
Ten artykuł poświęcony jest integracji Airbyte z jednymi z najpopularniejszych orkiestratorów danych w branży – Apache Airflow, Dagster i Prefect. Nie tylko przeprowadzimy Państwa przez proces integracji Airbyte z tymi orkiestratorami, ale także zapewnimy wgląd porównawczy w to, w jaki sposób każdy z nich może w wyjątkowy sposób usprawnić przepływy pracy z danymi.
Udostępniamy również linki do przykładów działającego kodu dla każdej z tych integracji. Zasoby te zostały zaprojektowane z myślą o szybkim wdrożeniu, umożliwiając płynną integrację Airbyte z wybranym przez Państwa orkiestratorem.
Niezależnie od tego, czy chcą Państwo usprawnić istniejące przepływy danych, porównać te orkiestratory, czy też odkryć nowe sposoby wykorzystania Airbyte w swojej strategii dotyczącej danych, ten post jest dla Państwa. Zanurzmy się i zbadajmy, w jaki sposób te integracje mogą poprawić Państwa podejście do zarządzania danymi.
Przegląd orkiestratorów danych: Apache Airflow, Dagster i Prefect
Na dynamicznej arenie nowoczesnego zarządzania danymi interoperacyjność jest kluczowa, jednak orkiestracja przepływów danych pozostaje złożonym wyzwaniem. W tym miejscu narzędzia takie jak Apache Airflow, Prefect i Dagster stają się istotne dla zespołów inżynierii danych, z których każde wnosi unikalne zalety.
Apache Airflow: Weteran orkiestracji przepływu pracy
Kontekst
Narodził się w Airbnb i został opracowany przez Maxime Beauchemin, Apache Airflow stał się sprawdzonym w boju rozwiązaniem do orkiestracji złożonych potoków danych. Jego przyjęcie przez Apache Software Foundation tylko umocniło jego pozycję jako niezawodnego narzędzia open-source.
Mocne strony
- Solidna społeczność i wsparcie: Dzięki szerokiemu zastosowaniu w tysiącach firm, Airflow może pochwalić się ogromną społecznością, zapewniając łatwy dostęp do rozwiązań typowych problemów.
- Bogaty ekosystem integracji: Mnogość dostawców platformy ułatwia integrację z niemal każdym narzędziem danych, zwiększając jej użyteczność w różnych środowiskach.
Wyzwania
Wraz z ewolucją krajobrazu danych, Airflow napotyka przeszkody w obszarach takich jak testowanie, nieplanowane przepływy pracy, parametryzacja, transfer danych między zadaniami i abstrakcja pamięci masowej, co skłania do poszukiwania alternatywnych narzędzi.
Dagster: Nowe podejście do inżynierii danych
Kontekst
Założona w 2018 roku przez Nicka Schrocka, Dagster przyjmuje podejście do inżynierii danych oparte na pierwszych zasadach, biorąc pod uwagę cały cykl rozwoju.
Cechy
- Zorientowany na cykl życia oprogramowania: Doskonale radzi sobie z pełnym spektrum od rozwoju do wdrożenia, z silnym naciskiem na testowanie i obserwowalność.
- Elastyczne przechowywanie i wykonywanie danych: Dagster abstrahuje od obliczeń i przechowywania danych, umożliwiając bardziej elastyczną i specyficzną dla środowiska obsługę danych.
Prefect: Upraszczanie złożonych potoków
Kontekst
Pomysłodawcą jest Jeremiah Lowin, Prefekt zajmuje się orkiestracją poprzez wykorzystanie istniejącego kodu i osadzenie go w rozproszonym potoku wspieranym przez potężny silnik planowania.
Cechy
- Filozofia inżynierii: Prefect działa przy założeniu, że użytkownicy są biegli w kodowaniu, koncentrując się na ułatwieniu przejścia od kodu do rozproszonych potoków.
- Parametryzacja i szybkie planowanie: Doskonale parametryzuje przepływy i oferuje szybkie planowanie, dzięki czemu nadaje się do złożonych zadań obliczeniowych.
Każdy orkiestrator odpowiada na wyzwania związane z zarządzaniem przepływem danych w unikalny sposób: Szerokie zastosowanie Apache Airflow i rozbudowane integracje sprawiają, że jest to bezpieczny i niezawodny wybór. Zorientowane na cykl życia podejście Dagster zapewnia elastyczność, szczególnie w zakresie rozwoju i testowania. Prefect koncentruje się na prostocie i wydajnym planowaniu, dzięki czemu idealnie nadaje się do szybko ewoluujących przepływów pracy.
Integracja Airbyte z Airflow, Dagster i Prefect
W tej sekcji pokrótce omówimy unikalne aspekty integracji Airbyte z tymi trzema popularnymi orkiestratorami danych na niskim poziomie. Chociaż szczegółowe instrukcje krok po kroku są dostępne w odpowiednich repozytoriach GitHub, tutaj skupimy się na tym, jak wygląda integracja tych narzędzi.
Integracja Airbyte i Apache Airflow
Proszę znaleźć działający przykład tej integracji w tym repozytorium GitHub.
Integracja Airbyte z Apache Airflow tworzy potężną synergię do zarządzania i automatyzacji przepływu danych. Zarówno Airbyte, jak i Airflow są zwykle wdrażane w środowiskach kontenerowych, co zwiększa ich skalowalność i łatwość zarządzania.
Rozważania dotyczące wdrożenia
- Środowiska kontenerowe: Wdrożenie kontenerowe Airbyte i Airflow ułatwia skalowanie, kontrolę wersji i usprawnia procesy wdrażania.
- Dostępność sieci: W przypadku wdrożenia w oddzielnych kontenerach lub kapsułach Kubernetes, zapewnienie łączności sieciowej między Airbyte i Airflow jest niezbędne do płynnej integracji.
Przed zagłębieniem się w szczegóły integracji, należy zauważyć, że przykłady kodu i szczegóły konfiguracji można znaleźć w sekcji repozytorium Airbyte-Airflow GitHub, w szczególności pod orchestration/airflow/dags/. Katalog ten zawiera niezbędne skrypty i pliki, w tym plik elt_dag.py który jest kluczowy dla zrozumienia integracji.
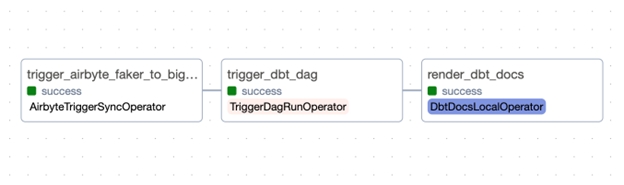
Plik elt_dag.py Skrypt stanowi przykład integracji Airbyte w ramach Airflow DAG.
-
AirbyteTriggerSyncOperator: Ten operator służy do uruchamiania zadań synchronizacji w Airbyte, łączenia się ze źródłami danych i zarządzania przepływem danych.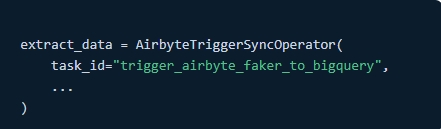
-
TriggerDagRunOperator and DbtDocsOperator: Operatory te pokazują, w jaki sposób Airflow może organizować złożone przepływy pracy, takie jak wyzwalanie dbt DAG po zadaniu Airbyte.
-
Sekwencjonowanie zadań: Skrypt definiuje sekwencję zadań, prezentując intuicyjną i czytelną składnię Airflow:

-
Definicja DAG: Używając
@dagdekorator, DAG jest zdefiniowany w sposób przejrzysty i łatwy w utrzymaniu.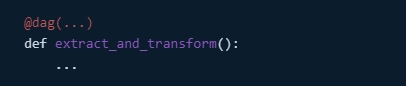
Korzyści z integracji
- Zautomatyzowane zarządzanie przepływem pracy: Integracja Airbyte z Airflow automatyzuje i optymalizuje proces potoku danych.
- Ulepszone monitorowanie i obsługa błędów: Możliwości Airflow w zakresie monitorowania i obsługi błędów przyczyniają się do bardziej niezawodnego i przejrzystego potoku danych.
- Skalowalność i elastyczność: Integracja oferuje skalowalne rozwiązania dla różnych ilości danych i elastyczność w dostosowywaniu do konkretnych wymagań.
Integracja Airbyte i Dagster
Proszę znaleźć działający przykład tej integracji w tym repozytorium GitHub.
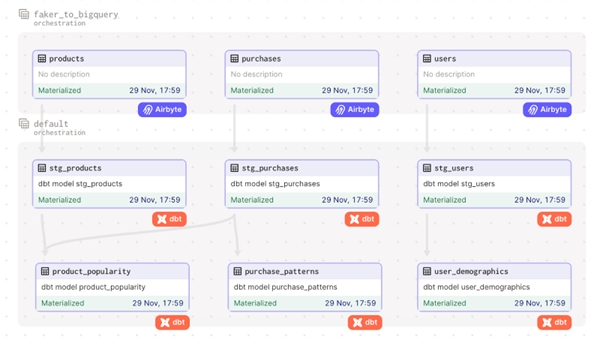
Integracja Airbyte z Dagster łączy w sobie solidne możliwości integracji danych Airbyte z naciskiem Dagster na produktywność rozwoju i wydajność operacyjną, tworząc przyjazne dla programistów podejście do budowy i konserwacji potoku danych.
Aby uzyskać szczegółowe informacje na temat tej integracji, w tym konkretne konfiguracje i przykłady kodu, proszę zapoznać się z poniższym artykułem Repozytorium Airbyte-Dagster GitHub, w szczególności skupiając się na orchestration/assets.py pliku.
The orchestration/assets.py stanowi wyraźny przykład tego, jak można skutecznie zintegrować Airbyte i Dagster.
-
Konfiguracja AirbyteResource: Ten segment kodu konfiguruje połączenie z instancją Airbyte, określając host, port i dane uwierzytelniające. Użycie zmiennych środowiskowych dla poufnych informacji, takich jak hasła, zwiększa bezpieczeństwo.
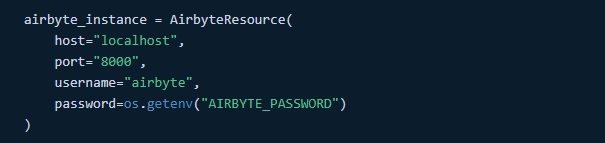
- Dynamiczne ładowanie zasobów: Integracja wykorzystuje funkcję
load_assets_from_airbyte_instancedo dynamicznego ładowania zasobów w oparciu o instancję Airbyte. To dynamiczne ładowanie ma kluczowe znaczenie dla zarządzania wieloma łącznikami danych i organizowania złożonych przepływów pracy z danymi.
-
Dbt Integration: Snippet demonstruje również integrację dbt do transformacji danych w tym samym potoku, pokazując, jak polecenia dbt mogą być wykonywane w potoku Dagster.

Korzyści z integracji
- Usprawniony rozwój: Podejście Dagster usprawnia rozwój i utrzymanie potoków danych, dzięki czemu integracja złożonych systemów, takich jak Airbyte, jest łatwiejsza w zarządzaniu.
- Widoczność operacyjna: Lepszy wgląd w przepływy pracy z danymi pomaga skuteczniej monitorować i optymalizować procesy związane z danymi.
- Elastyczna konstrukcja potoku: Elastyczność integracji pozwala na tworzenie solidnych i dostosowanych potoków danych, spełniających różne wymagania biznesowe.
Integracja Airbyte i Prefect
Proszę znaleźć działający przykład tej integracji w tym repozytorium GitHub.

Integracja Airbyte z Prefect reprezentuje przyszłościowe podejście do orkiestracji potoku danych, łącząc szerokie możliwości integracji danych Airbyte z nowoczesnym, Pythonicznym zarządzaniem przepływem pracy Prefect.
Aby zapoznać się ze szczegółowymi przykładami kodu i konfiguracją, prosimy zajrzeć na stronę my_elt_flow.py w pliku Repozytorium Airbyte-Prefect GitHub, znajdujące się pod adresem orchestration/my_elt_flow.py.
Ten plik zawiera praktyczny przykład tego, jak zorganizować przepływ pracy ELT (Extract, Load, Transform) przy użyciu Airbyte i Prefect.
-
AirbyteServerkonfiguracja: Skrypt rozpoczyna się od skonfigurowania zdalnego serwera Airbyte, określając szczegóły uwierzytelniania i informacje o serwerze. Konfiguracja ta jest niezbędna do nawiązania połączenia z instancją Airbyte.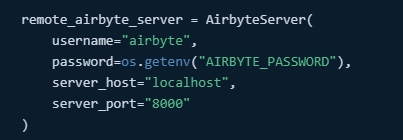
AirbyteConnectioni synchronizacji: AnAirbyteConnectionjest tworzony w celu zarządzania połączeniem z Airbyte. Obiektrun_airbyte_syncuruchamia i monitoruje zadanie synchronizacji Airbyte, demonstrując sposób integracji i kontroli zadań Airbyte w ramach przepływu Prefect.
-
Integracja Dbt: Przepływ integruje również operacje dbt przy użyciu funkcji
DbtCoreOperationtask. Pokazuje to, w jaki sposób polecenia dbt można włączyć do przepływu Prefect, łącząc je z wynikami zadania synchronizacji Airbyte.
-
Definicja przepływu: Prefekt
@flowsłuży do definiowania ogólnego przepływu pracy ELT. Przepływ organizuje sekwencję zadań synchronizacji Airbyte i dbt, pokazując zdolność Prefect do eleganckiego zarządzania złożonymi przepływami danych.
Korzyści z integracji
- Dynamiczna automatyzacja przepływu pracy: Możliwości dynamicznego przepływu Prefect pozwalają na elastyczną i adaptowalną konstrukcję potoku, dostosowując się do złożonych i zmieniających się potrzeb w zakresie danych.
- Ulepszona obsługa błędów: Integracja korzysta z solidnej obsługi błędów Prefect, zapewniając bardziej niezawodne i odporne przepływy danych.
- Pythoniczna elegancja: Podejście Prefect skoncentrowane na Pythonie oferuje znajome i intuicyjne środowisko dla inżynierów danych, umożliwiając płynną integrację różnych narzędzi danych.
Podsumowanie
Jak omówiliśmy w tym poście, integracja Airbyte z orkiestratorami danych, takimi jak Apache Airflow, Dagster i Prefect, może znacznie podnieść wydajność, skalowalność i solidność Państwa przepływów pracy z danymi. Każdy orkiestrator wnosi swoje unikalne zalety – od złożonego harmonogramu Airflow i zarządzania zależnościami, przez skupienie się Dagster na produktywności rozwoju, po nowoczesną, dynamiczną orkiestrację przepływu pracy Prefect.
Specyfika tych integracji, jak pokazano za pomocą fragmentów kodu i odniesień do repozytorium, podkreśla moc i elastyczność, jaką oferują te kombinacje.
Zachęcamy do zagłębienia się w udostępnione repozytoria GitHub w celu uzyskania szczegółowych instrukcji i eksperymentowania z tymi integracjami we własnych środowiskach. Droga uczenia się i doskonalenia jest ciągła, a stale ewoluujący charakter tych narzędzi obiecuje jeszcze więcej ekscytujących możliwości.
Proszę pamiętać, że najskuteczniejsze potoki danych to te, które są nie tylko dobrze zaprojektowane, ale także stale monitorowane, optymalizowane i aktualizowane, aby sprostać zmieniającym się potrzebom i wyzwaniom. Proszę więc zachować ciekawość, eksperymentować i nie wahać się dzielić swoimi doświadczeniami i spostrzeżeniami ze społecznością.