
Funkcja rurociągi umożliwiają płynne wykonywanie wielu funkcji w sposób sekwencyjny, gdzie dane wyjściowe jednej funkcji służą jako dane wejściowe dla następnej. Takie podejście pomaga w dzieleniu złożonych zadań na mniejsze, łatwiejsze w zarządzaniu kroki, dzięki czemu kod jest bardziej modułowy, czytelny i łatwy w utrzymaniu. Potoki funkcji są powszechnie stosowane w paradygmatach programowania funkcjonalnego do przekształcania danych za pomocą szeregu operacji. Promują one czysty i funkcjonalny styl kodowania, kładąc nacisk na kompozycję funkcji w celu osiągnięcia pożądanych rezultatów.
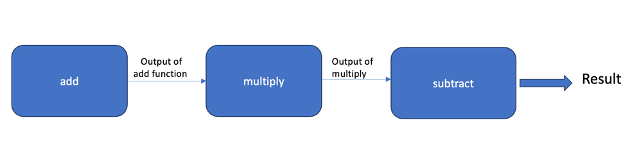
W tym artykule zbadamy podstawy potoków funkcji w Pythonie, w tym jak je tworzyć i efektywnie wykorzystywać. Omówimy techniki definiowania potoków, komponowania funkcji i stosowania potoków w rzeczywistych scenariuszach.
Tworzenie potoków funkcji w Pythonie
W tym segmencie zbadamy dwa przypadki potoków funkcji. W początkowym przykładzie zdefiniujemy trzy funkcje – “dodawanie”, “mnożenie” i “odejmowanie” – z których każda ma na celu wykonanie podstawowej operacji arytmetycznej, jak sugeruje jej nazwa.
def add(x, y):
return x + y
def multiply(x, y):
return x * y
def subtract(x, y):
return x - y
Następnie proszę utworzyć funkcję potoku, która przyjmuje dowolną liczbę funkcji jako argumenty i zwraca nową funkcję. Ta nowa funkcja stosuje kolejno każdą funkcję w potoku do danych wejściowych.
# Pipeline takes multiple functions as argument and returns an inner function
def pipeline(*funcs):
def inner(data):
result = data
# Iterate thru every function
for func in funcs:
result = func(result)
return result
return inner
Proszę zrozumieć działanie funkcji pipeline.
- Funkcja pipeline przyjmuje dowolną liczbę funkcji (*funcs) jako argumenty i zwraca nową funkcję (inner).
- Funkcja wewnętrzna przyjmuje pojedynczy argument (dane) reprezentujący dane wejściowe, które mają być przetwarzane przez potok funkcji.
- Wewnątrz funkcji wewnętrznej pętla iteruje po każdej funkcji na liście funcs.
- Dla każdej funkcji func na liście funcs, funkcja wewnętrzna stosuje func do zmiennej result, która początkowo przechowuje dane wejściowe. Wynik każdego wywołania funkcji staje się nową wartością result.
- Po zastosowaniu wszystkich funkcji w potoku do danych wejściowych, funkcja wewnętrzna zwraca wynik końcowy.
Następnie tworzymy funkcję o nazwie ‘calculation_pipeline‘, która przekazuje ‘add‘, ‘multiply‘ i ‘substract‘ do funkcji potoku.
# Create function pipeline
calculation_pipeline = pipeline(
lambda x: add(x, 5),
lambda x: multiply(x, 2),
lambda x: subtract(x, 10)
)
Następnie możemy przetestować potok funkcji, przekazując wartość wejściową przez potok.
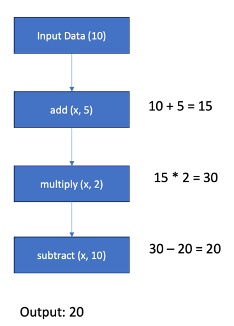
result = calculation_pipeline(10)
print(result) # Output: 20Możemy zwizualizować koncepcję potoku funkcji za pomocą prostego diagramu.
Inny przykład:
def validate(text):
if text is None or not text.strip():
print("String is null or empty")
else:
return text
def remove_special_chars(text):
for char in "!@#$%^&*()_+{}[]|\":;'<>?,./":
text = text.replace(char, "")
return text
def capitalize_string(text):
return text.upper()
# Pipeline takes multiple functions as argument and returns an inner function
def pipeline(*funcs):
def inner(data):
result = data
# Iterate thru every function
for func in funcs:
result = func(result)
return result
return inner
# Create function pipeline
str_pipeline = pipeline(
lambda x : validate(x),
lambda x: remove_special_chars(x),
lambda x: capitalize_string(x)
)
Testowanie potoku poprzez przekazanie poprawnych danych wejściowych:
# Test the function pipeline
result = str_pipeline("Test@!!!%#Abcd")
print(result) # TESTABCD
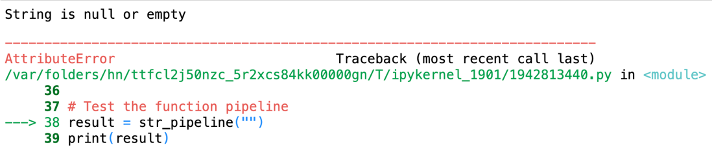
W przypadku pustego lub zerowego ciągu znaków:
result = str_pipeline("")
print(result) # Error
W tym przykładzie utworzyliśmy potok, który rozpoczyna się od sprawdzenia poprawności danych wejściowych, aby upewnić się, że nie są puste. Jeśli dane wejściowe pomyślnie przejdą tę walidację, przechodzą doremove_special_chars‘, a następnie do funkcji ‘Capitalize‘.
Korzyści z tworzenia potoków funkcji
- Potoki funkcji zachęcają do modułowego projektowania kodu poprzez dzielenie złożonych zadań na mniejsze, dające się komponować funkcje. Każda funkcja w potoku koncentruje się na określonej operacji, ułatwiając zrozumienie i modyfikację kodu.
- Łącząc funkcje w sposób sekwencyjny, potoki funkcji promują czysty i czytelny kod, ułatwiając innym programistom zrozumienie logiki i intencji stojących za przepływem pracy przetwarzania danych.
- Potoki funkcji są elastyczne i adaptowalne, umożliwiając programistom łatwe modyfikowanie lub rozszerzanie istniejących potoków w celu dostosowania ich do zmieniających się wymagań.