
Czas rzeczywisty uczenie maszynowe odnosi się do zastosowania algorytmów uczenia maszynowego, które w sposób ciągły uczą się na podstawie napływających danych i podejmują prognozy lub decyzje w czasie rzeczywistym. W przeciwieństwie do uczenia maszynowego wsadowego, w którym dane są gromadzone przez pewien czas i przetwarzane partiami w trybie offline, uczenie maszynowe w czasie rzeczywistym działa natychmiastowo na danych strumieniowych, umożliwiając natychmiastowe reagowanie na zmiany lub zdarzenia.
Typowe przypadki użycia obejmują wykrywanie oszustw w transakcjach finansowych, konserwację predykcyjną w produkcji, systemy rekomendacji w handlu elektronicznym i spersonalizowane dostarczanie treści w mediach. Wyzwania związane z tworzeniem możliwości uczenia maszynowego w czasie rzeczywistym obejmują wydajne zarządzanie dużymi ilościami danych strumieniowych, zapewnienie niskich opóźnień w celu uzyskania terminowych odpowiedzi, utrzymanie dokładności i wydajności modelu w czasie oraz rozwiązywanie problemów związanych z prywatnością i bezpieczeństwem związanych z przetwarzaniem danych w czasie rzeczywistym. Niniejszy artykuł zagłębia się w te koncepcje i zapewnia wgląd w to, w jaki sposób organizacje mogą pokonać te wyzwania, aby wdrożyć skuteczne systemy uczenia maszynowego w czasie rzeczywistym.
Przypadki użycia
Teraz wyjaśniliśmy różnicę między uczeniem maszynowym w trybie wsadowym a uczeniem maszynowym w czasie rzeczywistym, warto wspomnieć, że w rzeczywistych przypadkach użycia można mieć uczenie maszynowe w trybie wsadowym, uczenie maszynowe w czasie rzeczywistym lub pomiędzy uczeniem maszynowym w trybie wsadowym a uczeniem maszynowym w czasie rzeczywistym. Na przykład, można mieć scenariusze, w których mamy wnioskowanie w czasie rzeczywistym z funkcjami wsadowymi, wnioskowanie w czasie rzeczywistym z funkcjami w czasie rzeczywistym lub wnioskowanie w czasie rzeczywistym z funkcjami wsadowymi i funkcjami w czasie rzeczywistym. Ciągłe uczenie maszynowe wykracza poza zakres tego artykułu, ale można również zastosować rozwiązania funkcji czasu rzeczywistego do ciągłego uczenia maszynowego (CML).
Podejścia hybrydowe, które łączą aspekty uczenia w czasie rzeczywistym i uczenia wsadowego, oferują elastyczne rozwiązanie spełniające różne wymagania i ograniczenia w różnych zastosowaniach. Oto kilka rozszerzonych przykładów:
| Przypadki użycia | Batch | Czas rzeczywisty |
|---|---|---|
|
Wykrywanie oszustw w bankowości |
Początkowo model wykrywania oszustw może być trenowany w trybie offline przy użyciu dużego zbioru danych historycznych transakcji. To szkolenie wsadowe pozwala modelowi uczyć się złożonych wzorców nieuczciwych zachowań w czasie, wykorzystując całość dostępnych danych historycznych. |
Po wdrożeniu model nadal uczy się w czasie rzeczywistym, gdy pojawiają się nowe transakcje. Każda transakcja jest przetwarzana w czasie rzeczywistym, a model jest okresowo aktualizowany (np. co godzinę lub codziennie) przy użyciu partii najnowszych danych transakcyjnych. Ta aktualizacja w czasie rzeczywistym zapewnia, że model może szybko dostosować się do pojawiających się wzorców oszustw bez poświęcania wydajności obliczeniowej. |
|
Systemy rekomendacji w handlu elektronicznym |
A system rekomendacji może zostać początkowo przeszkolony w trybie offline przy użyciu partii historycznych danych dotyczących interakcji użytkownika, takich jak wcześniejsze zakupy, kliknięcia i oceny. To szkolenie wsadowe pozwala modelowi skutecznie uczyć się preferencji użytkownika i podobieństw przedmiotów. |
Po wdrożeniu modelu można go dostroić w czasie rzeczywistym, gdy użytkownicy wchodzą w interakcję z systemem. Na przykład, gdy użytkownik dokona zakupu lub przekaże opinię na temat produktu, model może zostać natychmiast zaktualizowany, aby dostosować przyszłe rekomendacje dla tego użytkownika. Ta personalizacja w czasie rzeczywistym zwiększa doświadczenie i zaangażowanie użytkownika bez konieczności ponownego szkolenia całego modelu przy każdej interakcji. |
|
Aplikacje przetwarzania języka naturalnego (NLP) |
Modele NLP, takich jak analiza sentymentu lub modele tłumaczenia językowego, mogą być trenowane offline przy użyciu dużych korpusów danych tekstowych. Trening wsadowy pozwala modelowi uczyć się reprezentacji semantycznych i struktur językowych z różnych źródeł tekstowych. |
Po wdrożeniu model może być dostrajany w czasie rzeczywistym przy użyciu danych tekstowych generowanych przez użytkowników, takich jak opinie klientów lub interakcje na czacie na żywo. Dostrajanie w czasie rzeczywistym umożliwia modelowi dostosowanie się do niuansów językowych specyficznych dla domeny lub użytkownika oraz zmieniających się trendów bez konieczności ponownego szkolenia od podstaw. |
W każdym z tych przykładów podejście hybrydowe łączy głębię analizy zapewnianą przez uczenie wsadowe z możliwościami adaptacyjnymi uczenia w czasie rzeczywistym, co skutkuje bardziej niezawodnymi i responsywnymi systemami uczenia maszynowego. Wybór między elementami uczenia w czasie rzeczywistym i uczenia wsadowego zależy od konkretnych wymagań aplikacji, takich jak ilość danych, ograniczenia opóźnień i potrzeba ciągłej adaptacji.
Jakie są główne komponenty potoku uczenia maszynowego w czasie rzeczywistym?
Potok uczenia maszynowego (ML) w czasie rzeczywistym składa się zazwyczaj z kilku komponentów współpracujących ze sobą w celu umożliwienia ciągłego przetwarzania danych i wdrażania modeli ML z minimalnymi opóźnieniami. Poniżej przedstawiamy główne komponenty takiego potoku:
1. Pozyskiwanie danych
Ten komponent jest odpowiedzialny za gromadzenie danych z różnych źródeł w czasie rzeczywistym. Może to obejmować strumieniowe przesyłanie danych z czujników, baz danych, interfejsów API lub innych źródeł.
2. Strumieniowe przetwarzanie danych i inżynieria funkcji
Po pozyskaniu danych muszą one zostać przetworzone w czasie rzeczywistym. Komponent ten obejmuje struktury przetwarzania danych strumieniowych, które efektywnie obsługują strumienie danych. Cechy wyodrębnione z surowych danych mają kluczowe znaczenie dla budowania modeli ML. Komponent ten obejmuje przekształcanie surowych danych w znaczące cechy, które mogą być wykorzystywane przez modele ML. Inżynieria cech może obejmować techniki takie jak normalizacja, kodowanie zmiennych kategorialnych i tworzenie nowych cech.
3. Trening modelu
Trening zwykle odbywa się w regularnych odstępach czasu, z częstotliwością zmieniającą się między czasem zbliżonym do rzeczywistego, który obejmuje częstsze ramy czasowe niż trening wsadowy, lub trening w czasie rzeczywistym online.
4. Wnioskowanie na podstawie modelu
Ten komponent obejmuje wdrażanie modeli ML i prognozowanie w czasie rzeczywistym. Wdrożone modele powinny być zoptymalizowane pod kątem wnioskowania o niskich opóźnieniach i muszą być dobrze skalowane, aby obsługiwać zmienne obciążenia.
5. Skalowalność i tolerancja błędów
Potoki uczenia maszynowego w czasie rzeczywistym muszą być skalowalne, aby obsługiwać duże ilości danych i odporne na błędy, aby z wdziękiem znosić awarie. Często wiąże się to z wdrożeniem potoku w systemach rozproszonych i wdrażanie mechanizmów odzyskiwania po awarii i replikacji danych.
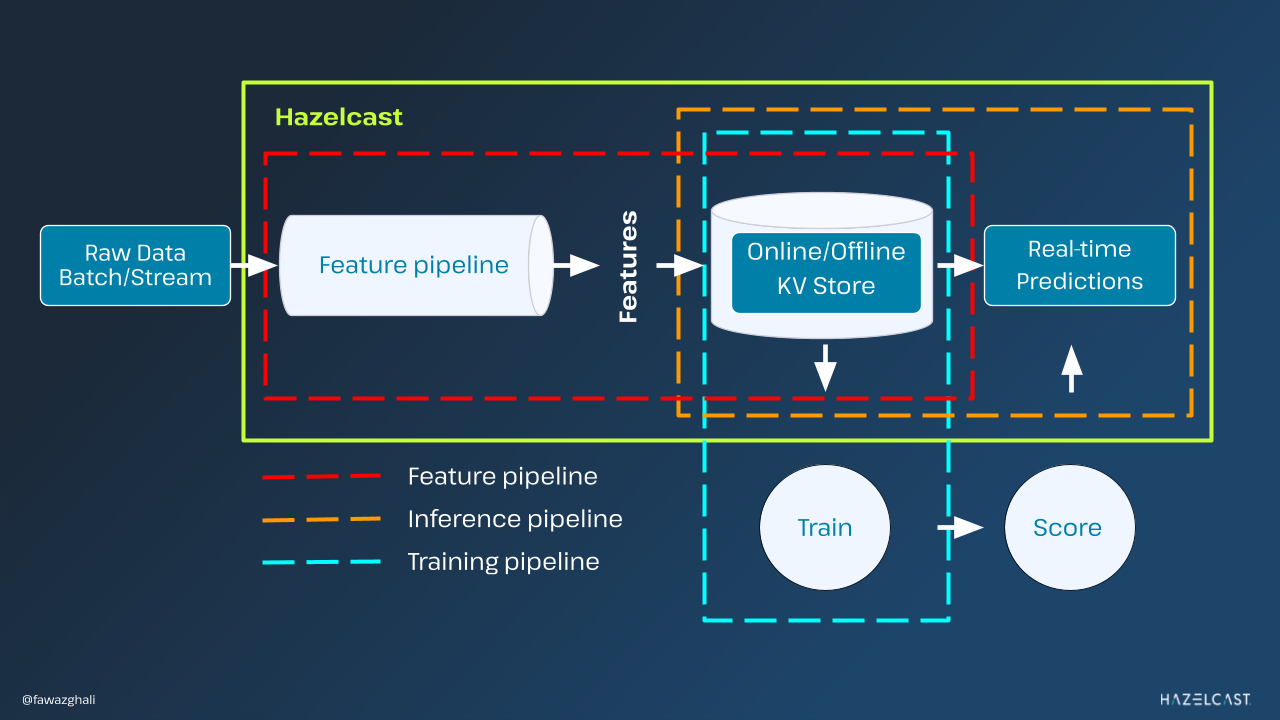
Wyzwania związane z tworzeniem potoków uczenia maszynowego w czasie rzeczywistym
Wymóg niskiego opóźnienia
Potoki czasu rzeczywistego muszą przetwarzać dane i tworzyć prognozy w ściśle określonym czasie, często w milisekundach. Osiągnięcie niskiego opóźnienia wymaga optymalizacji każdego elementu potoku, w tym pozyskiwania danych, wstępnego przetwarzania, wnioskowania o modelu i dostarczania danych wyjściowych.
Skalowalność
Potoki czasu rzeczywistego muszą obsługiwać różne obciążenia i skalować się, aby dostosować się do rosnącej ilości danych i wymagań obliczeniowych. Projektowanie skalowalnych architektur obejmuje wybór odpowiednich technologii i strategii obliczeń rozproszonych w celu zapewnienia efektywnego wykorzystania zasobów i skalowalności poziomej.
Inżynieria funkcji
Generowanie cech w czasie rzeczywistym z danych strumieniowych może być złożone i wymagać dużych zasobów. Kluczowym wyzwaniem jest zaprojektowanie wydajnych potoków ekstrakcji i transformacji cech, które dostosowują się do zmieniających się rozkładów danych i utrzymują dokładność modelu w czasie.
Bezpieczeństwo
Solidne mechanizmy uwierzytelniania, autoryzacji i bezpiecznej komunikacji są niezbędne dla uczenia maszynowego w czasie rzeczywistym. Posiadanie skutecznych reagowanie na incydenty i możliwości monitorowania umożliwiają organizacjom szybkie wykrywanie i reagowanie na incydenty bezpieczeństwa, wzmacniając ogólną odporność potoków uczenia maszynowego w czasie rzeczywistym na zagrożenia bezpieczeństwa. Zajmując się kompleksowo tymi kwestiami bezpieczeństwa, organizacje mogą budować bezpieczne potoki uczenia maszynowego w czasie rzeczywistym, które skutecznie chronią wrażliwe dane i zasoby.
Optymalizacja kosztów
Budowa i obsługa potoków uczenia maszynowego w czasie rzeczywistym może być kosztowna, zwłaszcza w przypadku korzystania z infrastruktury opartej na chmurze lub usług stron trzecich. Optymalizacja wykorzystania zasobów, wybór opłacalnych technologii oraz wdrażanie strategii automatycznego skalowania i dostarczania zasobów są niezbędne do kontrolowania kosztów operacyjnych.
Solidność i odporność na błędy
Rurociągi czasu rzeczywistego muszą być odporne na awarie i zapewniać ciągłość działania w niesprzyjających warunkach. Wdrożenie mechanizmów tolerancji błędów, takich jak replikacja danych, punkty kontrolne i automatyczne przełączanie awaryjne, ma kluczowe znaczenie dla utrzymania niezawodności i dostępności systemu.
Integracja z istniejącymi systemami
Integracja potoków uczenia maszynowego w czasie rzeczywistym z istniejącą infrastrukturą IT, źródłami danych i aplikacjami niższego szczebla wymaga starannego planowania i koordynacji. Zapewnienie kompatybilności, interoperacyjności i płynnego przepływu danych między różnymi komponentami systemu ma zasadnicze znaczenie dla pomyślnego wdrożenia i przyjęcia.
Sprostanie tym wyzwaniom wymaga połączenia wiedzy specjalistycznej w danej dziedzinie, umiejętności inżynierii oprogramowania oraz wiedzy na temat systemów rozproszonych, algorytmów uczenia maszynowego i technologii przetwarzania w chmurze.
Wybór rozwiązań, które usprawniają operacje poprzez zminimalizowanie liczby zaangażowanych narzędzi, może być przełomem. Takie podejście nie tylko zmniejsza wysiłki związane z integracją, ale także obniża koszty utrzymania i koszty operacyjne, jednocześnie wprowadzając mniejsze opóźnienia – kluczowy czynnik w aplikacjach ML w czasie rzeczywistym. Konsolidując przetwarzanie i przechowywanie funkcji w jednym, szybkim magazynie klucz-wartość, z obsługą modelu ML w czasie rzeczywistym, Hazelcast upraszcza krajobraz sztucznej inteligencji, zmniejszając złożoność i zapewniając płynny przepływ danych.
Przyszłość uczenia maszynowego w czasie rzeczywistym
Przyszłość uczenia maszynowego w czasie rzeczywistym (ML) jest ściśle powiązana z postępem w wektorowych bazach danych i pojawieniem się grafów atrybutów względnych (RAG). Wektorowe bazy danych zapewniają wydajne przechowywanie i możliwości zapytań dla danych wielowymiarowych, dzięki czemu dobrze nadają się do zarządzania dużymi przestrzeniami cech powszechnymi w aplikacjach ML. Z drugiej strony, grafy atrybutów względnych oferują nowatorskie podejście do reprezentowania i wnioskowania o złożonych relacjach w danych, umożliwiając bardziej wyrafinowaną analizę i podejmowanie decyzji w potokach uczenia maszynowego w czasie rzeczywistym.
W kontekście finansów i fintech, integracja wektorowych baz danych i RAG jest obiecująca dla poprawy różnych aspektów aplikacji ML w czasie rzeczywistym. Jednym z przykładów jest wykrywanie oszustw i zapobieganie im. Instytucje finansowe muszą stale monitorować transakcje i identyfikować podejrzane działania, aby zmniejszyć ryzyko oszustwa. Wykorzystując wektorowe bazy danych do efektywnego przechowywania i przeszukiwania wielowymiarowych danych transakcyjnych, w połączeniu z RAG do modelowania skomplikowanych relacji między transakcjami, algorytmy uczenia maszynowego w czasie rzeczywistym mogą wykrywać anomalie i nieuczciwe wzorce w czasie rzeczywistym z większą dokładnością i szybkością.
Innym obszarem zastosowań są spersonalizowane rekomendacje finansowe i zarządzanie portfelem. Tradycyjne systemy rekomendacji często mają trudności z uchwyceniem zróżnicowanych preferencji i celów poszczególnych użytkowników. Jednak wykorzystując wektorowe reprezentacje preferencji użytkownika i aktywów finansowych przechowywanych w wektorowych bazach danych oraz wykorzystując RAG do modelowania względnych atrybutów i współzależności między różnymi opcjami inwestycyjnymi, algorytmy ML w czasie rzeczywistym mogą generować spersonalizowane rekomendacje, które lepiej pasują do celów finansowych i profili ryzyka użytkowników. Przykładowo, system uczenia maszynowego w czasie rzeczywistym może analizować historię finansową użytkownika, tolerancję ryzyka i warunki rynkowe, aby dynamicznie dostosowywać jego portfel inwestycyjny w odpowiedzi na zmieniające się warunki rynkowe i osobiste preferencje.
Ponadto, w handel algorytmicznyModele uczenia maszynowego w czasie rzeczywistym zasilane przez wektorowe bazy danych i RAG mogą umożliwić bardziej wyrafinowane strategie handlowe, które dostosowują się do zmieniającej się dynamiki rynku i wykorzystują złożone zależności między różnymi instrumentami finansowymi. Analizując historyczne dane rynkowe przechowywane w wektorowych bazach danych i włączając sygnały rynkowe w czasie rzeczywistym reprezentowane jako RAG, algorytmiczne systemy transakcyjne mogą podejmować bardziej świadome i terminowe decyzje handlowe, optymalizując wyniki handlowe i zarządzanie ryzykiem.
Ogólnie rzecz biorąc, przyszłość uczenia maszynowego w czasie rzeczywistym w finansach i fintechach może znacznie skorzystać na postępach w wektorowych bazach danych i RAG. Wykorzystując te technologie, organizacje mogą budować bardziej inteligentne, adaptacyjne i wydajne potoki uczenia maszynowego w czasie rzeczywistym, które umożliwiają lepsze wykrywanie oszustw, spersonalizowane usługi finansowe i algorytmiczne strategie handlowe.