
Przechwytywanie danych o zmianach (CDC) to szeroko przyjęty wzorzec przenoszenia danych między systemami. Podczas gdy podstawowa zasada działa dobrze w małych przypadkach użycia pojedynczej tabeli, sprawy komplikują się, gdy musimy wziąć pod uwagę spójność, gdy informacje obejmują wiele tabel. W takich przypadkach tworzenie wielu przepływów 1-1 CDC nie wystarczy, aby zagwarantować spójny widok danych w bazie danych, ponieważ każda tabela jest śledzona osobno. Dopasowanie danych do granic transakcji staje się trudnym i podatnym na błędy problemem do rozwiązania, gdy dane opuszczą bazę danych.
Ten samouczek pokazuje, jak korzystać z PostgreSQL dekodowanie logiczne, wzorzec outbox i Debezium w celu propagacji spójnego widoku zbioru danych obejmującego wiele tabel.
Przypadek użycia: Sklep internetowy oparty na PostgreSQL
Relacyjne bazy danych są oparte na jednostka-relacja model, w którym encje są przechowywane w tabelach, a każda tabela ma klucz zapewniający unikalność. Relacje mają postać kluczy obcych, które umożliwiają łączenie informacji z różnych tabel.
Praktycznym przykładem jest poniższy przykład z trzema encjami users, products, orders, oraz order lines oraz relacje między nimi.
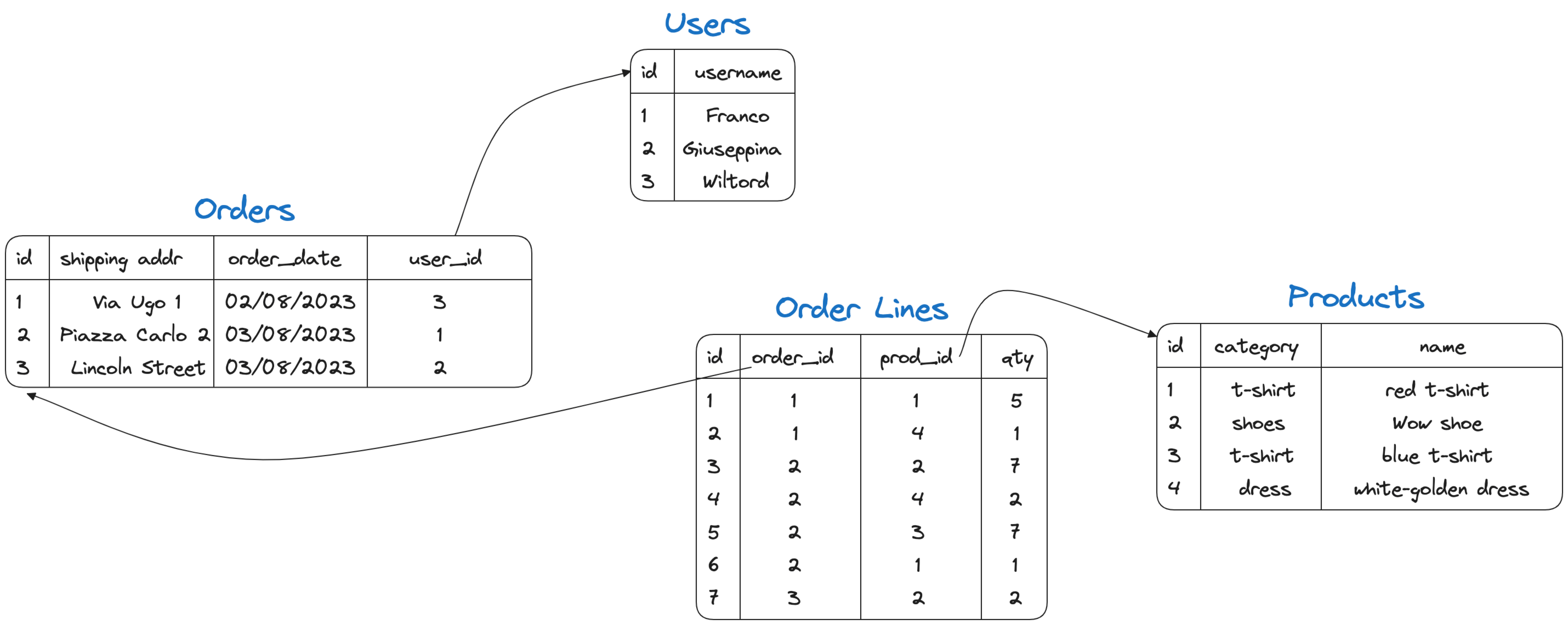
Na powyższym rysunku orders zawiera klucz obcy do users (użytkownik składający zamówienie), a tabela order lines zawiera klucze obce do orders i products co pozwala nam zrozumieć, do którego zamówienia należy dana linia i jakie produkty obejmuje.
Możemy odtworzyć powyższą sytuację poprzez zakładając konto Aiven i uzyskując dostęp do konsoli, a następnie utworzenie nowej usługi Aiven dla bazy danych PostgreSQL. Gdy usługa jest uruchomiona, możemy pobrać identyfikator URI połączenia z zakładki Overview na stronie konsoli usługi.
Po uzyskaniu identyfikatora URI połączenia, connect with psql i proszę uruchomić następujące polecenie:
CREATE TABLE USERS (ID SERIAL PRIMARY KEY, USERNAME TEXT);
INSERT INTO USERS (USERNAME) VALUES ('Franco'),('Giuseppina'),('Wiltord');
CREATE TABLE ORDERS (
ID SERIAL PRIMARY KEY,
SHIPPING_ADDR TEXT,
ORDER_DATE DATE,
USER_ID INT,
CONSTRAINT FK_USER
FOREIGN KEY(USER_ID)
REFERENCES USERS(ID)
);
INSERT INTO ORDERS (SHIPPING_ADDR, ORDER_DATE, USER_ID) VALUES
('Via Ugo 1', '02/08/2023',3),
('Piazza Carlo 2', '03/08/2023',1),
('Lincoln Street', '03/08/2023',2);
CREATE TABLE PRODUCTS (
ID SERIAL PRIMARY KEY,
CATEGORY TEXT,
NAME TEXT,
PRICE INT
);
INSERT INTO PRODUCTS (CATEGORY, NAME, PRICE) VALUES
('t-shirt', 'red t-shirt',5),
('shoes', 'Wow shoe',35),
('t-shirt', 'blue t-shirt',15),
('dress', 'white-golden dress',50);
CREATE TABLE ORDER_LINES (
ID SERIAL PRIMARY KEY,
ORDER_ID INT,
PROD_ID INT,
QTY INT,
CONSTRAINT FK_ORDER
FOREIGN KEY(ORDER_ID)
REFERENCES ORDERS(ID),
CONSTRAINT FK_PRODUCT
FOREIGN KEY(PROD_ID)
REFERENCES PRODUCTS(ID)
);
INSERT INTO ORDER_LINES (ORDER_ID, PROD_ID, QTY) VALUES
(1,1,5),
(1,4,1),
(2,2,7),
(2,4,2),
(2,3,7),
(2,1,1),
(3,2,2);Uruchom przepływ przechwytywania danych zmian za pomocą konektora Debezium
Teraz, jeśli chcemy wysłać zdarzenie do Apache Kafka® za każdym razem, gdy pojawi się nowe zamówienie, możemy zdefiniować plik Debezium CDC connector który zawiera wszystkie cztery tabele zdefiniowane powyżej.
Aby to zrobić, proszę przejść do Konsola Aiven i utworzyć nową usługę Aiven for Apache Kafka® (w tym przykładzie potrzebujemy przynajmniej biznesplanu). Następnie proszę włączyć Kafka Connect na stronie przeglądu usługi. Proszę przejść do dolnej części tej samej strony; możemy włączyć opcję kafka.auto_create_topics_enable w sekcji Parametr zaawansowany dla naszych celów testowych. Na koniec, gdy usługa jest uruchomiona, proszę utworzyć plik Debezium CDC connector z następującą definicją JSON:
{
"name": "mysourcedebezium",
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "<HOSTNAME>",
"database.port": "<PORT>",
"database.user": "avnadmin",
"database.password": "<PASSWORD>",
"database.dbname": "defaultdb",
"database.server.name": "mydebprefix",
"plugin.name": "pgoutput",
"slot.name": "mydeb_slot",
"publication.name": "mydeb_pub",
"publication.autocreate.mode": "filtered",
"table.include.list": "public.users,public.products,public.orders,public.order_lines"
}Gdzie:
database.hostname,database.port,database.passwordwskazują na parametry połączenia Aiven dla PostgreSQL, które można znaleźć w zakładce przeglądu usług Aiven Consoledatabase.server.namejest prefiksem dla nazw tematów w Aiven dla Apache Kafkaplugin.nameto używana nazwa wtyczki PostgreSQLpgoutputslot.nameorazpublication.nameto nazwa gniazda replikacji i publikacji w PostgreSQL"publication.autocreate.mode": "filtered"pozwala nam utworzyć publikację tylko dla tabel w zakresietable.include.listzawiera listę tabel, dla których chcemy włączyć CDC
Konektor utworzy cztery tematy (po jednym na tabelę) i będzie śledził zmiany osobno dla każdej tabeli.
W Aiven dla Apache Kafka powinniśmy zobaczyć cztery różne tematy o nazwach <prefix>.<schema_name>.<table_name> gdzie:
<prefix>pasuje dodatabase.server.name(mydebprefix)<schema_name>odpowiada nazwie schematu (publicw naszym scenariuszu)<table_name>odpowiada nazwie tabel (users,products,orders, orazorder_lines)
Jeśli sprawdzimy z kcat, the mydebprefix.public.users w Apache Kafka; powinniśmy zobaczyć dane podobne do poniższych:
{"before":null,"after":{"id":1,"username":"Franco"},"source":{"version":"1.9.7.aiven","connector":"postgresql","name":"mydebprefix1","ts_ms":1690794104325,"snapshot":"true","db":"defaultdb","sequence":"[null,\"251723832\"]","schema":"public","table":"users","txId":2404,"lsn":251723832,"xmin":null},"op":"r","ts_ms":1690794104585,"transaction":null}
{"before":null,"after":{"id":2,"username":"Giuseppina"},"source":{"version":"1.9.7.aiven","connector":"postgresql","name":"mydebprefix1","ts_ms":1690794104325,"snapshot":"true","db":"defaultdb","sequence":"[null,\"251723832\"]","schema":"public","table":"users","txId":2404,"lsn":251723832,"xmin":null},"op":"r","ts_ms":1690794104585,"transaction":null}
{"before":null,"after":{"id":3,"username":"Wiltord"},"source":{"version":"1.9.7.aiven","connector":"postgresql","name":"mydebprefix1","ts_ms":1690794104325,"snapshot":"true","db":"defaultdb","sequence":"[null,\"251723832\"]","schema":"public","table":"users","txId":2404,"lsn":251723832,"xmin":null},"op":"r","ts_ms":1690794104585,"transaction":null}Powyżej znajduje się typowa reprezentacja danych Debezium z rozszerzeniem before i after oświadczenia, a także informacje o transakcjach (ts_ms jako przykład) i źródle danych (schema, table i inne). Te bogate informacje będą przydatne później.
Problem spójności
Powiedzmy teraz Franco, jeden z naszych użytkowników zdecyduje się wydać nowe zamówienie na white-golden dress. Zaledwie kilka sekund później, nasza firma, ze względu na debaty online postanawia, że white-golden dress nazywa się teraz blue-black dress i chce pobierać opłaty 65$$ instead of the50$$ oryginalnej ceny.
Powyższe dwie akcje mogą być reprezentowane przez następujące dwie transakcje w PostgreSQL:
--- Franco purchasing the white-golden dress
BEGIN;
INSERT INTO ORDERS (SHIPPING_ADDR, ORDER_DATE, USER_ID) VALUES
('Piazza Carlo 2', '04/08/2023',1);
INSERT INTO ORDER_LINES (ORDER_ID, PROD_ID, QTY) VALUES
(4,4,1);
END;
--- Our company updating name and the price of the white-golden dress
BEGIN;
UPDATE PRODUCTS SET
NAME = 'blue-black dress',
PRICE = 65
WHERE ID = 4;
END;W każdym momencie możemy uzyskać szczegóły zamówienia za pomocą następującego zapytania:
SELECT
USERNAME,
ORDERS.ID ORDER_ID,
PRODUCTS.NAME PRODUCT_NAME,
PRODUCTS.PRICE PRODUCT_PRICE,
ORDER_LINES.QTY QUANTITY
FROM
USERS
JOIN ORDERS ON USERS.ID = ORDERS.USER_ID
JOIN ORDER_LINES ON ORDERS.ID = ORDER_LINES.ORDER_ID
JOIN PRODUCTS ON ORDER_LINES.PROD_ID = PRODUCTS.ID
WHERE ORDERS.ID = 4;Jeśli wykonamy zapytanie tuż po Francoale przed aktualizacją produktu, otrzymamy prawidłowe szczegóły zamówienia:
username | order_id | product_name | product_price | quantity
----------+----------+--------------------+---------------+----------
Franco | 4 | white-golden dress | 50 | 1
(1 row)Jeśli wykonamy to samo zapytanie po aktualizacji produktu, otrzymamy wynik blue-black dress znajduje się w zamówieniu i Franco naliczenie dodatkowych 15 dolarów.
username | order_id | product_name | product_price | quantity
----------+----------+------------------+---------------+----------
Franco | 4 | blue-black dress | 65 | 1
(1 row)Odtwarzanie spójności w Apache Kafka
Kiedy patrzymy na dane w Apache Kafka, możemy zobaczyć wszystkie zmiany w tematach. Przeglądanie mydebprefix.public.order_lines za pomocą kcat, możemy sprawdzić nowy wpis (wyniki w sekcji mydebprefix.public.orders będą podobne):
{"before":null,"after":{"id":8,"order_id":4,"prod_id":4,"qty":1},"source":{"version":"1.9.7.aiven","connector":"postgresql","name":"mydebprefix1","ts_ms":1690794206740,"snapshot":"false","db":"defaultdb","sequence":"[null,\"251744424\"]","schema":"public","table":"order_lines","txId":2468,"lsn":251744424,"xmin":null},"op":"c","ts_ms":1690794207231,"transaction":null}A w mydebprefix.public.products, możemy zobaczyć wpis taki jak poniższy, prezentujący aktualizację z white-golden dress do blue-black dress i związana z tym zmiana ceny:
{"before":{"id":4,"category":"dress","name":"white-golden dress","price":50},"after":{"id":4,"category":"dress","name":"blue-black dress","price":65},"source":{"version":"1.9.7.aiven","connector":"postgresql","name":"mydebprefix1","ts_ms":1690794209729,"snapshot":"false","db":"defaultdb","sequence":"[\"251744720\",\"251744720\"]","schema":"public","table":"products","txId":2469,"lsn":251744720,"xmin":null},"op":"u","ts_ms":1690794210275,"transaction":null}Pytanie brzmi teraz: jak możemy utrzymać porządek zgodny z rzeczywistością, gdzie Franco nabył white-golden dress za 50$?
Jak wspomniano wcześniej, format Debezium przechowuje wiele metadanych oprócz danych zmian. Moglibyśmy wykorzystać metadane transakcji (txId, lsn oraz ts_ms ) oraz dodatkowe narzędzia, takie jak Aiven dla Apache Flink® aby odtworzyć spójny widok transakcji za pomocą przetwarzania strumieniowego. To rozwiązanie wymaga jednak dodatkowych narzędzi, które mogą nie być w naszym zakresie.
Wykorzystanie wzorca Outbox w PostgreSQL
Alternatywnym rozwiązaniem, które nie wymaga dodatkowego oprzyrządowania, jest propagowanie spójnego widoku danych przy użyciu wzorca outbox pattern wbudowany w PostgreSQL. Dzięki wzorcowi skrzynki nadawczej przechowujemy, wraz z oryginalnym zestawem tabel, dodatkową tabelę, która konsoliduje informacje. Dzięki temu wzorcowi możemy aktualizować zarówno oryginalną tabelę, jak i tabelę skrzynki nadawczej w ramach transakcji.
Dodawanie nowej tabeli skrzynki nadawczej w PostgreSQL
Jak zaimplementować wzorzec skrzynki nadawczej w PostgreSQL? Pierwszą opcją jest dodanie nowej dedykowanej tabeli i zaktualizowanie jej w ramach tej samej transakcji, zmieniając atrybut ORDERS oraz ORDER_LINES . Możemy zdefiniować tabelę skrzynki nadawczej w następujący sposób:
CREATE TABLE ORDER_OUTBOX (
ORDER_LINE_ID INT,
ORDER_ID INT,
USERNAME TEXT,
PRODUCT_NAME TEXT,
PRODUCT_PRICE INT,
QUANTITY INT
);Następnie możemy dodać tabelę ORDER_OUTBOX w tabeli table.include.list dla Debezium Connector, aby śledzić jego zmiany. Ostatnią częścią równania jest aktualizacja tabeli skrzynki nadawczej przy każdym zamówieniu: jeśli Giuseppina chce 5 red t-shirts, transakcja będzie musiała zmienić ORDERS, ORDER_LINES oraz ORDER_OUTBOX tabele jak poniżej:
BEGIN;
INSERT INTO ORDERS (ID, SHIPPING_ADDR, ORDER_DATE, USER_ID) VALUES
(5, 'Lincoln Street', '05/08/2023',2);
INSERT INTO ORDER_LINES (ORDER_ID, PROD_ID, QTY) VALUES
(5,1,5);
INSERT INTO ORDER_OUTBOX
SELECT ORDER_LINES.ID,
ORDERS.ID,
USERNAME,
NAME PRODUCT_NAME,
PRICE PRODUCT_PRICE,
QTY QUANTITY
FROM USERS
JOIN ORDERS ON USERS.ID = ORDERS.USER_ID
JOIN ORDER_LINES ON ORDERS.ID = ORDER_LINES.ORDER_ID
JOIN PRODUCTS ON ORDER_LINES.PROD_ID = PRODUCTS.ID
WHERE ORDERS.ID=5;
END;Dzięki tej transakcji i zmianie konfiguracji Debezium w celu uwzględnienia public.order_outbox w CDC, otrzymujemy nowy temat o nazwie mydebprefix.public.order_outbox. Zawiera on następujące dane, które reprezentują spójną sytuację w PostgreSQL:
{"before":null,"after":{"order_line_id":12,"order_id":5,"username":"Giuseppina","product_name":"red t-shirt","product_price":5,"quantity":5},"source":{"version":"1.9.7.aiven","connector":"postgresql","name":"mydebprefix1","ts_ms":1690798353655,"snapshot":"false","db":"defaultdb","sequence":"[\"251744920\",\"486544200\"]","schema":"public","table":"order_outbox","txId":4974,"lsn":486544200,"xmin":null},"op":"c","ts_ms":1690798354274,"transaction":null}Unikanie dodatkowej tabeli z logicznym dekodowaniem PostgreSQL
Głównym problemem z podejściem opartym na tabeli skrzynki nadawczej jest to, że przechowujemy te same informacje dwukrotnie: raz w oryginalnych tabelach i raz w tabeli skrzynki nadawczej. Podwaja to zapotrzebowanie na pamięć masową, a oryginalne aplikacje korzystające z bazy danych zazwyczaj nie uzyskują do niej dostępu, co czyni to podejście nieefektywnym.
Lepszym podejściem transakcyjnym jest użycie Dekodowanie logiczne PostgreSQL. Stworzone pierwotnie do celów replikacji, dekodowanie logiczne PostgreSQL może również zapisywać informacje niestandardowe do dziennika WAL. Zamiast przywracać wynik połączonych danych w innej tabeli PostgreSQL, możemy wyemitować wynik jako wpis do dziennika WAL. Robiąc to w ramach transakcji, możemy skorzystać z izolacji transakcji; dlatego wpis w dzienniku jest zatwierdzany tylko wtedy, gdy cała transakcja jest.
Aby użyć logicznego dekodowania wiadomości PostgreSQL dla naszych potrzeb wzorca skrzynki nadawczej, musimy wykonać następujące czynności:
BEGIN;
DO
$$
DECLARE
JSON_ORDER text;
begin
INSERT INTO ORDERS (ID, SHIPPING_ADDR, ORDER_DATE, USER_ID) VALUES
(6, 'Via Ugo 1', '05/08/2023',3);
INSERT INTO ORDER_LINES (ORDER_ID, PROD_ID, QTY) VALUES
(6,4,2),(6,3,3);
SELECT JSONB_BUILD_OBJECT(
'order_id', ORDERS.ID,
'order_lines',
JSONB_AGG(
JSONB_BUILD_OBJECT(
'order_line', ORDER_LINES.ID,
'username', USERNAME,
'product_name', NAME,
'product_price',PRICE,
'quantity', QTY))) INTO JSON_ORDER
FROM USERS
JOIN ORDERS ON USERS.ID = ORDERS.USER_ID
JOIN ORDER_LINES ON ORDERS.ID = ORDER_LINES.ORDER_ID
JOIN PRODUCTS ON ORDER_LINES.PROD_ID = PRODUCTS.ID
WHERE ORDERS.ID=6
GROUP BY ORDERS.ID;
SELECT * FROM pg_logical_emit_message(true,'myprefix',JSON_ORDER) into JSON_ORDER;
END;
$$;
END;Gdzie:
- Dwa poniższe wiersze wstawiają nowe zamówienie do oryginalnych tabel
INSERT INTO ORDERS (ID, SHIPPING_ADDR, ORDER_DATE, USER_ID) VALUES
(6, 'Via Ugo 1', '05/08/2023',3);
INSERT INTO ORDER_LINES (ORDER_ID, PROD_ID, QTY) VALUES
(6,4,2),(6,3,3);Następnie musimy skonstruować plik SELECT że:
- Pobiera szczegóły nowego zamówienia z tabel źródłowych
- Tworzy unikalny dokument JSON (przechowywany w pliku
JSON_ORDER) dla całego zamówienia i przechowuje wyniki w tablicy dla każdego wiersza zamówienia. - Emituje to jako komunikat logiczny do pliku WAL.
The SELECT wygląda następująco:
SELECT * FROM pg_logical_emit_message(true,'outbox',JSON_ORDER) into JSON_ORDER;pg_logical_emit_message ma trzy argumenty. Pierwszy z nich, true, definiuje tę operację jako część transakcji. myprefix definiuje prefiks wiadomości, a JSON_ORDER to treść wiadomości.
Wyemitowany dokument JSON powinien wyglądać podobnie do:
{"order_id": 6, "order_lines": [{"quantity": 2, "username": "Wiltord", "order_line": 19, "product_name": "blue-black dress", "product_price": 65}, {"quantity": 3, "username": "Wiltord", "order_line": 20, "product_name": "blue t-shirt", "product_price": 15}]}Jeśli powyższa transakcja się powiedzie, powinniśmy zobaczyć nowy temat o nazwie mydebprefix.message który zawiera wiadomość logiczną, którą właśnie wypchnęliśmy, forma powinna być następująca:
{"op":"m","ts_ms":1690804437953,"source":{"version":"1.9.7.aiven","connector":"postgresql","name":"mydebmsg","ts_ms":1690804437778,"snapshot":"false","db":"defaultdb","sequence":"[\"822085608\",\"822089728\"]","schema":"","table":"","txId":8651,"lsn":822089728,"xmin":null},"message":{"prefix":"myprefix","content":"eyJvcmRlcl9pZCI6IDYsICJvcmRlcl9saW5lcyI6IFt7InF1YW50aXR5IjogMiwgInVzZXJuYW1lIjogIldpbHRvcmQiLCAib3JkZXJfbGluZSI6IDI1LCAicHJvZHVjdF9uYW1lIjogImJsdWUtYmxhY2sgZHJlc3MiLCAicHJvZHVjdF9wcmljZSI6IDY1fSwgeyJxdWFudGl0eSI6IDMsICJ1c2VybmFtZSI6ICJXaWx0b3JkIiwgIm9yZGVyX2xpbmUiOiAyNiwgInByb2R1Y3RfbmFtZSI6ICJibHVlIHQtc2hpcnQiLCAicHJvZHVjdF9wcmljZSI6IDE1fV19"}}Gdzie:
"op":"m"określa, że zdarzenie jest logicznym komunikatem dekodującym"prefix":"myprefix"jest prefiksem, który zdefiniowaliśmy wpg_logical_emit_messagecallcontentzawiera dokument JSON ze szczegółami zamówienia zakodowanymi na podstawie plikubinary.handling.modezdefiniowanego w definicji łącznika.
Jeśli użyjemy kombinacji kcat i jq do zaprezentowania danych zawartych w konektorze message.content części ładunku z:
kcat -b KAFKA_HOST:KAFKA_PORT \
-X security.protocol=SSL \
-X ssl.ca.location=ca.pem \
-X ssl.key.location=service.key \
-X ssl.certificate.location=service.crt \
-C -t mydebmsg.message -u | jq -r '.message.content | @base64d'Widzimy wiadomość w formacie JSON jako:
{"order_id": 6, "order_lines": [{"quantity": 2, "username": "Wiltord", "order_line": 25, "product_name": "blue-black dress", "product_price": 65}, {"quantity": 3, "username": "Wiltord", "order_line": 26, "product_name": "blue t-shirt", "product_price": 15}]}Wniosek
Zdefiniowanie systemu przechwytywania danych o zmianach pozwala technologiom niższego szczebla korzystać z zasobów informacyjnych, co jest przydatne tylko wtedy, gdy możemy zapewnić spójny widok danych. Wzorzec outbox pozwala nam łączyć dane z różnych tabel i zapewniać spójny, aktualny widok złożonych zapytań.
Logiczne dekodowanie PostgreSQL umożliwia nam przesyłanie takiego spójnego widoku do Apache Kafka bez konieczności zapisywania zmian w dodatkowej tabeli outbox, ale raczej poprzez zapisywanie bezpośrednio do dziennika WAL.