
Ten artykuł zagłębia się w świat systemów rozproszonych i bada fundamentalną zasadę zwaną twierdzeniem CAP. Systemy rozproszone odgrywają kluczową rolę w wielu nowoczesnych aplikacjach, a Twierdzenie CAP pomaga nam zrozumieć kompromisy nieodłącznie związane z tymi systemami.
Czym są systemy rozproszone?
Systemy rozproszone dystrybuują obliczenia i dane między wieloma połączonymi węzłami w sieci. Może to obejmować odciążenie mocy obliczeniowej lub geograficzne rozproszenie danych w celu ich szybszego dostarczenia. W przeciwieństwie do systemów scentralizowanych, które przechowują dane w jednej lokalizacji, systemy rozproszone rozprowadzają dane w wielu połączonych ze sobą punktach.
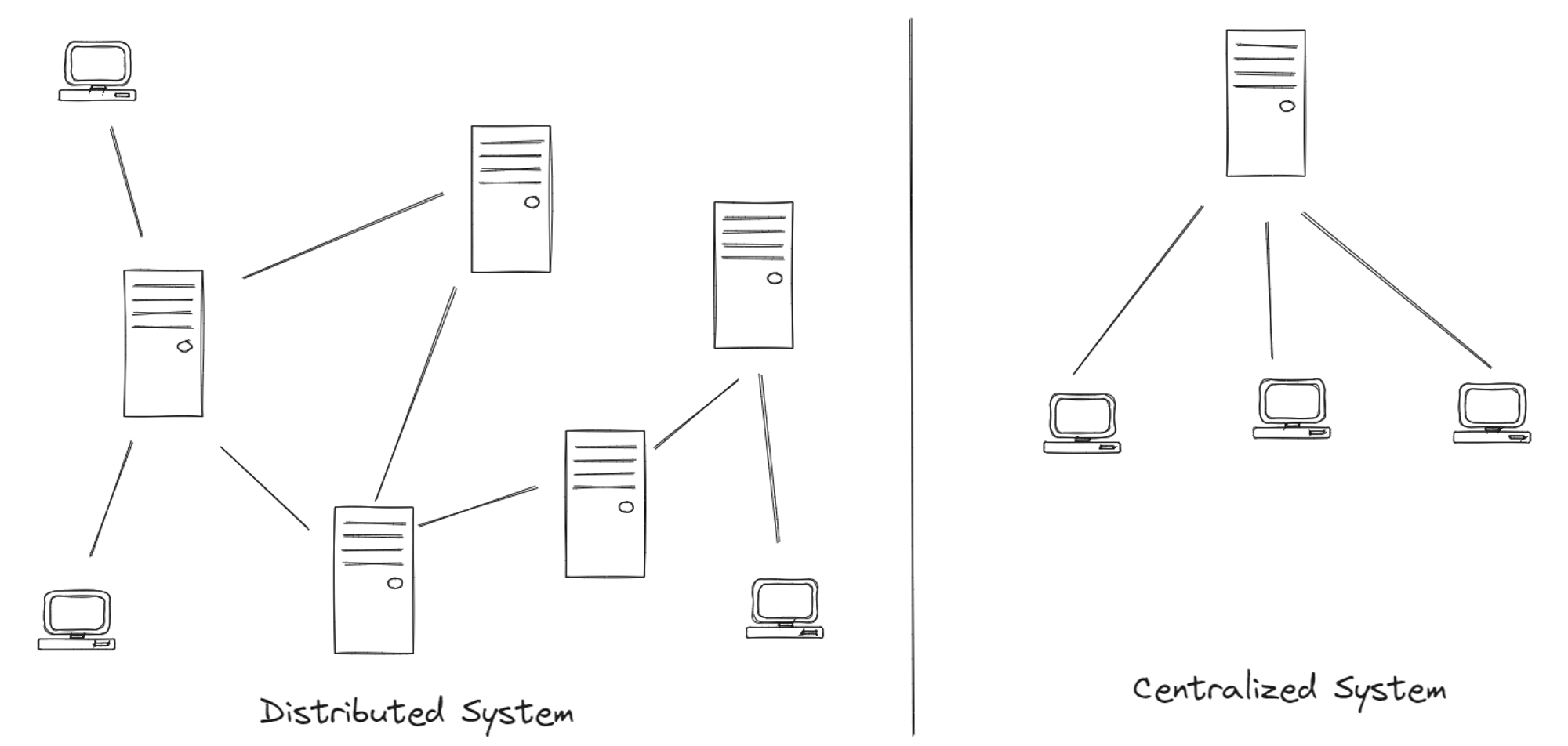
Taka dystrybucja niesie ze sobą własny zestaw wyzwań, z których pierwszym są awarie sieci. Łącza sieciowe mogą ulec uszkodzeniu, tworząc partycje sieciowe, w których cała sieć zostaje podzielona na odizolowane grupy. Każda partycja traci komunikację z pozostałymi. Zdolność systemu do wytrzymania takich partycji nazywana jest tolerancją partycji. Należy zauważyć, że osiągnięcie 100% tolerancji partycji jest praktycznie niemożliwe; wszystkie systemy rozproszone są w pewnym momencie podatne na partycje sieciowe.
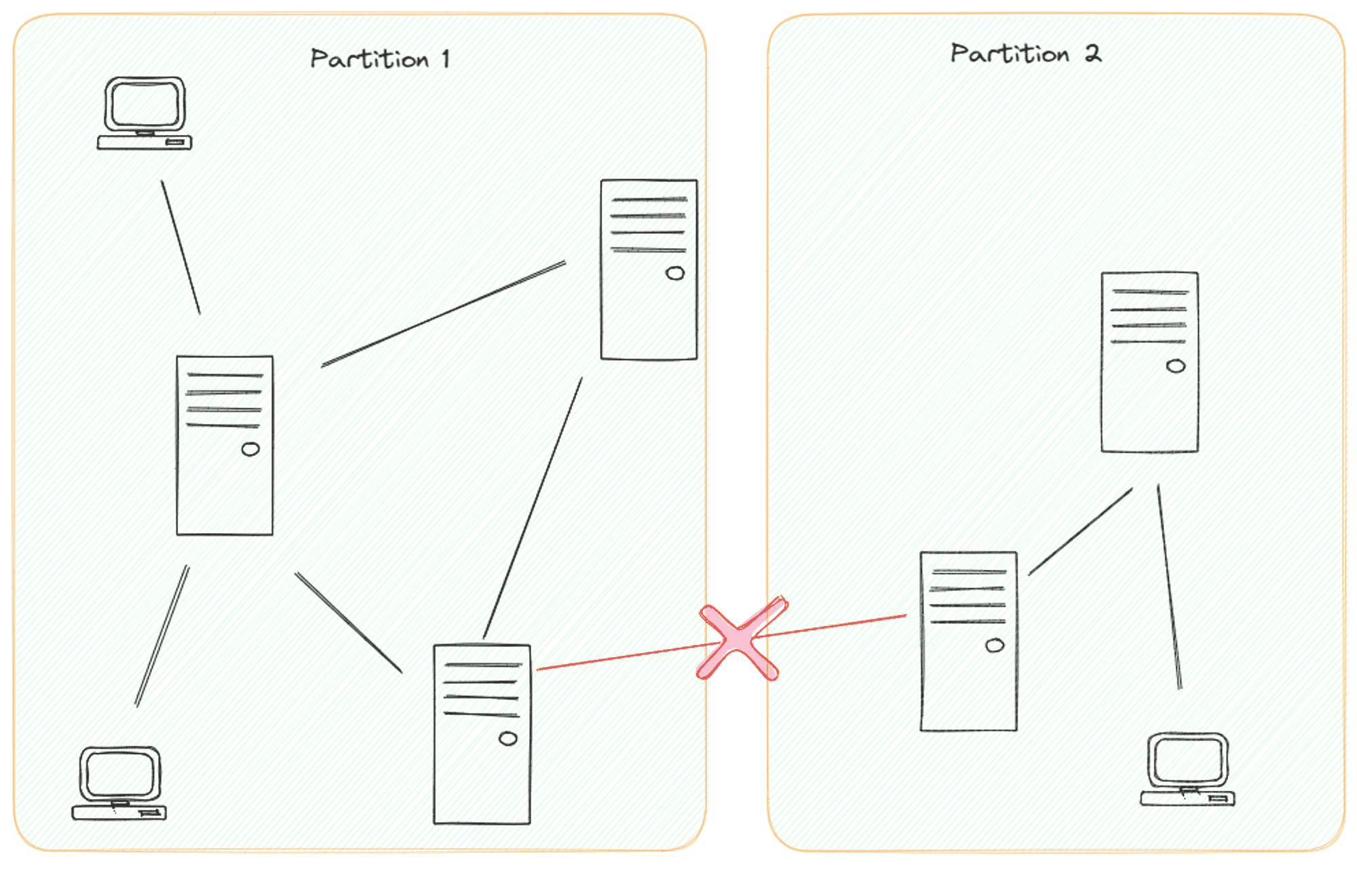
Partycje te, choć tymczasowe, zakłócają komunikację między częściami systemu. Rozważmy platformę mediów społecznościowych, taką jak Instagram lub Facebook. Jeśli wystąpi partycja, nowo opublikowane zdjęcie może nie być widoczne dla użytkowników w innej partycji, dopóki sieć nie odzyska sprawności.
To prowadzi nas do kolejnej kluczowej właściwości systemu rozproszonego. “Spójność“. Zauważyli już Państwo, że jeśli wystąpiły dwie partycje, to dane widziane przez dwie partycje są różne (lub innymi słowy niespójne). Spójność jest miarą tego, czy dane systemowe są poprawne w sieci w danym czasie.
Spójność odgrywa kluczową rolę w aplikacjach finansowych. W przeciwieństwie do postów w mediach społecznościowych, szybkość, z jaką dane są spójne w całym systemie, jest miarą tego, jak spójny jest system. Jeśli tak nie jest, może to spowodować poważne problemy, takie jak problem podwójnego wydatkowania. Jeśli nie znają Państwo problemu podwójnych wydatków, to dotyczy on systemu finansowego, który przechowuje saldo każdej osoby. Załóżmy, że Alicja ma na swoim koncie 100 USD, a wszystkie serwery są zgodne z saldem konta Alicji wynoszącym 100 USD. Alicja kupiła przez Internet zegarki o wartości 90 dolarów na serwerze A. Serwer A zakończył transakcję i wysłał powiadomienie do innych serwerów, aby odliczyć 90 dolarów z konta Alicji. Ale zanim wiadomość się rozpropaguje, następuje nagły podział i serwer B nie otrzymuje transakcji Alicji. Jeśli Alicja zadzwoni na serwer B i wykona kolejną transakcję, serwer nadal uzna, że Alicja ma 100 USD i pozwoli jej je ponownie wydać. Jeśli Alicja kupi torbę za 50 USD od serwera B, transakcja nadal zostanie zrealizowana.
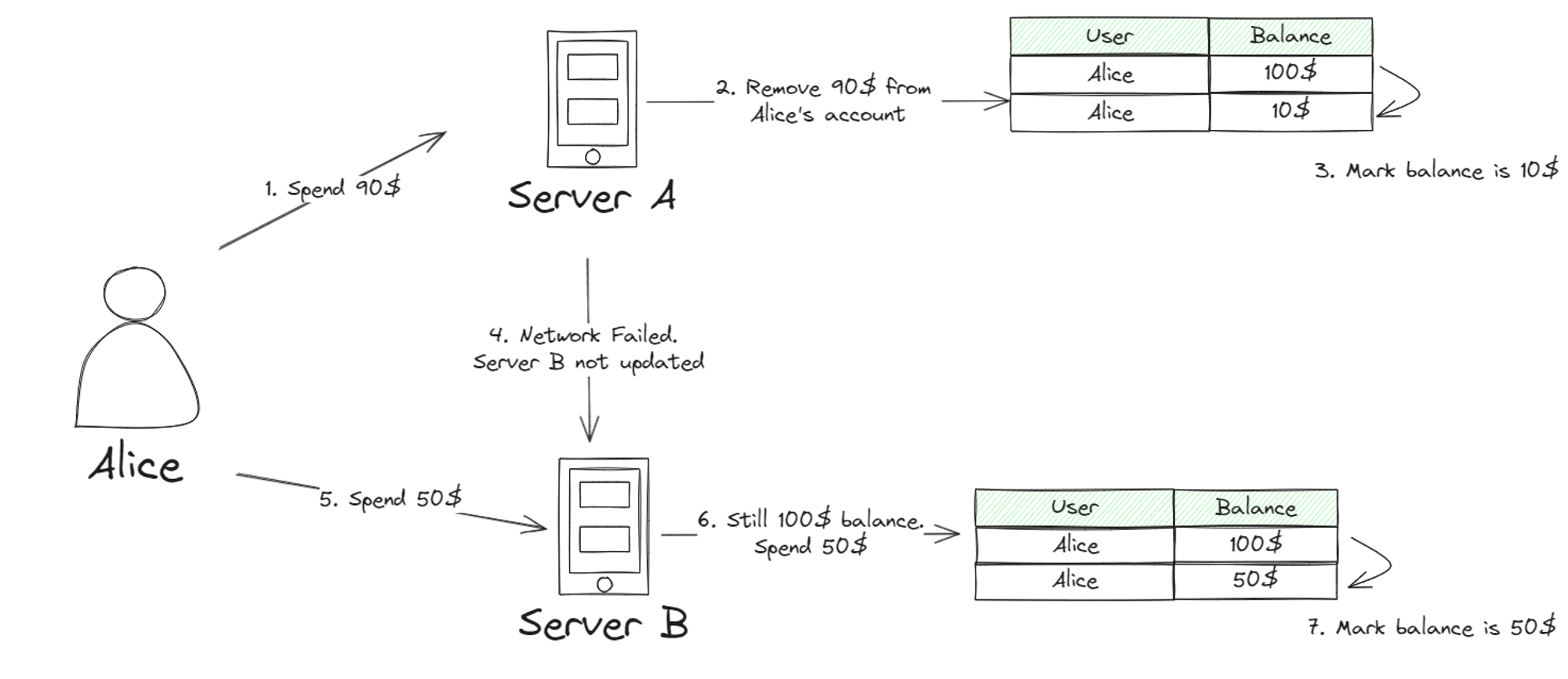
Jak widać, w tego rodzaju systemie finansowym spójność jest ważną kwestią i powinna mieć wyższą spójność. W przeciwieństwie do platform mediów społecznościowych, nie ma znaczenia, jak szybko otrzymają Państwo aktualizację od znajomego. Teraz wiemy, że systemy transakcji finansowych wymagają większej spójności. Ale jak mamy to osiągnąć?
Może istnieć wiele poziomów spójności, ale przeanalizujmy następujące poziomy, które są używane głównie w systemach rozproszonych:
- Liniowość
- Spójność sekwencyjna
- Spójność przyczynowo-skutkowa
- Ostateczna spójność
Linearyzowalność
Linearyzowalność to najwyższy poziom spójności. To spójność algorytm działa poprzez dodanie blokady odczytu dla wszystkich węzłów w systemie, jeśli którekolwiek z danych węzła wymagają aktualizacji. Dodając blokadę odczytu dla wszystkich węzłów, możemy upewnić się, że żaden z węzłów w systemie nie odczyta częściowo zaktualizowanych danych. Blokada jest usuwana, gdy wszystkie dane są w spójnym stanie. Jeśli istnieje partycjonowanie sieci, system potrzebuje więcej czasu, aby osiągnąć spójny stan. Co się stanie, jeśli klient połączy się z węzłem i zażąda odczytu danych, gdy węzeł jest zablokowany? Cóż, klient musi poczekać, aż węzeł zwolni blokadę.
To prowadzi nas do trzeciej ważnej właściwości, Dostępność. Dostępność jest właściwością, gdy klient żąda czegoś od węzła, ten odpowiada. Jeśli węzeł nie jest gotowy do obsłużenia żądania, klient nie otrzyma odpowiedzi lub odpowiedź nie powiedzie się. W przykładzie Linearizability blokujemy węzeł, aby klient nie otrzymał odpowiedzi. Oznacza to, że dopóki dane nie staną się spójne, węzły nie będą dostępne. Możemy wywnioskować, że jeśli spójność jest wyższa, nie możemy osiągnąć wyższej dostępności.
Spójność sekwencyjna
W przeciwieństwie do liniowości, spójność sekwencyjna jest zrelaksowanym modelem spójności. Zamiast blokować wszystkie węzły dla wszystkich aktualizacji danych, spójność sekwencyjna blokuje węzły w porządku chronologicznym. Proszę pomyśleć o aplikacji do czatu. Kiedy dwie osoby rozmawiają na czacie, wiadomości obu osób powinny być w odpowiedniej kolejności chronologicznej. W przeciwnym razie zrozumienie tego stałoby się kłopotliwe. Zrozummy to na przykładzie.
Alice musi wysłać wiadomość do grupy czatu i wysyła ją do systemu. Zakładając, że system nie ma partycji, jej wiadomość rozchodzi się do wszystkich węzłów. Teraz Bob również musi wysłać wiadomość do grupy, ale nastąpiła partycja sieci i niektóre węzły nie zostały zaktualizowane wiadomością Boba. Teraz, jeśli Alicja wyśle kolejną wiadomość w tym podzielonym systemie, niektóre węzły nadal nie zostaną zaktualizowane poprzednią wiadomością Boba. Jeśli węzeł nie zaktualizuje wiadomości Boba i doda tylko wiadomość Alicji, czat stanie się bałaganem. W tym scenariuszu sekwencyjnie spójny system nakłada blokadę zapisu na węzeł, gdzie tylko on może zapisać węzeł, jeśli wszystkie wcześniej opublikowane dane zostały już dodane. Dopóki węzeł nie zostanie zaktualizowany o poprzednie dane, musi czekać, aż wcześniej wysłane wiadomości dotrą do węzła.
W tym trybie spójności rozważamy tylko sekwencyjną spójność danych każdego węzła. Tutaj widać, że węzły są dostępne niż w modelu liniowości, w którym blokada zapisu jest stosowana do momentu rozwiązania kolejności zdarzeń. Klient nadal może uzyskać odpowiedź z danego węzła w systemie podzielonym na partycje, ale do ostatnich danych w prawidłowej kolejności sekwencyjnej.
Spójność przyczynowa
Spójność przyczynowa jest znacznie bardziej zrelaksowanym modelem spójności, który nie dba również o porządek. Spójność przyczynowo-skutkowa uwzględnia jedynie relacje między danymi. Na przykład, proszę pomyśleć o platformie mediów społecznościowych, na której można publikować zdjęcia i umieszczać komentarze. Alice publikuje zdjęcie na platformie, a w tym samym czasie Bob również publikuje zdjęcie na platformie. Te dwa posty nie mają żadnego związku. Kolejność postów nie ma wpływu na trzecią osobę Charliego oglądającą oba zdjęcia. Dla każdego zdjęcia istnieje jednak sekcja komentarzy. Kiedy Charlie widzi komentarze do zdjęć, komentarze te powinny być w porządku chronologicznym, aby mógł je zrozumieć. Komentarze w tym systemie są spójne przyczynowo. Oznacza to, że kolejność ma znaczenie w niektórych przypadkach, ale nie we wszystkich scenariuszach. Jeśli istnieją niepowiązane jednostki (takie jak posty), które mają bardziej zrelaksowaną spójność, podczas gdy komentarze są zależne od powiązanych z nimi postów.
Ostateczna spójność
Teraz możemy zrozumieć Ostateczna spójność łatwo. Proszę pomyśleć o tej samej platformie mediów społecznościowych bez funkcji komentowania. Teraz Alice i Bob publikują zdjęcia, a Charlie może zobaczyć ich posty na swoim kanale. Nie ma znaczenia, w jakiej kolejności otrzymał dane.
To prowadzi nas do zastanowienia się nad kolejnym ważnym faktem dotyczącym dostępności. Na poziomie spójności linearyzowalnej nie mogliśmy osiągnąć wyższej dostępności z powodu blokad. Ale w Eventual Consistency nie musimy mieć żadnych blokad. Dlatego węzły serwera są dostępne przez cały czas.
O co chodzi w twierdzeniu CAP?
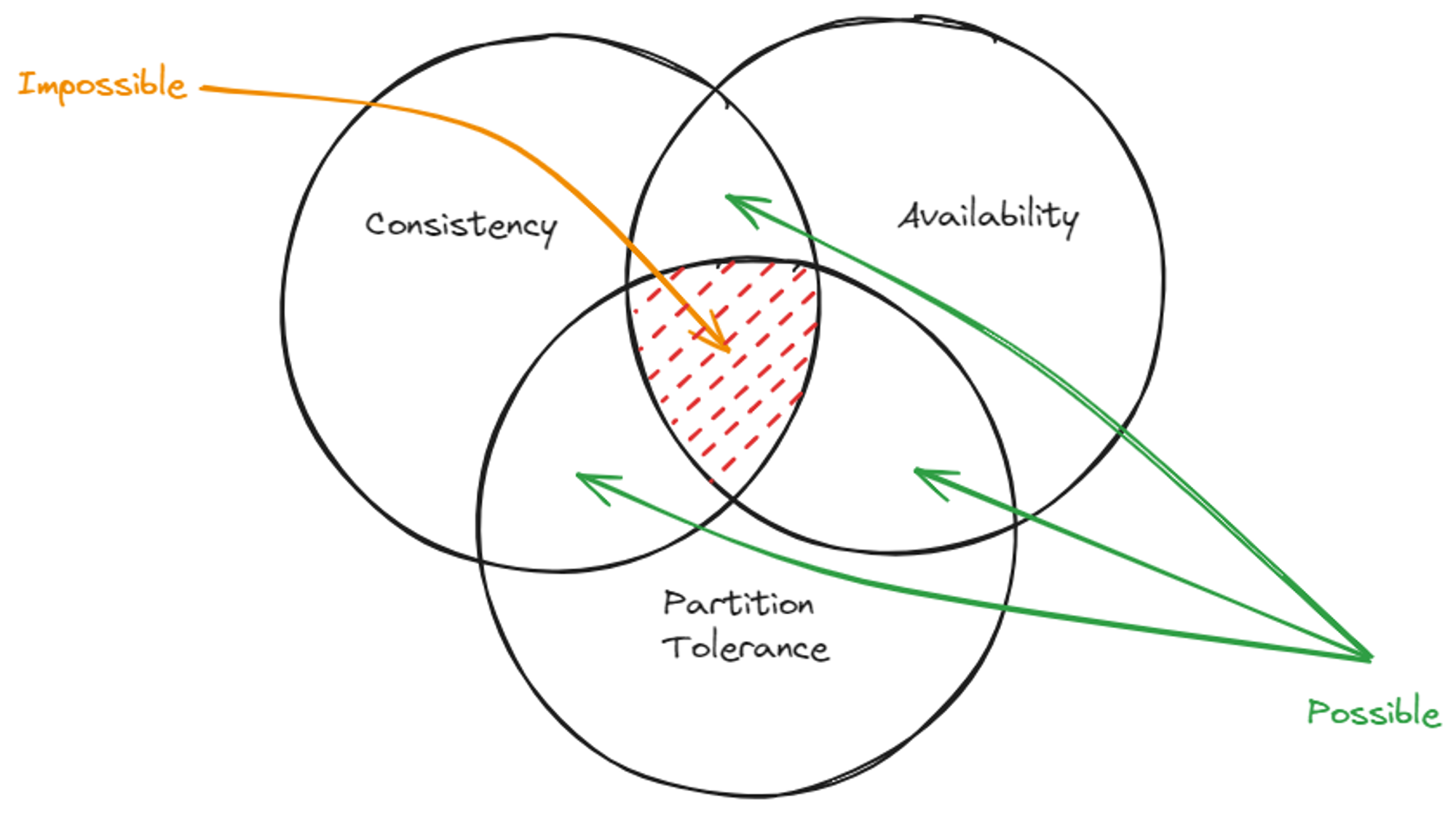
Teraz odkryliśmy wszystkie elementy twierdzenia CAP i nadszedł czas, aby dokończyć układankę. Omówiliśmy trzy właściwości systemu rozproszonego. Są to Tolerancja partycji mówi nam, że system może tolerować partycjonowanie, The Spójność który utrzymuje spójność danych w systemie rozproszonym, oraz Dostępność która zapewnia, że system zawsze odpowiada na żądania klientów. Twierdzenie CAP mówi, że możemy wybrać tylko dwie z tych właściwości spośród trzech. Przyjrzyjmy się wszystkim trzem przypadkom.
Proszę wybrać tolerancję partycji i spójność ponad dostępność
Jest to scenariusz, w którym zezwalamy systemowi na posiadanie partycji. Musimy jednak zachować spójność systemu. Omówiony przez nas scenariusz transakcji finansowych należy do tej kategorii. Aby zachować spójność, musimy zablokować węzły, dopóki dane nie staną się spójne w systemie. Dopiero wtedy można je odczytać z systemu. Dlatego dostępność jest ograniczona.
Proszę wybrać tolerancję partycji i dostępność ponad spójność
Jest to scenariusz, w którym nie potrzebujemy ścisłej spójności w systemie. Proszę przypomnieć sobie system mediów społecznościowych omówiony w ewentualnej spójności. Nie potrzebujemy spójnych danych, ale raczej danych w dowolnej kolejności. Mając zrelaksowany poziom spójności, nie musimy blokować węzłów, a węzły są zawsze dostępne.
Dostępność i spójność przy tolerancji partycji
Ten rodzaj systemu jest raczej systemem scentralizowanym niż rozproszonym. Nie możemy zbudować systemu bez partycjonowania sieci. Jeśli zapewnimy dostępność i spójność w tym samym czasie, nie może być żadnych partycji. Oznacza to, że jest to system scentralizowany. Dlatego w systemach rozproszonych nie omawiamy zarówno systemów dostępnych, jak i spójnych.
Przykładowe przypadki użycia dla twierdzenia CAP
Teraz wiedzą już Państwo, czym jest twierdzenie CAP. Zobaczmy kilka przykładowych narzędzi używanych we wszystkich trzech powyższych przypadkach.
Tolerancja partycji i spójny system
Redis i MongoDB to popularne rozwiązania bazodanowe dla CP (systemów spójnych i tolerujących partycje). Te bazy danych są zbudowane do pracy jako rozproszone bazy danych i pozwalają na partycje. Nawet jeśli istnieją partycje, pozwala to mieć spójne dane we wszystkich połączonych bazach danych.
Tolerancja partycji i dostępny system
Ten system nie dba zbytnio o spójność systemu. Raczej dba o responsywność i szybsze działanie. Obejmuje to bazy danych, takie jak Cassandra i CouchDB. Te bazy danych zostały stworzone do pracy w środowiskach rozproszonych i szybszego działania.
Spójny i dostępny system
Ten typ systemu nie ma być rozproszony, ale raczej scentralizowany. Bazy danych, takie jak SQLite i H2, są zbudowane tak, aby działały na jednym węźle. Te bazy danych są zawsze spójne i dostępne, ponieważ nie muszą blokować węzłów i jest to jedyny węzeł. Ale nie można ich mieć w systemie rozproszonym, ponieważ nie tolerują partycjonowania.
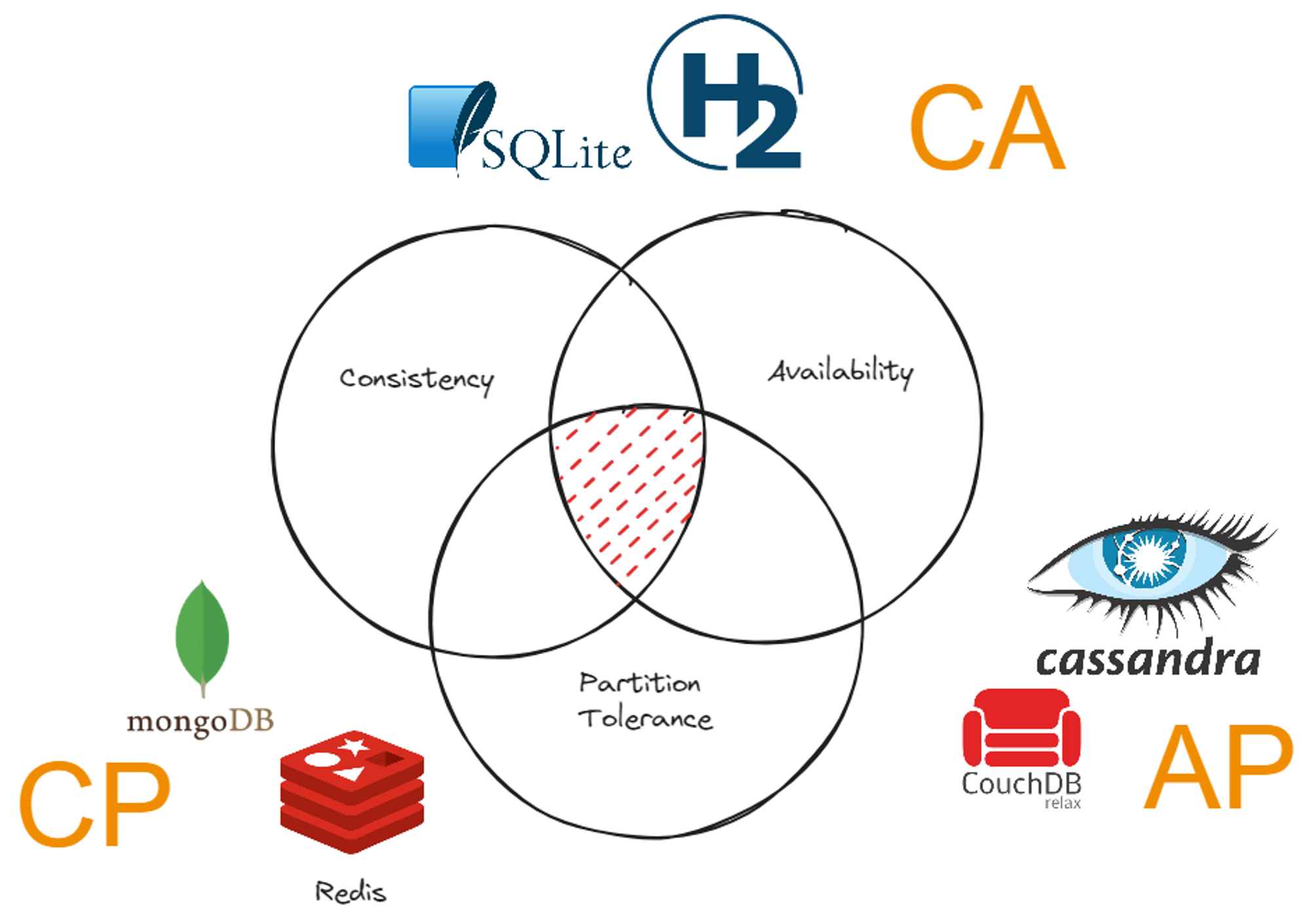 Dlaczego MYSQL nie jest wymieniony na żadnej z tych list? Cóż, MySQL jest ogólnie uważany za system CA zaprojektowany w celu zapewnienia dobrej spójności i dostępności przy jednoczesnym poświęceniu tolerancji partycji. Powodem tego jest to, że MYSQL działa w trybie master-slave, gdzie master jest węzłem, do którego klient ma dostęp. Dlatego nie jest to prawdziwy system rozproszony, o którym mówimy. Ale przy różnych konfiguracjach nadal można go używać jako systemu CP.
Dlaczego MYSQL nie jest wymieniony na żadnej z tych list? Cóż, MySQL jest ogólnie uważany za system CA zaprojektowany w celu zapewnienia dobrej spójności i dostępności przy jednoczesnym poświęceniu tolerancji partycji. Powodem tego jest to, że MYSQL działa w trybie master-slave, gdzie master jest węzłem, do którego klient ma dostęp. Dlatego nie jest to prawdziwy system rozproszony, o którym mówimy. Ale przy różnych konfiguracjach nadal można go używać jako systemu CP.
Jak widać, twierdzenie CAP nakłada ograniczenia na systemy rozproszone. Jako projektanci i twórcy systemów musimy wybrać, które właściwości mają być priorytetowe: spójność, dostępność czy tolerancja partycji. Wybrany model spójności określi, czy priorytetowo traktujemy wysoką dostępność, czy też poświęcamy część dostępności w celu zapewnienia spójności. Istnieje wiele narzędzi, które pomogą Państwu zaprojektować aplikację w oparciu o te kompromisy. Proszę wybierać mądrze! Następnym razem, gdy zetkną się Państwo z systemem rozproszonym, proszę wziąć pod uwagę te trzy kluczowe właściwości.