
Pamiętam, jak w poprzednim projekcie przechodziłem przez spotkania dotyczące wymagań, opracowywałem model danych, rysowałem projekt bazy danych i przesyłałem go zespołowi DBA do przeglądu i zatwierdzenia. Było wiele komunikacji w obie strony na temat nazewnictwa, typów danych i konwencji struktury. Kilka tygodni później tabele zostały utworzone w środowisku programistycznym, dzięki czemu mogłem załadować dane testowe oraz zbudować i przetestować kod pod ich kątem.
Kiedy wymagania uległy zmianie, zrozumienie modelu danych poprawiło się, iteracje danych testowych przyniosły inne wyniki lub zakres projektu wkradł się, rozpoczynaliśmy model danych -> projekt bazy danych -> przegląd / zatwierdzenie DBA -> proces tworzenia oprogramowania od nowa.
Ten projekt nie jest jedynym tego rodzaju. Podczas każdej iteracji projektów rozwojowych, produkcyjnych, a także konserwacyjnych/usprawniających przepalana jest znaczna liczba godzin projektowych. Ograniczając lub eliminując etap tłumaczenia między modelem danych a projektem bazy danych, możemy znacznie skrócić czas wprowadzania produktu na rynek i obniżyć koszty utrzymania.
Czym jest refaktoryzacja danych?
Korzenie refaktoryzacji danych prawdopodobnie sięgają refaktoryzacji kodu stosowanej w programach komputerowych. Martin Fowler definiuje refaktoryzację jako “zdyscyplinowaną technikę restrukturyzacji istniejącego kodu, zmieniającą jego wewnętrzną strukturę bez zmiany jego zewnętrznego zachowania”. Na ten temat napisano całe książki, ale jak to się ma do danych i baz danych?
Refaktoryzacja kodu jest często wykonywana po wstępnym szkicu kodu lub gdy konieczne jest wprowadzenie ulepszeń / funkcji. Każda z tych zmian może mieć wpływ na projekt przed lub po początkowej implementacji, aby kod był czystszy, wydajniejszy i łatwiejszy w utrzymaniu. Niektóre refaktoryzacje mogą również wystąpić z powodu zmian w strukturze danych wspierających kod, takich jak głębsze zrozumienie modelu danych lub dodawanie / odejmowanie do zebranych danych. Refaktoryzacja zachodzi również w danych i modelu danych.
Proszę zauważyć, że podczas gdy refaktoryzacja kodu może wystąpić bez zmian w modelu danych, na kod prawie zawsze wpływają zmiany w bazowym modelu danych. Refaktoryzacja danych staje się źródłem refaktoryzacji modelu, systemu przechowywania i kodu. Każdy element wymaga starannego planowania i dokładnego zrozumienia, co zwiększa zasoby projektu.
Widzimy pozytywne korzyści z refaktoryzacji dzięki lepszym danym i kodowi, więc czy poświęcony czas nie jest tego wart? W czym tkwi problem?
Patrząc na komponent refaktoryzacji danych w projekcie, istnieje kilka zadań, które mu towarzyszą. Pierwszym z nich jest wprowadzenie zmian w modelu danych, aby dopasować go do nowego przypadku, funkcji itp. Drugim jest dostosowanie modelu danych do formatu technologii przechowywania, tj. relacyjnego, grafowego lub innego. Każdy typ formatu przechowywania danych ma swój własny zestaw reguł, więc często wprowadzamy dalsze zmiany w danych, aby dostosować je do wymaganej struktury.
Ten etap “tłumaczenia” między modelem danych a etapami przechowywania danych może być uciążliwy, a towarzyszą mu zatwierdzenia w celu prawidłowego dostosowania struktur danych między światem rzeczywistym a ustrukturyzowanymi formatami w bazie danych. Grafowe bazy danych mogą skrócić lub skrócić fazę tłumaczenia, ponieważ w bardziej naturalny sposób modelują dane tak, jak istnieją one w świecie rzeczywistym.
Refaktoryzacja danych dla baz danych
W poprzedni artykułwykorzystaliśmy zestaw danych kawiarni z paragonami sprzedaży, produktami i klientami. Możemy użyć tego samego zestawu danych, aby przyjrzeć się refaktoryzacji danych dzisiaj, ale weźmy inną sekcję danych – sklepy i ich przydziały pracowników. Wszystkie dane, skrypty zmian i nie tylko są dostępne w sekcji powiązanym repozytorium Github.
Nasz przykładowy zestaw danych znajduje się w tabelach 1 i 2 poniżej.
|
sales_outlet_id |
sales_outlet_type |
store_square_feet |
store_address |
store_city |
store_state_province |
store_telephone |
store_postal_code |
menedżer |
|
1 |
centrala |
0 |
nieznany |
Nowy Jork |
NY |
111-222-3333 |
44444 |
2 |
|
2 |
magazyn |
3400 |
164-14 Jamaica Ave |
Jamajka |
NY |
972-871-0402 |
11432 |
1 |
|
3 |
sprzedaż detaliczna |
1300 |
32-20 Broadway |
Long Island City |
NY |
777-718-3190 |
11106 |
6 |
Tabela 1. Tabela lokalizacji sklepu
|
staff_id |
first_name |
last_name |
stanowisko |
start_date |
lokalizacja |
|
1 |
Sue |
Tindale |
CFO |
8/3/2001 |
1 |
|
2 |
Ian |
Tindale |
CEO |
8/3/2001 |
1 |
|
3 |
Marny |
Hermiona |
Roaster |
10/24/2007 |
2 |
|
4 |
Chelsea |
Claudia |
Roaster |
7/3/2003 |
2 |
|
5 |
Alec |
Isadora |
Roaster |
4/2/2008 |
2 |
|
6 |
Xena |
Rahim |
Kierownik sklepu |
7/24/2016 |
3 |
|
7 |
Kelsey |
Cameron |
Coffee Wrangler |
10/18/2003 |
3 |
|
8 |
Hamilton |
Emi |
Coffee Wrangler |
2/9/2005 |
3 |
|
9 |
Caldwell |
Veda |
Coffee Wrangler |
9/9/2013 |
3 |
|
10 |
Ima |
Winifred |
Coffee Wrangler |
12/10/2016 |
3 |
Tabela 2. Tabela personelu
Lokalizacje sklepów zawierają dane o typie lokalizacji, rozmiarze, adresie, numerze telefonu i przypisanym kierowniku. Tabela personelu zawiera nazwiska, stanowiska, daty rozpoczęcia i przypisane lokalizacje sklepów dla każdego pracownika.
Reprezentacja graficzna tych danych może wyglądać mniej więcej tak, jak widzimy poniżej.

Rysunek 1: Wykres przedstawiający lokalizacje sklepów i personel
W modelu grafu mamy dwie główne jednostki (węzły: Sklep oraz Personel. Relacje między tymi węzłami mówią nam, w jaki sposób są one połączone. Albo pracownik jest przypisany do pracy w danej lokalizacji, albo sklep jest zarządzany przez konkretnego pracownika.
Następnie przyjrzyjmy się, jak kilka konkretnych refaktoryzacji wpłynęłoby na każdy z tych modeli.
Refaktoryzacja 1: Dodanie nowej kolumny
Przechowywanie dodatkowych danych jest częstą zmianą w projektach. W naszym przypadku kawiarni możemy chcieć również śledzić datę otwarcia lokalizacji sklepu (tj. jak długo dana lokalizacja działa).
W formacie relacyjnym proces polegałby na dodaniu nowej kolumny do tabeli. Prawdopodobnie oznacza to wyjaśnienie zmiany zainteresowanym stronom, napisanie i wykonanie pliku Język definicji danych (DDL) w celu zmiany struktury tabeli (lub usunięcia całej tabeli i odbudowania jej z nową kolumną w DDL), dodania nowych danych do zestawu populacji, a następnie zaimportowania rzeczywistych danych do tabeli. Może to również wymagać dodania kroków zatwierdzania zmian między niektórymi zadaniami. Ta zmiana nie ma wpływu na tabelę personelu, więc nie są wymagane żadne zmiany.
|
sales_outlet_id |
sales_outlet_type |
store_open_date |
store_square_feet |
store_address |
store_city |
store_state_province |
store_telephone |
store_postal_code |
menedżer |
|
1 |
centrala |
8/1/2016 |
0 |
na |
Nowy Jork |
NY |
111-222-3333 |
44444 |
2 |
|
2 |
magazyn |
7/3/2003 |
3400 |
164-14 Jamaica Ave |
Jamajka |
NY |
972-871-0402 |
11432 |
1 |
|
3 |
sprzedaż detaliczna |
8/3/2001 |
1300 |
32-20 Broadway |
Long Island City |
NY |
777-718-3190 |
11106 |
6 |
Tabela 3. Refaktoryzacja #1 dla tabeli lokalizacji sklepu
W formacie wykresu musielibyśmy dodać nową właściwość do tabeli Shop węzeł. Podobnie jak w przypadku powyższego procesu relacyjnego, musielibyśmy wyjaśnić zmianę interesariuszom i uzyskać wszelkie niezbędne zgody na zmianę. Jednak porzucenie struktury danych, dodanie i ustawienie nowej struktury danych jest wyeliminowane w grafie, ponieważ nie ma ścisłego DDL. Struktura nie jest wymuszana na danych – raczej same dane określają strukturę i mogą być dostosowywane, gdy dane się zmieniają.

Rysunek 2. Refaktoryzacja #1 dla grafu
Przykładowe skrypty zarówno dla procesów relacyjnych, jak i grafowych są zawarte w dokumencie repozytorium kodu na GitHub.
Refaktoryzacja 2: Dodawanie nowej tabeli i relacji
Następnie, być może mamy problemy z pokryciem personelu w naszych lokalizacjach, więc chcemy zachować adresy pracowników, aby pomóc nam określić, kto może być w stanie pokryć zmianę w innej lokalizacji.
Chociaż moglibyśmy przechowywać adresy pracowników bezpośrednio w Personel W związku z tym, że adresy zmieniają się częściej niż inne dane, możemy chcieć oddzielić dane osobowe pracowników od ich informacji biznesowych. Możemy utworzyć oddzielną tabelę do przechowywania adresów, co oznacza utworzenie relacji klucza obcego między wierszem personelu a powiązanym adresem z nową kolumną, a także instrukcje dla nowej struktury tabeli i wstawiania danych.
|
staff_id |
first_name |
last_name |
stanowisko |
start_date |
lokalizacja |
address_id |
|
1 |
Sue |
Tindale |
CFO |
8/3/2001 |
1 |
1 |
|
2 |
Ian |
Tindale |
CEO |
8/3/2001 |
1 |
2 |
|
3 |
Marny |
Hermiona |
Roaster |
10/24/2007 |
2 |
3 |
|
4 |
Chelsea |
Claudia |
Roaster |
7/3/2003 |
2 |
4 |
|
5 |
Alec |
Isadora |
Roaster |
4/2/2008 |
2 |
5 |
|
6 |
Xena |
Rahim |
Kierownik sklepu |
7/24/2016 |
3 |
6 |
|
7 |
Kelsey |
Cameron |
Coffee Wrangler |
10/18/2003 |
3 |
7 |
|
8 |
Hamilton |
Emi |
Coffee Wrangler |
2/9/2005 |
3 |
8 |
|
9 |
Caldwell |
Veda |
Coffee Wrangler |
9/9/2013 |
3 |
9 |
|
10 |
Ima |
Winifred |
Coffee Wrangler |
12/10/2016 |
3 |
10 |
Tabela 4. Proszę dodać kolumnę klucza obcego address_id do tabeli Personel
|
address_id |
staff_id |
staff_address |
staff_city |
staff_state_province |
staff_postal_code |
staff_telephone |
|
1 |
1 |
111 Atlantic Avenue |
Brooklyn |
NY |
11201 |
999-888-7777 |
|
2 |
2 |
111 Atlantic Avenue |
Brooklyn |
NY |
11201 |
777-666-5555 |
|
3 |
3 |
94-22 117th Street |
Jamajka |
NY |
11419 |
123-456-7890 |
|
4 |
4 |
171-12 104th Avenue |
Jamajka |
NY |
11433 |
987-654-3210 |
|
5 |
5 |
8210 Surrey Place |
Jamajka |
NY |
11432 |
234-567-8901 |
|
6 |
6 |
13 46th Street |
Long Island City |
NY |
11101 |
345-678-9012 |
|
7 |
7 |
50-6 46th Street |
Woodside |
NY |
11377 |
456-789-0123 |
|
8 |
8 |
212 Leonard Street |
Brooklyn |
NY |
11211 |
567-890-1234 |
|
9 |
9 |
33-52 74th Street |
Jackson Heights |
NY |
11372 |
678-901-2345 |
|
10 |
10 |
33-1 29th Street |
Astoria |
NY |
11106 |
789-012-3456 |
Tabela 5. Nowa tabela staff_address
Na wykresie musielibyśmy dodać dane dla nowej tabeli StaffAddress węzeł i jego związek z Personel węzłów. Nie miałoby to wpływu na istniejące dane, więc nie musielibyśmy ich zmieniać. Personel podmiotów w bazie danych.
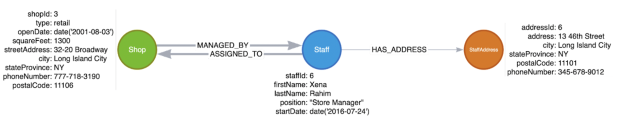
Rysunek 3: Refaktoryzacja nr 2 dla grafu
Refaktoryzacja 3: Dodawanie danych do istniejących tabel
W przypadku naszej trzeciej i ostatniej refaktoryzacji, biznes kwitnie i możemy chcieć dodać nowo zatrudnionych pracowników do nowej lokalizacji sklepu.
W strukturze relacyjnej utworzenie nowego pracownika w tabeli oznacza, że będziemy potrzebować przypisania lokalizacji sklepu, aby wiersz był kompletny. Prawdopodobnie będziemy potrzebować jakiegoś rodzaju reguła zależności (ograniczenie) która gwarantuje, że nie możemy wstawić wartości w polu Personel kolumnie lokalizacji tabeli, jeśli nie istnieje ona w tabeli Shop_Location tabela. Jeśli chcemy dodać adres nowego pracownika do tabeli staff_address musielibyśmy skonfigurować te same poręcze również w tej tabeli. Oznacza to, że każdy nowy pracownik przypisany do nowej lokalizacji musi najpierw utworzyć lokalizację, następnie pracownika, a następnie jego adres. Wykonanie tych kroków w niewłaściwej kolejności spowoduje błędy.
|
sales_outlet_id |
sales_outlet_type |
store_open_date |
store_square_feet |
store_address |
store_city |
store_state_province |
store_telephone |
store_postal_code |
menedżer |
|
1 |
centrala |
8/1/2016 |
0 |
na |
Nowy Jork |
NY |
111-222-3333 |
44444 |
2 |
|
2 |
magazyn |
7/3/2003 |
3400 |
164-14 Jamaica Ave |
Jamajka |
NY |
972-871-0402 |
11432 |
1 |
|
3 |
sprzedaż detaliczna |
8/3/2001 |
1300 |
32-20 Broadway |
Long Island City |
NY |
777-718-3190 |
11106 |
6 |
|
4 |
sprzedaż detaliczna |
9/15/2022 |
1400 |
376 Union Avenue |
Brooklyn |
NY |
978-878-0488 |
11211 |
11 |
Tabela 6. Tabela shop_location z nowym wierszem
|
staff_id |
first_name |
last_name |
stanowisko |
start_date |
lokalizacja |
address_id |
|
1 |
Sue |
Tindale |
CFO |
8/3/2001 |
1 |
1 |
|
2 |
Ian |
Tindale |
CEO |
8/3/2001 |
1 |
2 |
|
3 |
Marny |
Hermiona |
Roaster |
10/24/2007 |
2 |
3 |
|
4 |
Chelsea |
Claudia |
Roaster |
7/3/2003 |
2 |
4 |
|
5 |
Alec |
Isadora |
Roaster |
4/2/2008 |
2 |
5 |
|
6 |
Xena |
Rahim |
Kierownik sklepu |
7/24/2016 |
3 |
6 |
|
7 |
Kelsey |
Cameron |
Coffee Wrangler |
10/18/2003 |
3 |
7 |
|
8 |
Hamilton |
Emi |
Coffee Wrangler |
2/9/2005 |
3 |
8 |
|
9 |
Caldwell |
Veda |
Coffee Wrangler |
9/9/2013 |
3 |
9 |
|
10 |
Ima |
Winifred |
Coffee Wrangler |
12/10/2016 |
3 |
10 |
|
11 |
Jasmine |
Patterson |
Kierownik sklepu |
9/12/2022 |
4 |
11 |
|
12 |
Jose |
Vino |
Coffee Wrangler |
09/13/2022 |
4 |
12 |
Tabela 7. Tabela personelu z 2 nowymi pracownikami
|
address_id |
staff_id |
staff_address |
staff_city |
staff_state_province |
staff_postal_code |
staff_telephone |
|
1 |
1 |
111 Atlantic Avenue |
Brooklyn |
NY |
11201 |
999-888-7777 |
|
2 |
2 |
111 Atlantic Avenue |
Brooklyn |
NY |
11201 |
777-666-5555 |
|
3 |
3 |
94-22 117th Street |
Jamajka |
NY |
11419 |
123-456-7890 |
|
4 |
4 |
171-12 104th Avenue |
Jamajka |
NY |
11433 |
987-654-3210 |
|
5 |
5 |
8210 Surrey Place |
Jamajka |
NY |
11432 |
234-567-8901 |
|
6 |
6 |
13 46th Street |
Long Island City |
NY |
11101 |
345-678-9012 |
|
7 |
7 |
50-6 46th Street |
Woodside |
NY |
11377 |
456-789-0123 |
|
8 |
8 |
212 Leonard Street |
Brooklyn |
NY |
11211 |
567-890-1234 |
|
9 |
9 |
33-52 74th Street |
Jackson Heights |
NY |
11372 |
678-901-2345 |
|
10 |
10 |
33-1 29th Street |
Astoria |
NY |
11106 |
789-012-3456 |
|
11 |
11 |
107 Irving Avenue |
Brooklyn |
NY |
11237 |
890-123-4567 |
|
12 |
12 |
43-1 Cambridge Place |
Brooklyn |
NY |
11238 |
901-234-5678 |
Tabela 8. Tabela staff_address z 2 nowymi adresami
W przypadku naszej wersji wykresu musimy po prostu dodać nowe dane. Struktura pozostaje taka sama, a istniejące dane nie ulegają zmianie.
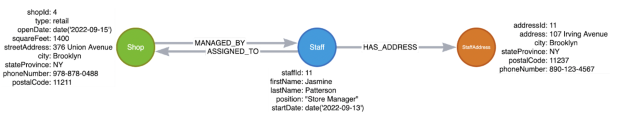
Rysunek 4: Refaktoryzacja nr 3 dla grafu
Graphs Reduce Data Refactoring
Widzieliśmy, jak refaktoryzacja danych wpływa zarówno na relacyjne, jak i grafowe bazy danych. Relacyjne bazy danych wymagają bardziej intensywnego procesu wprowadzania zmian ze względu na oddzielenie struktury tabeli od rzeczywistych danych. W przeciwieństwie do nich, grafy usuwają dodatkowy etap translacji między danymi rzeczywistymi a strukturą bazy danych, ponieważ w bardziej naturalny sposób modelują dane tak, jak istnieją one w świecie rzeczywistym.
Czas spędzony w dzisiejszym przykładzie mógł wydawać się trywialny, ale co się dzieje, gdy mają Państwo tysiące, miliony lub miliardy sklepów, pracowników i adresów? Systemy o krytycznym znaczeniu dla biznesu zniechęcają zespoły do wprowadzania zmian ze względu na pracochłonność i potencjalne skutki. Wykresy zachowują dane i model, który już mamy i zmieniają tylko to, co się zmieniło.
Refaktoryzacja grafów pozwala firmom na adaptację i zwinność, dając im możliwość przekształcania się wraz ze zmianami w branży lub danych wokół nich. Przejście na grafy w bieżącym projekcie może teraz skrócić czas wprowadzania produktu na rynek, a także poprawić przyszłą łatwość konserwacji, ograniczanie ryzyka i rozwój dodatkowych funkcji.
Proszę dowiedzieć się więcej o modelowaniu grafów i refaktoryzacji poprzez Neo4j GraphAcademy, gdzie znajdą Państwo darmowe kursy online!