
Podczas gdy SQL został wynaleziony dla modelu relacyjnego, okazał się nieracjonalnie skuteczny dla wielu form danych, w tym danych dokumentów z heterogenicznością typów, zagnieżdżaniem i brakiem schematu. Couchbase Capella posiada zarówno silniki operacyjne, jak i analityczne. Zarówno silniki operacyjne, jak i analityczne obsługują JSON do modelowania danych i SQL++ do zapytań. Ponieważ przypadki użycia operacyjnego i analitycznego mają różne wymagania dotyczące obciążenia, dwa silniki Couchbase mają różne możliwości, które są dostosowane do wymagań każdego obciążenia. W tym artykule przedstawiono niektóre z nowych funkcji i możliwości nowej usługi analitycznej Couchbase, usługi Capella Columnar.
Aby usprawnić przetwarzanie danych w czasie rzeczywistym, Couchbase wprowadził usługę usługę Capella Columnar. Istnieje wiele technologii wyróżniających tę nową usługę, w tym przechowywanie kolumnowe dla bezschematowego silnika danych i jego przetwarzanie. W tym artykule przedstawimy Państwu przegląd wyzwań związanych z wdrażaniem przechowywania w kolumnach dla JSON oraz technik stosowanych w tej usłudze. Kolumnowy aby sprostać tym wyzwaniom.
Przechowywanie danych w wierszach i kolumnach
Przechowywanie wierszowe
Z przechowywanie rzędowe, każdy wiersz tabeli jest przechowywany jako ciągła jednostka na stronach danych tabeli. Wszystkie pola pojedynczego wiersza są przechowywane razem, a następnie pola następnego wiersza i tak dalej. Każdy wiersz może mieć od 1 do N kolumn, a aby uzyskać dostęp do dowolnej z kolumn, całe wiersze są przenoszone do pamięci i przetwarzane. Jest to wydajne w przypadku operacji transakcyjnych, ponieważ zwykle potrzebne są wszystkie lub większość pól.

Rysunek 1: Tabela logiczna do fizycznej reprezentacji wierszy
Przechowywanie kolumnowe
Magazynowanie kolumnoweZ drugiej strony, przechowuje każdą kolumnę (pole w dokumencie JSON) danych oddzielnie. Wszystkie wartości pojedynczej kolumny są przechowywane w sposób ciągły. Format ten jest szczególnie wydajny w przypadku operacji analitycznych i wymagających odczytu, które obejmują zapytania dotyczące kilku kolumn w wielu wierszach, ponieważ pozwala na szybszy odczyt odpowiednich danych, lepszą kompresję i bardziej efektywne wykorzystanie zasobów, takich jak żądania we / wy dysku.
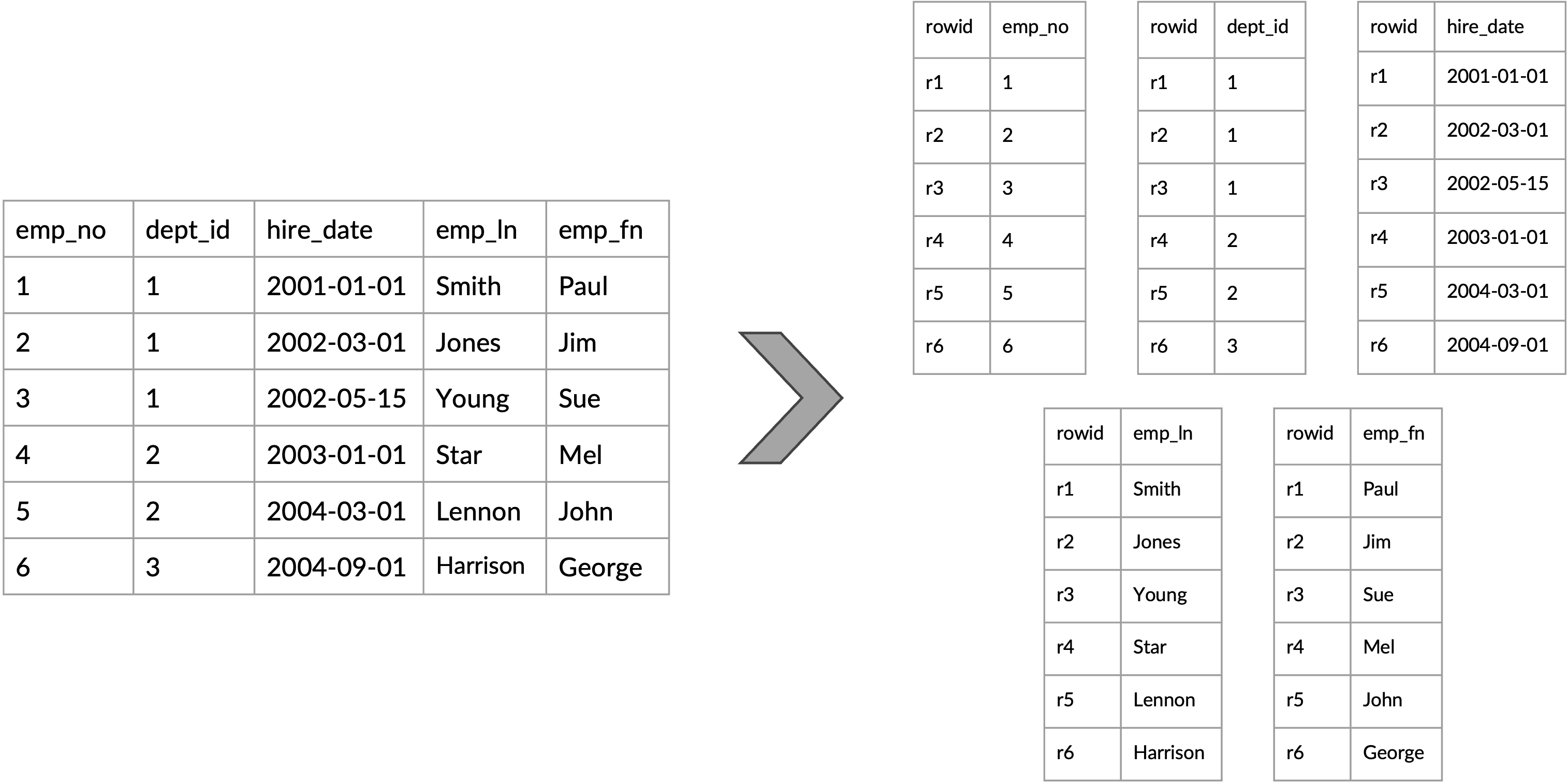
Rysunek 2: Tabela logiczna do fizycznej reprezentacji kolumnowej
Przechowywanie dokumentów (podobne do przechowywania wierszy)
Każdy dokument kolekcji jest przechowywany jako ciągła jednostka. Oznacza to, że wszystkie pola podrzędnych pól pojedynczego dokumentu są przechowywane razem, a następnie pola następnego dokumentu i tak dalej. Takie podejście jest skuteczne w przypadku operacji transakcyjnych, ponieważ pozwala na szybkie wyszukiwanie kompletnych dokumentów. Może być jednak mniej wydajne w przypadku zapytań analitycznych, które uzyskują dostęp tylko do kilku pól w wielu dokumentach, ponieważ odczytywane są również niepotrzebne dane z każdego dokumentu.
W przypadku modelu danych JSON (dokumentu), zazwyczaj mają Państwo więcej pól w każdym dokumencie w porównaniu do pojedynczego wiersza w tabeli relacyjnej. Jednak w przypadku obciążeń analitycznych każde zapytanie nadal odczytuje kilka pól z każdego dokumentu. Potencjalne korzyści płynące z przechowywania danych w kolumnach dla magazynu dokumentów są więc jeszcze większe niż w przypadku relacyjnych baz danych. Nie jest to jednak łatwe do wdrożenia! W płaskich tabelach relacyjnych, gdzie schematy są dobrze zdefiniowane, a typy kolumn są znane a priori, techniki używane do przechowywania i wyszukiwania danych w takich tabelach są dobrze znane. Jednak wdrożenie silnika przechowywania danych w kolumnach dla magazynu dokumentów JSON jest trudne, ponieważ wiele rzeczy, które sprawiają, że JSON jest idealny dla nowoczesnych aplikacji, utrudnia przechowywanie danych w kolumnach! Oto najważniejsze powody:
- Elastyczność schematu
- Zagnieżdżone i złożone struktury
- Obsługa typów niejednorodnych
- Dynamiczne zmiany schematu
- Wyzwania związane z kompresją i kodowaniem
Przyjrzyjmy się pokrótce każdemu z tych wyzwań:
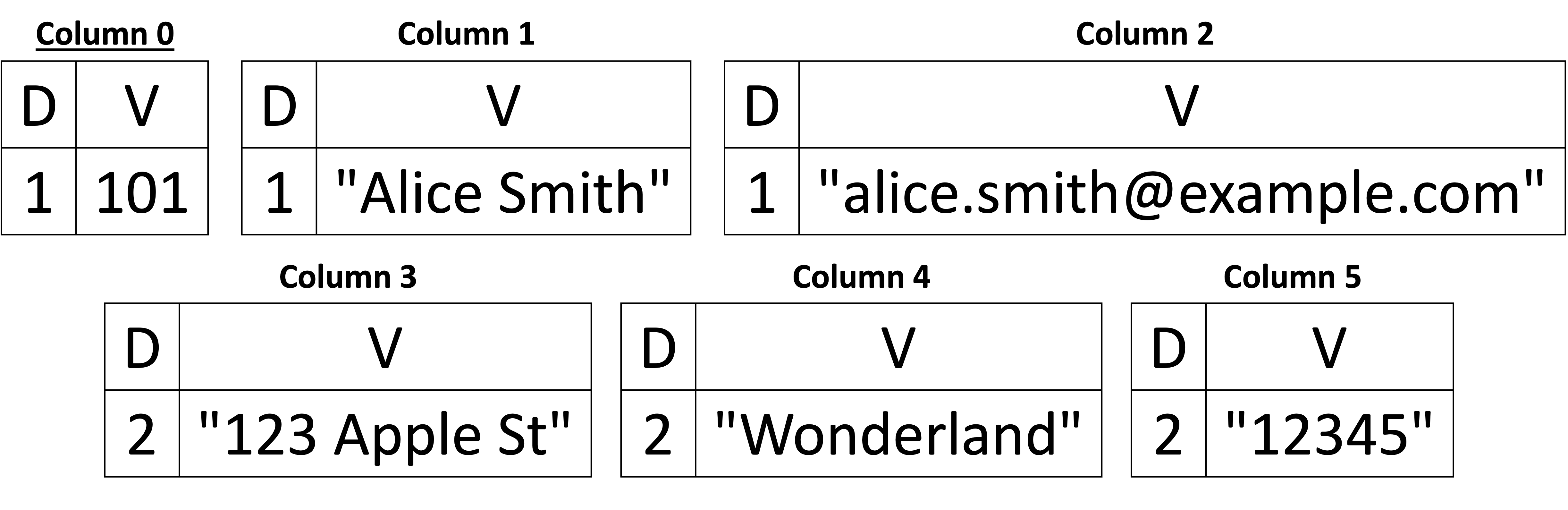
- Elastyczność schematu: JSON nie posiada schematu, co oznacza, że każdy dokument sam się opisuje i może mieć inną strukturę z różnymi polami. Ta elastyczność wyraźnie kontrastuje ze sztywnym, predefiniowanym schematem tradycyjnych relacyjnych baz danych. W modelu JSON dokumentów klientów jeden rekord może mieć pole adresu, podczas gdy inny może go nie mieć, w odrębnej podstrukturze, jak w przykładzie pokazanym poniżej. W kolumnowej bazie danych ta nieprzewidywalność utrudnia zdefiniowanie spójnej struktury kolumn.
{
"customer_id": 101,
"name": "Alice Smith",
"email": "alice.smith@example.com",
"address": {
"street": "123 Apple St",
"city": "Wonderland",
"zip": "12345"
}
}
{
"customer_id": 102,
"name": "Bob Jones",
"email": "bob.jones@example.com"
// Note: No address field
}
{
"customer_id": 103,
"name": "James Brown",
"email": "james.brown@example.com",
"address": {
"street": "Kenmare House, The Fossa Way",
// First appearance of county
"county": "County Kerry",
// postcode instead zip
"postcode": "V93 A0XH",
// First appearance of country
"country": "Ireland"
}
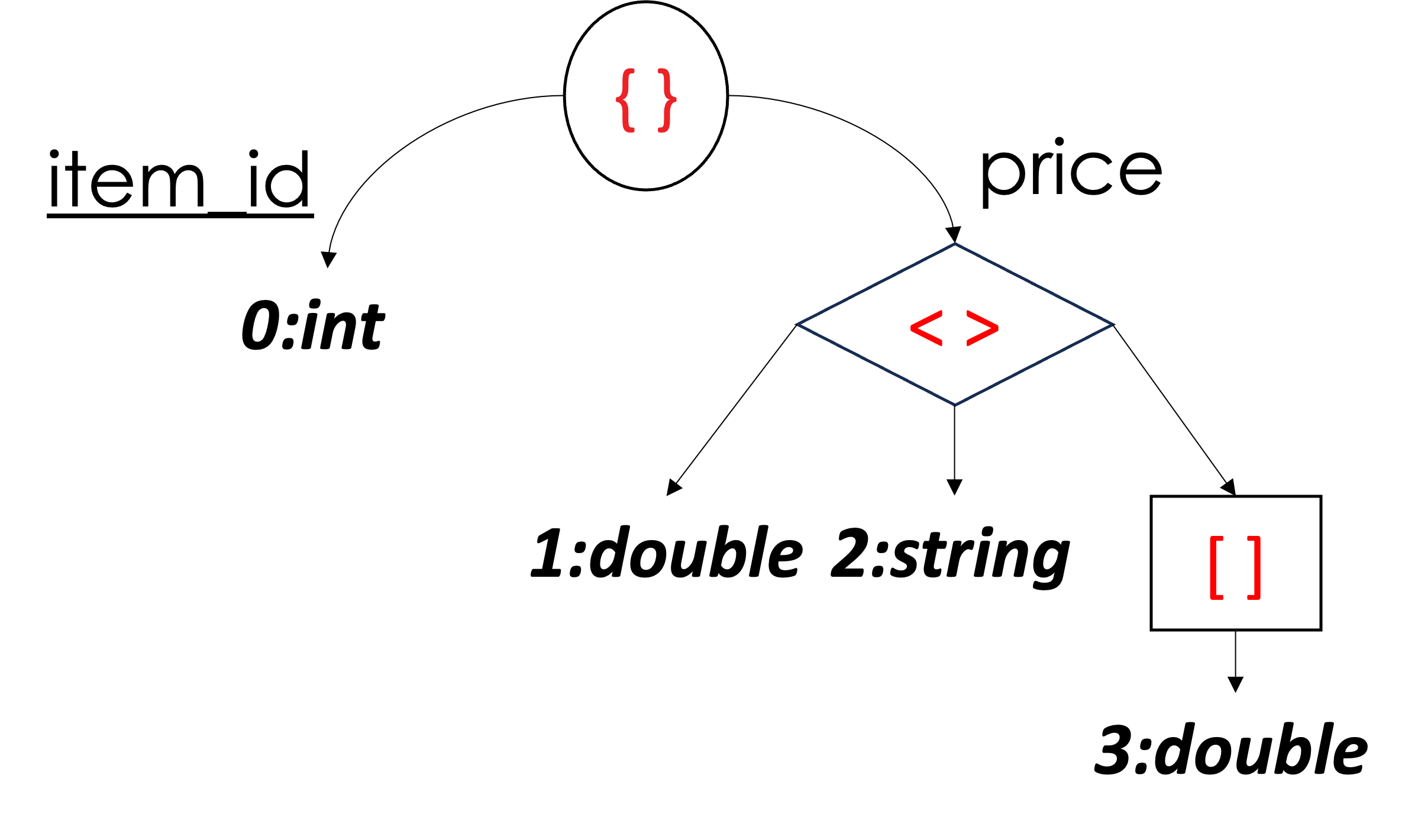
}- Zagnieżdżone i złożone struktury: JSON obsługuje dowolnie zagnieżdżone struktury, takie jak obiekty wewnątrz tablic wewnątrz obiektów. Przechowywanie kolumnowe zazwyczaj działa najlepiej z płaskimi, tabelarycznymi danymi, a mapowanie tych złożonych, hierarchicznych struktur na kolumny może być niezwykle złożone. Jak w przykładzie pokazanym poniżej, pojedynczy JSON zamówienia dokument może zawierać listę pozycji, a każdy element może mieć swoje własne właściwości. Zwykłe spłaszczenie tego do kolumn byłoby wyzwaniem i mogłoby prowadzić do ogromnej liczby rzadkich kolumn. W naszym przykładzie poniżej, uporządkowany element z atrybutem item_id = 1001 jest jedynym z odpowiednim kodem promocyjnym, a zatem brakuje go (podobnie jak NULL w relacyjnych bazach danych) we wszystkich innych pozycjach.
{
"order_id": 5002,
"customer_id": 101,
"date": "2023-11-24",
"items": [
{
"item_id": 1001,
"quantity": 1,
"purchase_price": 1200.00,
// The only item that has applicable promo code
"promo": "BLACK-FRIDAY"
},
{
"item_id": 1002,
"quantity": 1,
"purchase_price": 30.00
}
]
}
{
"order_id": 5003,
"customer_id": 103,
"date": "2023-02-15",
"items": [
{
"item_id": 1003,
"quantity": 1,
"purchase_price": 80.00
},
{
"item_id": 1004,
"quantity": 2,
"purchase_price": 300.00
},
{
"item_id": 1005,
"quantity": 1,
"purchase_price": 99.00
}
]
}- Obsługa typów heterogenicznych: Wartości JSON mogą być różnych typów (np. ciągi znaków, liczby, wartości logiczne, a nawet typy złożone, takie jak obiekty i tablice). W pojedynczym polu w różnych dokumentach typ danych może się różnić, podczas gdy kolumnowe relacyjne bazy danych, a nawet kolumnowe formaty plików zwykle wymagają, aby wszystkie dane w kolumnie były tego samego typu. Jeśli pole “cena” jest czasami przechowywane jako ciąg znaków (“10,99”), a innym razem jako liczba (10,99) lub nawet jako tablica ([10.99, 11.99]) (zakładając przechowywanie wszystkich cen sezonowych), komplikuje to proces przechowywania i pobierania danych ze źródła, które przechowuje takie dane w formacie kolumnowym, gdzie oczekuje się, że typy danych będą jednolite.
{
"item_id": 3003,
"price": 10.99
}
{
"item_id": 3004,
"price": "10.99"
}
{
"item_id": 3005,
"price": [10.99, 11.99]
}
{
"item_id": 3006,
// price is missing (perhaps indicating unavailable or unknown price)
}- Dynamiczne zmiany schematu: Ponieważ JSON nie posiada schematu, struktura danych może zmieniać się w czasie. Ta elastyczność jest jedną z zalet JSON dla nowoczesnych aplikacji. Może to być problematyczne w przypadku kolumnowych relacyjnych baz danych, w których schematy nie zmieniają się często. Jednak w bezschematycznych magazynach dokumentów dodawanie nowych pól lub nawet zmiana istniejących pól po prostu działa. Przykładowo, aplikacja może zacząć przechwytywać dodatkowe dane użytkownika, takie jak adresy klientów, lub zmienić cenę z jednego typu danych na inny. W relacyjnej kolumnowej bazie danych wymagałoby to dodania nowej kolumny, co może być stosunkowo ciężką operacją (szczególnie w hurtowniach danych) lub nawet niemożliwe w przypadku zmiany typu danych pola.
| Dodanie nowego pola (pól): Klienci | Zmiana typu danych pola: Pozycje | |
|---|---|---|
| Przed Upsert |
|
|
| Po Upsert |
|
|
- Wyzwania związane z kompresją i kodowaniem: Jedną z zalet przechowywania kolumnowego w relacyjnej bazie danych jest możliwość korzystania z bardzo wydajnych schematów kodowania, ponieważ wartości tego samego typu i tej samej domeny są przechowywane przylegle, a schematy są przechowywane oddzielnie od danych. Zróżnicowany i złożony charakter JSON może jednak utrudniać ich efektywne zastosowanie. W przypadku kolumny czysto liczbowej proste techniki kodowania i kompresji mogą być bardzo skuteczne. Jeśli jednak kolumna łączy ciągi znaków, liczby, zera i braki (a nawet tablice i obiekty) w nieprzewidywalny sposób, znalezienie skutecznej strategii kodowania staje się znacznie bardziej skomplikowane lub nawet niemożliwe.
Kolumnowy silnik pamięci masowej w Capella Columnar
Do przechowywania danych w kolumnach Capella Columnar wykorzystuje rozszerzoną wersję technik i podejść opisanych w tym dokumencie technicznym: Formaty kolumnowe dla bezschematycznych magazynów dokumentów opartych na LSM. Więcej szczegółów znajdą Państwo w pracy doktorskiej Waila Alkowaileeta, W kierunku magazynów dokumentów zoptymalizowanych pod kątem analityki. Techniki te zostały pierwotnie zaimplementowane dla Apache AsterixDB i są obecnie częścią Couchbase Capella Columnar.
Przegląd pamięci masowej
Technologia kolumnowa w Capella Columnar rozwiązuje ograniczenia baz danych przechowujących dokumenty do analizy dużych ilości danych częściowo ustrukturyzowanych ze względu na ich niezdolność do efektywnego wykorzystania układów głównych kolumn, które są oczywiście bardziej wydajne w przypadku obciążeń analitycznych. Celem jest zapewnienie wydajnego magazynu kolumn dla JSON przy jednoczesnym zachowaniu wszystkich zalet modelu danych JSON i usprawnieniu przetwarzania zapytań. W tej części artykułu opisujemy ulepszenia i usprawnienia w tych obszarach, aby sprostać opisanym wcześniej wyzwaniom. Proszę zapoznać się z wyżej wymienionymi artykuł oraz teza w celu uzyskania dalszych informacji.
W dalszej części tego artykułu opisano następujące aspekty nowej oferty Capella Columnar Service:
- Potok pozyskiwania i kolumnizacji danych JSON
- Kolumnowa reprezentacja JSON
- Fizyczny układ kolumnowy pamięci masowej
- Przetwarzanie zapytań dla kolekcji kolumnowych
Potok pozyskiwania i kolumnowania danych JSON
Capella Columnar może pozyskiwać dane z różnych źródeł danych, takich jak Capella Data Service, lub z innych źródeł zewnętrznych, takich jak inne magazyny dokumentów i relacyjne bazy danych. Silnik pamięci masowej Capella Columnar jest silnikiem opartym na drzewie LSM (Log-structured Merge tree) i działa tak, jak pokazano na rysunku 3. Kiedy dokumenty JSON docierają do Capella Columnar z jednego z obsługiwanych źródeł, dokumenty te są wstawiane do komponentu pamięci (znanego również w literaturze jako memtable), który jest B+-drzewo przechowywane w całości w pamięci. Po zapełnieniu komponentu w pamięci, wstawione dokumenty są zapisywane na dysku (poprzez operację spłukiwania) do komponentu na dysku (znanego również w literaturze jako SSTable), który jest B+-fragment drzewa przechowywany w całości na dysku. Zwolniony element pamięci może być następnie ponownie wykorzystany dla nowej partii dokumentów.
Wsadowy charakter LSM daje możliwość “przemyślenia”, w jaki sposób dokumenty w komponencie w pamięci powinny być zapisywane i przechowywane na dysku. W Capella Columnar korzystamy z tej okazji, aby (1) wywnioskować schemat danych i (2) wyodrębnić wartości z wprowadzonych dokumentów JSON i zapisać je w kolumnach – oba wykonywane przez Columnar Transformer, jak pokazano poniżej na rysunku 3. Wywnioskowany schemat jest używany do identyfikacji kolumn, które pojawiły się w tych dokumentach – więcej na ten temat zostanie omówione później. Proszę zauważyć, że Capella Columnar wykonuje zarówno (1), jak i (2) jednocześnie (tj. w jednym przebiegu na każdym przepłukanym dokumencie JSON). Po zakończeniu operacji spłukiwania wywnioskowany schemat jest utrwalany w nowo utworzonym komponencie LSM na dysku, aby można go było pobrać w razie potrzeby.
![]()
Rysunek 3: Przepływ pracy pozyskiwania danych
Kolumnowa reprezentacja JSON w Capella Columnar
Teraz, gdy wiemy, że mamy możliwość (1) wnioskowania o schemacie i (2) kolumnizacji pozyskanych dokumentów JSON, główne pytanie brzmi: w jaki sposób możemy reprezentować te pozyskane dokumenty JSON jako kolumny, a także umożliwić ich przechowywanie, aktualizację i pobieranie – biorąc pod uwagę pięć wyzwań narzuconych przez model danych JSON?
Capella Columnar reprezentuje przyjmowane dokumenty JSON przy użyciu podejścia opisanego w artykule ten artykuł, który rozszerza format Dremel (wprowadzony przez Google w artykule Dremel: Interaktywna analiza zbiorów danych w skali internetowej), aby sprostać tym pięciu wyzwaniom. Warto zauważyć, że Apache Parquet jest implementacją open-source pełnego schematu formatu Dremel, a zatem bez naszych rozszerzeń nie byłoby możliwe użycie Apache Parquet (w obecnej postaci) w bazie danych dokumentów. Poniżej opisujemy, w jaki sposób Capella Columnar reprezentuje wprowadzone dokumenty JSON w układzie kolumnowym przy użyciu naszego rozszerzonego formatu Dremel.
Zacznijmy od prostego przykładu reprezentacji pierwszego dokumentu Klienci Dokument JSON z Listingu 1, który pokazano poniżej na Rysunku 4.
|
Dokument |
Inferred Schema |
|---|---|
|
 |
| Kolumny danych | |
 |
|
Rysunek 4: Przedstawienie pierwszego Klienci Dokument JSON jako kolumny
Po pierwsze, widzimy, że schemat jest strukturą drzewa, która opisuje, co znajduje się w dokumencie Klienci document. Zaczynając od korzenia drzewa (obiektu JSON lub dokumentu), widzimy, że ma ono cztery elementy podrzędne. Dzieci korzenia reprezentują pola korzenia, którymi są customer_id, nazwa, e-mail, oraz adres. Proszę zauważyć, że adres jest również obiektem (lub dokumentem podrzędnym) zagnieżdżonym w dokumencie głównym, a obiekt adres ma troje dzieci: ul., miasto, oraz zip. Widzimy, że wartości skalarne są liśćmi struktury drzewa schematu – zarówno dla dokumentu głównego, jak i dokumentu podrzędnego adresu. Każda wartość skalarna ma przypisany tak zwany “indeks kolumny”. Na przykład, liść 0:int mówi nam, że pole customer_id – klucz podstawowy kolekcji (PK) – jest liczbą całkowitą i ma przypisany indeks kolumny 0. Podobnie, 4:string mówi nam miasto wartość w adres jest typu string i ma przypisany indeks kolumnowy 4. Ze schematu możemy wywnioskować, że mamy sześć kolumn (tj. sześć liści, a każdy liść ma przypisany indeks kolumny z zakresu [0, 5]).
Tak więc schemat daje nam opis struktury dokumentu i typów wartości, ale nie samych wartości. W Capella Columnar wartości dokumentów są przechowywane oddzielnie od schematu jako kolumny. Rysunek 4 przedstawia “kolumny danych” (dokładnie sześć kolumn), a każda kolumna jest reprezentowana jako dwa wektory (przedstawione na rysunku jako tabela z dwiema kolumnami dla łatwiejszej interpretacji przez czytelnika) o nazwach “D” i “V”. Wektor “D” w każdej kolumnie jest tym, co nazywamy (jak w Dremel) Dwektor na poziomie definicji, a “V” to wektor Vwektor wartości. Jak można wywnioskować z rysunku, wektory wartości przechowują rzeczywiste wartości z dokumentu JSON. Z drugiej strony, wektory poziomów definicji są używane jako “metawartości” w celu określenia, czy dana wartość jest obecna, czy nie (tj. NULL lub brak). Weźmy kolumnę 1, która odpowiada wartości name w naszym przykładzie. Widzimy, że wartość “Alice Smith” ma poziom definicji równy 1, co mówi nam, że ta konkretna wartość kolumny 1 jest obecna, a powiązana z nią wartość to “Alice Smith”. Weźmy teraz kolumnę 4, która odpowiada polu miasto w adres pod-dokument. Ma poziom definicji równy 2, a wartość to “Wonderland”. Dlaczego więc poziom definicji wynosi 1 w name i 2 w miasto dokumentu podrzędnego adres? Poziom definicji (jak sama nazwa wskazuje) mówi nam, na jakim poziomie (zagnieżdżenia) pojawiła się wartość, biorąc pod uwagę wywnioskowaną definicję schematu tej konkretnej wartości. Tak więc name jest elementem podrzędnym dokumentu głównego. Zatem jest to jeden poziom od korzenia, podczas gdy miasto jest dzieckiem adresu dokumentu podrzędnego, a zatem jest to dwa poziomy od korzenia (korzeń → nazwa vs. korzeń → adres → miasto).
Aby lepiej zrozumieć obsługę brakujących wartości, dodajmy teraz następujący dokument:
|
Dokument |
Kolumny danych |
|---|---|
|
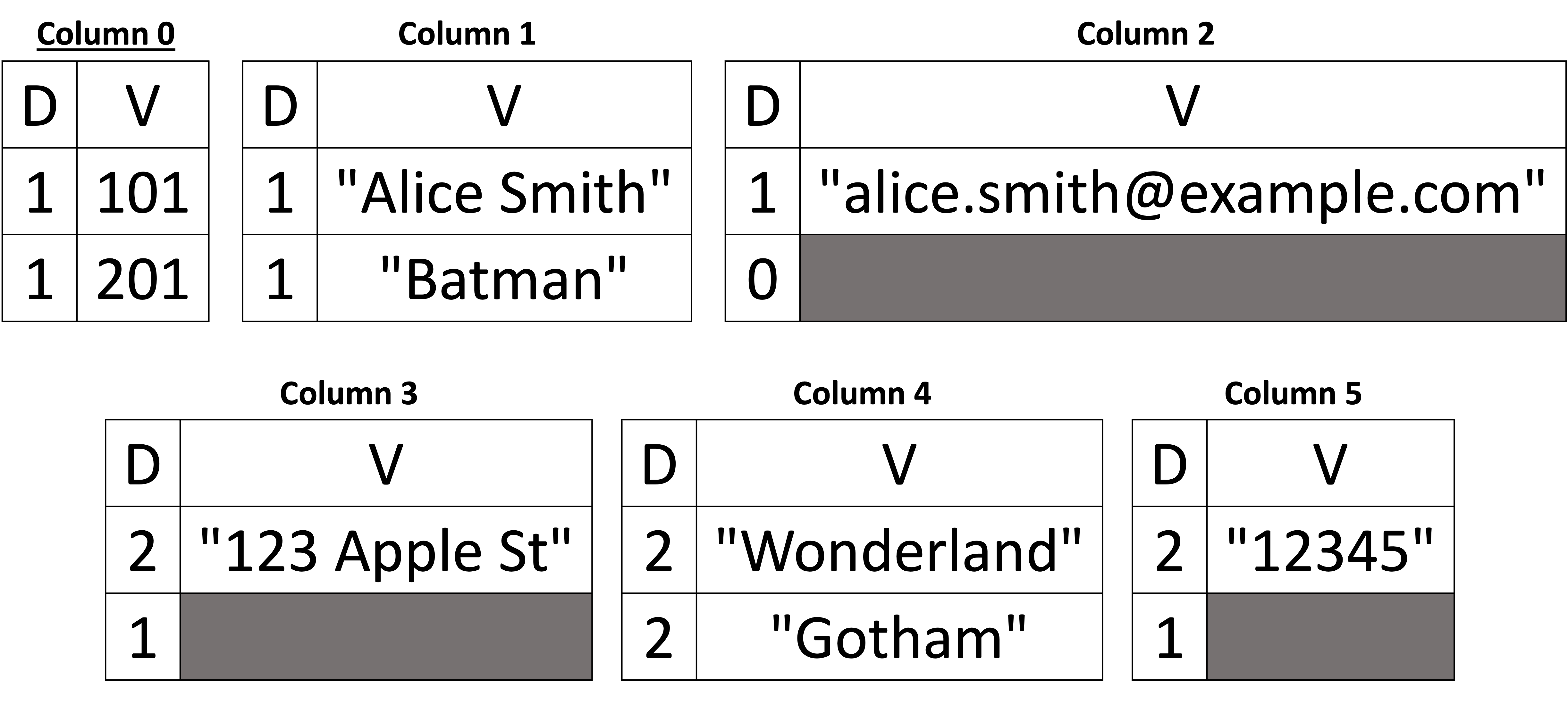 |
Rysunek 5: Obsługa brakujących wartości
Schemat jest taki sam, ponieważ pola, które pojawiły się w powyższym dokumencie (Rysunek 5), są podzbiorem pól pierwszego dokumentu pokazanego na Rysunku 4; w związku z tym nie są wymagane żadne zmiany we wnioskowanym schemacie. Przyjrzyjmy się jednak kolumnom danych po dodaniu powyższego dokumentu. Widzimy, że kolumna 1 (nazwa) jest również obecna w drugim dokumencie, a jej wartość to “Batman”. Jednak kolumna 2 ma poziom definicji równy 0 w drugim dokumencie, co mówi nam, że kolumna email brakuje dla tego klienta. Dla tego samego klienta widzimy, że zarówno pole street oraz zip również brakuje, a zatem zarówno kolumna 3, jak i kolumna 5 mają poziom definicji równy 1. Jednak kolumna 4 (miasto) jest obecny (poziom definicji = 2), a wartością jest “Gotham”. W kolumnach 3 i 5 obecny jest podrzędny dokument nadrzędny (tj, adres), ale nie ulica oraz zip wartości. Proszę zauważyć, że posiadanie poziomu definicji równego 1 zarówno w kolumnie 3, jak i kolumnie 5 nie jest wymagane, aby wywnioskować, że nie brakuje adresu. Ponieważ kolumna 4 (miasto) jest obecny, oznacza to, że jego rodzic (adres) jest również obecny. Oznacza to, że zarówno kolumna 3, jak i kolumna 5 mogą mieć poziom definicji równy 0, a my nadal możemy przywrócić dokument do jego pierwotnej postaci bez żadnych strat. Dlatego możemy powiedzieć, że brakuje samego adresu, jeśli poziomy definicji dla ulicy, miasta i kodu pocztowego są równe 0.
Jak wyjaśniono powyżej, poziom definicji określa, czy wartość jest obecna, czy nie. Służy on jednak innemu celowi w przypadku kolumn kluczy głównych (PK). Poziom definicji w PK odróżnia rzeczywisty dokument JSON od wpisu antymaterii (lub nagrobka). Ponieważ nie można pominąć pól PK, poziomy definicji wartości PK służą do odróżnienia wpisów antymaterii, które nie mają wartości w żadnej z kolumn niebędących kluczami, od rzeczywistych dokumentów JSON (nieantymaterii), które mogą mieć dowolną liczbę wartości w kolumnach niebędących kluczami. Pomijamy tutaj szczegóły techniczne dotyczące obsługi wpisów antymaterii (szczegóły znajdują się w sekcji paper). Należy jednak zauważyć, że zdolność do obsługi wpisów antymaterii pozwala Capella Columnar na wykonywanie usuwania i wstawiania do kolekcji przechowywanych przy użyciu tej reprezentacji kolumnowej.
Elastyczność schematu i dynamiczne zmiany schematu
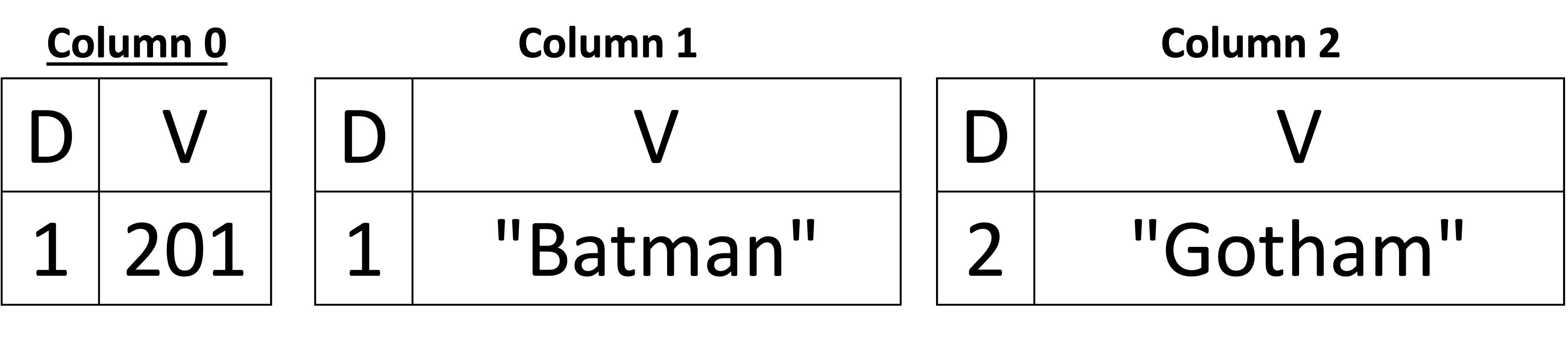
W poprzednim przykładzie pokazaliśmy, że w dowolnym dokumencie może brakować pól (tj. są one opcjonalne) – z wyjątkiem kluczy podstawowych. Ponadto w poprzednim przykładzie schemat pierwszego dokumentu był nadzbiorem schematu drugiego dokumentu. W związku z tym schemat nie musiał się zmieniać po dodaniu drugiego dokumentu. Aby jednak zobaczyć, jak schemat może ewoluować, odwróćmy kolejność przetwarzania i dodawania dwóch dokumentów, abyśmy mogli zaobserwować przypadek wnioskowania o nowych kolumnach w naszej reprezentacji kolumnowej. Poniżej, na rysunku 6, widzimy, że pierwszy wywnioskowany schemat zawiera tylko trzy kolumny: customer_id, nazwa, oraz miasto (w dokumencie podrzędnym adres) i widzimy przypisane im indeksy kolumn wynoszące odpowiednio 0, 1 i 2. Po dodaniu drugiego dokumentu dodawane są trzy dodatkowe kolumny, a mianowicie email w dokumencie głównym i ul. oraz zip w adres . Proszę zauważyć, że nowo dodane kolumny mają indeksy kolumn 3, 4 i 5 dla email, ul., oraz zip, odpowiednio. Poziomy definicji są dokładnie takie same jak w poprzednim przykładzie. Jedyną zmianą między tymi dwoma przykładami (tj. na rysunku 6 i na rysunku 5) są indeksy kolumn, ale reszta jest taka sama.
| Po dodaniu dokumentu z customer_id: 201 | Po dodaniu dokumentu z customer_id: 101 |
|---|---|
 |
 |
 |
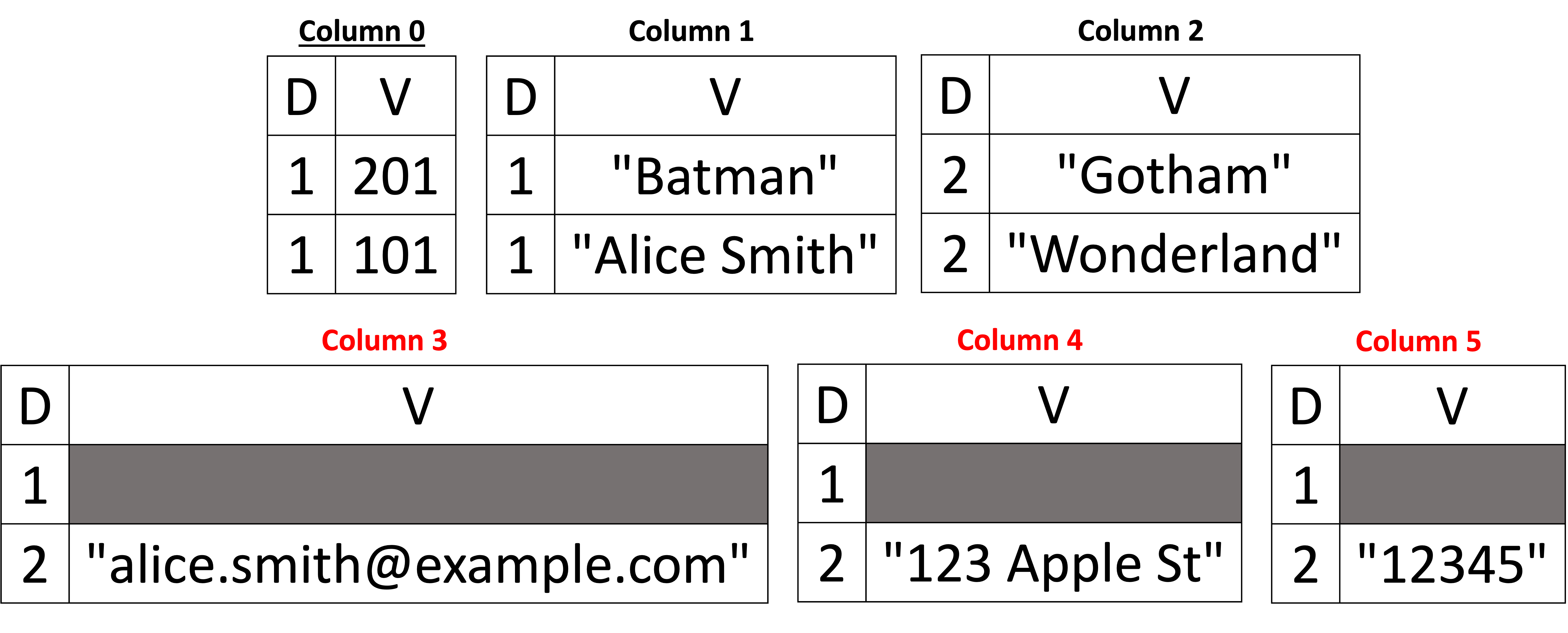 |
Rysunek 6: Obsługa zmian schematu
Warto tutaj zwrócić uwagę na pewien szczegół techniczny. Widzimy, że gdy dodaliśmy nową kolumnę, która należy do pola zagnieżdżonego (na przykład kolumna 5, która odpowiada polu zip), pierwszy poziom definicji wynosi 1, co odpowiada brakującej wartości zip w pierwszym dokumencie. Ale w jaki sposób uzyskaliśmy tę informację (tj. poziom definicji wynosi 1, ale nie 0, gdy dodajemy drugi dokument)? Rodzic może przechowywać listę liczb całkowitych wszystkich poprzednich dokumentów, których adres dokumentu podrzędnego był obecny lub go brakowało (tj. poziomy definicji adresu, które mogą wynosić 0 lub 1 we wszystkich poprzednich dokumentach). Gdy dodawana jest nowa kolumna, najpierw ustawiamy poziomy definicji podrzędnego dokumentu nadrzędnego address do nowo utworzonej kolumny. W naszym przykładzie address był obecny w dokumencie z customer_id = 201. W związku z tym adres ma poziom definicji 1. Kiedy utworzono kolumnę 5, najpierw dodaliśmy poziom definicji 1, aby powiedzieć, że adres był obecny w poprzednim dokumencie, ale brakowało wartości zip. Utrzymywanie tej listy w każdym zagnieżdżonym węźle jest opcjonalne z powodu wyjaśnionego powyżej (możemy po prostu dodać 0 dla każdej nowo utworzonej kolumny). Jednak utrzymanie tej listy w pamięci może być stosunkowo tanie przy użyciu odpowiedniej struktury danych. W Capella Columnar zaimplementowaliśmy prostą strukturę danych, która wykorzystuje reparatywną naturę poziomów definicji – a nasze eksperymenty wykazały, że ma ona znikomy ślad pamięciowy. Dodatkowo, ta lista liczb całkowitych jest ograniczona liczbą dokumentów na każdej fizycznej stronie, która jest ograniczona do maksymalnie 15 000 (więcej szczegółów na temat tego limitu można znaleźć w artykule). Utrzymywanie rzeczywistych poziomów definicji węzłów nadrzędnych upraszcza algorytm składania dokumentów JSON (stąd lepsza i łatwiejsza konserwacja kodu składania dokumentów). Dlatego zdecydowaliśmy się to zrobić w Capella Columnar.
Obsługa tablic JSON
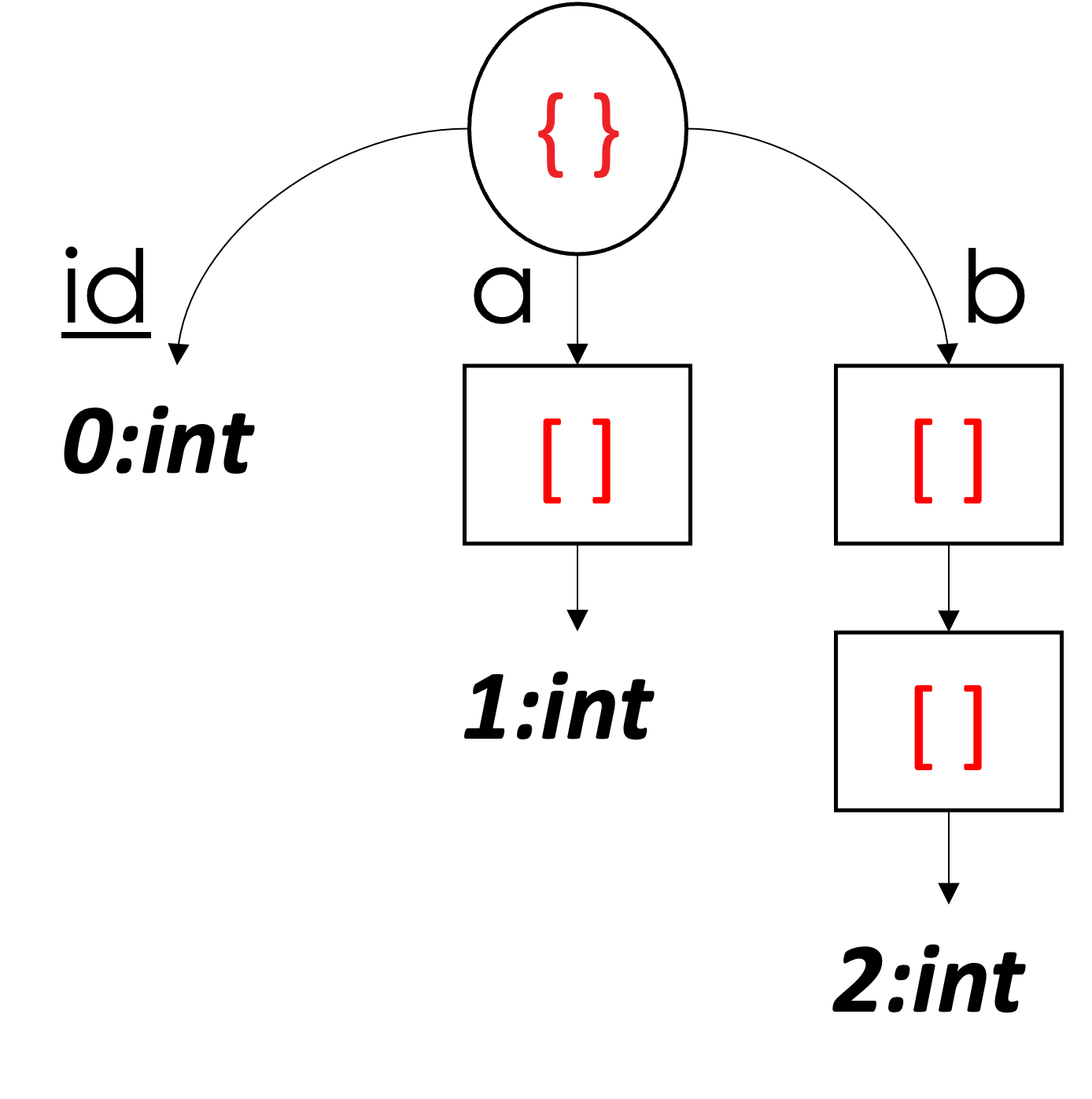
W poprzednich przykładach zajmowaliśmy się obiektami JSON (dokumentami i dokumentami podrzędnymi). Następnie skupimy się na obsłudze tablic JSON. Zacznijmy od prostego przykładu pokazanego poniżej na rysunku 7. W tym przykładzie mamy trzy dokumenty, a ze schematu wynika, że wszystkie dokumenty mają pole id, który jest kluczem podstawowym. Pierwsze dwa dokumenty mają dwa dodatkowe pola, a oraz b, gdzie a jest tablicą liczb całkowitych i b jest tablicą tablic liczb całkowitych. W ostatnim dokumencie, zarówno a oraz b brakuje.
Zaczynając od idwidzimy, że jego wartości są przechowywane w kolumnie 0. W tym przykładzie oznaczyliśmy kolorami poziomy definicji, abyśmy mogli wizualnie powiązać wartość w kolumnie z jej dokumentem w taki sposób, że zieloni należą do pierwszego dokumentu, pomarańcze należą do drugiego dokumentu, oraz sky-blues dotyczą trzeciego dokumentu. Stąd ids 1, 2 i 3 w kolumnie 0 należą odpowiednio do pierwszego, drugiego i trzeciego dokumentu.
Następnie kolumna 1 przechowuje wartości całkowite tablicy a dla wszystkich trzech dokumentów. Pytanie brzmi teraz, w jaki sposób możemy określić, która wartość w tej kolumnie należy do którego dokumentu. Korzystając z kodowania kolorami, można zauważyć, że pierwsze cztery wartości należą do pierwszego dokumentu – ale jak maszyna może to ustalić? Widzimy, że tablica a w pierwszym dokumencie zawiera trzy liczby całkowite [1, 2, 3], a każda z nich ma poziom definicji równy 2 (co oznacza, że wartości są obecne – jak widzieliśmy wcześniej), po którym następuje poziom definicji równy 0. W poprzednich przykładach używaliśmy poziomów definicji do określenia, czy wartość jest obecna, czy nie. W tablicach poziomy definicji mają dodatkową rolę, która działa jako ograniczniki tablicy; tak więc po pierwszych trzech poziomach definicji (2, 2 i 2), ostatni poziom definicji (0) jest ogranicznikiem, który mówi nam, że koniec tablicy został osiągnięty, więc następna wartość należy do następnego dokumentu. Proszę zauważyć, że umieściliśmy ‘]’ w wektorze wartości; jest to jednak tylko do celów ilustracyjnych – ograniczniki tablicy nie mają żadnej wartości. Podobnie jak w pierwszym dokumencie, następujące poziomy definicji w kolorze pomarańczowym (2, 2 i 2) wskazują na obecność wartości tablicy a z drugiego dokumentu, a wartości te to [4, 5, 6]. Ponownie, następujący poziom definicji (0) wskazuje koniec tablicy dla drugiego dokumentu. Podążając za ogranicznikiem drugiego dokumentu, widzimy niebieski poziom definicji (0), który odpowiada trzeciemu dokumentowi, w którym brakuje tablicy a. Zatem poziom definicji (0) wskazuje, że w trzecim dokumencie brakuje tablicy a – dlaczego nie jest to ogranicznik, można zapytać? Poziom definicji może być interpretowany jako ogranicznik, jeśli element tablicy jest obserwowany jako obecny a priori; w przeciwnym razie jest to wskazanie brakującej wartości. Innymi słowy, ogranicznik musi być poprzedzony wartością o wyższym poziomie definicji; w przeciwnym razie obserwowany poziom definicji jest wskazaniem brakującej wartości, a nie ogranicznikiem tablicy.
|
Dokumenty |
Inferred Schema |
Kolumny danych |
|
|---|---|---|---|
|
 |
 |
|
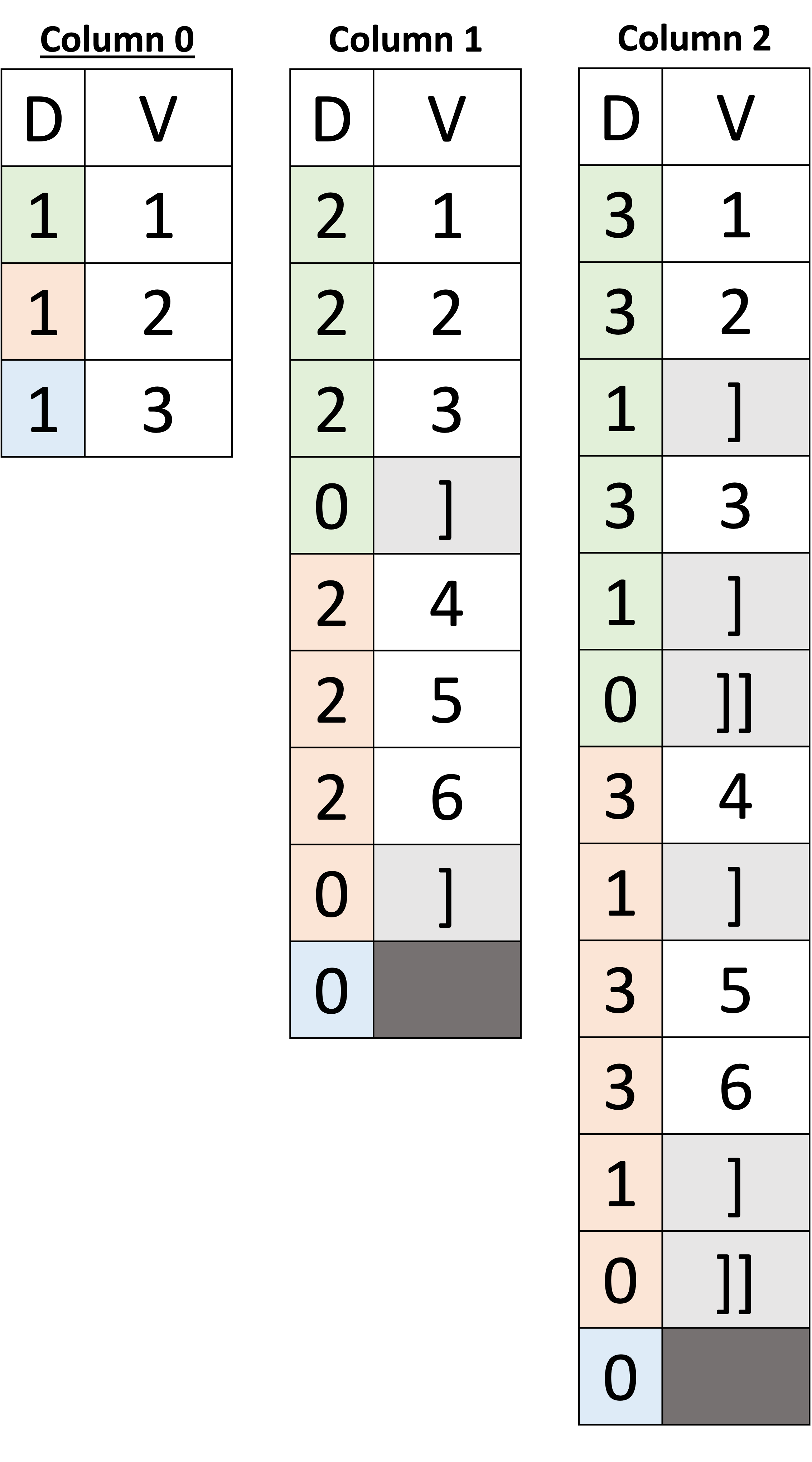
Rysunek 7: Reprezentowanie tablic JSON
Zobaczmy teraz, jak wygląda tablica tablic (np. b na rysunku 7 powyżej). Wystarczy poszukać ograniczników w kolumnie 2, które są oznaczone jako ‘]’ dla wewnętrznych i ‘]]’ dla outer, widzimy, że istnieją dwa ograniczniki z dwoma różnymi poziomami definicji: 1 i 0. W kolumnie 2 potrzebujemy dwóch ograniczników, aby odróżnić ograniczniki wewnętrzne i zewnętrzne. Na przykład po wartościach [1, 2] w pierwszym dokumencie umieszczony jest ogranicznik o poziomie definicji 1, wskazujący koniec wewnętrznej tablicy, po którym następuje wartość [3], która wskazuje pierwszy element drugiej wewnętrznej tablicy. Po wartości [3], widzimy dwa kolejne ograniczniki z poziomami definicji 1, a następnie 0. Pierwszy ogranicznik z poziomem definicji 1 mówi nam o końcu wewnętrznej tablicy, a na końcu ogranicznik z poziomem definicji 0 mówi nam o końcu tablicy b w pierwszym dokumencie – zatem poniższa wartość należy do drugiego dokumentu. Podobnie dla drugiego dokumentu mamy wartość [4] po której następuje ogranicznik o poziomie definicji 1 – wskazujący, że pierwsza wewnętrzna tablica ma tylko jeden element [4]. Następnie mamy wartości [5, 6] po których następują ograniczniki z poziomami definicji 1, a następnie 0 – wskazujące odpowiednio koniec drugiej tablicy wewnętrznej i tablicy zewnętrznej. Wreszcie, poziom definicji 0 w trzecim dokumencie wskazuje, że tablica b brakuje.
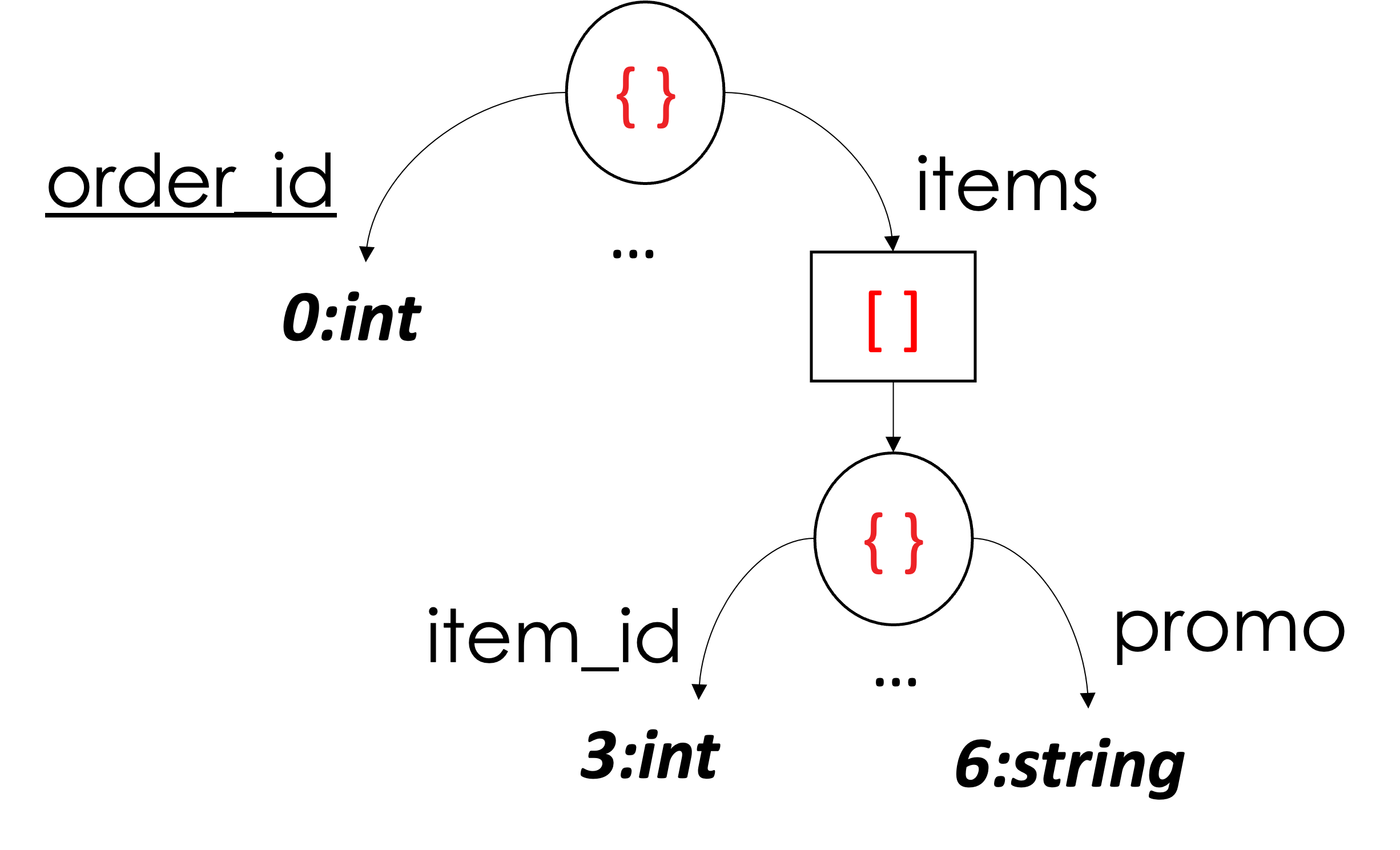
To wszystko, jeśli chodzi o reprezentację tablicy i tablicy tablic wartości skalarnych! Następnie wyjaśnimy reprezentację tablicy obiektów. Zacznijmy od przykładu pokazanego poniżej na Rysunku 8, używając pierwszego dokumentu Orders z Listingu 2. Przykład pokazuje tylko dwie kolumny (z sześciu) i pomija pozostałe (pominięte kolumny można wykorzystać jako ćwiczenie dla czytelnika). Głównie skupimy się na kolumnie 3 i kolumnie 6 (tj, item_id oraz promocja ze schematu). Obie kolumny należą do tej samej tablicy items. Z “perspektywy kolumny” “widzi siebie” jako tablicę wartości skalarnych. Innymi słowy, możemy zobaczyć wartości item_id jako tablica liczb całkowitych [1001, 1002] oraz wartości promocja jako tablica ciągów znaków [“BLACK-FRIDAY,” missing]. Tak więc reprezentowanie tablicy obiektów może być postrzegane jako reprezentowanie dwóch różnych tablic skalarnych o tej samej liczbie elementów. W związku z tym ich ograniczniki będą znajdować się dokładnie w tym samym miejscu. W naszym przykładzie poniżej, ograniczniki tablicy zarówno kolumny 3, jak i kolumny 6 pojawiają się dokładnie w pozycji 3rd pozycji. Kolejnym rozróżnieniem (w porównaniu do rzeczywistej tablicy skalarów) jest to, na którym poziomie definicji wartość jest obecna. Ponieważ obie kolumny są potomkami tej samej tablicy obiektów, poziom definicji równy 3 jest wskazaniem obecnej wartości – ponieważ wartości obu kolumn item_id oraz promocja pojawił się na trzecim poziomie od korzenia. Np. root (0) →\rightarrow→ pozycje (1) →\rightarrow→ obiekt (2) →\rightarrow→ promo (3). Po ponownym złożeniu kolumn do ich pierwotnej postaci widzimy, że w tablicy znajdują się dwa obiekty items, gdzie item_id wynosi 1001 w pierwszym obiekcie i 1002 w drugim. Analogicznie promo jest “BLACK-FRIDAY” w tym samym pierwszym obiekcie i brak w drugim.
|
Dokumenty |
Inferred Schema |
Kolumny danych |
|
|---|---|---|---|
|
 |
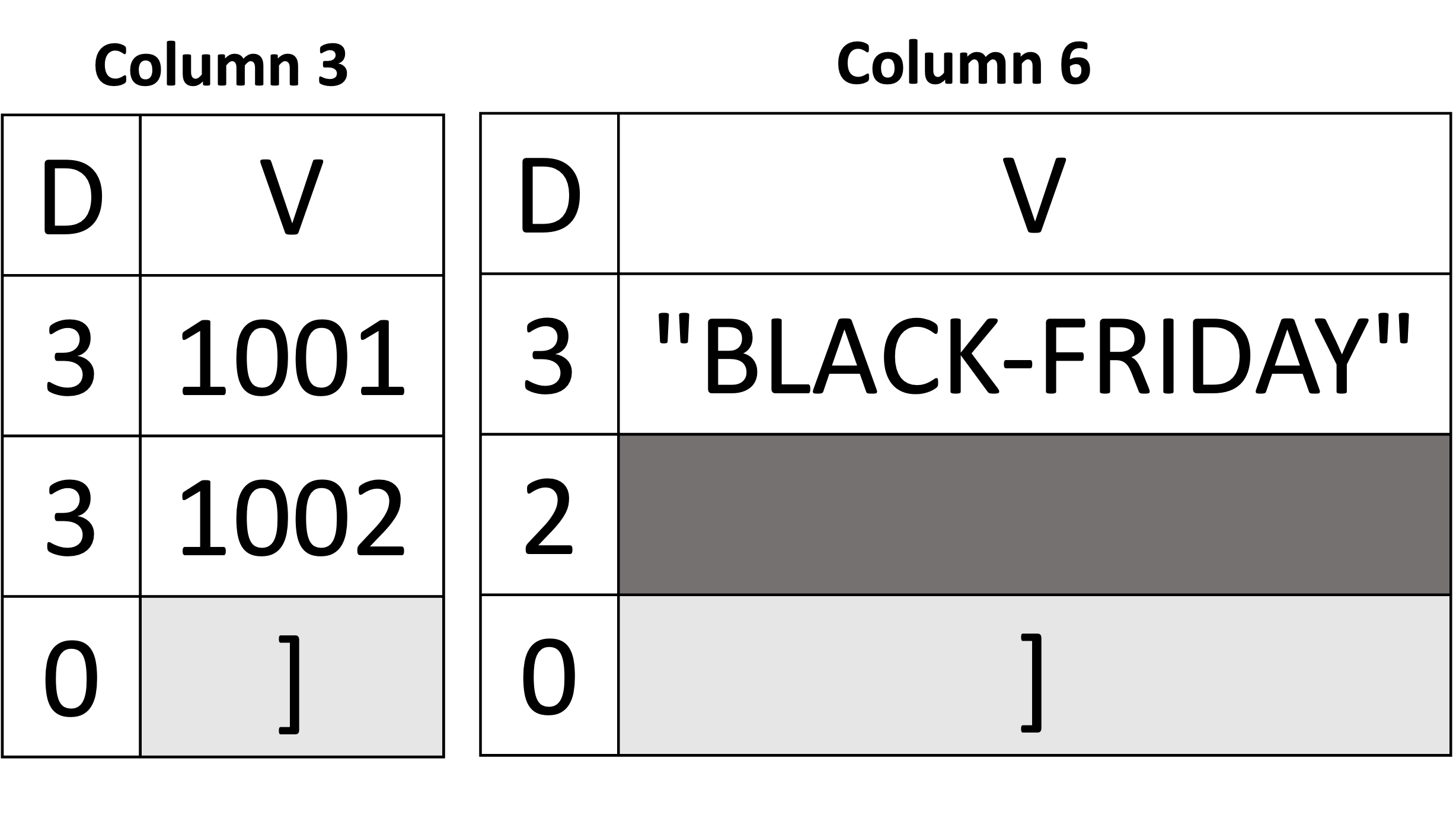 |
|
Rysunek 8: Reprezentowanie tablicy obiektów
Obsługa typów niejednorodnych
W porządku! Do tego momentu wiemy, jak reprezentować obiekty JSON, tablice i ich wartości skalarne jako kolumny oraz jak obsługiwać zmiany schematu (tj. wnioskowanie o nowych kolumnach). Następnie wyjaśnimy, jak obsługiwać heterogeniczne typy danych. Weźmy przykład pokazany poniżej na Rysunku 9, używając dokumentów pokazanych na Listingu 3. Po pierwsze, widzimy, że mamy cztery dokumenty, w których pole price może być wartością podwójną, ciągiem znaków, tablicą wartości podwójnych lub brakującą wartością. Wnioskowany schemat reprezentuje typ ceny jako unię wartości double, string lub array. Węzeł unii w strukturze drzewa schematu jest reprezentowany jako diament na rysunku 9, z trzema elementami podrzędnymi. Typy unii we wnioskowanym schemacie są szczególnym przypadkiem na trzy sposoby. Po pierwsze, związek jest opisem logicznym, który nie może istnieć w rzeczywistym dokumencie. Po drugie, ponieważ jest to opis logiczny, nie wpływa na poziom definicji. Po trzecie, tylko jedna wartość może być obecna w wartości unii, a reszta musi być brakująca – a gdy brakuje wszystkich wartości, wartość unii sama jest wskazywana jako brakująca.
Rozpakujmy to i użyjmy poniższego przykładu, aby zrozumieć te trzy kryteria typu unii. Po pierwsze, widzimy, że kolumna 1, kolumna 2 i kolumna 3 należą do typu price. Podobnie jak w dokumencie podrzędnym, gałęzie związku mogą mieć dowolną liczbę kolumn. Na przykład, kolumna 1 odpowiada podwójnej wersji typu cena, kolumna 2 jest wersją typu string cena, a kolumna 3 to wersja typu tablica podwójna cena. Po uzyskaniu dostępu do wartości price, wszystkie trzy kolumny muszą zostać odczytane w tym samym czasie, aby określić rzeczywistą wartość ceny. Zaczynając od kolumny 1, widzimy, że pierwsza wartość ma poziom definicji równy 1, co wskazuje, że wartość jest obecna, a jej wartość wynosi 10,99. Proszę zauważyć, że posiadanie unii między korzeniem a samą kolumną nie zmieniło wyniku (tj. wynik jest nadal podwójny, jak pokazano w pierwszym dokumencie – 1st kryterium z góry). Proszę również zauważyć, że poziom definicji wynosi 1 (a nie 2), mimo że ścieżka od korzenia do kolumny 1 przechodzi przez węzeł unii (2nd kryterium). Teraz, ponieważ kolumna 1 zawiera wartość, której nie brakuje dla pierwszego dokumentu, brakuje wartości w kolumnach 2 i 3 dla tego samego dokumentu (3rd kryterium). W drugim dokumencie cena jest ciągiem znaków. W związku z tym wartość ciągu jest obecna w kolumnie 2, a brakuje zarówno kolumny 1, jak i kolumny 3. W trzecim dokumencie cena jest tablicą liczb podwójnych, a zatem wartości tablicy dla ceny są przechowywane w kolumnie 3. Wreszcie w czwartym dokumencie pole price nie istnieje. Dlatego poziom definicji wynosi 0 we wszystkich trzech kolumnach – wskazując, że brakuje samej ceny.
| Dokumenty | Inferred Schema | Kolumny danych | |
|---|---|---|---|
|
 |
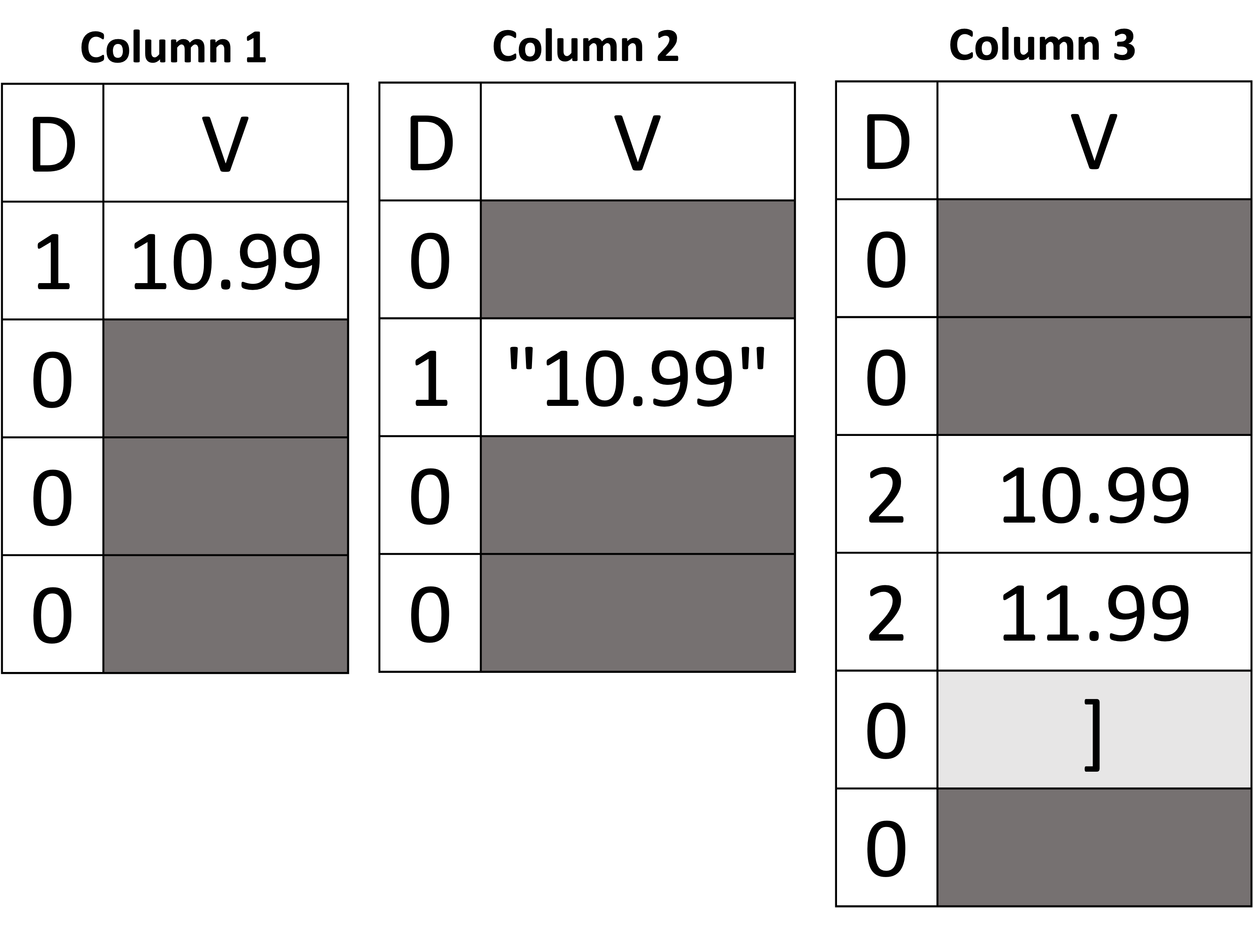 |
|
Rysunek 9: Reprezentowanie typów heterogenicznych
Kodowanie
W tej reprezentacji widzimy, że każda kolumna przechowuje wartości, które są tego samego typu i domeny. Nawet w polach o heterogenicznych typach danych, takich jak cena na rysunku 9, każda fizyczna kolumna jest przeznaczona do przechowywania jednego określonego typu danych cena wartości. Daje nam to możliwość korzystania z tego samego eferentu schematów kodowania używanych w Parquet, obecnie z wyłączeniem kodowania słownikowego (ze względu na wymóg dodatkowych stron pamięci). Planujemy zbadać potencjalne korzyści / wady włączenia kodowania słownikowego w przyszłej wersji.
Widzimy teraz, że Capella Columnar – wykorzystując tę reprezentację kolumnową – jest w stanie obsługiwać elastyczność schematów w modelu danych JSON, a także obsługiwać dynamiczne zmiany schematu podczas przechowywania danych jako kolumn. Reprezentacja jest również w stanie obsłużyć zagnieżdżony charakter modelu danych JSON. Wreszcie, schemat i kolumny mogą dynamicznie dostosowywać się w przypadku napotkania heterogenicznych typów wartości.
Fizyczny układ magazynu kolumnowego
Skoro wiemy już, jak reprezentować dokumenty JSON jako kolumny, pytanie brzmi teraz, jak faktycznie je przechowywać. Wcześniej opisaliśmy metodę ingestion pipeline w Capella Columnar i wyjaśniliśmy, w jaki sposób dokumenty JSON są zapisywane jako kolumny w komponentach LSM na dysku. Zanurzmy się więc i zobaczmy, co znajduje się wewnątrz komponentu na dysku. Komponent na dysku to plik B+-drzewo przechowywane w całości na dysku. W Capella Columnar używamy fizycznego układu pamięci masowej opisanego w dokumencie paper, znany jako AsterixDB Mega Attributes across (lub AMAX), do przechowywania kolumn danych. Rysunek 10 przedstawia układ pamięci masowej. Każdy komponent AMAX LSM jest również komponentem B+-drzewo; jednakże węzły liścia B+-drzewa są węzły mega-liścia, z których każdy może zajmować wiele stron danych zamiast pojedynczej strony danych, jak w oryginalnym B+-drzewo. Na rysunku 10 widzimy, że istnieją cztery węzły mega leaf (cztery strzałki wychodzące z węzłów wewnętrznych), z których każdy zajmuje inną liczbę stron danych. Powiększając jeden z węzłów mega leaf, widzimy, że składa się on z 5 stron danych (od strony 0 do strony 4). Strona 0 jest stroną specjalną, ponieważ przechowuje nagłówek węzła mega leaf zawierający metainformacje o węźle mega leaf. Dodatkowo, strona 0 przechowuje wszystkie klucze główne węzłów mega leaf, a także prefiksy o stałej długości minimalnych i maksymalnych wartości dla każdej kolumny, które można wykorzystać do odfiltrowania węzłów mega leaf podczas odpytywania komponentu LSM (więcej na ten temat później).
Następnie strony od 1 do 4 przechowują dane kolumn (a mianowicie ich poziomy definicji i wartości). Na tym samym rysunku widzimy kilka logicznych reprezentacji zwanych Megapage, z których każda przechowuje dane dla określonej kolumny. Na przykład megapage 1, która zajmuje stronę 1, stronę 2 i część strony 3, przechowuje dane dla pojedynczej kolumny. To samo dotyczy megapage 2, która zajmuje stronę 3 i stronę 4 i przechowuje dane innej kolumny.

Rysunek 10: Fizyczny układ kolumnowej pamięci masowej (AMAX)
Techniki przetwarzania zapytań dla kolekcji kolumnowych
Gdy składnik LSM dla indeksu głównego kolekcji jest odpytywany, każdy węzeł mega-liścia w B+-Drzewo na rysunku 10 powyżej jest przetwarzane (od lewej do prawej). Jednak tylko odpowiednie megapage (lub kolumny) będą dostępne w każdym węźle mega liścia. Na przykład, proszę założyć, że wykonywane jest następujące zapytanie:
SELECT AVG(i.price)
FROM Items iW każdym węźle mega leaf uzyskany zostanie dostęp tylko do strony 0 wraz z mega stroną, która odpowiada kolumnie cena wartość (lub kolumna). Na przykład, powiedzmy, że megapage 2 przechowuje wartość cenę wartości; wówczas dostęp będzie możliwy tylko do strony 0, strony 3 i strony 4, a strony 1 i strona 2 zostaną pominięte – co zmniejszy koszt wejścia/wyjścia.
Jak wspomnieliśmy, strona 0 przechowuje również prefiksy o stałej długości minimalnych i maksymalnych wartości dla każdej kolumny. Powiedzmy, że chcemy uruchomić kolejne zapytanie, takie jak poniższe:
SELECT *
FROM Customers c
WHERE address.city = "Gotham"Kiedy uzyskujemy dostęp do węzła mega leaf, pierwszą stroną, którą czytamy, jest strona 0. Tak więc, przed przeczytaniem innych stron wymaganych przez zapytanie (w przypadku powyższego zapytania są to wszystkie kolumny), używamy filtrów na stronie 0, aby pominąć czytanie mega stron węzła mega leaf, gdy filtry min/max nie mogą spełnić warunku address.city = "Gotham". W ten sposób można pominąć pewną liczbę mega-węzłów liści. Takie filtry mogą znacznie przyspieszyć wykonanie zapytania, jeśli filtr jest selektywny.
Powyższe zapytanie wykonuje SELECT *, co wymaga złożenia dokumentów JSON z powrotem do ich oryginalnej postaci. Koszt montażu – koszt procesora – może być wysoki, jeśli liczba kolumn jest wysoka. Aby uniknąć niepotrzebnych kosztów, Capella Columnar zepchnie predykat klauzuli WHERE do warstwy pamięci masowej. Mówiąc dokładniej, Capella Columnar najpierw odczytuje kolumny wymagane do oceny klauzuli WHERE w zapytaniu i odkłada odczyt innych kolumn. Gdy Capella Columnar znajdzie dokument JSON, który spełnia warunek klauzuli WHERE, odczytuje pozostałe kolumny i składa tylko te dokumenty JSON, które spełniają warunek zapytania. Takie podejście filtrowania drugiego poziomu może działać jako “druga linia obrony”, gdy zakres filtra min/max na stronie 0 jest zbyt “szeroki”. Ponadto koszt ponownego złożenia jest zmniejszony poprzez unikanie składania dokumentów JSON, które nie spełniają warunku wykonanego zapytania.
Wyżej wymienione techniki działają dla różnych zapytań. Na przykład kompilator Capella Columnar może wykrywać i używać filtrów nawet w odniesieniu do elementów tablicy, jak w poniższym zapytaniu:
-- Return the number of orders that contain at least one purchased
-- item with a purchase price less than 10.0
SELECT COUNT(*)
FROM Orders o
-- o.items is an array in Orders (see Listing 2)
-- The filter will be pushed and applied in
-- the storage layer even against array items
WHERE (SOME i IN o.items SATISFIES i.purchase_price < 10.0)Wreszcie, Capella Columnar obsługuje również tworzenie i używanie drugorzędnych indeksów na kolekcjach kolumnowych (tak jak tradycyjnie robi się to w przypadku kolekcji wierszy) w celu dalszej filtracji.
Wnioski
Usługa kolumnowa Couchbase została zaprojektowana w celu zapewnienia podejścia zero-ETL do przenoszenia szerokiej gamy danych na jedną platformę do analizy w czasie rzeczywistym. Model danych JSON, wydajny silnik pamięci masowej oraz kompilator zapytań i procesor zapytań są jednymi z kluczowych składników tego przepisu. Teraz znają Państwo ten sekret!