
Odidentyfikowanie danych jest niezbędnym ćwiczeniem, które muszą wdrożyć instytucje opieki zdrowotnej i organizacje zajmujące się danymi osobowymi. Z pomocą oprogramowania do de-identyfikacji danych, łatwiejsze stało się maskowanie danych osobowych, które mogą narazić daną osobę na ryzyko.
Odidentyfikowanie danych ułatwia ich udostępnianie i ponowne wykorzystywanie stronom trzecim do różnych celów, w tym badań, spisów powszechnych, pobierania próbek itp. Jest to również konieczne w ramach HIPAA prawo do maskowania danych osobowych, a inne ramy, w tym RODO, CCPA i CPRA, nakazują to samo.
Mamy listę najlepszych narzędzi do deidentyfikacji danych, które mogą Państwo wykorzystać w wewnętrznym procesie maskowania danych. Proszę czytać dalej, aby dowiedzieć się więcej.
5 najlepszych narzędzi do deidentyfikacji danych do wyboru
HIPAA i podobne ramy ochrony danych określiły 18 identyfikatorów, które nie powinny być dostępne publicznie. Należą do nich imiona i nazwiska, identyfikatory geograficzne, daty, dane kontaktowe, numery ubezpieczenia społecznego, dokumentacja medyczna, numery kont, adresy IPi kilka innych identyfikatorów.
Narzędzia te pomagają w identyfikacji danych na cztery sposoby: usuwanie, maskowanie, agregacja i pseudonimizacja. Wybierając spośród dostępnych rozwiązań do deidentyfikacji danych, należy upewnić się, że mogą one pomóc w maskowaniu wszystkich identyfikatorów i ograniczeniu nieautoryzowanego dostępu.
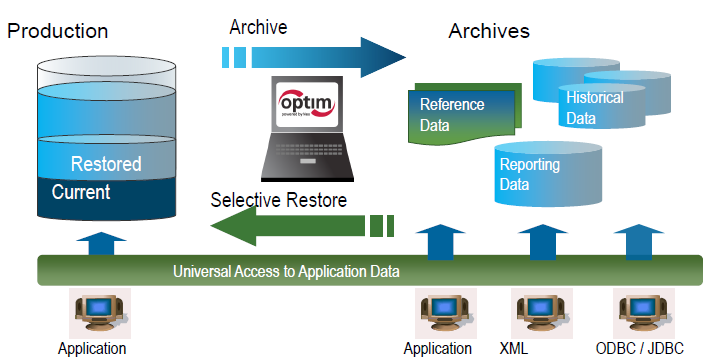
1. IBM InfoSphere Optim
IBM InfoSphere Optim został zaprojektowany specjalnie dla branży opieki zdrowotnej, oferując różnorodne opcje deidentyfikacji danych.
IBM InfoSphere Optim
Główne cechy:
- Łatwe maskowanie skomplikowanych danych: Może łatwo anonimizować dane osobowe, takie jak nazwiska, adresy i dokumentację medyczną, aby chronić prywatność pacjentów.
- Potrafi obsługiwać duże zbiory danych: IBM InfoSphere może usuwać tożsamość z dużych ilości danych, ukrywając poufne informacje za pomocą maskowania i pseudonimizacji.
- Generowanie danych syntetycznych: Może tworzyć sztuczne, ale realistyczne dane do celów badawczych i analitycznych.
Obszary do poprawy
- Interfejs jest dość skomplikowany w nawigacji dla mniej technicznych użytkowników.
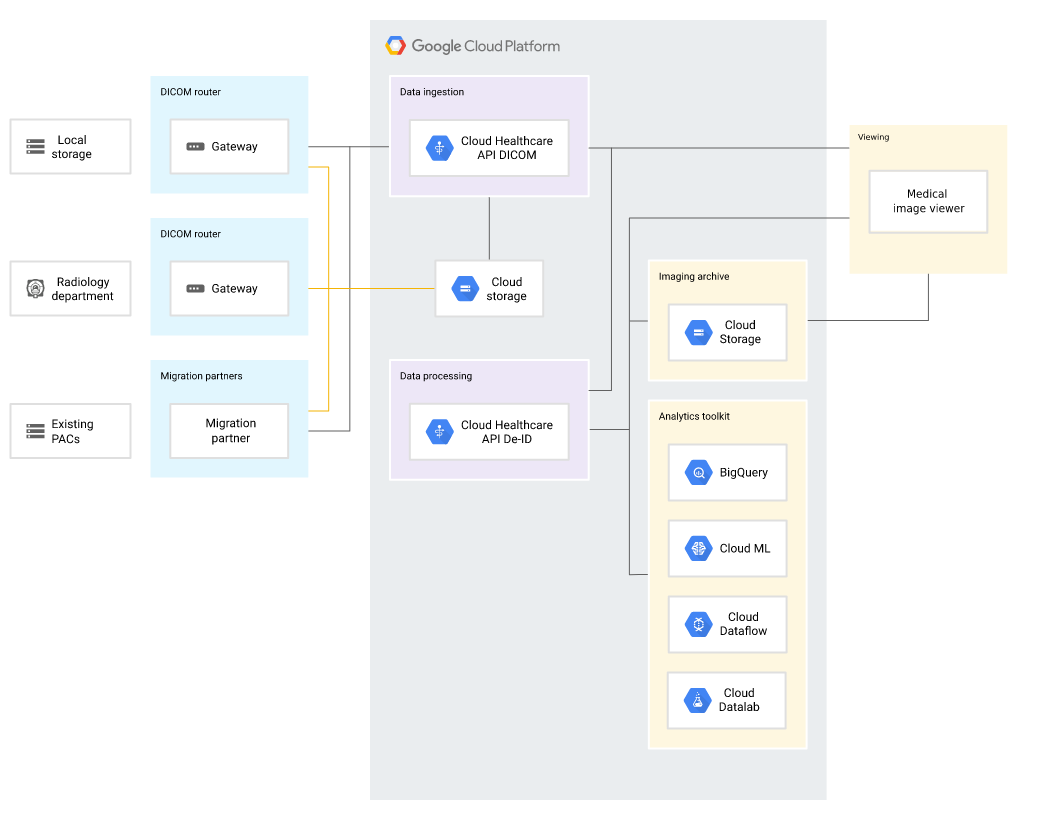
2. Google Healthcare API
Google Healthcare API umożliwia przechowywanie i zarządzanie danymi w Fast Healthcare Interoperability Resources (FHIR), jednocześnie umożliwiając wymianę danych między różnymi systemami opieki zdrowotnej. Ponadto dzięki temu oprogramowaniu do deidentyfikacji danych z obsługą DICOM można zintegrować zbiory danych z usługami Google Cloud w celu szybszej analizy danych.
Google Healthcare API
Główne cechy:
- Elastyczność operacyjna: Google Healthcare API działa w oparciu o infrastrukturę bezserwerową, co ułatwia skalowanie i obsługę dużych ilości danych.
- Deidentyfikacja oparta na sztucznej inteligencji: Wykorzystuje sztuczną inteligencję w opiece zdrowotnej i uczenie maszynowe w celu poprawy wydajności operacyjnej oraz prowadzenia lepszych badań i analiz.
Obszary do poprawy
- Brak dokumentacji: Google nie dostarczyło wystarczającej dokumentacji dotyczącej konfiguracji i uruchamiania, co prowadzi do stromej krzywej uczenia się.
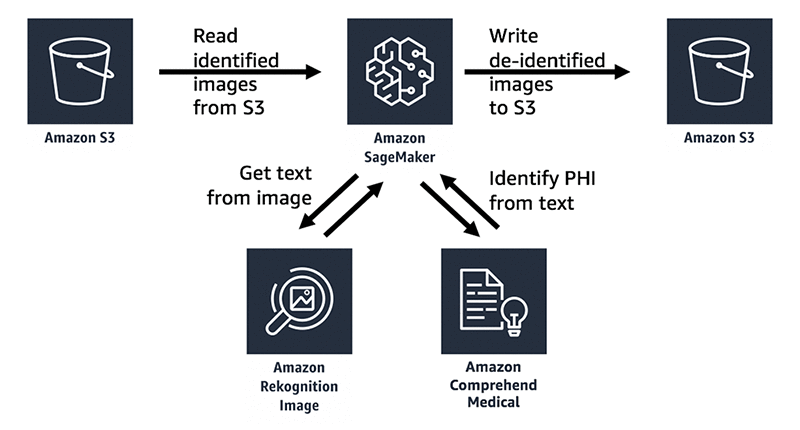
3. AWS Comprehend Medical
To rozwiązanie wykrywa i zwraca przydatne informacje medyczne z nieustrukturyzowanych notatek klinicznych, podsumowań, notatek z przypadków i wyników testów. Aby zidentyfikować chronione informacje zdrowotne (PHI), wykorzystuje możliwości przetwarzania języka naturalnego.
AWS Comprehend Medical
Główne cechy:
- Rozpoznawanie i ekstrakcja: AWS Comprehend Medical kwalifikuje się do HIPAA Możliwości NLP, umożliwiając identyfikację wrażliwych medycznie i osobistych informacji z większą dokładnością. Może również odkrywać połączenia między jednostkami, aby ujawnić wzorce kliniczne i trendy.
- Analiza nastrojów: Może oceniać odczucia pacjentów na podstawie nagrań, notatek i informacji zwrotnych w celu poprawy i personalizacji świadczenia opieki zdrowotnej.
Obszary wymagające poprawy:
- Trudne w użyciu: Interfejs można ulepszyć, aby zapewnić lepsze wrażenia użytkownika.
4. Shaip
Proszę doświadczyć deidentyfikacji danych przez człowieka z Shaip, ponieważ łączy on również AI w opiece zdrowotnej rozwiązania z inteligencją ekspertów. Shaip dostarcza precyzyjne metody deidentyfikacji danych dostosowane do Państwa potrzeb. Zintegruj API Shaip, aby uzyskać dostęp do ich usług w czasie rzeczywistym i dostęp na żądanie do wymaganych informacji.

Shaip API
Główne cechy:
- Skuteczne bezpieczeństwo danych: Kontrola bezpieczeństwa danych za pomocą wcześniej ustalonych zasad w celu zapewnienia pełnej ochrony informacji.
- Skalowalna deidentyfikacja: Przetwarzanie i anonimizacja danych na dużą skalę bez żadnego oporu dzięki ludzkiej wiedzy i możliwościom sztucznej inteligencji.
Obszary ulepszeń:
- Posiada Krzywa uczenia się: Bez interwencji lub pomocy człowieka praca z narzędziem Shaip może być skomplikowana.
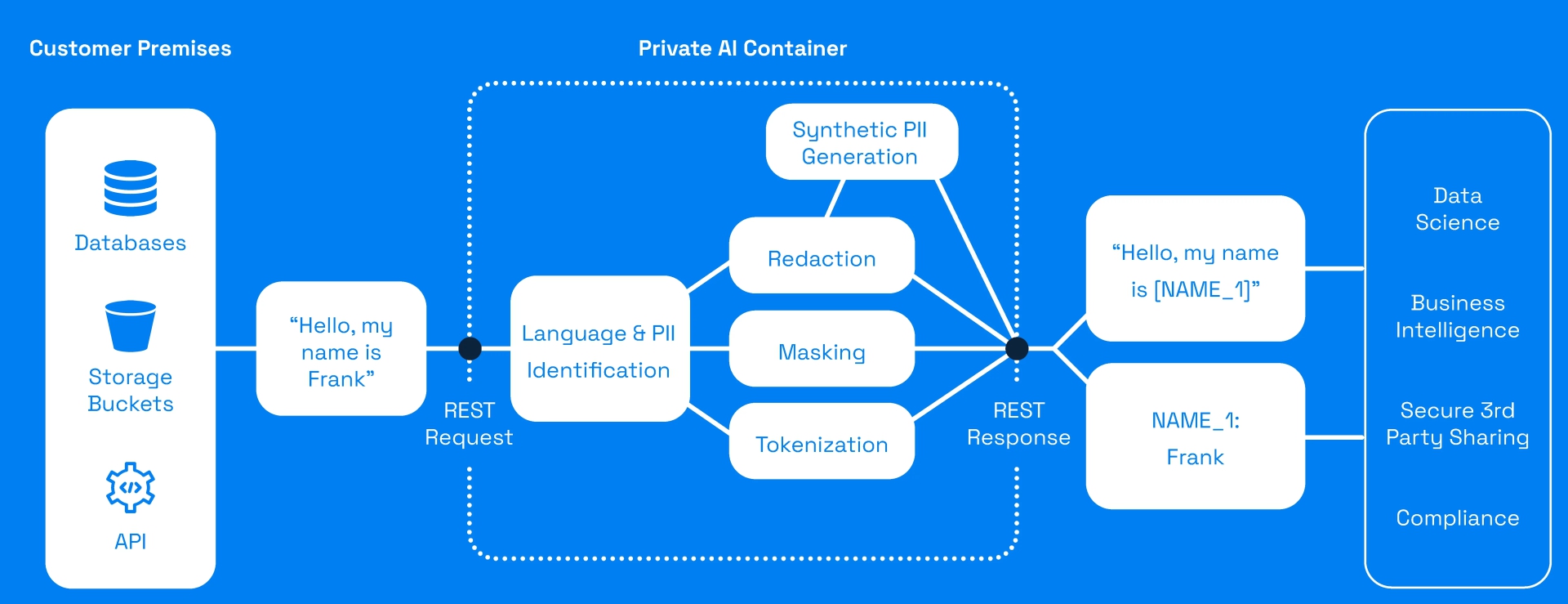
5. Prywatna sztuczna inteligencja
Private AI wykorzystuje zaawansowane systemy uczenia maszynowego do identyfikacji i redagowania informacji umożliwiających identyfikację osób. Za pomocą tego narzędzia można wykryć i usunąć około 50 rodzajów podmiotów opieki zdrowotnej w 52 językach.
Prywatna sztuczna inteligencja
Główne cechy:
- Generowanie danych syntetycznych: Dzięki Private-AI mogą Państwo tworzyć sztuczne dane w celu zastąpienia rzeczywistych danych do celów badawczych i testowych.
- Trenowanie modeli AI: Dzięki możliwościom uczenia maszynowego z zachowaniem prywatności można trenować modele sztucznej inteligencji na wrażliwych danych w szerokim zakresie celów.
Obszary wymagające poprawy
- Dostępność i użyteczność: Obecnie prywatna sztuczna inteligencja ma stromą krzywą uczenia się, co utrudnia każdemu korzystanie z narzędzia bez pomocy eksperta.
Przegląd najlepszych narzędzi do identyfikacji danych
|
Nazwa narzędzia |
Metoda identyfikacji danych |
Obsługiwany typ danych |
Zgodności |
Wdrożenie |
Automatyzacja Lub Nadzór nad ludźmi |
|
IBM InfoSphere Optim |
Maskowanie Pseudonimizacja Generowanie danych syntetycznych |
Dokumentacja medyczna Dane finansowe Dane klienta Ogólny zbiór danych |
HIPAA RODO |
Lokalnie i w chmurze |
Konfigurowalne dzięki automatyzacji i interwencji człowieka |
|
Google Healthcare API |
Maskowanie Pseudonimizacja |
Dokumentacja medyczna Dokumenty kliniczne Dane dotyczące roszczeń |
HIPAA HL7 FHIR |
Oparte na chmurze |
Dostępny jest zautomatyzowany przegląd ekspercki |
|
AWS Comprehend Medical |
Rozpoznawanie podmiotów Ekstrakcja relacji Analiza nastrojów |
Uwagi kliniczne Raporty Podsumowania |
HIPAA 21 CFR część 11 |
Oparte na chmurze |
Zautomatyzowane |
|
Shaip |
Maskowanie Anonimizacja Redagowanie Tokenizacja Pseudonimizacja |
Medyczne rejestry tekstowe Elektroniczna dokumentacja medyczna Raporty kliniczne Obrazy |
HIPAA RODO Specyficzne dostosowanie |
Oparte na chmurze |
Zautomatyzowany z człowiekiem w pętli |
|
Private-AI |
Maskowanie Generowanie danych syntetycznych Uczenie maszynowe z zachowaniem prywatności |
Tekst kliniczny Obrazy Audio |
RODO HIPAA CPRA |
Oparte na chmurze |
Konfigurowalny za pomocą automatyzacji i przeglądu przez człowieka. |
Wnioski
Deidentyfikacja danych ma kluczowe znaczenie dla ochrony danych osobowych w opiece zdrowotnej, zgodnie z wymogami regulacyjnymi, takimi jak HIPAA i RODO. Prezentowane narzędzia, w tym IBM InfoSphere Optim, Google Healthcare API, AWS Comprehend Medical, Shaip i Private-AI, oferują różnorodne rozwiązania do skutecznego maskowania danych.
Shaip, wykorzystujący sztuczną inteligencję w opiece zdrowotnej i ludzką wiedzę, wyróżnia się skalowalną deidentyfikacją i silnymi funkcjami bezpieczeństwa danych. Chociaż krzywa uczenia się może stanowić wyzwanie, integracja ludzkiego nadzoru zapewnia precyzję w ochronie tożsamości pacjentów i klientów. Ogólnie rzecz biorąc, wybór odpowiedniego narzędzia do deidentyfikacji danych ma kluczowe znaczenie dla instytucji opieki zdrowotnej, aby zachować zgodność z przepisami i zabezpieczyć wrażliwe informacje.