
Proszę sobie wyobrazić wyzwanie polegające na szybkim agregowaniu i przetwarzaniu dużych ilości danych z wielu systemów punktów sprzedaży (POS) w celu analizy w czasie rzeczywistym. W takich scenariuszach, w których szybkość ma krytyczne znaczenie, połączenie Kafki i ClickHouse staje się potężnym rozwiązaniem. Kafka wyróżnia się w obsłudze strumieni danych o wysokiej przepustowości, podczas gdy ClickHouse wyróżnia się błyskawicznymi możliwościami przetwarzania danych. Razem tworzą one potężny duet, umożliwiający tworzenie pulpitów analitycznych najwyższego poziomu, które zapewniają aktualne i kompleksowe informacje. W tym artykule zbadano, w jaki sposób Kafka i ClickHouse mogą zostać zintegrowane w celu przekształcenia ogromnej ilości danych. strumieni danych w wartościowe analizy w czasie rzeczywistym.
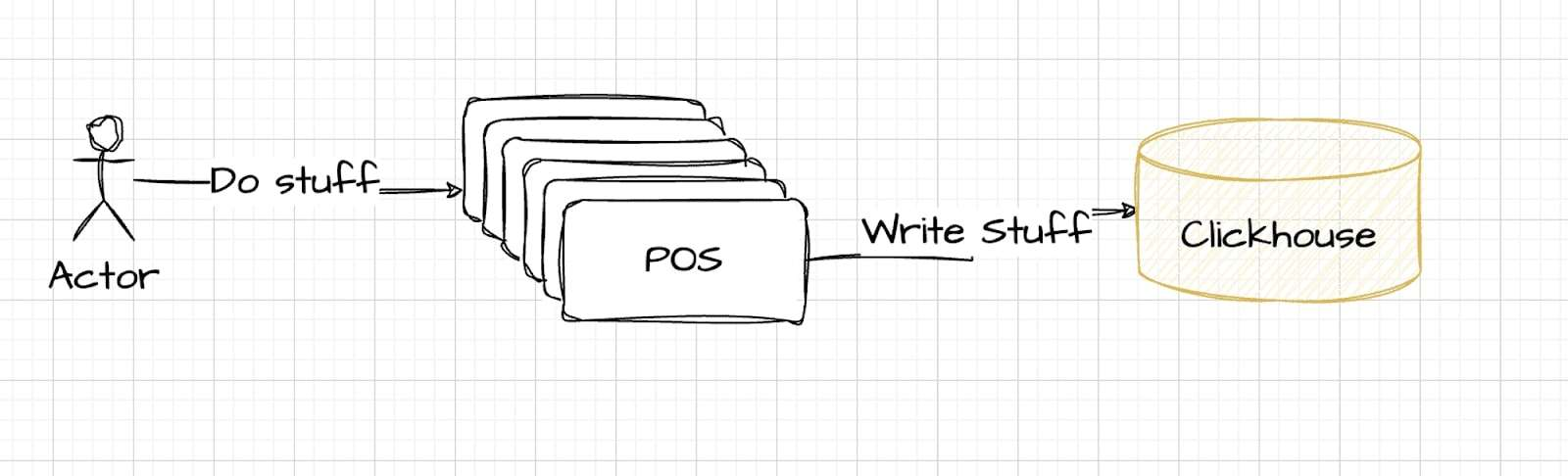
Ten diagram przedstawia początkowe, proste podejście: dane przepływają bezpośrednio z systemów POS do ClickHouse w celu przechowywania i analizy. Choć pozornie skuteczne, to nieco naiwne rozwiązanie może nie skalować się dobrze lub nie radzić sobie ze złożonością wymagań przetwarzania w czasie rzeczywistym, przygotowując grunt pod bardziej niezawodne rozwiązanie wykorzystujące Kafkę.
Zrozumienie wyzwań związanych z wprowadzaniem danych w ClickHouse
Proste podejście może doprowadzić Państwa do częstej pułapki lub pierwszego “grzechu śmiertelnego” podczas rozpoczynania pracy z ClickHouse (więcej szczegółów można znaleźć na stronie Typowe problemy związane z rozpoczęciem pracy z ClickHouse). Prawdopodobnie napotkają Państwo ten błąd podczas wstawiania danych, widoczny w logach ClickHouse lub jako odpowiedź na żądanie INSERT. Zrozumienie tego problemu wymaga znajomości architektury ClickHouse, a w szczególności pojęcia “części”.
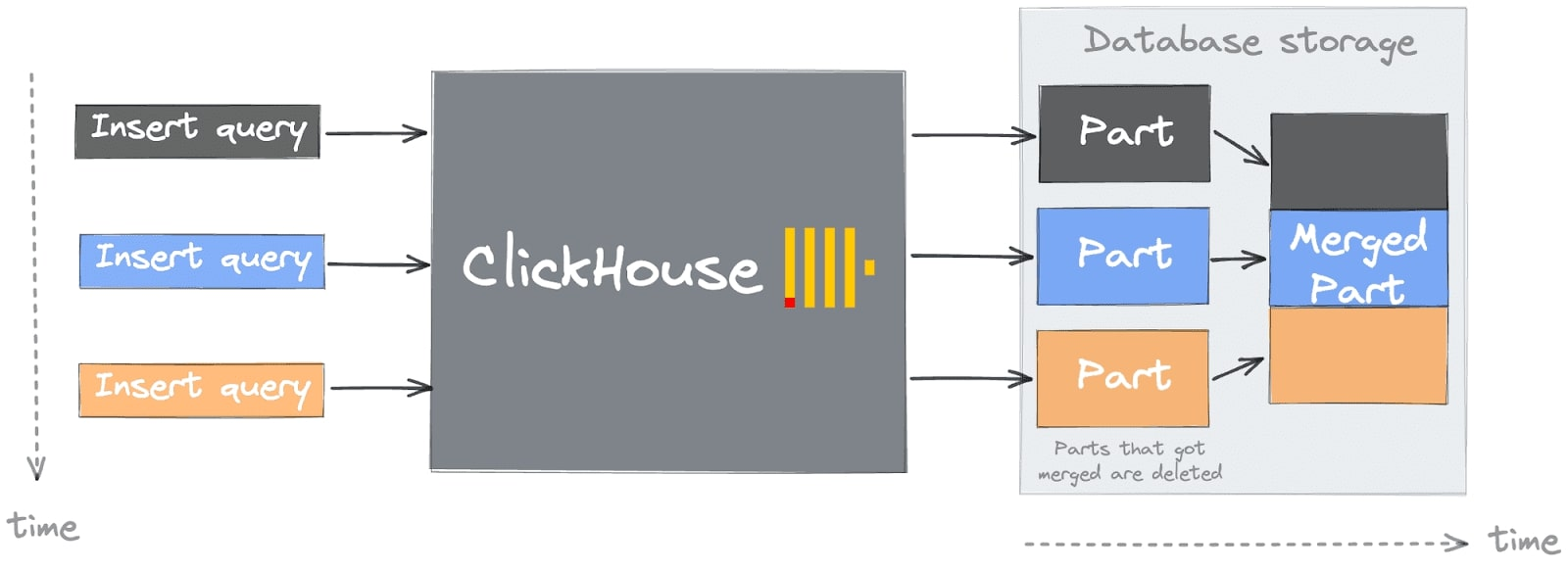
Wprowadzanie danych do ClickHouse jest najbardziej efektywne, gdy jest precyzyjnie zarządzane, wykorzystując zarówno szybkość, jak i równoległość. Optymalny proces, jak pokazano na ilustracji, obejmuje wsadowe wstawianie koordynowane przez system centralny, a nie pojedyncze, niekontrolowane strumienie danych:
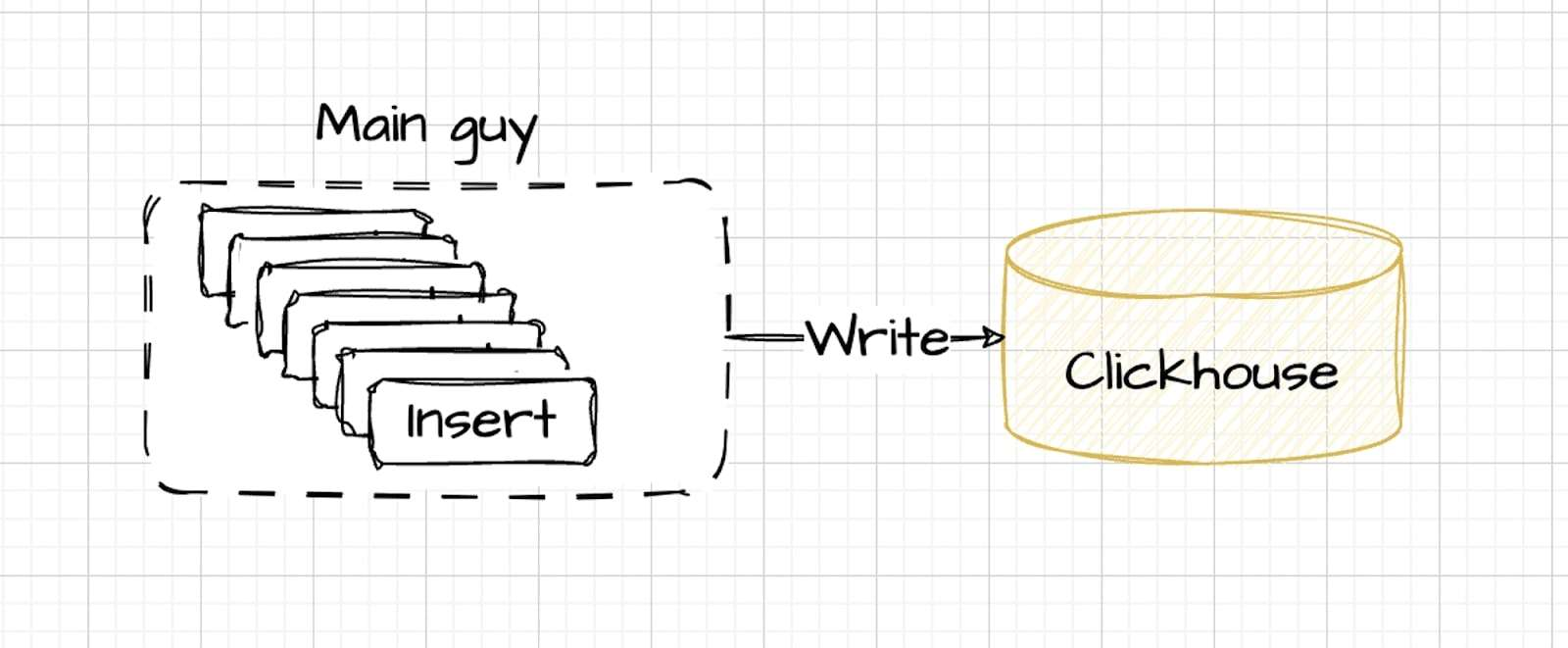
W optymalnej konfiguracji dane są wprowadzane przez główny kontroler, który zarządza przepływem, dynamicznie dostosowując prędkość przy zachowaniu kontrolowanej równoległości. Metoda ta zapewnia wydajne przetwarzanie danych i jest zgodna z optymalnymi warunkami wydajności ClickHouse.
Dlatego też w praktyce często wprowadza się bufor przed ClickHouse:
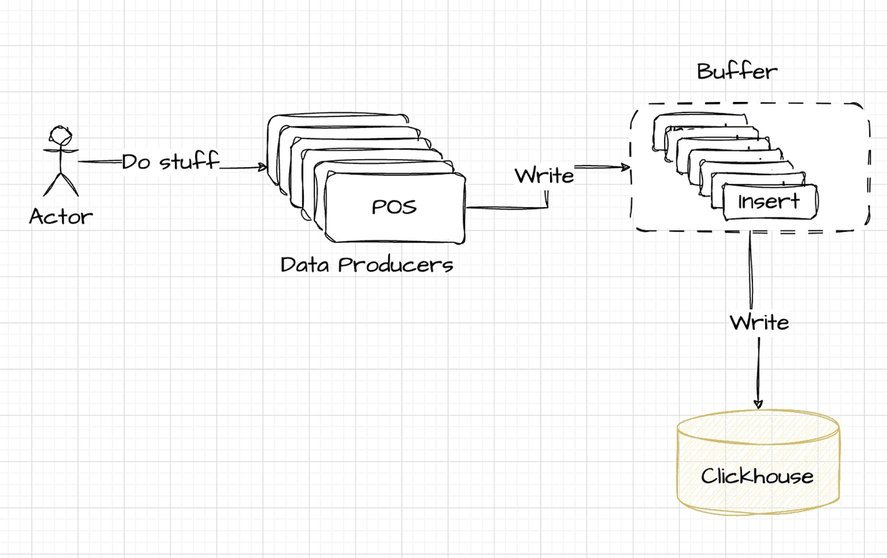
Kafka wchodzi teraz do architektury jako preferowane rozwiązanie do buforowania danych. Bez trudu wypełnia lukę między producentami danych a ClickHouse, oferując solidnego pośrednika, który usprawnia obsługę danych. Oto jak zmieniona architektura integruje Kafkę:
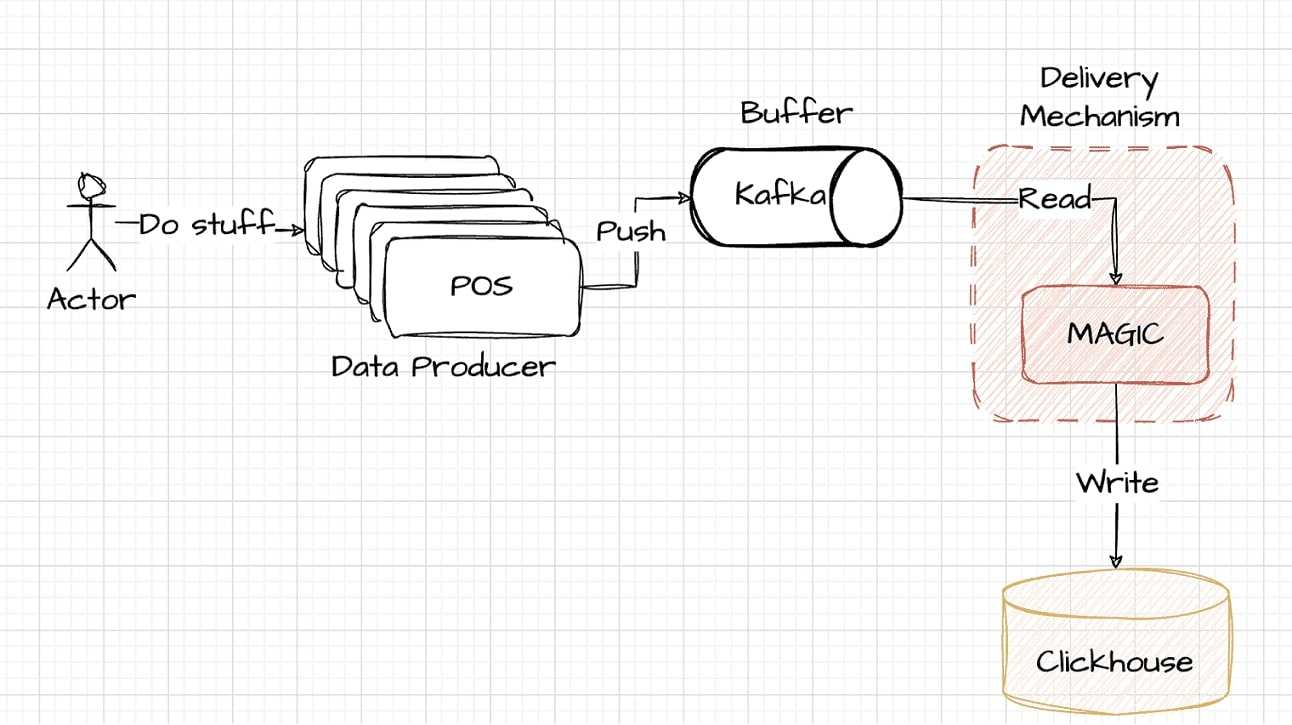
Integracja Kafki wymaga dodatkowego kodowania w celu przesyłania danych z systemów POS, a następnie do ClickHouse. Ten element architektury, choć potężny i skalowalny, wprowadza złożoność, którą omówimy bardziej szczegółowo w dalszej części artykułu.
Transfer danych z Kafki do ClickHouse
Krytyczne etapy dostarczania danych z Kafki do ClickHouse obejmują czytanie Tematy Kafki, przekształcanie danych do formatów kompatybilnych z ClickHouse, oraz pisanie tych sformatowanych danych do tabel ClickHouse. Kompromis polega tutaj na podjęciu decyzji, gdzie wykonać każdy etap.
Każdy etap ma swoje własne wymagania dotyczące zasobów:
- Etap czytania: Ta początkowa faza zużywa procesor i przepustowość sieci w celu pobrania danych z tematów Kafka.
- Proces transformacji: Przekształcanie danych wymaga użycia procesora i pamięci. Jest to prosta faza wykorzystania zasobów, w której moc obliczeniowa przekształca dane tak, aby pasowały do specyfikacji ClickHouse.
- Etap pisania: Ostatni etap obejmuje zapisywanie danych w tabelach ClickHouse, co również wymaga mocy procesora i przepustowości sieci. Jest to rutynowy proces, zapewniający, że dane znajdą swoje miejsce w pamięci ClickHouse z przydzielonymi zasobami.
Podczas integracji niezbędne jest zrównoważenie wykorzystania tych zasobów.
Przeanalizujmy teraz różne metodologie łączenia Kafki z ClickHouse.
Silnik Kafka ClickHouse
Wykorzystaj silnik Kafka w ClickHouse, aby bezpośrednio pozyskiwać dane do swoich tabel. Proces wysokiego poziomu jest wizualnie przedstawiony na załączonym diagramie:
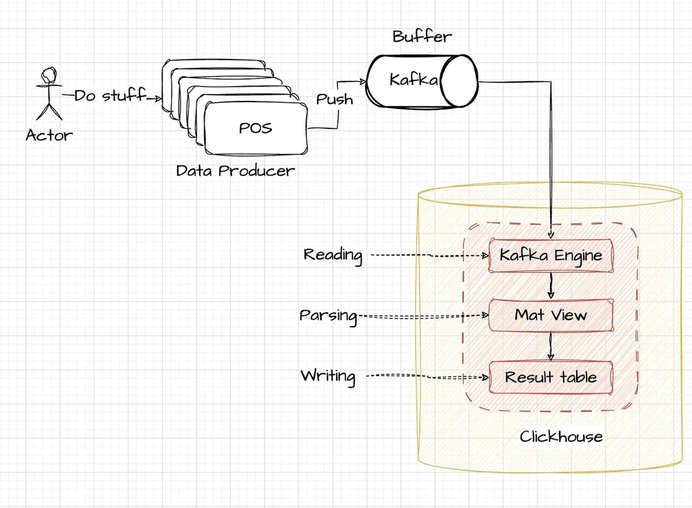
Biorąc pod uwagę ten scenariusz, terminale POS są zaprojektowane do wyprowadzania danych w ustrukturyzowanym formacie JSON, z każdym wpisem oddzielonym nową linią. Format ten jest zazwyczaj odpowiedni dla systemów pozyskiwania i przetwarzania logów.
{"user_ts": "SOME_DATE", "id": 123, "message": "SOME_TEXT"}
{"user_ts": "SOME_DATE", "id": 1234, "message": "SOME_TEXT"}Aby skonfigurować silnik Kafka w ClickHouse, zaczynamy od utworzenia wrappera tematu w ClickHouse przy użyciu silnika Kafka. Zostało to opisane w dostarczonym pliku przykładowym: example kafka_stream_engine.sql
-- Clickhouse queue wrapper
CREATE TABLE demo_events_queue ON CLUSTER '{cluster}' (
-- JSON content schema
user_ts String,
id UInt64,
message String
) ENGINE = Kafka SETTINGS
kafka_broker_list="KAFKA_HOST:9091",
kafka_topic_list="TOPIC_NAME",
kafka_group_name="uniq_group_id",
kafka_format="JSONEachRow"; -- FormatW tym zapytaniu ustalane są trzy rzeczy:
- Schemat danych: Struktura tabeli ClickHouse zawierająca trzy zdefiniowane kolumny;
- Format danych: Format określony jako “JSONEachRow”, odpowiedni do analizowania danych JSON rozdzielanych wierszami;
- Konfiguracja Kafka: Ustawienia hosta i tematu Kafka są uwzględnione w celu połączenia źródła danych z ClickHouse.
Kolejnym krokiem w konfiguracji jest zdefiniowanie tabeli docelowej w ClickHouse, która będzie przechowywać przetworzone dane:
/example_projects/clickstream/kafka_stream_engine.sql#L12-L23
-- Table to store data
CREATE TABLE demo_events_table ON CLUSTER '{cluster}' (
topic String,
offset UInt64,
partition UInt64,
timestamp DateTime64,
user_ts DateTime64,
id UInt64,
message String
) Engine = ReplicatedMergeTree('/clickhouse/tables/{shard}/{database}/demo_events_table', '{replica}')
PARTITION BY toYYYYMM(timestamp)
ORDER BY (topic, partition, offset);Ta tabela będzie miała strukturę przy użyciu ReplicatedMergeTree zapewniając solidne możliwości przechowywania danych. Oprócz kolumn danych podstawowych, tabela będzie zawierać dodatkowe kolumny pochodzące z metadanych dostarczanych przez silnik Kafka, co pozwoli na wzbogacenie możliwości przechowywania danych i zapytań.
/example_projects/clickstream/kafka_stream_engine.sql#L25-L34
-- Delivery pipeline
CREATE MATERIALIZED VIEW readings_queue_mv TO demo_events_table AS
SELECT
-- kafka engine virtual column
_topic as topic,
_offset as offset,
_partition as partition,
_timestamp as timestamp,
-- example of complex date parsing
toDateTime64(parseDateTimeBestEffort(user_ts), 6, 'UTC') as user_ts,
id,
message
FROM demo_events_queue;Ostatnim krokiem w procesie integracji jest skonfigurowanie zmaterializowanego widoku w ClickHouse, który łączy tabelę Kafka Engine z tabelą docelową. Ten zmaterializowany widok zautomatyzuje transformację i wstawianie danych z tematu Kafka do tabeli docelowej, zapewniając spójne i wydajne przetwarzanie i przechowywanie danych.
Razem, te konfiguracje ułatwiają solidny potok do przesyłania strumieniowego danych z Kafki do ClickHouse:
SELECT count(*)
FROM demo_events_table
Query id: f2637cee-67a6-4598-b160-b5791566d2d8
┌─count()─┐
│ 6502 │
└─────────┘
1 row in set. Elapsed: 0.336 sec.Podczas wdrażania wszystkich trzech etapów – odczytu, przekształcania i zapisu – w ClickHouse, ta konfiguracja jest ogólnie łatwiejsza w zarządzaniu w przypadku mniejszych zbiorów danych. Może ona jednak nie skalować się tak efektywnie w przypadku większych obciążeń. Przy dużym obciążeniu ClickHouse zazwyczaj daje pierwszeństwo operacjom zapytań, co może prowadzić do zwiększonych opóźnień w dostarczaniu danych, ponieważ pojawia się konkurencja o zasoby. Jest to ważna kwestia przy planowaniu obsługi dużych ilości danych.
Integracja z silnikiem Kafka jest funkcjonalna, ale wiąże się z kilkoma wyzwaniami:
- Zarządzanie offsetem: Zniekształcone dane w Kafce mogą zablokować ClickHouse, wymagając ręcznej interwencji w celu usunięcia offsetów, co może być wymagającym zadaniem.
- Ograniczona obserwowalność: Ponieważ operacje są wewnętrzne dla ClickHouse, monitorowanie jest bardziej złożone i opiera się w dużej mierze na analizie logów ClickHouse, aby zrozumieć zachowanie systemu.
- Problemy ze skalowalnością: Wykonywanie parsowania i odczytu wewnątrz ClickHouse może utrudniać skalowanie podczas dużych obciążeń, co może prowadzić do problemów z rywalizacją zasobów.
Wykorzystanie Kafka Connect
Kafka Connect oferuje inne podejście, przenosząc złożoność zarządzania danymi z ClickHouse do Kafki.
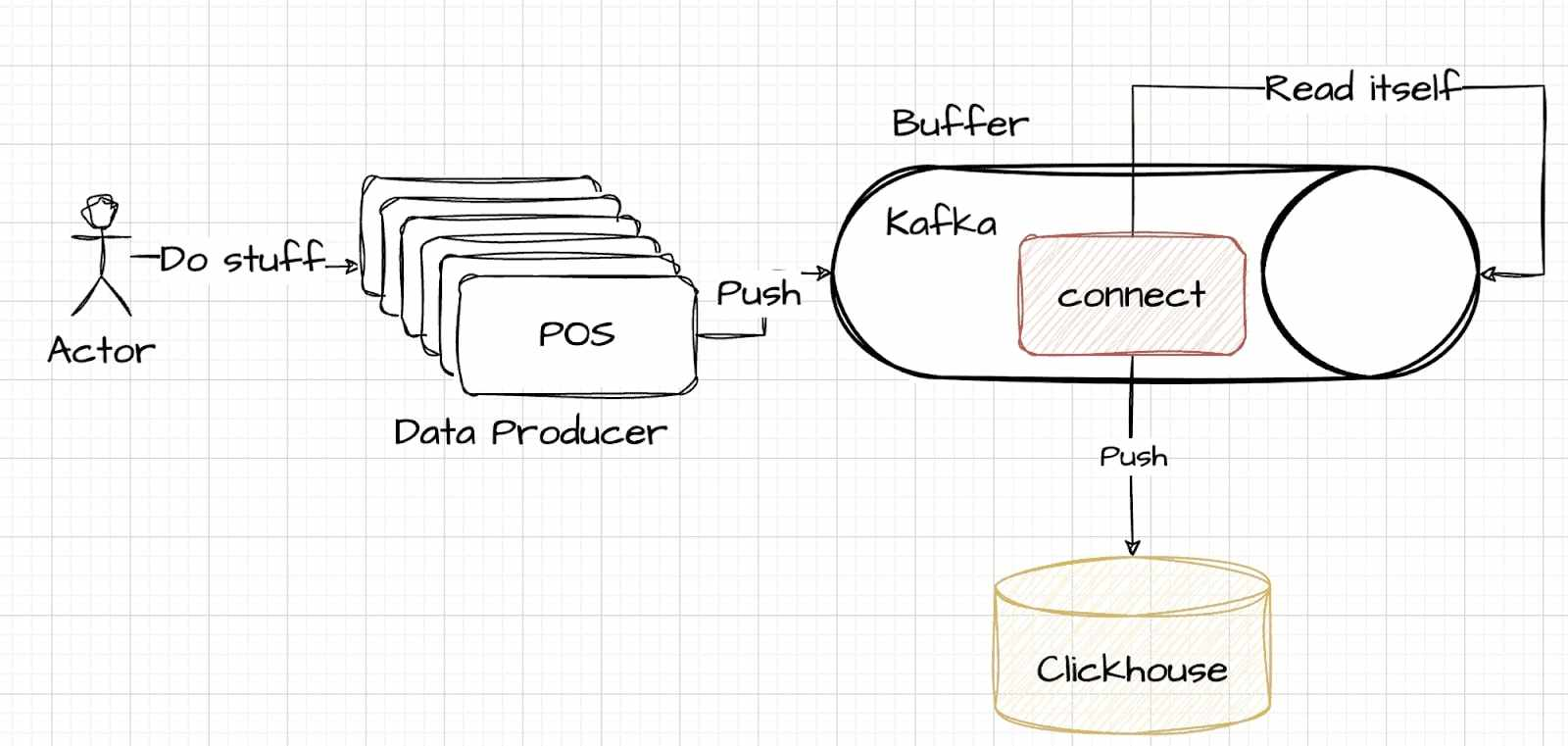
Strategia ta wymaga starannej decyzji o tym, gdzie obsługiwać zawiłości zarządzania danymi. W tym modelu zadania takie jak odczytywanie, analizowanie i zapisywanie są zarządzane w ramach Kafka Connect, który działa jako część systemu Kafka. Kompromisy w tym podejściu są podobne, ale polegają na przeniesieniu ciężaru przetwarzania ze strony przechowywania danych na stronę buforowania. Przedstawiono ilustrujący przykład tutaj aby zademonstrować, jak ustanowić to połączenie.
Wybór zewnętrznej nagrywarki
Podejście External Writer reprezentuje rozwiązanie premium, oferując doskonałą wydajność dla tych, którzy są gotowi zainwestować więcej. Zazwyczaj obejmuje ono zewnętrzny system odpowiedzialny za obsługę danych, umieszczony poza warstwami bufora (Kafka) i pamięci masowej (ClickHouse). Konfiguracja ta może być nawet zlokalizowana razem ze źródłami generującymi dane, oferując wysoki poziom wydajności i szybkości. Poniższy diagram upraszcza tę konfigurację, pokazując, w jaki sposób zewnętrzne rejestratory mogą zostać zintegrowane z potokiem danych:
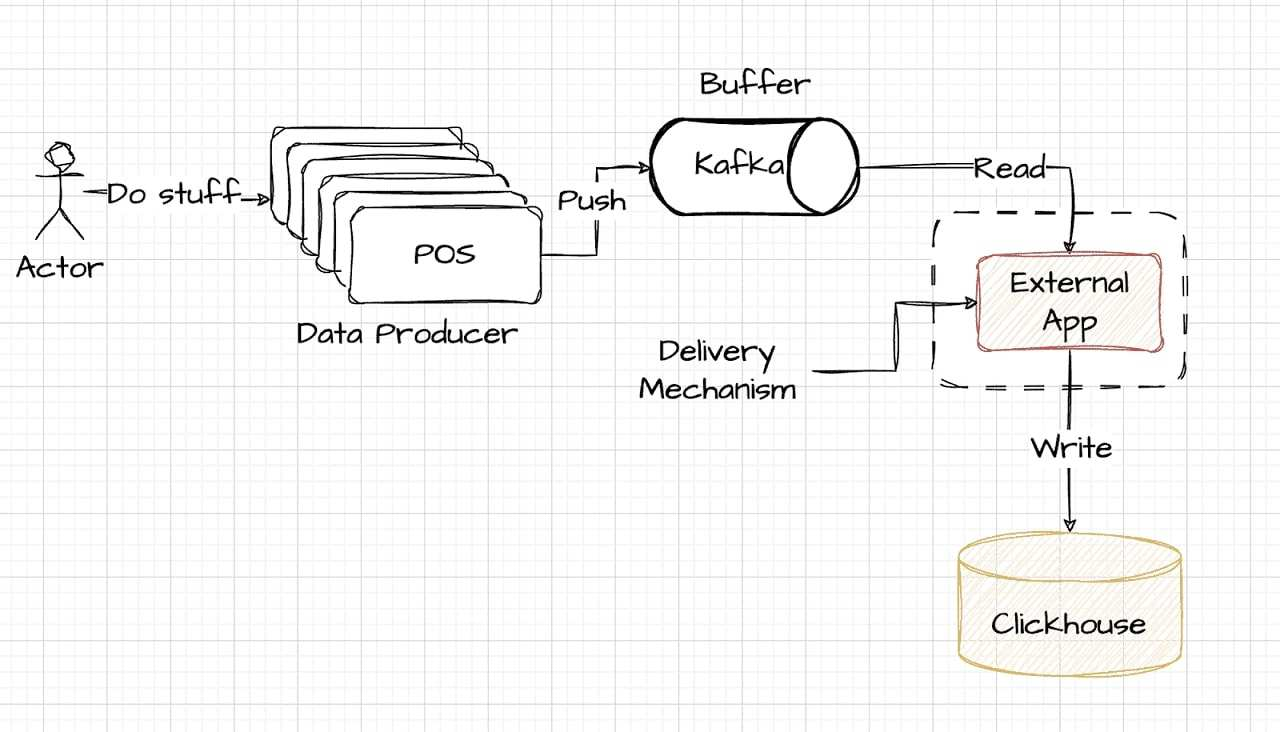
External Writer za pośrednictwem DoubleCloud
Aby zaimplementować podejście zewnętrznego pisarza przy użyciu DoubleCloud Transfer, konfiguracja obejmuje dwa podstawowe komponenty: źródłowy i docelowy punkt końcowy, a także sam mechanizm transferu. Konfiguracja ta jest efektywnie zarządzana przy użyciu Terraform. Kluczowym elementem tej konfiguracji jest reguła parsera dla punktu końcowego Source, która ma kluczowe znaczenie dla dokładnej interpretacji i przetwarzania przychodzącego strumienia danych. Szczegóły tej konfiguracji zostały opisane tutaj:
/example_projects/clickstream/transfer.tf#L16-L43
parser {
json {
schema {
fields {
field {
name = "user_ts"
type = "datetime"
key = false
required = false
}
field {
name = "id"
type = "uint64"
key = false
required = false
}
field {
name = "message"
type = "utf8"
key = false
required = false
}
}
}
null_keys_allowed = false
add_rest_column = true
}
}Konfiguracja parsera w DoubleCloud Transfer odgrywa podobną rolę do specyfikacji DDL w ClickHouse. Ma ona kluczowe znaczenie dla zapewnienia prawidłowej interpretacji i przetwarzania przychodzących danych. Po ustaleniu źródłowego punktu końcowego, następnym krokiem jest dodanie docelowej bazy danych, co zazwyczaj jest prostsze:
/example_projects/clickstream/transfer.tf#L54-L63
clickhouse_target {
clickhouse_cleanup_policy = "DROP"
connection {
address {
cluster_id = doublecloud_clickhouse_cluster.target-clickhouse.id
}
database = "default"
user = "admin"
}
}Na koniec proszę połączyć je w jeden transfer:
/example_projects/clickstream/transfer.tf#L67-L75
resource "doublecloud_transfer" "clickstream-transfer" {
name = "clickstream-transfer"
project_id = var.project_id
source = doublecloud_transfer_endpoint.clickstream-source[count.index].id
target = doublecloud_transfer_endpoint.clickstream-target[count.index].id
type = "INCREMENT_ONLY"
activated = true
}Po wykonaniu tych kroków Państwa system dostarczania danych wykorzystujący DoubleCloud Transfer jest już gotowy do działania. Ta konfiguracja zapewnia płynny przepływ danych ze źródła do docelowej bazy danych, skutecznie zarządzając całym procesem.
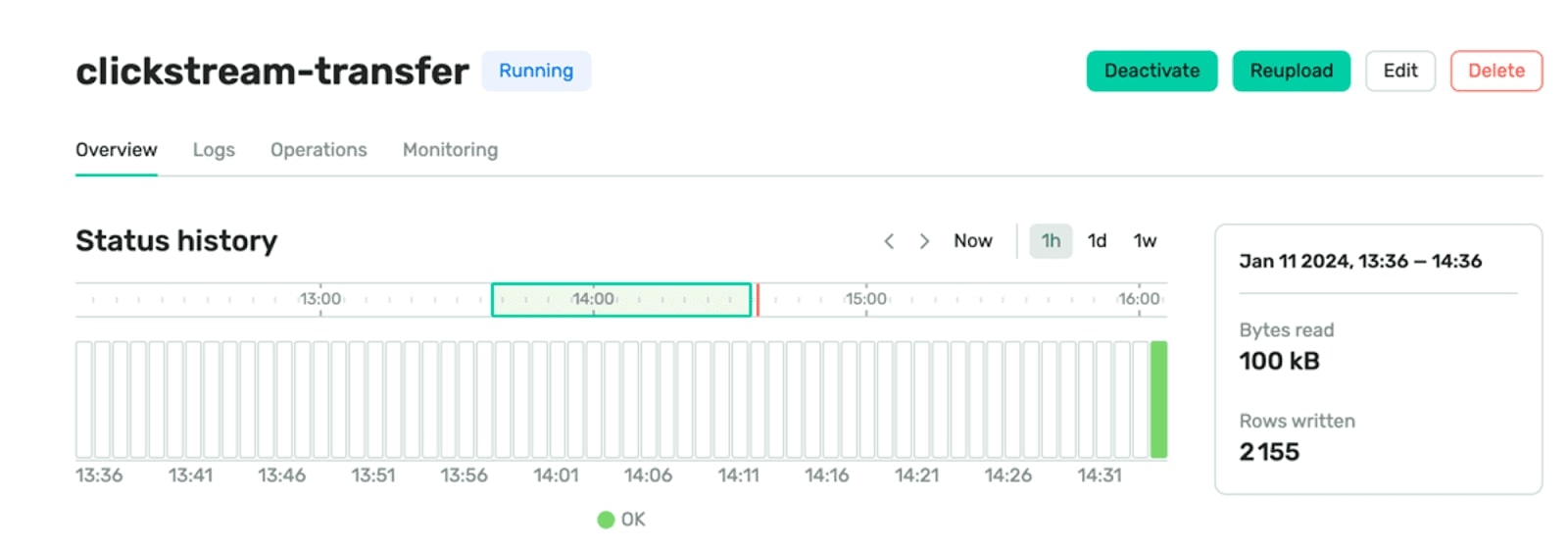
Silnik EL
- Zautomatyzowane zarządzanie offsetem: Transfer automatyzuje obsługę uszkodzonych danych za pośrednictwem nieprzeanalizowanych tabel, minimalizując potrzebę ręcznego zarządzania offsetami.
- Zwiększona obserwowalność: W przeciwieństwie do ograniczonego monitorowania w ClickHouse, Transfer zapewnia dedykowane pulpity nawigacyjne i alerty umożliwiające wgląd w czasie rzeczywistym w metryki dostarczania, takie jak opóźnienie danych, liczba wierszy i dostarczone bajty.
- Dynamiczna skalowalność: Zadania dostarczania Transfer, hostowane na Kubernetes, EC2 lub GCP, umożliwiają skalowalne operacje niezależne od ClickHouse.
Transfer dodatkowo zapewnia nieszablonowe funkcje zwiększające jego funkcjonalność:
- Automatyczna ewolucja schematu: Automatycznie synchronizuje wstecznie kompatybilne zmiany schematu z docelową pamięcią masową.
- Automatyczna kolejka martwych liter: Skutecznie zarządza uszkodzonymi danymi, przekierowując je do wyznaczonej kolejki martwych liter (DLQ) w tabeli ClickHouse.
Zewnętrzny zapis przez Clickpipes
ClickPipes oferuje uproszczone i wydajne rozwiązanie do pozyskiwania danych z różnych źródeł. Jego przyjazny dla użytkownika interfejs pozwala na szybką konfigurację przy minimalnym wysiłku. Zaprojektowany z myślą o scenariuszach wysokiego zapotrzebowania, ClickPipes może pochwalić się solidną, skalowalną architekturą, która zapewnia stałą wydajność i niezawodność. Chociaż pod względem funkcjonalności ClickPipes jest podobny do DoubleCloud Transfer, nie obsługuje on automatycznej ewolucji schematu. Aby uzyskać szczegółowe instrukcje konfiguracji, dostępny jest kompleksowy przewodnik tutaj.
Wnioski
W tym artykule przeanalizowaliśmy różne metodologie integracji Kafki z ClickHouse, koncentrując się na opcjach takich jak Kafka Engine, Kafka Connect, DoubleCloud Transfer i ClickPipes. Każde z tych podejść oferuje unikalne mocne strony i uwagi dostosowane do różnych wymagań przetwarzania danych i skali operacyjnej. Od zarządzania zasobami po skalowalność systemu, wybór odpowiedniego podejścia ma kluczowe znaczenie dla optymalnej obsługi danych.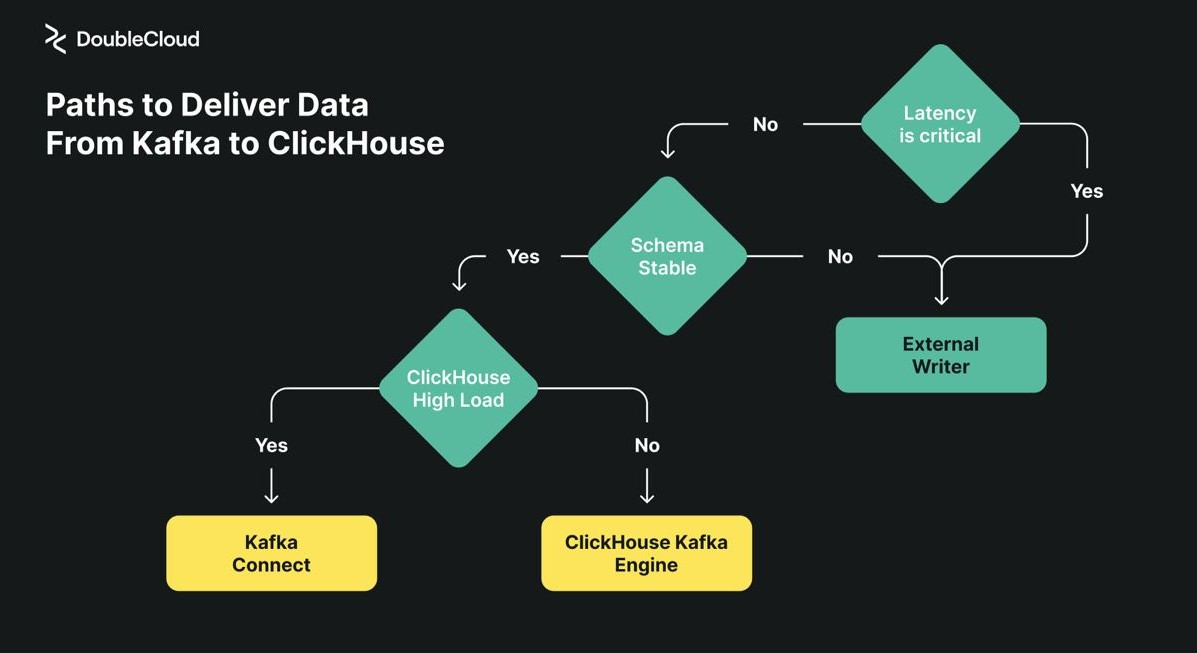
Aby dalej odkrywać synergię Kafki i ClickHouse, proszę rozważyć zagłębienie się w stos DoubleCloud. Zapewniają oni wnikliwe przykłady Terraform, które mogą być świetnym punktem wyjścia dla tych, którzy chcą wdrożyć te potężne narzędzia w swoich przepływach pracy przetwarzania danych. Aby uzyskać bardziej szczegółowe wskazówki, proszę sprawdzić Przykłady Terraform.