikacji, magazynu danych lub innego silnika przetwarzania strumieniowego.
Obliczanie danych w przetwarzaniu strumieniowym
Biorąc pod uwagę charakter procesów strumieniowych, dane są przetwarzane na różne sposoby w odniesieniu do przetwarzania wsadowego.
Omówmy, w jaki sposób.
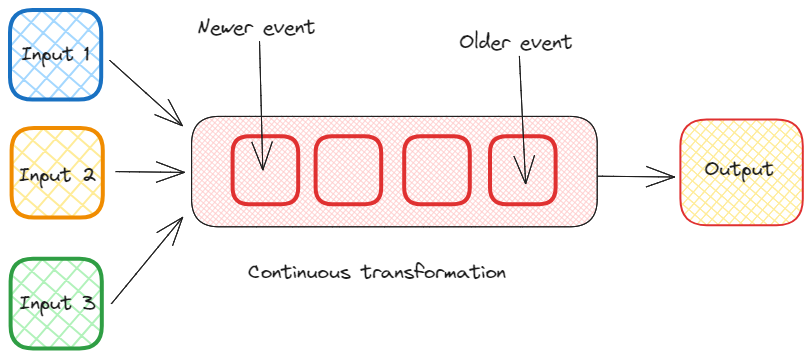
Obliczenia przyrostowe
Obliczenia przyrostowe to technika wykorzystywana do optymalizacji procesów obliczeniowych, umożliwiająca im przetwarzanie tylko tych części danych, które uległy zmianie od czasu poprzedniego obliczenia, zamiast ponownego obliczania całego wyniku od zera.
Technika ta jest szczególnie przydatna do oszczędzania zasobów obliczeniowych.
Obliczenia przyrostowe. Obraz autorstwa Federico Trotta.
W kontekście przetwarzania strumieniowego obliczenia przyrostowe obejmują ciągłe aktualizowanie wyników w miarę napływania nowych danych, zamiast ponownego obliczania wszystkiego od zera za każdym razem.
Aby podać przykład, powiedzmy, że mamy strumień danych z czujników z urządzeń IoT mierzących temperaturę w fabryce. Chcemy obliczyć średnią temperaturę w przesuwnym oknie czasu, na przykład średnią temperaturę w ciągu ostatnich 5 minut, i chcemy aktualizować tę średnią w czasie rzeczywistym, gdy napływają nowe dane z czujników.
Zamiast ponownie obliczać całą średnią za każdym razem, gdy napływają nowe dane, co może być kosztowne obliczeniowo, zwłaszcza gdy zbiór danych rośnie, możemy użyć obliczeń przyrostowych, aby skutecznie zaktualizować średnią.
Transformacje w przetwarzaniu strumieniowym
W kontekście przetwarzania strumieniowego możemy wykonywać różne zestawy przekształceń przychodzącego strumienia danych.
Niektóre z nich są typowymi przekształceniami, które zawsze możemy wykonać na danych, podczas gdy inne są specyficzne dla “przypadku czasu rzeczywistego”.
Wśród innych możemy wymienić następujące metodologie:
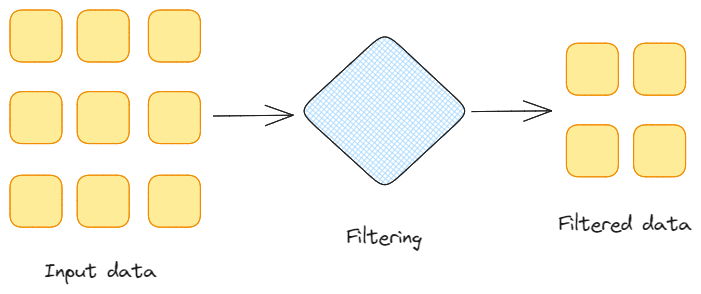
Filtrowanie danych. Obraz autorstwa Federico Trotta.
-
Agregacja: Obejmuje to sumowanie, uśrednianie, liczenie lub znajdowanie innej miary statystycznej w celu uzyskania wglądu w dany strumień danych w określonych odstępach czasu.
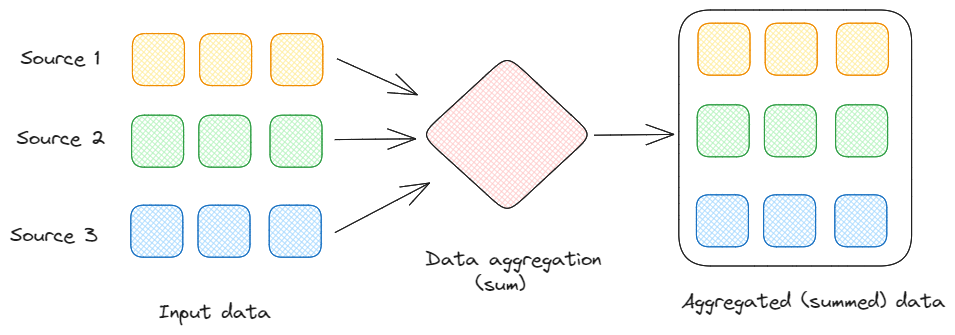
Agregacja danych. Obraz autorstwa Federico Trotta.
-
Wzbogacanie: Jest to czynność polegająca na ulepszaniu przychodzących danych poprzez dodawanie dodatkowych informacji ze źródeł zewnętrznych. Proces ten może zapewnić więcej kontekstu dla danych, czyniąc je bardziej wartościowymi dla dalszych aplikacji.
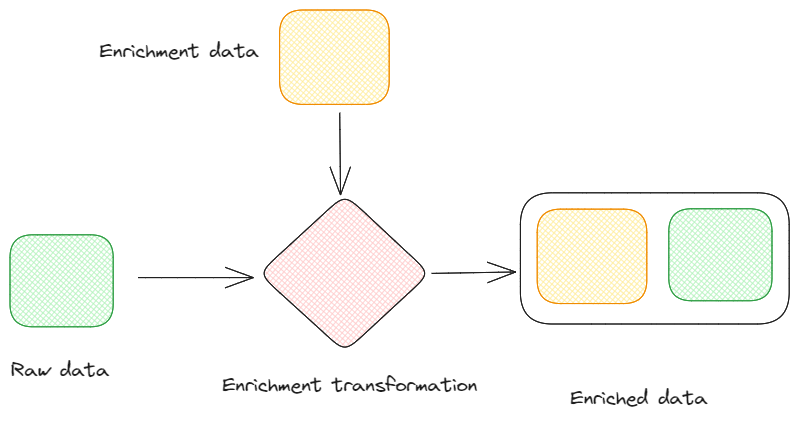
Wzbogacanie danych. Obraz autorstwa Federico Trotta.
-
Transformacja: Transformacja danych to ogólny sposób modyfikowania formatów danych. Dzięki tej metodologii stosujemy różne przekształcenia danych, takie jak konwersja formatów danych, normalizacja wartości lub wyodrębnianie określonych pól, zapewniając, że dane mają pożądany format do dalszej analizy lub integracji.
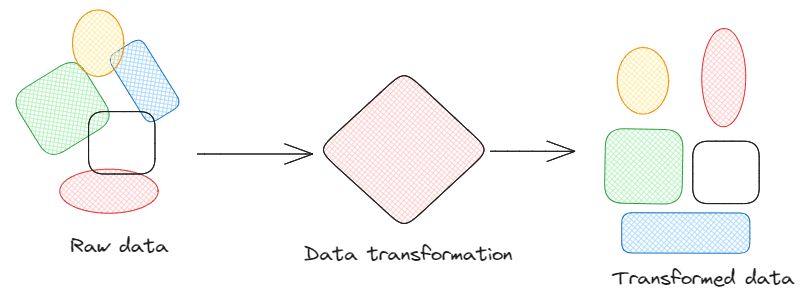
Transformacja danych. Obraz autorstwa Federico Trotta.
-
Windowing: Jest to czynność dzielenia ciągłego strumienia na dyskretne okna danych. Pozwala nam to analizować dane w określonych ramach czasowych, umożliwiając wykrywanie trendów i wzorców w różnych odstępach czasu.
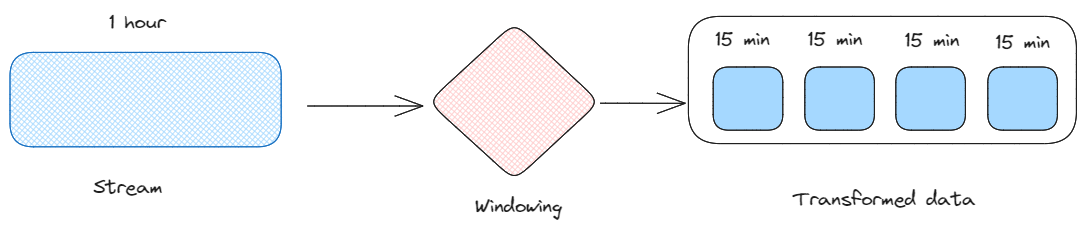
Windowing. Obraz autorstwa Federico Trotta.
-
Obciążenie, równoważenie i skalowanie: Jest to sposób na rozłożenie obciążenia przetwarzania na wiele węzłów w celu osiągnięcia skalowalności. Struktury przetwarzania strumieniowego w rzeczywistości często obsługują równoległość i obliczenia rozproszone w celu wydajnej obsługi dużych ilości danych.
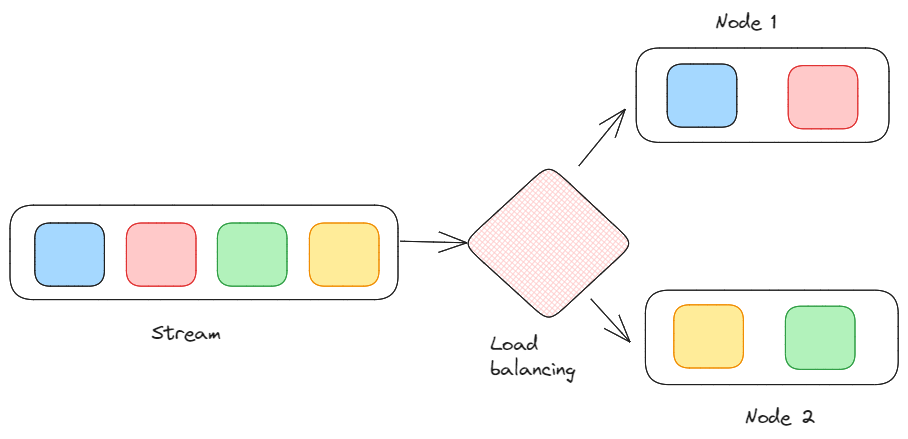
Proces obciążenia, równoważenia i skalowania. Obraz autorstwa Federico Trotta.
-
Państwowe przetwarzanie strumieniowe. Jest to rodzaj transformacji, który obejmuje przetwarzanie ciągłego strumienia danych w czasie rzeczywistym, przy jednoczesnym zachowaniu aktualnego stanu przetworzonych danych. Pozwala to systemowi przetwarzać każde otrzymane zdarzenie, jednocześnie śledząc zmiany w strumieniu danych w czasie, poprzez uwzględnienie historii i kontekstu danych.
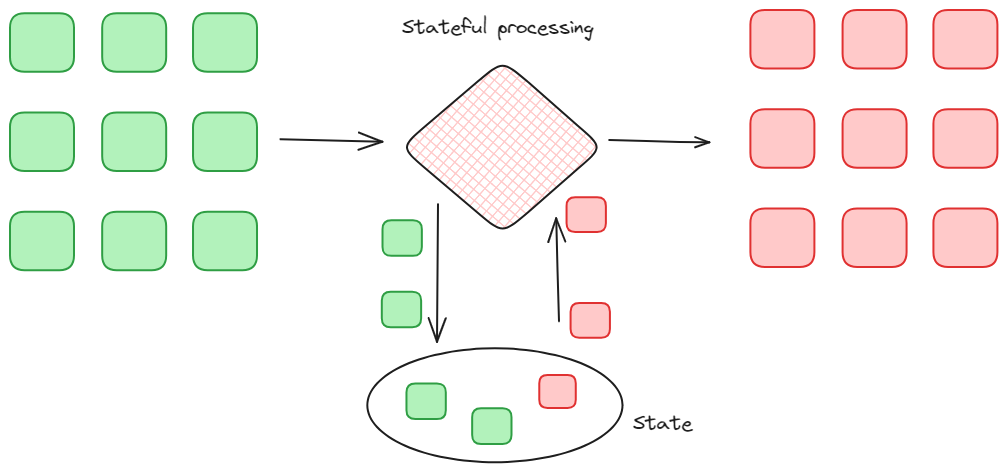
Przetwarzanie stanowe. Obraz autorstwa Federico Trotta.
-
Rozpoznawanie wzorców: Jak można zrozumieć, jest to rodzaj transformacji, która wyszukuje zestaw wzorców zdarzeń. Jest to szczególnie interesujące w przypadku strumieni danych, ponieważ dane są w ciągłym przepływie, ponieważ może również przechwytywać anomalie w przepływie.
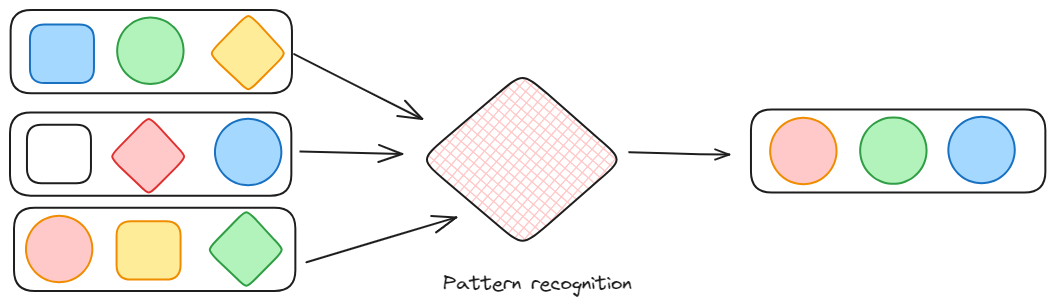
Rozpoznawanie wzorców przez Federico Trotta.
Przypadki użycia przetwarzania strumieniowego
Aby uzyskać głębsze zrozumienie przetwarzania strumieniowego, rozważmy kilka rzeczywistych przypadków użycia.
Przypadek użycia 1: Wykrywanie oszustw w transakcjach finansowych w czasie rzeczywistym
Ze względu na rosnącą liczbę transakcji online, oszuści stają się coraz bardziej wyrafinowani, a wykrywanie nieuczciwych działań w czasie rzeczywistym ma kluczowe znaczenie dla zapobiegania stratom finansowym i ochrony klientów.
W tym przypadku przetwarzanie strumieniowe jest stosowane do analizy przychodzących transakcji, w poszukiwaniu wzorców lub anomalii, które mogą wskazywać na nieuczciwe zachowania.
Na przykład, jeśli ktoś sklonuje Państwa kartę kredytową i kupi coś z lokalizacji po drugiej stronie świata, system rozpozna nieuczciwą transakcję dzięki przetwarzaniu strumieniowemu (i uczeniu maszynowemu).
Przypadek użycia 2: Analiza danych IoT na potrzeby konserwacji predykcyjnej
W dzisiejszym połączonym świecie urządzenia i czujniki generują ogromne ilości danych. W branżach takich jak produkcja, przewidywanie awarii sprzętu i przeprowadzanie proaktywnej konserwacji ma kluczowe znaczenie dla zminimalizowania przestojów i obniżenia kosztów operacyjnych.
W tym przypadku przetwarzanie strumieniowe jest wykorzystywane do analizy strumieni danych z czujników IoT, stosując algorytmy do wykrywania anomalii, analizy trendów i rozpoznawania wzorców. Pomaga to firmom we wczesnej identyfikacji potencjalnych awarii sprzętu lub odchyleń od normalnych warunków pracy.
Przypadek użycia 3: Wykrywanie i obsługa anomalii w systemach transakcyjnych
Systemy transakcyjne generują stały strumień danych finansowych, w tym ceny akcji, wolumeny obrotu i inne wskaźniki rynkowe.
Ponieważ wykrywanie anomalii jest kluczowym aspektem systemów transakcyjnych, pomagającym zidentyfikować nietypowe wzorce lub zachowania w danych finansowych, które mogą wskazywać na potencjalne problemy, błędy lub nieuczciwe działania, zaawansowane algorytmy są wykorzystywane do analizy strumienia danych w czasie rzeczywistym i identyfikacji wzorców, które odbiegają od normalnych zachowań rynkowych.
Przypadek użycia 4: Analiza reklam
W analityce reklamowej wykorzystanie strumieni danych ma fundamentalne znaczenie dla gromadzenia, przetwarzania i analizowania ogromnych ilości danych w czasie rzeczywistym w celu optymalizacji kampanii reklamowych, zrozumienia zachowań użytkowników i pomiaru skuteczności działań reklamowych.
Strumienie danych pozwalają reklamodawcom monitorować kampanie reklamowe w czasie rzeczywistym, a wskaźniki takie jak wyświetlenia, kliknięcia, konwersje i zaangażowanie mogą być stale śledzone, zapewniając natychmiastowy wgląd w wydajność zasobów reklamowych.
Jak radzić sobie z przetwarzaniem strumieniowym: Wprowadzenie do strumieniowych baz danych i systemów
Ponieważ przetwarzanie strumieniowe wiąże się z przetwarzaniem danych w czasie rzeczywistym, muszą one być zarządzane inaczej niż dane w partiach.
Mamy na myśli to, że “klasyczna” baza danych nie jest już wystarczająca. To, czego naprawdę potrzebujemy, to “ekosystem”: nie tylko baza danych, która może zarządzać danymi “w locie”.
W tej sekcji przedstawiamy kilka tematów i koncepcji, które zostaną pogłębione w nadchodzących, pogłębionych artykułach na temat systemów strumieniowych i baz danych.
Ksqldb
Apache Kafka “to rozproszona platforma strumieniowego przesyłania zdarzeń typu open source wykorzystywana przez tysiące firm do wysokowydajnych potoków danych, analizy strumieniowej, integracji danych i aplikacji o znaczeniu krytycznym”.
Kafka to w szczególności ekosystem, który zapewnia strumieniową bazę danych o nazwie “ksqldb”, ale także narzędzia i integracje, które pomagają inżynierom danych wdrożyć architekturę przetwarzania strumieniowego do istniejących źródeł danych.
Apache Flink
Apache Flink “jest frameworkiem i silnikiem przetwarzania rozproszonego do obliczeń stanowych na nieograniczonych i ograniczonych strumieniach danych. Flink został zaprojektowany do działania we wszystkich popularnych środowiskach klastrowych i wykonywania obliczeń z prędkością w pamięci i w dowolnej skali”.
W szczególności Apache Flink jest potężnym frameworkiem przetwarzania strumieniowego odpowiednim do analizy w czasie rzeczywistym i złożonego przetwarzania zdarzeń, podczas gdy Kafka jest rozproszoną platformą strumieniową wykorzystywaną głównie do tworzenia potoków danych w czasie rzeczywistym.
RisingWave
RisingWave “to rozproszona strumieniowa baza danych SQL, która umożliwia proste, wydajne i niezawodne przetwarzanie danych strumieniowych”.
RisingWave zmniejsza złożoność tworzenia aplikacji do przetwarzania strumieniowego, umożliwiając programistom wyrażanie skomplikowanej logiki przetwarzania strumieniowego za pomocą kaskadowych zmaterializowanych widoków. Co więcej, pozwala użytkownikom utrwalać dane bezpośrednio w systemie, eliminując potrzebę dostarczania wyników do zewnętrznych baz danych w celu przechowywania i obsługi zapytań.
W szczególnościRisingWave może gromadzić dane w czasie rzeczywistym z różnych aplikacji, czujników i urządzeń, aplikacji społecznościowych, stron internetowych i innych.
Wnioski
Jako delikatne wprowadzenie do przetwarzania strumieniowego, w tym artykule zdefiniowaliśmy, czym jest przetwarzanie strumieniowe, czym różni się od przetwarzania wsadowego i jak działają obliczenia w przetwarzaniu strumieniowym.
Opisaliśmy również kilka przypadków użycia, aby pokazać, w jaki sposób teoria procesów strumieniowych ma zastosowanie do rzeczywistych przykładów, takich jak produkcja i finanse.
Na koniec przedstawiliśmy kilka rozwiązań dotyczących wdrażania przetwarzania strumieniowego. W nadchodzących artykułach opiszemy, czym są systemy przetwarzania strumieniowego i strumieniowe bazy danych oraz jak wybrać ten, który odpowiada Państwa potrzebom biznesowym.