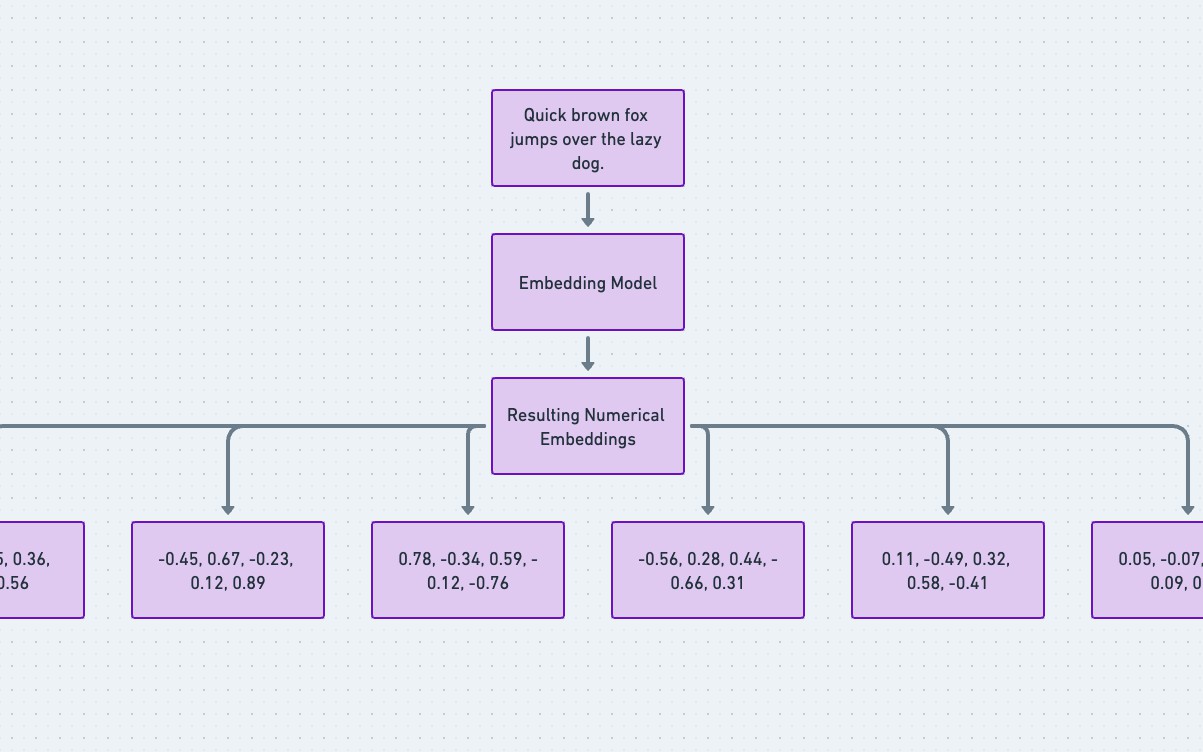
Osadzenia wektorowe są potężnym narzędziem w sztucznej inteligencji. Są to matematyczne (numeryczne) reprezentacje słów lub fraz w przestrzeni wektorowej. Zwykle przetwarzane przez modele osadzania, te reprezentacje wektorowe przechwytują semantyczne relacje między słowami, umożliwiając algorytmy do zrozumienia kontekstu i znaczenia tekstu. Analizując kontekst, w którym pojawia się słowo, osadzenia mogą uchwycić jego znaczenie i semantyczne relacje z innymi słowami.
Rola osadzeń i wektorowych magazynów/baz danych w nowoczesnych aplikacjach
Embeddings mają kluczowe znaczenie dla nowoczesnych aplikacji, takich jak systemy rekomendacji, wyszukiwarki i bazy danych wektorów. przetwarzanie języka naturalnego. Pomagają one zrozumieć preferencje użytkowników, dopasować zapytania do odpowiednich dokumentów i poprawić dokładność zadań związanych z językiem.
Alongside embeddings, wektorowe bazy danych odgrywają kluczową rolę w uwolnieniu ich mocy. Wektorowe bazy danych, takie jak Pinecone i ChromaDB, zapewniają skalowalne i wydajne przechowywanie i pobieranie osadzeń wektorów. Pozwalają one na szybkie wyszukiwanie podobieństw wśród rozległych kolekcji osadzeń, umożliwiając szybkie i dokładne wyszukiwanie istotnych informacji. Mogą Państwo znaleźć listę sklepów wektorowych i baz danych, z których mogą Państwo korzystać w Państwa aplikacji.
Weźmy przykład aplikacji czatu opartej na sztucznej inteligencji, aby zrozumieć, jak działają te dwie rzeczy. Deweloperzy mogą szybko wyszukiwać odpowiednie odpowiedzi na czacie na podstawie zapytań użytkowników, przechowując i indeksując wiadomości czatu jako osadzenia wektorowe w wektorowej bazie danych. Te osadzenia wektorowe przechwytują informacje kontekstowe konwersacji, umożliwiając spójne i konsekwentne odpowiedzi w trakcie sesji. Dzięki stanowej interakcji i możliwościom reagowania w czasie rzeczywistym, Pinecone może skutecznie obsługiwać kontekst konwersacji i utrzymywać stan sesji w tym scenariuszu.
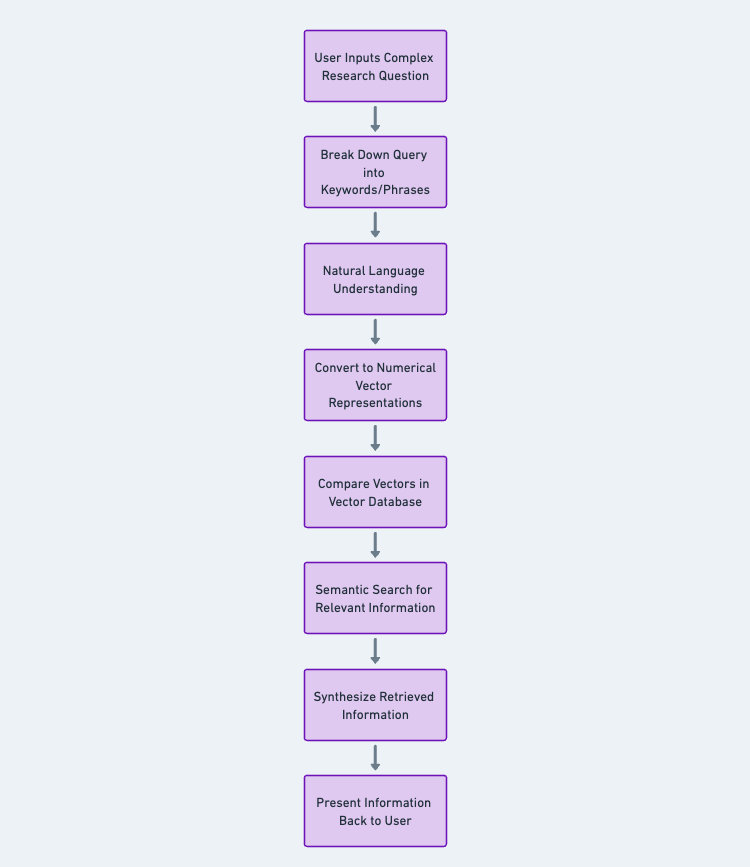
Jak działa wyszukiwanie informacji.
Wdrażanie embeddings w Państwa projektach
Jako inżynier produktu lub oprogramowania mogą Państwo włączyć osadzanie do swoich projektów na kilka sposobów. Można użyć wstępnie wytrenowanych modeli osadzania, takich jak ColBERT, Word2Vec lub GloVe, które zostały wytrenowane na dużych korpusach danych tekstowych i są łatwo dostępne do użycia. Ponadto dostępne są biblioteki i frameworki, które ułatwiają implementację i wykorzystanie osadzania w Państwa projektach. Oto ich lista open-source embedding modele. Jeśli są Państwo programistami Pythona, mogą Państwo znaleźć listę dostępnych transformatorów zdań (embedderów opartych na Pythonie) na stronie Huggingface.
Proszę napisać przykładowy projekt używając najnowszego openAI text-embedding-3-small i text-embedding-3-large modele osadzania.
Krok 1: Proszę utworzyć nowy folder i uruchomić poniższe polecenie, aby skonfigurować projekt węzła.
Krok 2: Proszę zainstalować pakiet openai
npm install --save openaiKrok 3: Proszę utworzyć plik index.js i skopiować do niego poniższe elementy.
const { OpenAI} = require("openai");
const openai = new OpenAI({
apiKey: ""
});
async function main() {
const embedding = await openai.embeddings.create({
model: "text-embedding-3-small",
input: "Quick brown fox jumps over the lazy dog.",
encoding_format: "float",
});
console.log(embedding);
}
main();Proszę pamiętać, że to tylko do testów. Proszę upewnić się, że zapisali Państwo klucz `openai: process.env.OPENAI_API_KEY` w pliku .env dla środowisk produkcyjnych.
Krok 4: Proszę uruchomić `node index.js`, a zobaczy Pan tablicę osadzania i liczbę użytych tokenów.
{
object: 'list',
data: [ { object: 'embedding', index: 0, embedding: [Array] } ],
model: 'text-embedding-3-small',
usage: { prompt_tokens: 9, total_tokens: 9 }
}
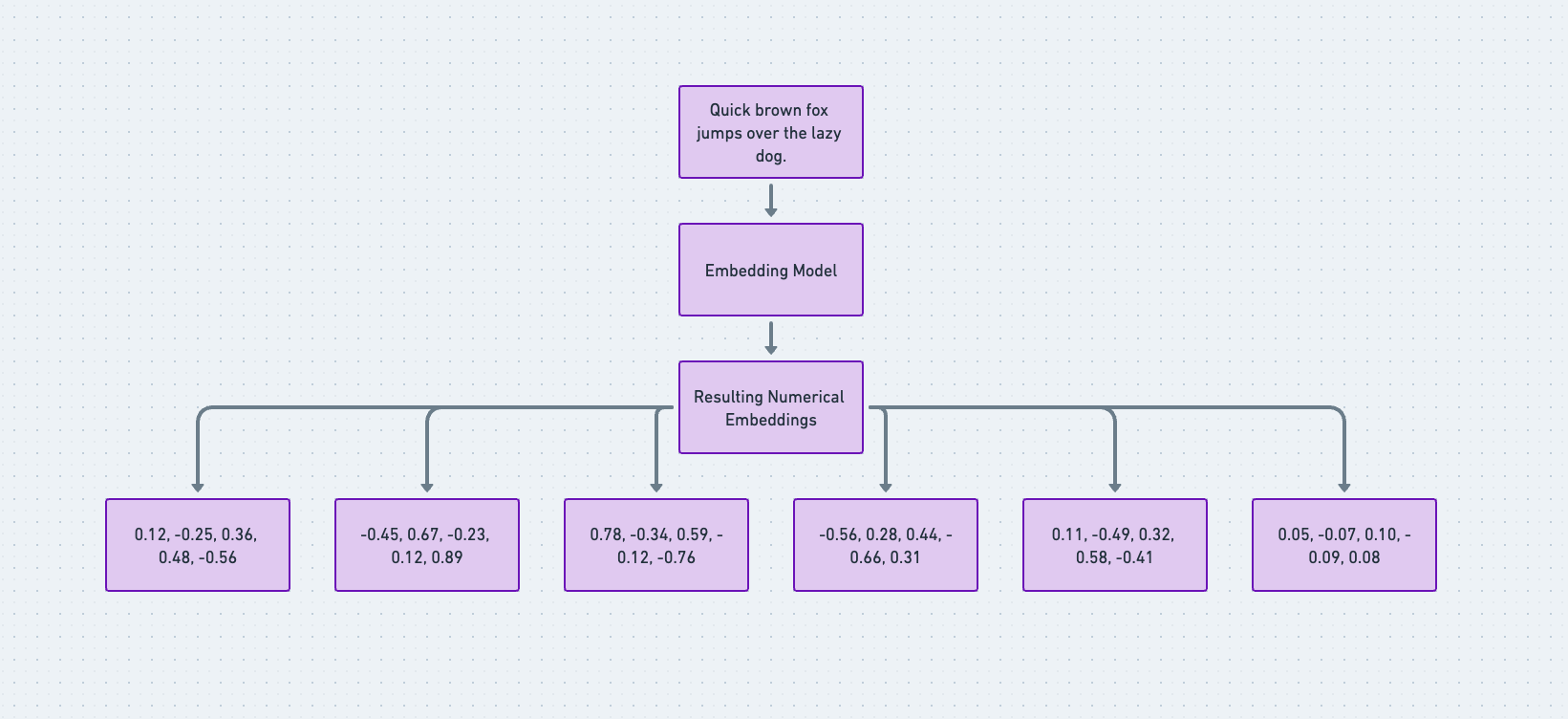
Krok 5: Aby uzyskać dostęp do osadzeń wektorowych wygenerowanych z naszego tekstu zachęty, zmieńmy `console.log(embedding);` na `console.log(embedding.data[0].embedding),` i powinni Państwo zobaczyć ogromną tablicę osadzeń, jak ta poniżej:

Wynik osadzania tekstu.
Najlepsze praktyki dotyczące pracy z osadzeniami
Podczas pracy z osadzeniami istnieje kilka najlepszych praktyk, których inżynierowie produktu i oprogramowania mogą przestrzegać, aby zmaksymalizować ich skuteczność:
1. Proszę wybrać odpowiedni model osadzania: Dostępne są różne wstępnie wytrenowane modele osadzania, z których każdy ma swoje mocne i słabe strony. Inżynierowie produktu i oprogramowania muszą starannie wybrać model osadzania, który najlepiej pasuje do ich konkretnej aplikacji, budżetu i danych.
2. Efektywne wstępne przetwarzanie danych: Proszę dokładnie wyczyścić i wstępnie przetworzyć dane tekstowe, aby poprawić jakość osadzania. Obejmuje to między innymi tokenizację, usuwanie słów stop i zarządzanie słowami spoza słownictwa. Jeśli korzystają Państwo z frameworka do tworzenia aplikacji opartych na sztucznej inteligencji, takich jak Langchain, jest on dostarczany z pakietem programów ładujących dokumenty, które pomogą w czystym analizowaniu i wstępnym przetwarzaniu źródeł danych.
3. Proszę stale aktualizować i oceniać swoje osadzenia. Proszę je regularnie przekwalifikowywać z wykorzystaniem nowych danych, aby były aktualne i odpowiednie. Należy również konsekwentnie oceniać wydajność osadzania w dalszych zadaniach, aby upewnić się, że skutecznie przyczyniają się one do realizacji celów aplikacji. Na przykład, można uzyskać najnowsze testy wydajności modeli osadzania tekstu na stronie Massive Text Embedding Benchmark (MTEB) Leaderboard.
Wnioski
Włączenie osadzania wektorowego do rozwiązań inżynieryjnych może odblokować znaczące korzyści dla inżynierów produktu i oprogramowania. Wykorzystując osadzenia wektorowe i powiązane z nimi konfiguracje sztucznej inteligencji, inżynierowie produktu i oprogramowania mogą tworzyć bardziej wyrafinowane i zaawansowane aplikacje oparte na sztucznej inteligencji, aby zapewnić lepsze wrażenia użytkownika.