
Dla firmy takiej jak Uber, dane w czasie rzeczywistym są siłą napędową zarówno usług skierowanych do klientów, jak i usług wewnętrznych. Klienci polegają na danych w czasie rzeczywistym, aby uzyskać przejazdy i zamówić jedzenie w dogodnym dla siebie czasie. Zespoły wewnętrzne również polegają na aktualnych danych, aby zasilać infrastrukturę stojącą za ich aplikacjami skierowanymi do klientów, takimi jak wewnętrzne narzędzie monitorujące analitykę awarii aplikacji mobilnych.
Firma Uber przeprowadziła migrację do Apache Pinot, aby zasilić to wewnętrzne narzędzie i doświadczyła znacznej poprawy w porównaniu z poprzednim silnikiem analitycznym (Elasticsearch). Przechodząc na Pinot, prawdziwą platformę analityczną działającą w czasie rzeczywistym, firma Uber dostrzegła korzyści obejmujące:
- 70% redukcja kosztów infrastruktury (oszczędność ponad 2 mln USD rocznie)
- 80% redukcja liczby rdzeni CPU
- 66% redukcja śladu danych
- Skrócenie czasu ładowania strony o 64% (z 14 sekund do poniżej 5 sekund)
- Zmniejszone opóźnienie wczytywania do <10 milisekund
- Spadek limitów czasu zapytań i wyeliminowanie problemu utraty danych

Proszę obejrzeć teraz
Treść tego bloga opiera się na osobistym spotkaniu, na którym przedstawiono historie użytkowników Apache Pinot. Odnosimy się również do blogu zespołu inżynierów Ubera który opisuje, w jaki sposób używają Pinot do analizy w czasie rzeczywistym awarii aplikacji mobilnych. Proszę obejrzeć spotkanie tutaj:
Proszę czytać dalej, aby dowiedzieć się, w jaki sposób firma Uber osiągnęła te wyniki dzięki Apache Pinot.
Jak Uber dostarcza analizy w czasie rzeczywistym dotyczące awarii aplikacji mobilnych
Uber posiada zautomatyzowany potok pozyskiwania danych, który śledzi awarie aplikacji i gromadzi dane dochodzeniowe. Niektóre z tych danych są przekazywane do Apache Flink w celu transformacji, a następnie umieszczane z powrotem w tematach Kafka w celu dalszej konsumpcji. Te nieprzetworzone i przetworzone zdarzenia w Kafce są następnie konsumowane przez Apache Pinot, który następnie uruchamia zapytania analityczne, których wyniki są dostarczane użytkownikom wewnętrznym za pośrednictwem Grafany i wewnętrznych narzędzi wizualizacyjnych. Ich potok pobiera zarówno dane w czasie rzeczywistym, jak i offline (nie przedstawiono), aby stworzyć pełny widok użytkowników, znany jako tabele hybrydowe w Apache Pinot.
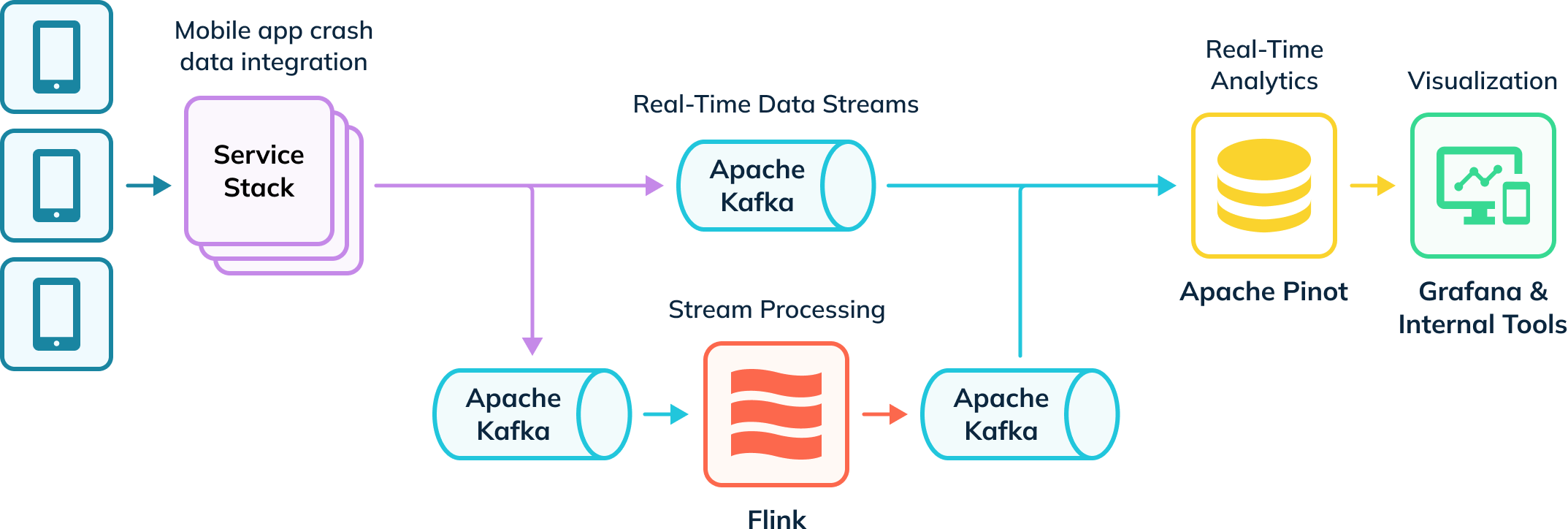
Analiza awarii aplikacji w czasie rzeczywistym za pomocą Apache Pinot
Firma Uber co tydzień wprowadza około 11 000 nowych zmian w kodzie i infrastrukturze, a także polega na wewnętrznym narzędziu (Healthline), które pomaga wykrywać i rozwiązywać problemy z awariami. Healthline pozwala Uberowi lepiej mierzyć i osiągać średni czas do wykrycia (MTTD). Na przykład, firma może wprowadzić nową funkcję, która powoduje nieoczekiwane awarie aplikacji i musi być w stanie szybko zlokalizować źródło awarii, zagłębiając się w dane dotyczące awarii.
Poniższy pulpit nawigacyjny przedstawia tygodniowe dane o awariach dla jednej aplikacji mobilnej i jednej wersji systemu operacyjnego. W tym przykładzie zdarzenia sesji występują do setek tysięcy razy na sekundę, a awarie mierzą od 15 000 do 20 000 zdarzeń na sekundę. Uber łączy te wskaźniki, aby obliczyć wskaźnik bezawaryjności, który wskazuje na kondycję aplikacji (celem jest osiągnięcie jak najbliżej 100%).
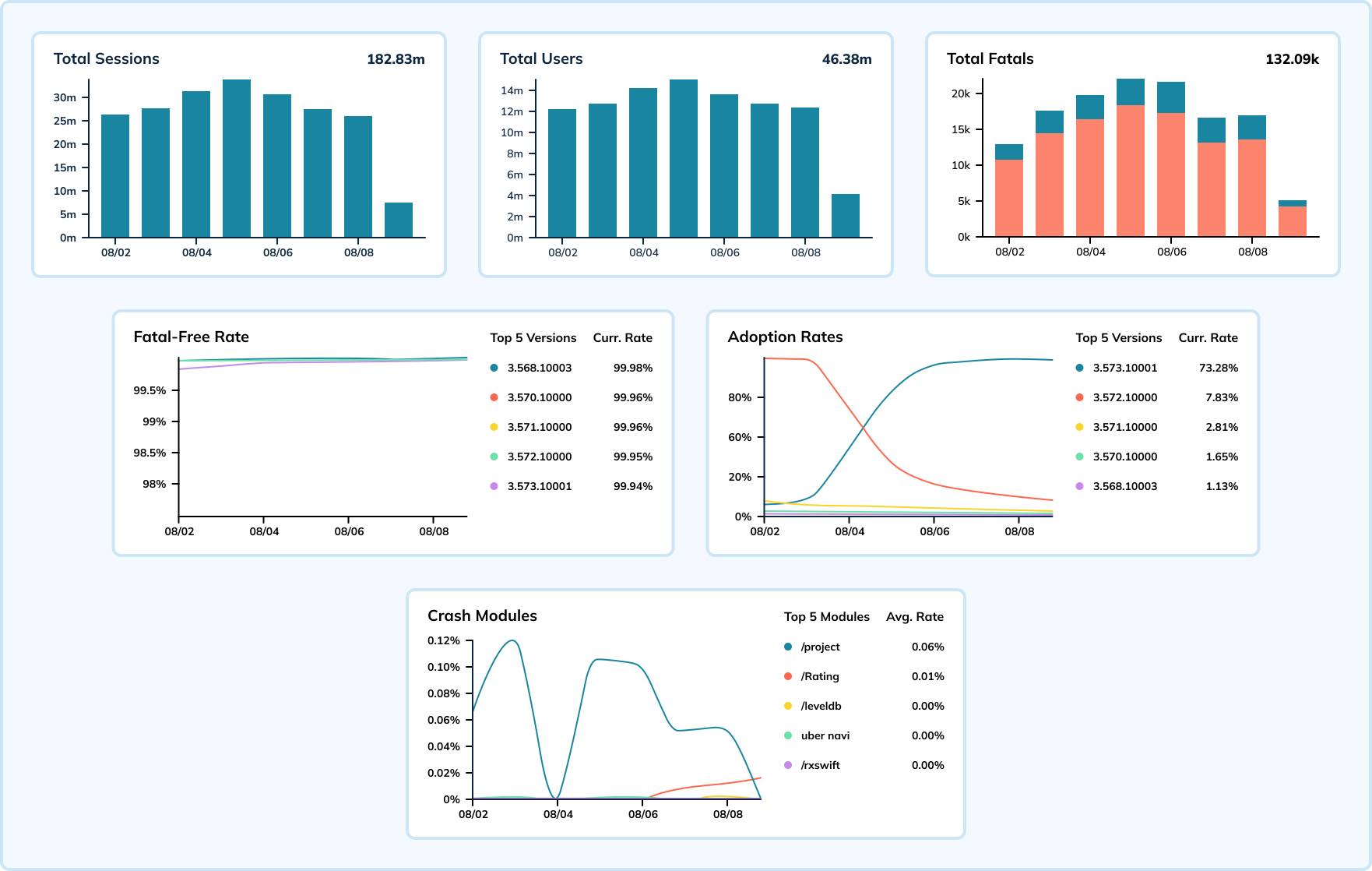
W przypadku Elasticsearch, wyszukiwarki ogólnego przeznaczenia, skoki częstotliwości awarii powodowały opóźnienia w pozyskiwaniu danych i opóźniały reakcję zespołu na identyfikację problemów. Dzięki przejściu na Apache Pinot, który został zaprojektowany specjalnie do analizy w czasie rzeczywistym na masową skalę, zespół zaobserwował spadek liczby i dotkliwości opóźnień w pozyskiwaniu danych.
Szczegółowa analiza danych o wypadkach
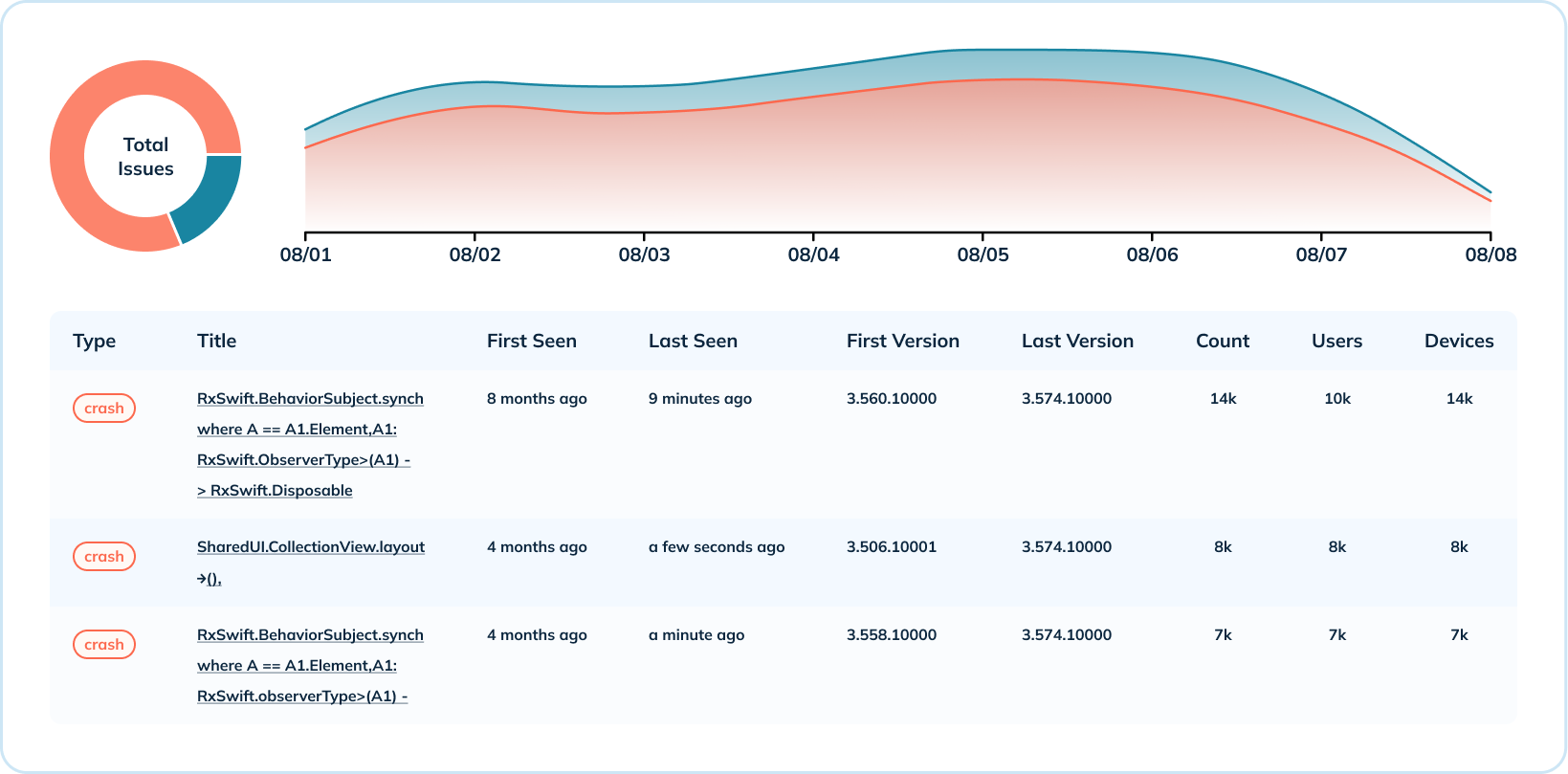
Oprócz ogólnego przeglądu danych dotyczących awarii, Uber zapewnia również dogłębną analizę na poziomie awarii. Agregują one metryki awarii w różnych wymiarach, takich jak liczba awarii na system operacyjny i na wersję oraz rozkład awarii na wersję. Ten przypadek użycia wykorzystuje kilka indeksów Pinot (zakres, odwrócony i tekst), aby udostępniać informacje o wystąpieniu danego typu awarii, wersjach, liczbie wystąpień oraz liczbie dotkniętych użytkowników i urządzeń.
W przypadku dogłębnej analizy krytyczne było, aby Uber miał możliwości wyszukiwania tekstowego w celu odczytywania komunikatów o błędach awarii. Indeks tekstowy Pinot jest zbudowany w oparciu o Lucene i daje możliwość wyszukiwania awarii według komunikatu o awarii, nazwy klasy, śladu przebiegu i innych.
Pomiar sesji na dużą skalę
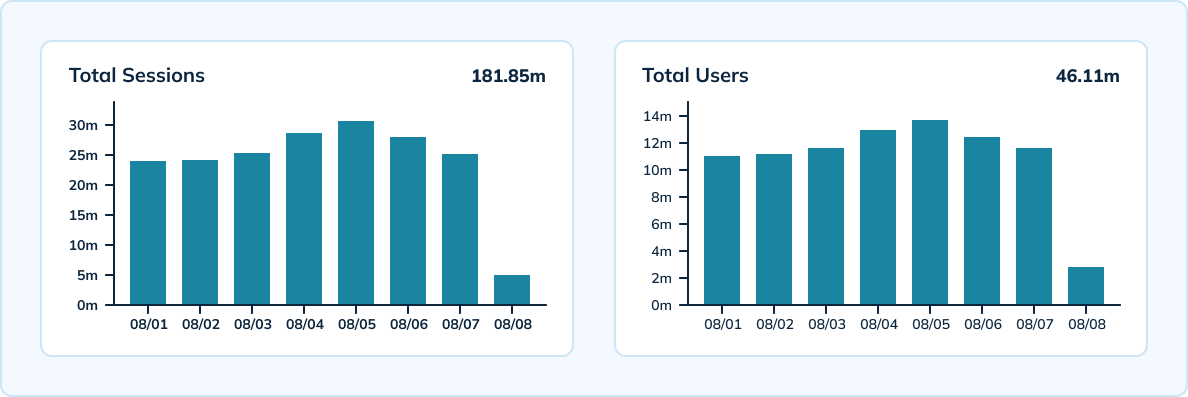
Uber wykorzystuje również Pinot do pomiaru unikalnych sesji według urządzenia, wersji, systemu operacyjnego i godziny na dużą skalę. Pinot oferuje przetwarzanie w czasie rzeczywistym z wysoką przepustowością zdolną do przyjmowania 300 000 zdarzeń analitycznych Ubera na sekundę. Zespół ma hybrydową konfigurację, która obejmuje tabelę czasu rzeczywistego z 10-minutową szczegółowością i 3-dniową retencją danych, a także tabelę offline z godzinową i dzienną szczegółowością oraz 45-dniową retencją danych.
Wykorzystanie HyperLogLog Apache Pinot pozwoliło zespołowi zmniejszyć liczbę przechowywanych zdarzeń i wykonać mniej unikalnych agregacji między zdarzeniami. Pinot zapewnił również bardzo niskie opóźnienia – poniżej 100 milisekund dla opóźnienia p99.5.
Oszczędności kosztów infrastruktury
Według obliczeń firmy Uber, migracja do Pinot pozwoliła jej zaoszczędzić ponad 2 miliony dolarów na rocznych kosztach infrastruktury. Konfiguracja Pinot doprowadziła do 70% spadku kosztów infrastruktury w porównaniu do Elasticsearch. Zaobserwowano również 80% redukcję liczby rdzeni procesora i 66% zmniejszenie śladu danych.

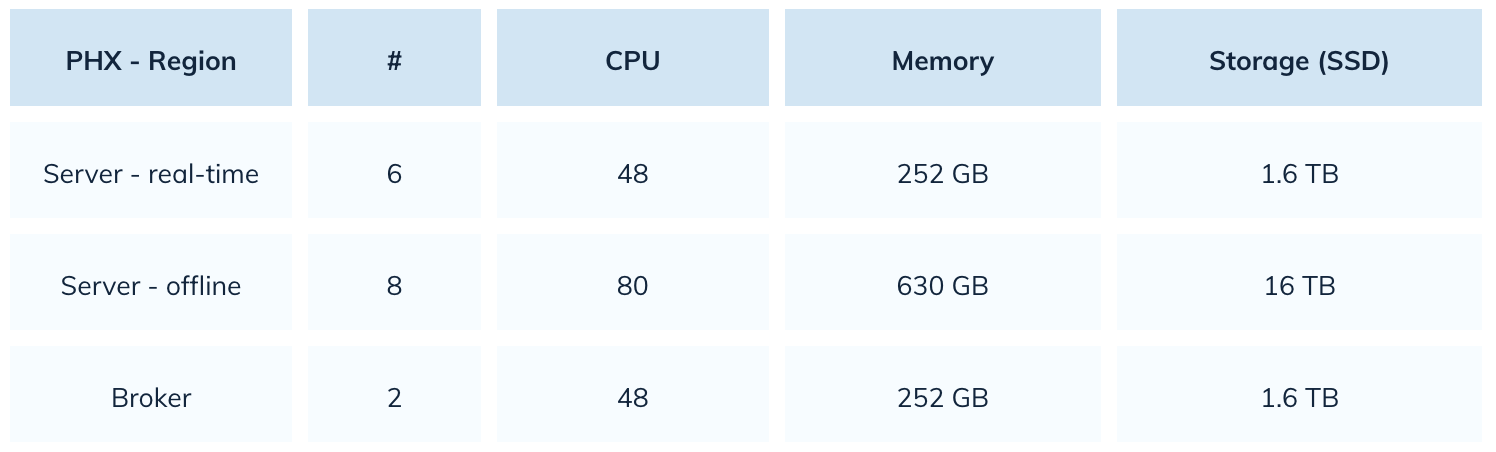
Dzięki Elasticsearch, Uber wykorzystywał 22 000 rdzeni procesora. Dzięki Pinot liczba ta zmniejszyła się o 80%. Oto migawka ich konfiguracji Pinot:
Ulepszona wydajność zapytań i wrażenia użytkownika
Dzięki Apache Pinot, Uber jest w stanie zapewnić lepsze wrażenia użytkownika dzięki szybszemu ładowaniu stron i zwiększonej niezawodności. Migracja do Pinot skróciła czas ładowania strony o 64%, z 14 sekund do poniżej 5 sekund. Pinot ma również lepszą tolerancję na skoki obciążenia, co prowadzi do szybszego odzyskiwania opóźnień. Nawet jeśli zespół zauważy opóźnienie w pozyskiwaniu, Pinot jest w stanie szybko wrócić do normy w ciągu kilku minut.
W porównaniu do Elasticsearch, Pinot wykazał również znaczną poprawę w zakresie limitów czasu zapytań i utraty danych. W przypadku awarii aplikacji mobilnej podczas korzystania z Elasticsearch, zapytania dotyczące tego indeksu kończyły się po czasie. Uber rozwiązał ten problem za pomocą Pinot, kontrolując rozmiar segmentu. Zespół nie ma również problemów z utratą danych w Pinot, w porównaniu do częstych problemów z danymi, gdy Elasticsearch radził sobie ze zwiększoną przepustowością pozyskiwania.
Kolejna iteracja konfiguracji Pinot firmy Uber
W następnej kolejności Uber planuje migrację do natywnego indeksowania tekstu dla swoich mobilnych danych o wypadkach. Ich mobilne dane o wypadkach zawierają wiele ustrukturyzowanych danych, dzięki czemu zespół może migrować wszystkie swoje przypadki użycia do natywnych indeksów tekstowych. Przejście to zapewni oszczędność kosztów związanych z przechowywaniem danych i skróci czas wyszukiwania danych.
Uber nie jest jedyną organizacją odnoszącą sukcesy dzięki migracji z Elasticsearch do Pinot
Uniqode (dawniej Beaconstac) odnotował 10-krotną poprawę ogólnej wydajności zapytań po przejściu z Elasticsearch na Pinot. Firma Cisco Webex również przeniosła swoją analitykę i obserwowalność w czasie rzeczywistym do Pinot po napotkaniu dużych opóźnień. Zespół Webex odkrył, że Apache Pinot zapewnia od 5x do 150x niższe opóźnienia niż Elasticsearch.