
Nowoczesny stos danych przedstawia ewolucję zarządzanie danymi, przechodząc od tradycyjnych, monolitycznych systemów do zwinnych, opartych na chmurze architektur. Został zaprojektowany do obsługi dużych ilości danych, zapewniając skalowalność, elastyczność i możliwości przetwarzania w czasie rzeczywistym. Stos ten jest modułowy, umożliwiając organizacjom korzystanie z wyspecjalizowanych narzędzi dla każdej funkcji: pozyskiwanie danych, przechowywanie, transformację i analizę, ułatwiając bardziej wydajne i zdemokratyzowane podejście do analizy danych i operacji biznesowych. Ponieważ firmy nadal priorytetowo traktują podejmowanie decyzji w oparciu o dane, nowoczesny stos danych stał się integralną częścią odblokowywania praktycznych spostrzeżeń i wspierania innowacji.
Ewolucja nowoczesnego stosu danych
Początki: Przed 2000 rokiem
Firmy używają dużych, pojedynczych systemów do przechowywania danych i zarządzania nimi. Były one dobre do codziennych zadań biznesowych, ale nie do analizy dużej ilości danych. Dane były przechowywane w tradycyjnych relacyjnych bazach danych, takich jak Oracle, IBM DB2 i Microsoft SQL Server.
Era Big Data: Wczesne lata 2000 – 2010
Okres ten zapoczątkował zwrot w kierunku systemów, które mogły obsługiwać ogromne ilości danych z dużą prędkością i w różnych formatach. Zaczęliśmy dostrzegać znacznie więcej danych, które napływały do nas bardzo szybko. Nowe technologie, takie jak Hadoop, pomogły rozłożyć pracę z danymi na wiele komputerów.
Rozwój hurtowni danych w chmurze: Połowa lat 2010
Chmura obliczeniowa zaczęła rewolucjonizować przechowywanie i przetwarzanie danych. Hurtownie danych w chmurze, takie jak Amazon Redshift i Google BigQuery, oferowały skalowalność i elastyczność, zmieniając ekonomię i szybkość analizy danych. Pojawił się również Snowflake, startup zajmujący się hurtowniami danych w chmurze, oferujący unikalną architekturę oddzielającą przetwarzanie i przechowywanie danych.
Nowoczesny stos danych: Koniec lat 2010 – teraźniejszość
Nowoczesny stos danych nabrał kształtu wraz z rozwojem procesów ELT, narzędzi do integracji danych opartych na SaaS oraz oddzieleniem pamięci masowej i obliczeń. W tej erze nastąpiło rozpowszechnienie narzędzi zaprojektowanych dla określonych części cyklu życia danych, umożliwiając bardziej modułowe i wydajne podejście do zarządzania danymi.
Ograniczenia tradycyjnych systemów danych
W moim kariera inżyniera danychw kilku organizacjach, intensywnie pracowałem z Microsoft SQL Server. Ta sekcja będzie czerpać z tych doświadczeń, zapewniając osobisty charakter, gdy opowiadam o wyzwaniach stojących przed tym tradycyjnym systemem. Później zbadamy, w jaki sposób Modern Data Stack (MDS) rozwiązuje wiele z tych problemów; niektóre rozwiązania były dla mnie objawieniem!
Skalowalność
Tradycyjne wdrożenia SQL Server były często hostowane lokalnie, co oznaczało, że skalowanie w celu dostosowania do rosnących ilości danych wymagało znacznych inwestycji w sprzęt i mogło prowadzić do wydłużonych przestojów podczas aktualizacji. Co więcej, gdy mieliśmy do czynienia z mniejszą ilością danych, wciąż mieliśmy cały ten dodatkowy sprzęt, którego tak naprawdę nie potrzebowaliśmy. Ale wciąż za nie płaciliśmy. To tak, jakby płacić za cały autobus, gdy potrzebnych jest tylko kilka miejsc.
Złożone ETL
SSIS był szeroko stosowany do ETL; choć jest to potężne narzędzie, miało pewne ograniczenia, zwłaszcza w porównaniu z bardziej nowoczesnymi rozwiązaniami do integracji danych. Warto zauważyć, że Microsoft SQL Server rozwiązał wiele z tych ograniczeń w Azure Data Factory i SQL Server Data Tools (SSDT).
- Wywołania API: SSIS początkowo nie posiadał bezpośredniego wsparcia dla wywołań API. Do interakcji z usługami sieciowymi wymagane było tworzenie niestandardowych skryptów, co komplikowało procesy ETL.
- Alokacja pamięci: Zadania SSIS wymagały starannego zarządzania pamięcią. Bez wystarczającej ilości pamięci na serwerze, złożone zadania danych mogły zakończyć się niepowodzeniem.
- Audyt: Do monitorowania i rozwiązywania problemów konieczny był rozbudowany audyt pakietów SSIS, co dodatkowo zwiększało obciążenie pracą.
- Kontrola wersji: Wczesne wersje SSIS stanowiły wyzwanie dla integracji kontroli wersji, komplikując śledzenie zmian i współpracę zespołową.
- Dostępność międzyplatformowa: Zarządzanie SSIS z systemów innych niż Windows było trudne, ponieważ było to narzędzie skoncentrowane na systemie Windows.
Wymagania dotyczące konserwacji
Konserwacja serwerów lokalnych wymagała dużych zasobów. Przypominam sobie znaczny wysiłek wymagany do zapewnienia aktualności i płynnego działania systemów, co często wiązało się z przestojami, którymi trzeba było starannie zarządzać.
Integracja
Integracja SQL Server z nowszymi narzędziami i platformami nie zawsze była prosta. Czasami wymagało to kreatywnych obejść, które zwiększały złożoność naszej architektury danych.
Jak nowoczesny stos danych rozwiązał moje wyzwania związane z danymi
Nowoczesny stos danych (MDS) rozwiązał wiele starych problemów, które miałem z SQL Server. Teraz możemy używać chmury do przechowywania danych, co oznacza koniec wydatków na duże, drogie serwery, których nie zawsze potrzebujemy. Pobieranie danych z różnych miejsc jest łatwiejsze, ponieważ istnieją narzędzia, które robią to wszystko za nas i nie ma już skomplikowanego kodowania.
Jeśli chodzi o sortowanie i czyszczenie naszych danych, możemy to zrobić bezpośrednio w bazie danych za pomocą prostych poleceń. Pozwala to uniknąć bólu głowy związanego z zarządzaniem dużymi serwerami lub przekopywaniem się przez tony danych w celu znalezienia drobnego błędu. A kiedy mówimy o utrzymaniu bezpieczeństwa i porządku naszych danych, MDS ma narzędzia, które sprawiają, że jest to bardzo łatwe i znacznie mniej uciążliwe.
Dzięki MDS oszczędzamy czas, możemy działać szybciej i jest to o wiele mniej kłopotów. To tak, jakby mieć grupę inteligentnych pomocników, którzy zajmują się trudnymi rzeczami, dzięki czemu możemy skupić się na fajnej części – odkrywaniu tego, co mówią nam dane.
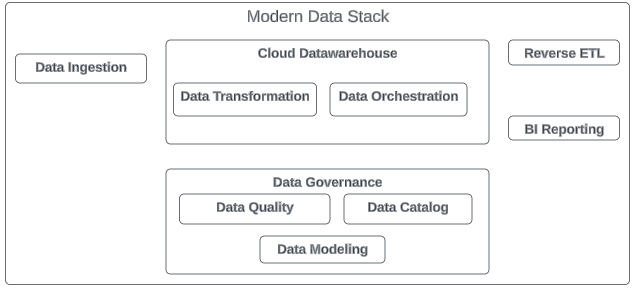
Składniki nowoczesnego stosu danych
MDS składa się z różnych warstw, z których każda posiada wyspecjalizowane narzędzia, które współpracują ze sobą w celu usprawnienia procesów danych.
Pozyskiwanie i integracja danych
Pozyskiwanie i ładowanie danych z różnych źródeł, w tym interfejsów API, baz danych i aplikacji SaaS.
Narzędzia do pozyskiwania danych
fivetran, stitch, airbyte, segment itp.
Przechowywanie danych
Nowoczesne hurtownie danych w chmurze i jeziora danych oferują skalowalne, elastyczne i opłacalne rozwiązania w zakresie przechowywania danych.
Hurtownie danych w chmurze
Google Bigquery, Snowflake, Redshift itp.
Transformacja danych
Narzędzia takie jak dbt (narzędzie do budowania danych) umożliwiają transformację w hurtowni danych przy użyciu prostego języka SQL, usprawniając tradycyjne procesy ETL.
Analiza danych i Business Intelligence
Narzędzia analityczne i Business Intelligence umożliwiają zaawansowaną eksplorację danych, wizualizację i udostępnianie spostrzeżeń w całej organizacji.
Narzędzia Business Intelligence
Tableau, Looker, Power BI, Good Data
Ekstrakcja danych i odwrotne ETL
Umożliwia organizacjom operacjonalizację danych z hurtowni poprzez przeniesienie ich z powrotem do aplikacji biznesowych, napędzając działania na podstawie spostrzeżeń.
Narzędzia odwrotnego ETL
Hightouch, Census
Orkiestracja danych
Platformy, które pomagają zautomatyzować i zarządzać przepływami danych, zapewniając, że właściwe dane są przetwarzane we właściwym czasie.
Narzędzia do orkiestracji
Airflow, Astronomer, Dagster, AWS Step Functions
Zarządzanie danymi i bezpieczeństwo
Zarządzanie danymi koncentruje się na znaczeniu zarządzania dostępem do danych, zapewnieniu zgodności i ochronie danych w ramach MDS. Data Governance zapewnia również kompleksowe zarządzanie dostępem do danych, jakością i zgodnością, oferując jednocześnie zorganizowany spis zasobów danych, który zwiększa wykrywalność i wiarygodność.
Narzędzia do katalogowania danych
Alation (do katalogowania danych), Collibra (do zarządzania i katalogowania), Apache Atlas.
Jakość danych
Zapewnia wiarygodność i dokładność danych poprzez walidację i czyszczenie, dając pewność w podejmowaniu decyzji opartych na danych.
Narzędzia jakości danych: Talend, Monte Carlo, Soda, Anomolo, Great Expectations
Modelowanie danych
Pomaga w łatwym projektowaniu i iteracji schematów baz danych, wspierając zwinne i responsywne praktyki architektury danych.
Narzędzia do modelowania
Erwin, SQLDBM
Wnioski: Przyjęcie MDS ze świadomością kosztów
Modern Data Stack jest całkiem niesamowity; to jak posiadanie szwajcarskiego scyzoryka do obsługi danych. Zdecydowanie przyspiesza pracę i zmniejsza ból głowy. Ale chociaż jest super potężny i daje nam wiele fajnych narzędzi, ważne jest również, aby zwracać uwagę na cenę. Ceny chmury w modelu pay-as-you-go są świetne, ponieważ płacimy tylko za to, czego używamy. Ale, podobnie jak w przypadku rachunku telefonicznego, jeśli nie będziemy ostrożni, te małe rzeczy mogą się sumować. Tak więc, chociaż cieszymy się niesamowitymi funkcjami MDS, powinniśmy również upewnić się, że korzystamy z nich w mądry sposób. W ten sposób możemy oszczędzać czas bez żadnych niespodzianek, jeśli chodzi o koszty.