
Inżynierowie oprogramowania zajmują ekscytujące miejsce na tym świecie. Niezależnie od stosu technologicznego czy branży, naszym zadaniem jest rozwiązywanie problemów, które bezpośrednio przyczyniają się do realizacji celów naszych pracodawców. Co więcej, możemy wykorzystywać technologię do łagodzenia wszelkich wyzwań, które pojawiają się na naszym celowniku.
W tym przykładzie chciałem skupić się na tym, w jaki sposób pgvector – wyszukiwarka podobieństw wektorowych typu open source dla Postgres – może być używana do identyfikowania podobieństw danych istniejących w danych przedsiębiorstwa.
Prosty przypadek użycia
Jako prosty przykład załóżmy, że dział marketingu potrzebuje pomocy przy kampanii, którą planuje uruchomić. Celem jest dotarcie do wszystkich Salesforce kont, które działają w branżach ściśle powiązanych z branżą oprogramowania.
Ostatecznie chcieliby skupić się na kontach w trzech najbardziej podobnych branżach, z możliwością wykorzystania tego narzędzia w przyszłości do znalezienia podobieństw dla innych branż. Jeśli to możliwe, chcieliby mieć możliwość podania żądanej liczby pasujących branż, zamiast zawsze zwracać trzy najlepsze.
Projekt wysokiego poziomu
Ten przypadek użycia koncentruje się na wyszukiwaniu podobieństw. Chociaż możliwe jest wykonanie tego ćwiczenia ręcznie, to Wikipedia2Vec narzędzie przychodzi na myśl ze względu na wstępnie wytrenowane osadzenia, które zostały już utworzone dla wielu języków. Osadzenia słów – znane również jako wektory – to numeryczne reprezentacje słów, które zawierają zarówno informacje składniowe, jak i semantyczne. Reprezentując słowa jako wektory, możemy matematycznie określić, które słowa są semantycznie “bliższe” innym.
W naszym przykładzie mogliśmy również napisać prosty program w języku Python, aby utworzyć wektory słów dla każdej branży skonfigurowanej w Salesforce.
The pgvector wymaga bazy danych Postgres. Jednak dane przedsiębiorstwa dla naszego przykładu znajdują się obecnie w Salesforce. Na szczęście, Heroku Connect zapewnia łatwy sposób synchronizacji kont Salesforce z Heroku Postgres, przechowując je w tabeli o nazwie salesforce.account. Następnie będziemy mieć kolejną tabelę o nazwie salesforce.industries która zawiera każdą branżę w Salesforce (jako klucz VARCHAR) wraz z powiązanym z nią wektorem słów.
Mając dane Salesforce i wektory słów w Postgres, stworzymy RESTful API przy użyciu Java i Spring Boot. Usługa ta wykona niezbędne zapytanie, zwracając wyniki w formacie JSON.
Możemy zilustrować wysokopoziomowy widok rozwiązania w następujący sposób:

Kod źródłowy będzie znajdował się w GitLab. Wydanie polecenia git push heroku uruchomi wdrożenie w Heroku, wprowadzając interfejs API RESTful, z którego zespół marketingowy będzie mógł łatwo korzystać.
Tworzenie rozwiązania
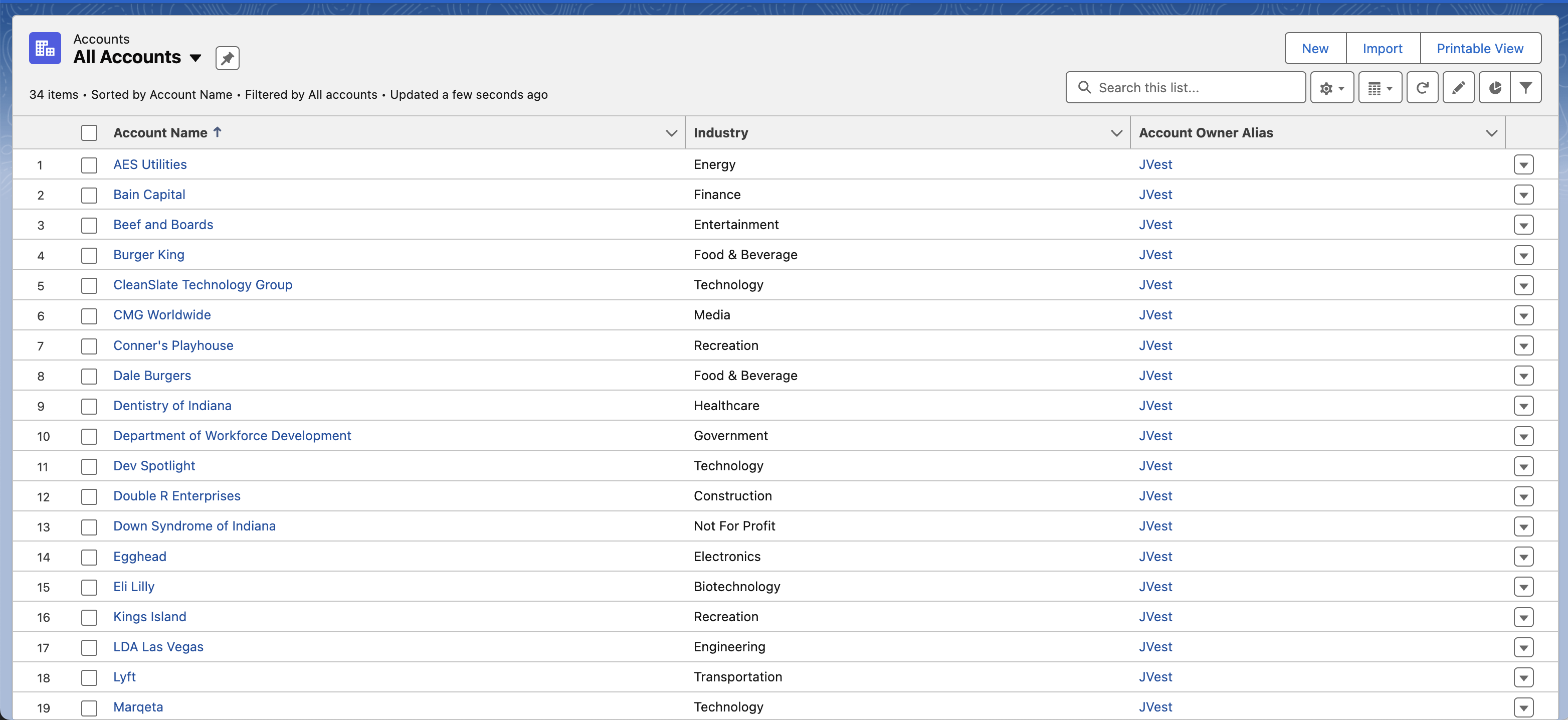
Mając gotowy projekt wysokiego poziomu, możemy rozpocząć tworzenie rozwiązania. Korzystając z mojego loginu Salesforce, mogłem przejść do sekcji Konta aby wyświetlić dane dla tego ćwiczenia. Oto przykład pierwszej strony danych przedsiębiorstwa:
Proszę utworzyć aplikację Heroku
W tym przypadku planowałem użyć Heroku, aby rozwiązać prośbę zespołu marketingowego. Zalogowałem się na moje konto Heroku i użyłem opcji Create New App aby utworzyć nową aplikację o nazwie similarity-search-sfdc:

Po utworzeniu aplikacji przeszedłem do strony Zasoby aby znaleźć dodatek Heroku Postgres. Wpisałem “Postgres” w polu wyszukiwania dodatków.

Po wybraniu Heroku Postgres z listy wybrałem Standard 0 plan, ale pgvector jest dostępny na bazach danych warstwy Standard (lub wyższej) z bazą danych PostgreSQL 15 lub bazą danych warstwy Essential w wersji beta.

Kiedy potwierdziłem dodatek, Heroku wygenerowało i udostępniło plik DATABASE_URL connection string. Znalazłem to w Config Vars sekcja Ustawienia w zakładce mojej aplikacji. Użyłem tych informacji, aby połączyć się z moją bazą danych i włączyć rozszerzenie pgvector w następujący sposób:
Następnie wyszukałem i znalazłem rozszerzenie Heroku Connect add-on. Wiedziałem, że da mi to łatwy sposób na połączenie się z danymi przedsiębiorstwa w Salesforce.

Na potrzeby tego ćwiczenia, darmowy dodatek Demo Edition plan działa bez zarzutu.

W tym momencie Zasoby zakładka dla similarity-search-sfdc wyglądała następująco:

Postępowałem zgodnie z “Konfiguracja Heroku Connect“, aby połączyć moje konto Salesforce z Heroku Connect. Następnie wybrałem opcję Konto do synchronizacji. Po zakończeniu mogłem zobaczyć te same dane konta Salesforce w Heroku Connect i w bazowej bazie danych Postgres.

Z perspektywy SQL to, co zrobiłem, spowodowało utworzenie obiektu salesforce.account tabeli o następującej konstrukcji:
create table salesforce.account
(
createddate timestamp,
isdeleted boolean,
name varchar(255),
systemmodstamp timestamp,
accountnumber varchar(40),
industry varchar(255),
sfid varchar(18),
id serial
primary key,
_hc_lastop varchar(32),
_hc_err text
);Generowanie wektorów
Aby wyszukiwanie podobieństw działało zgodnie z oczekiwaniami, musiałem wygenerować wektory słów dla każdej branży kont Salesforce:
- Odzież
- Bankowość
- Biotechnologia
- Budowa
- Edukacja
- Elektronika
- Inżynieria
- Rozrywka
- Żywność i napoje
- Finanse
- Rząd
- Opieka zdrowotna
- Gościnność
- Ubezpieczenia
- Media
- Nie dla zysku
- Inne
- Rekreacja
- Sprzedaż detaliczna
- Wysyłka
- Technologia
- Telekomunikacja
- Transport
- Usługi komunalne
Ponieważ główny przypadek użycia wskazywał na potrzebę znalezienia podobieństw dla branży oprogramowania, będziemy musieli wygenerować wektor słów również dla tej branży.
Aby uprościć to ćwiczenie, ręcznie wykonałem to zadanie przy użyciu Pythona 3.9 i pliku o nazwie embed.py, który wygląda następująco:
from wikipedia2vec import Wikipedia2Vec
wiki2vec = Wikipedia2Vec.load('enwiki_20180420_100d.pkl')
print(wiki2vec.get_word_vector('software').tolist())Proszę zwrócić uwagę – plik get_word_vector() metoda oczekuje reprezentacji branży małymi literami.
Uruchamianie Pythona embed.py wygenerowało następujący wektor słów dla software słowo:
[-0.40402618050575256, 0.5711150765419006, -0.7885153293609619, -0.15960034728050232, -0.5692323446273804,
0.005377458408474922, -0.1315757781267166, -0.16840921342372894, 0.6626015305519104, -0.26056772470474243,
0.3681095242500305, -0.453583300113678, 0.004738557618111372, -0.4111144244670868, -0.1817493587732315,
-0.9268549680709839, 0.07973367720842361, -0.17835664749145508, -0.2949991524219513, -0.5533796548843384,
0.04348105192184448, -0.028855713084340096, -0.13867013156414032, -0.6649054884910583, 0.03129105269908905,
-0.24817068874835968, 0.05968991294503212, -0.24743635952472687, 0.20582349598407745, 0.6240783929824829,
0.3214546740055084, -0.14210252463817596, 0.3178422152996063, 0.7693028450012207, 0.2426985204219818,
-0.6515568494796753, -0.2868216037750244, 0.3189859390258789, 0.5168254971504211, 0.11008890718221664,
0.3537853956222534, -0.713259220123291, -0.4132286608219147, -0.026366405189037323, 0.003034653142094612,
-0.5275223851203918, -0.018167126923799515, 0.23878540098667145, -0.6077089905738831, 0.5368344187736511,
-0.1210874393582344, 0.26415619254112244, -0.3066694438457489, 0.1471938043832779, 0.04954215884208679,
0.2045321762561798, 0.1391817331314087, 0.5286830067634583, 0.5764685273170471, 0.1882934868335724,
-0.30167853832244873, -0.2122340053319931, -0.45651525259017944, -0.016777794808149338, 0.45624101161956787,
-0.0438646525144577, -0.992512047290802, -0.3771328926086426, 0.04916151612997055, -0.5830298066139221,
-0.01255014631897211, 0.21600870788097382, -0.18419665098190308, 0.1754663586616516, -0.1499166339635849,
-0.1916201263666153, -0.22884036600589752, 0.17280352115631104, 0.25274306535720825, 0.3511175513267517,
-0.20270302891731262, -0.6383468508720398, 0.43260180950164795, -0.21136239171028137, -0.05920517444610596,
0.7145522832870483, 0.7626600861549377, -0.5473887920379639, 0.4523043632507324, -0.1723199188709259,
-0.10209759324789047, -0.5577948093414307, -0.10156919807195663, 0.31126976013183594, 0.3604489266872406,
-0.13295558094978333, 0.2473849356174469, 0.278846800327301, -0.28618067502975464, 0.00527254119515419]Tworzenie tabeli dla branż
Aby przechowywać wektory słów, musieliśmy dodać tabelę industries do bazy danych Postgres przy użyciu następującego polecenia SQL:
create table salesforce.industries
(
name varchar not null constraint industries_pk primary key,
embeddings vector(100) not null
);Z poleceniem industries wstawimy każdy z wygenerowanych wektorów słów. Zrobimy to za pomocą instrukcji SQL podobnej do poniższej:
INSERT INTO salesforce.industries
(name, embeddings)
VALUES
('Software','[-0.40402618050575256, 0.5711150765419006, -0.7885153293609619, -0.15960034728050232, -0.5692323446273804, 0.005377458408474922, -0.1315757781267166, -0.16840921342372894, 0.6626015305519104, -0.26056772470474243, 0.3681095242500305, -0.453583300113678, 0.004738557618111372, -0.4111144244670868, -0.1817493587732315, -0.9268549680709839, 0.07973367720842361, -0.17835664749145508, -0.2949991524219513, -0.5533796548843384, 0.04348105192184448, -0.028855713084340096, -0.13867013156414032, -0.6649054884910583, 0.03129105269908905, -0.24817068874835968, 0.05968991294503212, -0.24743635952472687, 0.20582349598407745, 0.6240783929824829, 0.3214546740055084, -0.14210252463817596, 0.3178422152996063, 0.7693028450012207, 0.2426985204219818, -0.6515568494796753, -0.2868216037750244, 0.3189859390258789, 0.5168254971504211, 0.11008890718221664, 0.3537853956222534, -0.713259220123291, -0.4132286608219147, -0.026366405189037323, 0.003034653142094612, -0.5275223851203918, -0.018167126923799515, 0.23878540098667145, -0.6077089905738831, 0.5368344187736511, -0.1210874393582344, 0.26415619254112244, -0.3066694438457489, 0.1471938043832779, 0.04954215884208679, 0.2045321762561798, 0.1391817331314087, 0.5286830067634583, 0.5764685273170471, 0.1882934868335724, -0.30167853832244873, -0.2122340053319931, -0.45651525259017944, -0.016777794808149338, 0.45624101161956787, -0.0438646525144577, -0.992512047290802, -0.3771328926086426, 0.04916151612997055, -0.5830298066139221, -0.01255014631897211, 0.21600870788097382, -0.18419665098190308, 0.1754663586616516, -0.1499166339635849, -0.1916201263666153, -0.22884036600589752, 0.17280352115631104, 0.25274306535720825, 0.3511175513267517, -0.20270302891731262, -0.6383468508720398, 0.43260180950164795, -0.21136239171028137, -0.05920517444610596, 0.7145522832870483, 0.7626600861549377, -0.5473887920379639, 0.4523043632507324, -0.1723199188709259, -0.10209759324789047, -0.5577948093414307, -0.10156919807195663, 0.31126976013183594, 0.3604489266872406, -0.13295558094978333, 0.2473849356174469, 0.278846800327301, -0.28618067502975464, 0.00527254119515419]
');Proszę zauważyć – podczas gdy utworzyliśmy wektor słów z małą reprezentacją branży oprogramowania (oprogramowanie), wektor słów industries.name musi odpowiadać nazwie branży pisanej wielkimi literami (Software).
Po dodaniu wszystkich wygenerowanych wektorów słów do pliku industries możemy skupić się na wprowadzeniu interfejsu API RESTful.
Wprowadzenie usługi Spring Boot
To był moment, w którym moja pasja jako inżyniera oprogramowania wskoczyła na wysokie obroty, ponieważ miałem wszystko na miejscu, aby rozwiązać wyzwanie.
Następnie, używając Spring Boot 3.2.2 i Java (temurin) 17, stworzyłem aplikację similarity-search-sfdc w IntelliJ IDEA z następującymi zależnościami Maven:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.pgvector</groupId>
<artifactId>pgvector</artifactId>
<version>0.1.4</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>Stworzyłem uproszczone encje zarówno dla Konto obiekt i Przemysł (embedding), który jest powiązany z utworzonymi wcześniej tabelami bazy danych Postgres.
@AllArgsConstructor
@NoArgsConstructor
@Data
@Entity
@Table(name = "account", schema = "salesforce")
public class Account {
@Id
@Column(name = "sfid")
private String id;
private String name;
private String industry;
}
@AllArgsConstructor
@NoArgsConstructor
@Data
@Entity
@Table(name = "industries", schema = "salesforce")
public class Industry {
@Id
private String name;
}Korzystając z interfejsu JpaRepository, dodałem następujące rozszerzenia, aby umożliwić łatwy dostęp do tabel Postgres:
public interface AccountsRepository extends JpaRepository<Account, String> {
@Query(nativeQuery = true, value = "SELECT sfid, name, industry " +
"FROM salesforce.account " +
"WHERE industry IN (SELECT name " +
" FROM salesforce.industries " +
" WHERE name != :industry " +
" ORDER BY embeddings <-> (SELECT embeddings
FROM salesforce.industries
WHERE name = :industry) " +
" LIMIT :limit)" +
"ORDER BY name")
Set<Account> findSimilaritiesForIndustry(String industry, int limit);
}
public interface IndustriesRepository extends JpaRepository<Industry, String> { }Proszę zwrócić uwagę na findSimilaritiesForIndustry() to metoda, w której odbędzie się całe ciężkie podnoszenie w celu rozwiązania tego przypadku użycia. Metoda przyjmie następujące parametry:
industry: branża, dla której mają zostać znalezione podobieństwalimit: maksymalna liczba podobieństw branżowych do wyszukania podczas wyszukiwania kont.
Proszę zwrócić uwagę na operator odległości euklidesowej (<->) w naszym zapytaniu powyżej. Jest to wbudowane rozszerzenie operator do wyszukiwania podobieństwa.
Przy oryginalnym przypadku użycia branży “Oprogramowanie” i ograniczeniu do trzech najbliższych branż, wykonywane zapytanie wyglądałoby następująco:
SELECT sfid, name, industry
FROM salesforce.account
WHERE industry
IN (SELECT name
FROM salesforce.industries
WHERE name != 'Software'
ORDER BY embeddings
<-> (SELECT embeddings
FROM salesforce.industries
WHERE name="Software")
LIMIT 3)
ORDER BY name;Stamtąd zbudowałem AccountsService do interakcji z repozytoriami JPA:
@RequiredArgsConstructor
@Service
public class AccountsService {
private final AccountsRepository accountsRepository;
private final IndustriesRepository industriesRepository;
public Set<Account> getAccountsBySimilarIndustry(String industry,
int limit)
throws Exception {
List<Industry> industries = industriesRepository.findAll();
if (industries
.stream()
.map(Industry::getName)
.anyMatch(industry::equals)) {
return accountsRepository
.findSimilaritiesForIndustry(industry, limit);
} else {
throw new Exception(
"Could not locate '" + industry + "' industry");
}
}
}Na koniec miałem klasę AccountsController zapewnić punkt wejścia RESTful i połączyć się z klasą AccountsService:
@RequiredArgsConstructor
@RestController
@RequestMapping(value = "/accounts")
public class AccountsController {
private final AccountsService accountsService;
@GetMapping(value = "/similarities")
public ResponseEntity<Set<Account>> getAccountsBySimilarIndustry(@RequestParam String industry, @RequestParam int limit) {
try {
return new ResponseEntity<>(
accountsService
.getAccountsBySimilarIndustry(industry, limit),
HttpStatus.OK);
} catch (Exception e) {
return new ResponseEntity<>(HttpStatus.NOT_FOUND);
}
}
}Wdrażanie na Heroku
Po przygotowaniu usługi Spring Boot dodałem następujące elementy Procfile do projektu, informując Heroku o naszej usłudze:
web: java $JAVA_OPTS -Dserver.port=$PORT -jar target/*.jarDla bezpieczeństwa dodałem atrybut system.properties aby określić, jakie wersje Java i Maven są oczekiwane:
java.runtime.version=17
maven.version=3.9.5Korzystając z interfejsu Heroku CLI, dodałem pilota do mojego repozytorium GitLab dla pliku similarity-search-sfdc do platformy Heroku:
heroku git:remote -a similarity-search-sfdcUstawiłem również typ buildpack dla similarity-search-sfdc za pomocą następującego polecenia:
heroku buildpacks:set https://github.com/heroku/heroku-buildpack-java Na koniec wdrożyłem usługę similarity-search-sfdc na Heroku za pomocą następującego polecenia:
Teraz Zasoby zakładka dla similarity-search-sfdc pojawiła się jak pokazano poniżej:

Wyszukiwanie podobieństw w akcji
Po uruchomieniu RESTful API wydałem następujące polecenie cURL, aby zlokalizować trzy najlepsze branże Salesforce (i powiązane konta), które są najbliżej Oprogramowanie przemysł:
curl --location 'https://HEROKU-APP-ROOT-URL/accounts/similarities?industry=Software&limit=3'Interfejs API RESTful zwraca wartość 200 OK HTTP status odpowiedzi wraz z następującym ładunkiem:
[
{
"id": "001Kd00001bsP80IAE",
"name": "CleanSlate Technology Group",
"industry": "Technology"
},
{
"id": "001Kd00001bsPBFIA2",
"name": "CMG Worldwide",
"industry": "Media"
},
{
"id": "001Kd00001bsP8AIAU",
"name": "Dev Spotlight",
"industry": "Technology"
},
{
"id": "001Kd00001bsP8hIAE",
"name": "Egghead",
"industry": "Electronics"
},
{
"id": "001Kd00001bsP85IAE",
"name": "Marqeta",
"industry": "Technology"
}
]W rezultacie Technologia, Media, oraz Elektronika to branże najbardziej zbliżone do Oprogramowanie przemysł w tym przykładzie.
Teraz dział marketingu ma listę kont, z którymi może się skontaktować w celu przeprowadzenia kolejnej kampanii.
Wnioski
Lata temu spędziłem więcej czasu, niż chciałbym przyznać, grając w Team Fortress 2 wieloosobowa gra wideo. Oto zrzut ekranu z wydarzenia z 2012 roku, które było świetną zabawą:

Osoby zaznajomione z tym aspektem mojego życia mogą powiedzieć, że moją domyślną klasą był żołnierz. To dlatego, że żołnierz ma najlepszą równowagę między zdrowiem, ruchem, szybkością i siłą ognia.
Czuję, że inżynierowie oprogramowania są “klasą żołnierza” w prawdziwym świecie, ponieważ potrafimy dostosować się do każdej sytuacji i skupić się na dostarczaniu rozwiązań, które spełniają oczekiwania w efektywny sposób.
Od kilku lat skupiam się na następującej misji, która moim zdaniem może mieć zastosowanie do każdego profesjonalisty IT:
“Proszę skupić swój czas na dostarczaniu cech/funkcjonalności, które zwiększają wartość Państwa własności intelektualnej. Wykorzystaj frameworki, produkty i usługi do wszystkiego innego”.
– J. Vester
W przykładzie dla tego postu byliśmy w stanie wykorzystać Heroku Connect do synchronizacji danych przedsiębiorstwa z bazą danych Postgres. Po zainstalowaniu rozszerzenia pgvector utworzyliśmy wektory słów dla każdej unikalnej branży z tych kont Salesforce. Na koniec wprowadziliśmy usługę Spring Boot, która uprościła proces lokalizowania kont Salesforce, których branża była najbliższa innej branży.
Szybko rozwiązaliśmy ten przypadek użycia dzięki istniejącym technologiom open source, dodaniu niewielkiej usługi Spring Boot i Heroku PaaS – w pełni przestrzegając mojej misji. Nie mogę sobie wyobrazić, ile czasu zajęłoby to bez tych frameworków, produktów i usług.
Jeśli są Państwo zainteresowani, oryginalny kod źródłowy tego artykułu można znaleźć na stronie GitLab.
Miłego dnia!