
Ten artykuł jest fragmentem mojej książki Książka kucharska TinyML, wydanie drugie. Mogą Państwo znaleźć kod użyty w artykule tutaj.
Getting Ready
Aplikacja, którą zaprojektujemy w tym artykule, ma na celu ciągłe nagrywanie 1-sekundowego klipu audio i uruchamianie wnioskowania o modelu, jak pokazano na poniższym obrazku:
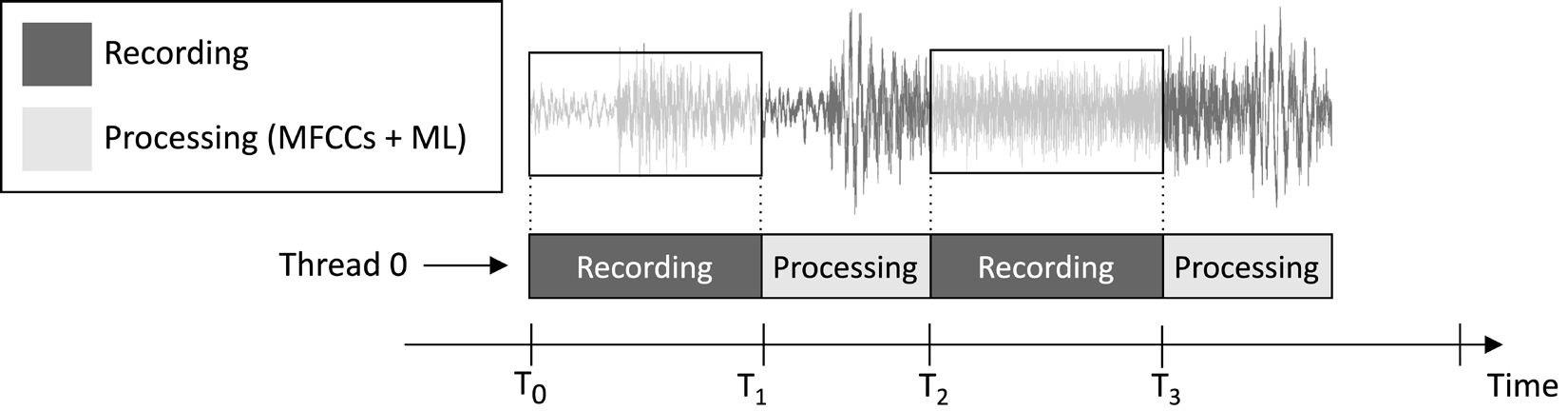
Rysunek 1: Zadania nagrywania i przetwarzania działające sekwencyjnie
Z osi czasu wykonywania zadań pokazanej na poprzednim obrazku można zauważyć, że ekstrakcja cech i wnioskowanie o modelu są zawsze wykonywane po nagraniu audio, a nie jednocześnie. Dlatego oczywiste jest, że nie przetwarzamy niektórych segmentów strumienia audio na żywo.
W przeciwieństwie do aplikacji do wykrywania słów kluczowych w czasie rzeczywistym (KWS), która powinna przechwytywać i przetwarzać wszystkie fragmenty strumienia audio, aby nigdy nie przegapić żadnego wypowiedzianego słowa, tutaj możemy złagodzić ten wymóg, ponieważ nie zagraża to skuteczności aplikacji.
Jak wiemy, danymi wejściowymi do ekstrakcji cech MFCC jest 1-sekundowy surowy dźwięk w formacie Q15. Jednak próbki pozyskane za pomocą mikrofonu są reprezentowane jako 16-bitowe wartości całkowite. Stąd, Jak przekonwertować 16-bitowe wartości całkowite na Q15? Rozwiązanie jest prostsze niż mogłoby się wydawać: konwertowanie próbek audio nie jest konieczne.
Aby zrozumieć dlaczego, proszę rozważyć format stałoprzecinkowy Q15. Format ten może reprezentować wartości zmiennoprzecinkowe w zakresie [-1, 1] zakresu. Konwersja z formatu zmiennoprzecinkowego na Q15 polega na pomnożeniu wartości zmiennoprzecinkowych przez 32 768 (215). Niemniej jednak, ponieważ reprezentacja zmiennoprzecinkowa pochodzi z podzielenia 16-bitowej próbki liczby całkowitej przez 32 768 (215), oznacza to, że 16-bitowe wartości całkowite są z natury w formacie Q15.
Jak to zrobić…
Proszę wziąć płytkę prototypową z mikrofonem podłączonym do Raspberry Pi Pico. Proszę odłączyć kabel danych od mikrokontrolera i usunąć przycisk oraz podłączone do niego zworki z płytki prototypowej, ponieważ nie są one wymagane w tym przepisie. Rysunek 2 pokazuje, co powinien Pan mieć na płytce prototypowej:
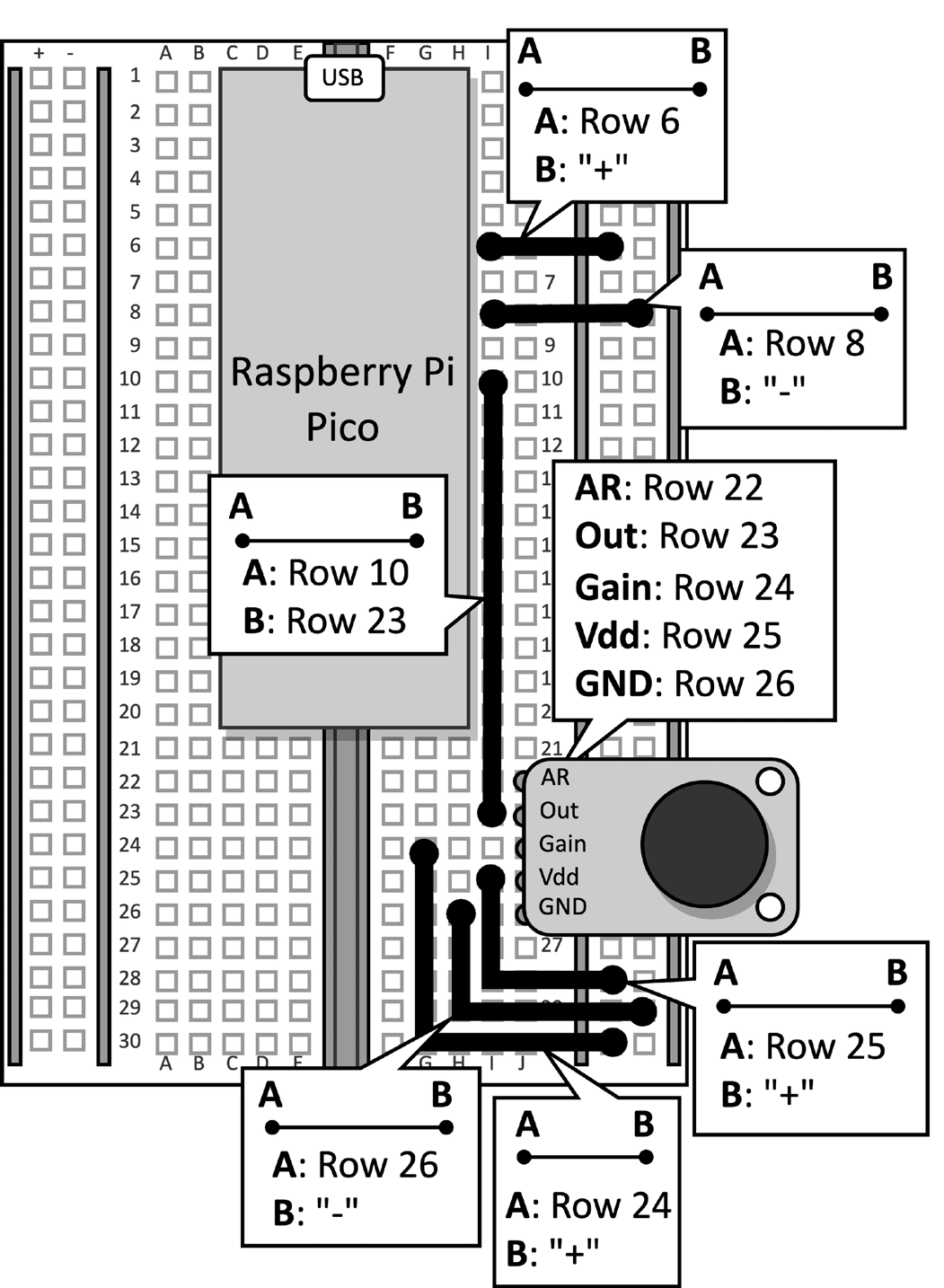
Rysunek 2: Układ elektroniczny zbudowany na płytce drukowanej
Po usunięciu przycisku z płytki, proszę otworzyć Arduino IDE i utworzyć nowy szkic.
Teraz proszę wykonać następujące kroki, aby opracować aplikację do rozpoznawania gatunków muzycznych na Raspberry Pi Pico:
Krok 1
Proszę pobrać Arduino TensorFlow Lite biblioteka z TinyML-Cookbook_2E GitHub repozytorium.
Po pobraniu pliku ZIP proszę zaimportować go do Arduino IDE.
Krok 2
Proszę zaimportować wszystkie wygenerowane pliki nagłówkowe C wymagane dla algorytmu ekstrakcji cech MFCCs do Arduino IDE, z wyłączeniem test_src.h i test_dst.h.
Krok 3
Proszę skopiować szkic opracowany w Rozdział 6, Wdrożenie algorytmu ekstrakcji cech MFCCs na Raspberry Pi Pico do implementacji ekstrakcji cech MFCCs, z wyłączeniem algorytmu setup() i loop() funkcje.
Proszę usunąć włączenie funkcji test_src.h i test_dst.h pliki nagłówkowe. Następnie proszę usunąć alokację tablicy dst, ponieważ MFCC będą przechowywane bezpośrednio na wejściu modelu.
Krok 4
Proszę skopiować szkic opracowany w Rozdział 5, Rozpoznawanie gatunków muzycznych za pomocą TensorFlow i Raspberry Pi Pico – Część 1, aby nagrywać próbki audio za pomocą mikrofonu, z wyjątkiem setup() i loop() funkcje.
Po zaimportowaniu kodu proszę usunąć wszelkie odniesienia do diody LED i przycisku, ponieważ nie są one już potrzebne. Następnie proszę zmienić definicję AUDIO_LENGTH_SEC na nagrywanie dźwięku trwającego 1 sekundę:
#define AUDIO_LENGTH_SEC 1Krok 5
Proszę zaimportować plik nagłówkowy zawierający model TensorFlow Lite (model.h) do projektu Arduino.
Po zaimportowaniu pliku, proszę dołączyć plik model.h plik nagłówkowy w szkicu:
Proszę dołączyć niezbędne pliki nagłówkowe dla tflite-micro:
#include <TensorFlowLite.h>
#include <tensorflow/lite/micro/all_ops_resolver.h>
#include <tensorflow/lite/micro/micro_interpreter.h>
#include <tensorflow/lite/micro/micro_log.h>
#include <tensorflow/lite/micro/system_setup.h>
#include <tensorflow/lite/schema/schema_generated.h>Krok 6
Proszę zadeklarować zmienne globalne dla modelu i interpretera tflite-micro:
const tflite::Model* tflu_model = nullptr;
tflite::MicroInterpreter* tflu_interpreter = nullptr;
Następnie proszę zadeklarować obiekty tensora TensorFlow Lite (TfLiteTensor), aby uzyskać dostęp do tensorów wejściowych i wyjściowych modelu:
TfLiteTensor* tflu_i_tensor = nullptr;
TfLiteTensor* tflu_o_tensor = nullptr;
Krok 7
Proszę zadeklarować bufor (tensor arena) do przechowywania pośrednich tensorów używanych podczas wykonywania modelu:
constexpr int tensor_arena_size = 16384;
uint8_t tensor_arena[tensor_arena_size] __attribute__((aligned(16)));
Rozmiar areny tensorowej został określony na podstawie testów empirycznych, ponieważ pamięć potrzebna dla tensorów pośrednich różni się w zależności od sposobu implementacji operatora LSTM. Nasze eksperymenty na Raspberry Pi Pico wykazały, że model wymaga jedynie 16 KB pamięci RAM do wnioskowania.
Krok 8
W sekcji setup() proszę zainicjować szeregowe urządzenie peryferyjne za pomocą parametru 115200 szybkość transmisji:
Serial.begin(115200);
while (!Serial);
Szeregowe urządzenie peryferyjne zostanie wykorzystane do przesyłania rozpoznanego gatunku muzyki za pośrednictwem komunikacji szeregowej.
Krok 9
W sekcji setup() proszę załadować model TensorFlow Lite przechowywany w pliku model.h pliku nagłówkowym:
tflu_model = tflite::GetModel(model_tflite);Następnie proszę zarejestrować wszystkie operacje DNN obsługiwane przez tflite-micro i zainicjować interpreter tflite-micro:
tflite::AllOpsResolver tflu_ops_resolver;
static tflite::MicroInterpreter static_interpreter(
tflu_model,
tflu_ops_resolver,
tensor_arena,
tensor_arena_size);
tflu_interpreter = &static_interpreter;Krok 10
W sekcji setup() proszę przydzielić pamięć wymaganą dla modelu i pobrać wskaźnik pamięci tensorów wejściowych i wyjściowych:
tflu_interpreter->AllocateTensors();
tflu_i_tensor = tflu_interpreter->input(0);
tflu_o_tensor = tflu_interpreter->output(0);
Krok 11
W sekcji setup() proszę użyć Raspberry Pi Pico SDK do zainicjowania urządzenia peryferyjnego ADC:
adc_init();
adc_gpio_init(26);
adc_select_input(0);
Krok 12
W loop() proszę przygotować dane wejściowe modelu. W tym celu należy nagrać klip audio trwający 1 sekundę:
// Reset audio buffer
buffer.cur_idx = 0;
buffer.is_ready = false;
constexpr uint32_t sr_us = 1000000 / SAMPLE_RATE;
timer.attach_us(&timer_ISR, sr_us);
while(!buffer.is_ready);
timer.detach();Po nagraniu dźwięku proszę wyodrębnić MFCC:
mfccs.run((const q15_t*)&buffer.data[0],
(float *)&tflu_i_tensor->data.f[0]);
Jak widać z poprzedniego fragmentu kodu, MFCC będą przechowywane bezpośrednio na wejściu modelu.
Krok 13
Proszę uruchomić wnioskowanie modelu i zwrócić wynik klasyfikacji za pośrednictwem komunikacji szeregowej:
tflu_interpreter->Invoke();
size_t ix_max = 0;
float pb_max = 0;
for (size_t ix = 0; ix < 3; ix++) {
if(tflu_o_tensor->data.f[ix] > pb_max) {
ix_max = ix;
pb_max = tflu_o_tensor->data.f[ix];
}
}
const char *label[] = {"disco", "jazz", "metal"};
Serial.println(label[ix_max]);Teraz proszę podłączyć kabel danych micro-USB do Raspberry Pi Pico. Po podłączeniu proszę skompilować i wgrać szkic na mikrokontroler.
Następnie proszę otworzyć monitor szeregowy w oknie Arduino IDE i umieścić smartfon w pobliżu mikrofonu, aby odtworzyć utwór disco, jazz lub metal. Aplikacja powinna teraz rozpoznać gatunek muzyczny utworu i wyświetlić wynik klasyfikacji na monitorze szeregowym!
Wnioski
W tym artykule dowiedzieli się Państwo, jak wdrożyć wytrenowany model klasyfikacji gatunków muzycznych na Raspberry Pi Pico przy użyciu tflite-micro.