
Jeśli Państwa praca wiąże się z analizą danych, optymalizacją SEO lub jakąkolwiek rolą, która wymaga przeszukiwania treści cyfrowych, zrozumienie, jak skutecznie wyodrębniać słowa kluczowe, jest niezbędne. Umiejętność ta usprawnia zarządzanie danymi i ich dostępność, stanowiąc znaczący postęp w metodologii przetwarzania i analizy danych.
W samym centrum tej umiejętności znajduje się przetwarzanie języka naturalnego. Ta najnowocześniejsza technologia umożliwia komputerom zrozumienie ludzkiego języka, skutecznie zmniejszając przepaść między zarządzaniem danymi cyfrowymi a rzeczywistą interakcją międzyludzką. W tej dziedzinie biblioteka spaCy Python wyróżnia się solidnymi funkcjami przetwarzania języka. Znana ze swojej wydajności i łatwości użytkowania, spaCy umożliwia profesjonalistom z różnych dziedzin usprawnienie praktyk analizy tekstu, poprawiając ich przepływ pracy i wyniki.
W tym artykule chciałbym pomóc Państwu poszerzyć wiedzę na temat NLP i pokazać, w jaki sposób spaCy może być Państwa potężnym sprzymierzeńcem w skutecznej ekstrakcji słów kluczowych. Zapoznając się z tymi technologiami, zostaną Państwo wyposażeni w wiedzę, która pozwoli wykorzystać ich potencjał, zwiększając Państwa zdolność do wydobywania cennych informacji z tekstu.
Zrozumienie przetwarzania języka naturalnego
NLP jest istotną dziedziną w ramach szerszej dyscypliny sztucznej inteligencji, która łączy komunikację międzyludzką i zrozumienie komputerowe. Jest to technologia stojąca za zdolnością komputera do interpretowania, rozumienia i wyprowadzania znaczenia z ludzkiego języka. NLP łączy ustrukturyzowane podejście lingwistyki obliczeniowej z innowacyjnymi technikami metod statystycznych, uczenia maszynowego i głębokiego uczenia.
NLP jest stale obecne w naszym życiu, subtelnie zasilając takie rzeczy jak aktywowany głosem GPS i wirtualni asystenci naszych smartfonów. Jednak rola NLP wykracza daleko poza proste polecenia; zagłębia się w złożone obszary, takie jak analiza tekstu, tłumaczenie języków, ocena nastrojów i, co ważne dla naszej dyskusji, wyodrębnianie słów kluczowych.
Proces wyodrębniania słów kluczowych obejmuje identyfikację najistotniejszych słów lub fraz w tekście. Te słowa kluczowe mogą podsumować treść i zaoferować wgląd w omawiany temat. Technika ta ma kluczowe znaczenie dla profesjonalistów, którzy muszą efektywnie przetwarzać i kategoryzować duże ilości tekstu. Wykorzystując NLP do automatyzacji ekstrakcji słów kluczowych, można osiągnąć znaczną oszczędność czasu. Redukcja ręcznego wysiłku pozwala specjalistom poświęcić więcej czasu na analizę i podejmowanie decyzji, usprawniając etap wstępnego przetwarzania danych.
Wprowadzenie do spaCy
spaCy jest kluczowym narzędziem w zestawie narzędzi profesjonalistów pracujących z NLP. Jego konstrukcja jest przeznaczona dla osób wymagających wydajnych i dokładnych możliwości przetwarzania języka, co czyni go kamieniem węgielnym dla projektów obejmujących analizę tekstu. Zbudowany w języku Python, spaCy łączy prostotę z mocą, oferując funkcje obejmujące szerokie spektrum zadań NLP, w tym tokenizację, tagowanie części mowy, rozpoznawanie nazwanych jednostek i parsowanie zależności.
To, co wyróżnia spaCy, to jego zaangażowanie w wydajność i skalowalność. Zoptymalizowany pod kątem szybkości, szybko przetwarza duże ilości tekstu, zapewniając, że projekty obejmujące obszerne zbiory danych lub strumienie danych w czasie rzeczywistym korzystają ze skróconego czasu przetwarzania. Algorytmy spaCy są biegłe w wychwytywaniu subtelności ludzkiego języka, zwiększając w ten sposób trafność i głębię wyników ekstrakcji słów kluczowych.
spaCy może pochwalić się obszerną dokumentacją i wsparciem tętniącej życiem społeczności, oferując łatwy start. Zasoby te ułatwiają płynną integrację spaCy z różnymi projektami, zarówno w celu ulepszenia istniejących przepływów pracy, jak i osadzenia możliwości NLP w nowych aplikacjach. Poniżej zagłębimy się w instalację spaCy, zbadamy jego architekturę modelu i zilustrujemy jego zastosowanie w ekstrakcji słów kluczowych na praktycznych przykładach.
Instalacja spaCy i konfiguracja środowiska
Aby rozpocząć wykorzystywanie spaCy do zadań NLP, pierwszym krokiem jest skonfigurowanie spaCy na Państwa komputerze. Proces ten jest dość prosty:
1. Warunki wstępne
spaCy obsługuje różne wersje Pythona, dzięki czemu jest dostępny dla większości użytkowników. Aby uzyskać płynne działanie, zalecam korzystanie ze środowiska wirtualnego w celu efektywnego zarządzania zależnościami.
2. Proszę zainstalować spaCy
Proszę wykonać następujące polecenie w terminalu lub wierszu poleceń:
pip install -U pip setuptools wheel
pip install -U spacy3. Proszę pobrać modele językowe
spaCy działa przy użyciu modeli językowych dostosowanych do różnych języków. Modele te odgrywają kluczową rolę w zadaniach takich jak tokenizacja, tagowanie części mowy i rozpoznawanie jednostek nazwanych. Aby pobrać model, proszę użyć:
python -m spacy download en_core_web_lgOgólnie rzecz biorąc, spaCy oczekuje, że wszystkie pakiety potoku będą zgodne z konwencją nazewnictwa [lang]_[name].
W przypadku rurociągów spaCy zdecydowaliśmy się również podzielić nazwę na trzy komponenty:
- Typ: Możliwości (np. rdzeń dla potoku ogólnego przeznaczenia z tagowaniem, parsowaniem, lematyzacją i rozpoznawaniem jednostek nazwanych lub dep tylko dla tagowania, parsowania i lematyzacji).
- Gatunek: Rodzaj tekstu, na którym trenowany jest potok, np. strony internetowe lub wiadomości.
- Rozmiar: Wskaźnik rozmiaru pakietu, sm, md, lg lub trf. Dla potoków z domyślnymi wektorami, md ma zredukowaną tablicę wektorów słów z 20 tys. unikalnych wektorów dla ~500 tys. słów, a lg ma dużą tablicę wektorów słów z ~500 tys. wpisów. W przypadku rurociągów z wektorami floret, tabele wektorów md mają 50 tys. wpisów, a tabele wektorów lg mają 200 tys. wpisów.
np, en_core_web_sm to mały potok języka angielskiego przeszkolony na pisanym tekście internetowym (blogi, wiadomości, komentarze), który obejmuje słownictwo, składnię i encje. spaCy oferuje modele o różnych rozmiarach, aby zrównoważyć szybkość i dokładność zgodnie z potrzebami Państwa projektu.
Po zainstalowaniu spaCy, integracja z Państwa projektami wymaga zaledwie kilku linijek kodu. Projekt biblioteki kładzie nacisk na łatwość użytkowania, pozwalając skupić się na logice aplikacji, a nie na standardowym kodzie.
Praktyczne zastosowania spaCy do ekstrakcji słów kluczowych
spaCy, ze swoimi wszechstronnymi możliwościami NLP, doskonale radzi sobie z wydajnym wydobywaniem słów kluczowych, zwłaszcza gdy wykorzystuje się jego większe modele, takie jak en_core_web_lg dla większej dokładności.
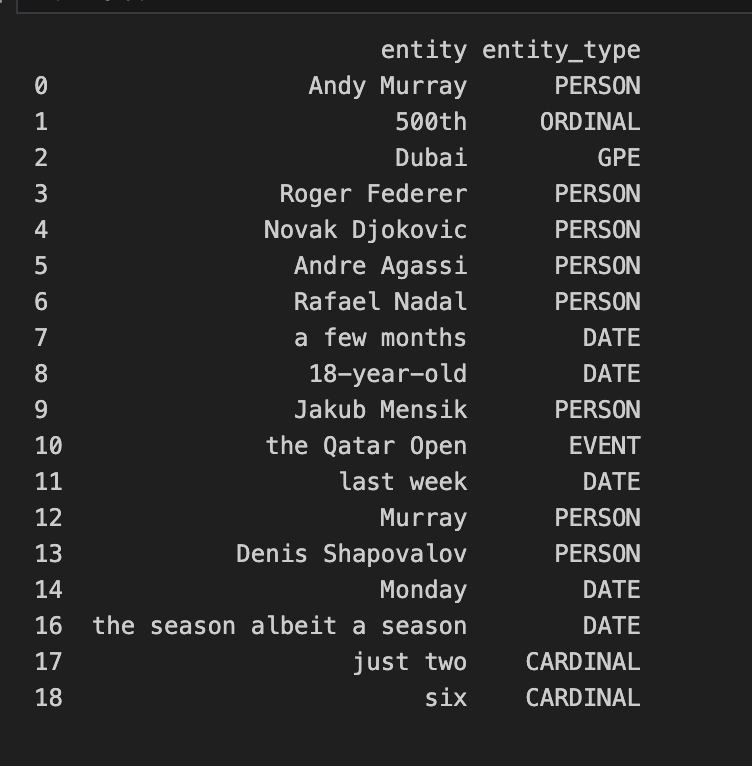
Rozważmy scenariusz, w którym analizujemy artykuł sportowy, aby wyodrębnić kluczowe jednostki, takie jak nazwiska sportowców, lokalizacje i ważne numery. Zastosujmy spaCy do migawki tekstu z artykułu omawiającego karierę Andy’ego Murraya:
import spacy
import pandas as pd
# Load spaCy's large English model
nlp = spacy.load("en_core_web_lg")
# Sample text from a sports news article
text = """Andy Murray chalked up a 500th hard-court win in Dubai to join an exclusive club containing greats Roger Federer, Novak Djokovic, Andre Agassi, and Rafael Nadal - then sparked more speculation over his future by suggesting he only has a few months left of his career. Fresh from a chastening defeat to 18-year-old Jakub Mensik in the Qatar Open last week, Murray produced a superb comeback to beat Denis Shapovalov on Monday. It was Murray's biggest result of the season - albeit a season that has yielded just two wins from six tournaments."""
# Process the text with spaCy
doc = nlp(text)
# Extract entities and their labels
ent_label = []
for ent in doc.ents:
ent_label.append([ent.text, ent.label_])
# Create a DataFrame to display entities and their types
df = pd.DataFrame(ent_label, columns=['entity', 'entity_type']).drop_duplicates()
print(df)Ten fragment kodu przetwarza tekst, identyfikując i oznaczając jednostki, takie jak nazwiska, organizacje, lokalizacje i liczby. Przekształcając te encje w pandas DataFrame, możemy łatwo przeglądać i analizować wyodrębnione informacje.
Więcej niż podstawowa ekstrakcja
Podczas gdy powyższy przykład koncentruje się na wyodrębnianiu nazwanych jednostek, możliwości spaCy sięgają dalej. Dostosowując potok NLP lub integrując spaCy z modelami uczenia maszynowego, można udoskonalić proces ekstrakcji słów kluczowych, aby dostosować go do konkretnych potrzeb. Może to obejmować identyfikację tematycznych słów kluczowych poza nazwanymi jednostkami, analizę nastrojów w celu oceny tonu tekstu lub powiązanie wyodrębnionych słów kluczowych z szerszymi tematami w celu kompleksowej analizy treści.
W praktyce wykorzystanie spaCy do ekstrakcji słów kluczowych umożliwia profesjonalistom efektywną nawigację i organizowanie dużych zbiorów danych. Niezależnie od tego, czy chodzi o podsumowywanie artykułów informacyjnych, analizowanie opinii klientów czy kategoryzowanie artykułów naukowych, spaCy zapewnia skalowalne i dokładne rozwiązanie do wyodrębniania znaczących słów kluczowych.
Wyzwania i ograniczenia spaCy
Pomimo solidnych możliwości spaCy w zakresie ekstrakcji słów kluczowych i zadań NLP, mogą Państwo napotkać wyzwania i ograniczenia, które wynikają z nieodłącznej złożoności języka i projektu narzędzia. Jednym ze znaczących wyzwań jest obsługa niuansów lub niejednoznacznego języka. Język naturalny jest pełen zawiłości, takich jak idiomy, sarkazm i znaczenia, które zależą od kontekstu. Pomimo tego, że modele spaCy są szkolone na dużych zbiorach danych w celu rozpoznawania różnych wzorców językowych, czasami mają trudności z interpretacją tekstów o wysokim stopniu niejednoznaczności lub specjalistycznej terminologii. Problem ten może wpływać na dokładność ekstrakcji słów kluczowych, potencjalnie prowadząc do pominięcia lub nieprawidłowej interpretacji ważnych informacji przez model.
Skuteczność i precyzja spaCy zależy w dużej mierze od jakości i trafności wstępnie wytrenowanych modeli. Chociaż modele te stanowią potężny punkt wyjścia, ich skuteczność może się różnić w zależności od języka i specjalistycznej dziedziny. Na przykład model wyszkolony głównie na artykułach informacyjnych może mieć trudności z dokładnym przetwarzaniem dokumentów technicznych z dziedzin takich jak prawo czy medycyna. Oznacza to, że trzeba będzie włożyć dodatkową pracę w niestandardowe szkolenie lub dostosowanie modeli za pomocą danych specyficznych dla danej dziedziny. Jednak nawet z tymi przeszkodami spaCy wyróżnia się jako narzędzie do zadań NLP. Wiedza o tym, gdzie są jego braki, jest kluczem do maksymalnego wykorzystania tego, co oferuje i uniknięcia wszelkich problemów.
spaCy wyróżnia się w dziedzinie przetwarzania języka naturalnego, oferując zestaw funkcji do różnych zadań analizy tekstu, w tym ekstrakcji słów kluczowych. Jego konfiguracja zapewnia zgrabną równowagę między szybkością a dokładną obsługą języka, dając ludziom na różnych stanowiskach poważny impuls do pracy z mnóstwem danych tekstowych w celu znalezienia samorodków wglądu, których potrzebują. Możliwość szybkiego i dokładnego wyodrębniania słów kluczowych za pomocą spaCy nie tylko usprawnia zarządzanie danymi, ale także znacznie przyspiesza procesy analityczne, umożliwiając głębsze zrozumienie treści na dużą skalę.
W naszej eksploracji spaCy i jego zastosowania w wyodrębnianiu słów kluczowych, odsłoniliśmy warstwy jego funkcjonalności i praktyczności, mając na celu wyposażenie Państwa w wiedzę umożliwiającą wykorzystanie tej potężnej biblioteki. Włączając spaCy do swoich zadań NLP, proszę pamiętać, że podróż odkrywania i optymalizacji w cyfrowej analizie tekstu trwa. Podejmujmy wyzwania, cieszmy się ze spostrzeżeń i kontynuujmy wprowadzanie innowacji, zapewniając, że Państwa praca pozostanie w czołówce możliwości technologicznych.