
Uwaga redaktora: Poniższy artykuł został napisany i opublikowany w DZone’s 2024 Trend Report, Sztuczna inteligencja w przedsiębiorstwie: wyłaniający się krajobraz inżynierii wiedzy.
W dzisiejszej erze cyfrowej dane stały się podstawą podejmowania decyzji w różnych dziedzinach, od biznesu i opieki zdrowotnej po edukację i rząd. Zdolność do gromadzenia, analizowania i wyciągania wniosków z danych zmieniła sposób działania organizacji, oferując bezprecedensowe możliwości innowacji, wydajności i rozwoju.
Czym jest podejście oparte na danych?
Podejście oparte na danych to metodologia, która opiera się na analizie i interpretacji danych w celu kierowania procesem decyzyjnym i rozwojem strategii. Podejście to obejmuje szereg technik, w tym gromadzenie, przechowywanie, analizę, wizualizację i interpretację danych, a wszystko to ma na celu wykorzystanie mocy danych do osiągnięcia sukcesu organizacyjnego.
Kluczowe zasady obejmują:
- Gromadzenie danych – Gromadzenie odpowiednich danych z różnych źródeł ma zasadnicze znaczenie dla zapewnienia ich jakości i przydatności do późniejszej analizy.
- Analiza danych – Przetwarzanie i analizowanie zebranych danych przy użyciu technik statystycznych i uczenia maszynowego (ML) ujawnia cenne spostrzeżenia umożliwiające podejmowanie świadomych decyzji.
- Wizualizacja danych – wizualne przedstawienie spostrzeżeń za pomocą wykresów i grafów ułatwia zrozumienie i pomaga decydentom w rozpoznawaniu trendów i wzorców.
- Podejmowanie decyzji w oparciu o dane – integracja danych z procesami decyzyjnymi na wszystkich poziomach organizacji usprawnia zarządzanie ryzykiem i optymalizację procesów.
- Ciągłe doskonalenie – przyjęcie kultury ciągłego gromadzenia, analizy i działania danych sprzyja innowacjom i adaptacji do zmieniających się warunków.
Strategie integracji danych z wykorzystaniem sztucznej inteligencji
Integracja danych łączy dane z różnych źródeł w celu uzyskania ujednoliconego widoku. Sztuczna inteligencja (AI) usprawnia integrację poprzez automatyzację zadań, zwiększenie dokładności i zarządzanie różnymi wolumenami danych. Oto cztery najważniejsze strategie/wzorce integracji danych wykorzystujące sztuczną inteligencję:
- Zautomatyzowane dopasowywanie i łączenie danych – algorytmy sztucznej inteligencji, takie jak ML i przetwarzanie języka naturalnego (NLP), mogą dopasowywać i automatycznie łączyć dane z różnych źródeł.
- Integracja danych w czasie rzeczywistym – technologie AI, takie jak przetwarzanie strumieniowe i architektury sterowane zdarzeniami, mogą ułatwić integrację danych w czasie rzeczywistym poprzez ciągłe pozyskiwanie, przetwarzanie i integrację danych w miarę ich dostępności.
- Mapowanie i transformacja schematów – narzędzia oparte na sztucznej inteligencji mogą zautomatyzować proces mapowania i przekształcania schematów danych z różnych formatów lub struktur. Obejmuje to konwersję danych między relacyjnymi bazami danych, bazami danych NoSQL i innymi formatami danych – a także obsługę ewolucji schematu w czasie.
- Grafy wiedzy i integracja oparta na grafach – sztuczna inteligencja może tworzyć i przeszukiwać grafy wiedzy reprezentujące relacje między jednostkami i pojęciami. Grafy wiedzy umożliwiają elastyczną i semantyczną integrację danych poprzez przechwytywanie bogatych informacji kontekstowych i obsługę złożonych zapytań w heterogenicznych źródłach danych.
Integracja danych jest podstawą nowoczesnych strategii zarządzania danymi, które mają kluczowe znaczenie dla zapewnienia organizacjom kompleksowego zrozumienia ich krajobrazu danych. Integracja danych zapewnia spójny i ujednolicony widok zasobów danych organizacyjnych poprzez płynne łączenie danych z różnych źródeł, takich jak bazy danych, aplikacje i systemy.
Jedną z głównych zalet integracji danych jest jej zdolność do poprawy jakości danych. Konsolidując dane z wielu źródeł, organizacje mogą identyfikować i korygować niespójności, błędy i nadmiarowości, poprawiając w ten sposób dokładność i wiarygodność swoich danych. To z kolei umożliwia decydentom podejmowanie świadomych decyzji w oparciu o wiarygodne informacje. Przyjrzyjmy się bliżej, w jaki sposób możemy wykorzystać generatywną sztuczną inteligencję w procesach związanych z danymi.
Badanie wpływu generatywnej sztucznej inteligencji na procesy związane z danymi
Generatywna sztuczna inteligencja zrewolucjonizowała w ostatnich latach różne branże i procesy związane z danymi. Generatywna sztuczna inteligencja obejmuje szeroki wachlarz metodologii, od generatywnych sieci przeciwstawnych (GAN) i autoenkoderów wariacyjnych (VAE) po modele oparte na transformatorach, takie jak GPT (generatywny wstępnie wytrenowany transformator). Algorytmy te wykazują imponujące zdolności w tworzeniu realistycznych obrazów, tekstu, dźwięku, a nawet filmów, które ściśle naśladują ludzką kreatywność poprzez generowanie świeżych próbek danych.
Wykorzystanie generatywnej sztucznej inteligencji do lepszej integracji danych
Doszliśmy teraz do praktycznej części roli generatywnej sztucznej inteligencji w ulepszonej integracji danych. Poniżej przedstawiłem kilka rzeczywistych scenariuszy. Pozwoli to lepiej zrozumieć rolę sztucznej inteligencji w integracji danych.
Tabela 1. Rzeczywiste przypadki użycia
| Przemysł/zastosowanie | Przykład |
|---|---|
|
Opieka zdrowotna/rozpoznawanie obrazów |
|
|
E-commerce |
|
|
Media społecznościowe |
|
|
Cyberbezpieczeństwo |
|
|
Usługi finansowe |
|
Zapewnienie dokładności i spójności danych przy użyciu sztucznej inteligencji i uczenia maszynowego
Organizacje zmagają się z utrzymaniem dokładnych i wiarygodnych danych w dzisiejszym świecie opartym na danych. Sztuczna inteligencja i uczenie maszynowe pomagają wykrywać anomalie, identyfikować błędy i automatyzować procesy czyszczenia. Przyjrzyjmy się bliżej tym wzorcom.
Walidacja i czyszczenie danych
Walidacja i oczyszczanie danych to często pracochłonne zadania, wymagające znacznego nakładu czasu i zasobów. Narzędzia oparte na sztucznej inteligencji usprawniają i przyspieszają te procesy. Algorytmy ML uczą się na podstawie wcześniejszych danych, aby automatycznie identyfikować i naprawiać typowe problemy związane z jakością. Mogą standaryzować formaty, uzupełniać brakujące wartości i godzić niespójności. Automatyzacja tych zadań zmniejsza liczbę błędów i przyspiesza przygotowanie danych.
Odkrywanie wzorców i spostrzeżeń
Algorytmy AI i ML mogą odkrywać ukryte wzorce, trendy i korelacje w zbiorach danych. Analizując ogromne ilości danych, algorytmy te mogą identyfikować relacje, które mogą nie być widoczne dla ludzkich analityków. AI i ML mogą również zrozumieć przyczyny leżące u podstaw problemów z jakością danych i opracować strategie ich rozwiązania. Algorytmy ML mogą na przykład identyfikować typowe błędy lub wzorce przyczyniające się do niespójności danych. Organizacje mogą następnie wdrożyć nowe procesy w celu usprawnienia gromadzenia danych, ulepszyć wytyczne dotyczące wprowadzania danych lub zidentyfikować potrzeby szkoleniowe pracowników.
Anomalie w danych
Algorytmy AI i ML ujawniają ukryte wzorce, trendy i korelacje w zbiorach danych, analizując ogromne ilości danych w celu odkrycia spostrzeżeń, które nie są łatwo widoczne dla ludzi. Rozumieją również podstawowe przyczyny problemów z jakością danych, identyfikując typowe błędy lub wzorce powodujące niespójności. Umożliwia to organizacjom wdrażanie nowych procesów, takich jak udoskonalanie metod gromadzenia danych lub ulepszanie szkoleń pracowników, w celu rozwiązania tych problemów.
Wykrywanie anomalii w danych
Modele uczenia maszynowego doskonale radzą sobie z wykrywaniem wzorców, w tym odchyleń od norm. Dzięki ML organizacje mogą analizować duże ilości danych, porównywać je z ustalonymi wzorcami i oznaczać potencjalne problemy. Organizacje mogą następnie zidentyfikować anomalie i określić, w jaki sposób poprawić, zaktualizować lub rozszerzyć swoje dane, aby zapewnić ich integralność.
Przyjrzyjmy się usługom, które mogą weryfikować dane i wykrywać anomalie.
Wykrywanie anomalii przy użyciu Stream Analytics
Azure Stream Analytics, AWS Kinesisoraz Google Cloud Dataflow to przykłady narzędzi, które zapewniają wbudowane funkcje wykrywania anomalii, zarówno w chmurze, jak i na brzegu sieci, umożliwiając rozwiązania neutralne pod względem dostawców. Platformy te oferują różne funkcje i operatorów do wykrywania anomalii, umożliwiając użytkownikom monitorowanie anomalii, w tym tymczasowych i trwałych.
Na przykład, w oparciu o moje doświadczenie w budowaniu walidacji przy użyciu Stream Analytics, oto kilka kluczowych działań, które należy rozważyć:
- Dokładność modelu poprawia się wraz z większą ilością danych w przesuwanym oknie, traktując je jako oczekiwane w ramach czasowych. Skupia się na historii zdarzeń w oknie, aby wykryć anomalie, odrzucając stare wartości podczas przesuwania.
- Funkcje ustalają bazową wartość normalną, porównując dane z przeszłości i identyfikując wartości odstające w ramach poziomu ufności. Rozmiar okna można ustawić na podstawie minimalnej liczby zdarzeń potrzebnych do praktycznego szkolenia.
- Czas reakcji wzrasta wraz z rozmiarem historii, więc dla lepszej wydajności należy uwzględnić tylko niezbędne zdarzenia.
- W oparciu o ML można monitorować tymczasowe anomalie, takie jak skoki i spadki w strumieniu zdarzeń szeregów czasowych za pomocą operatora AnomalyDetection_SpikeAndDip.
- Jeśli drugi skok w tym samym oknie przesuwnym jest mniejszy niż pierwszy, jego wynik może nie być wystarczająco znaczący w porównaniu z pierwszym skokiem w ramach określonego poziomu ufności. Aby temu zaradzić, proszę rozważyć dostosowanie poziomu ufności modelu. Jeśli jednak otrzymują Państwo zbyt wiele alertów, należy użyć wyższego przedziału ufności.
Wykorzystanie generatywnej sztucznej inteligencji do transformacji i rozszerzania danych
Generatywna sztuczna inteligencja pomaga w rozszerzaniu i przekształcaniu danych, które są również częścią procesu walidacji danych. Modele generatywne mogą generować dane syntetyczne, które przypominają rzeczywiste próbki danych. Może to być szczególnie przydatne, gdy dostępny zestaw danych jest niewielki lub wymaga większej różnorodności. Modele generatywne można również trenować w celu tłumaczenia danych z jednej domeny na inną lub przekształcania danych przy jednoczesnym zachowaniu ich podstawowych cech.
Na przykład modele sekwencja-sekwencja, takie jak transformatory, mogą być wykorzystywane w NLP do zadań takich jak tłumaczenie języka lub podsumowanie tekstu, skutecznie przekształcając dane wejściowe w inną reprezentację. Proces transformacji danych może być również wykorzystywany do rozwiązywania problemów w starszych systemach opartych na starej bazie kodu. Organizacje mogą odblokować liczne korzyści, przechodząc na nowoczesne języki programowania. Przykładowo, starsze systemy są zbudowane w oparciu o przestarzałe języki programowania, takie jak Cobol, Lisp i Fortran. Aby je zmodernizować i zwiększyć ich wydajność, musimy je zmigrować lub przepisać przy użyciu najnowszych, wysokowydajnych i zaawansowanych języków programowania, takich jak Python, C# lub Go.
Spójrzmy na poniższy diagram, aby zobaczyć, w jaki sposób generatywna sztuczna inteligencja może zostać wykorzystana do ułatwienia tego procesu migracji:
Rysunek 1. Wykorzystanie generatywnej sztucznej inteligencji do przepisania starszego kodu
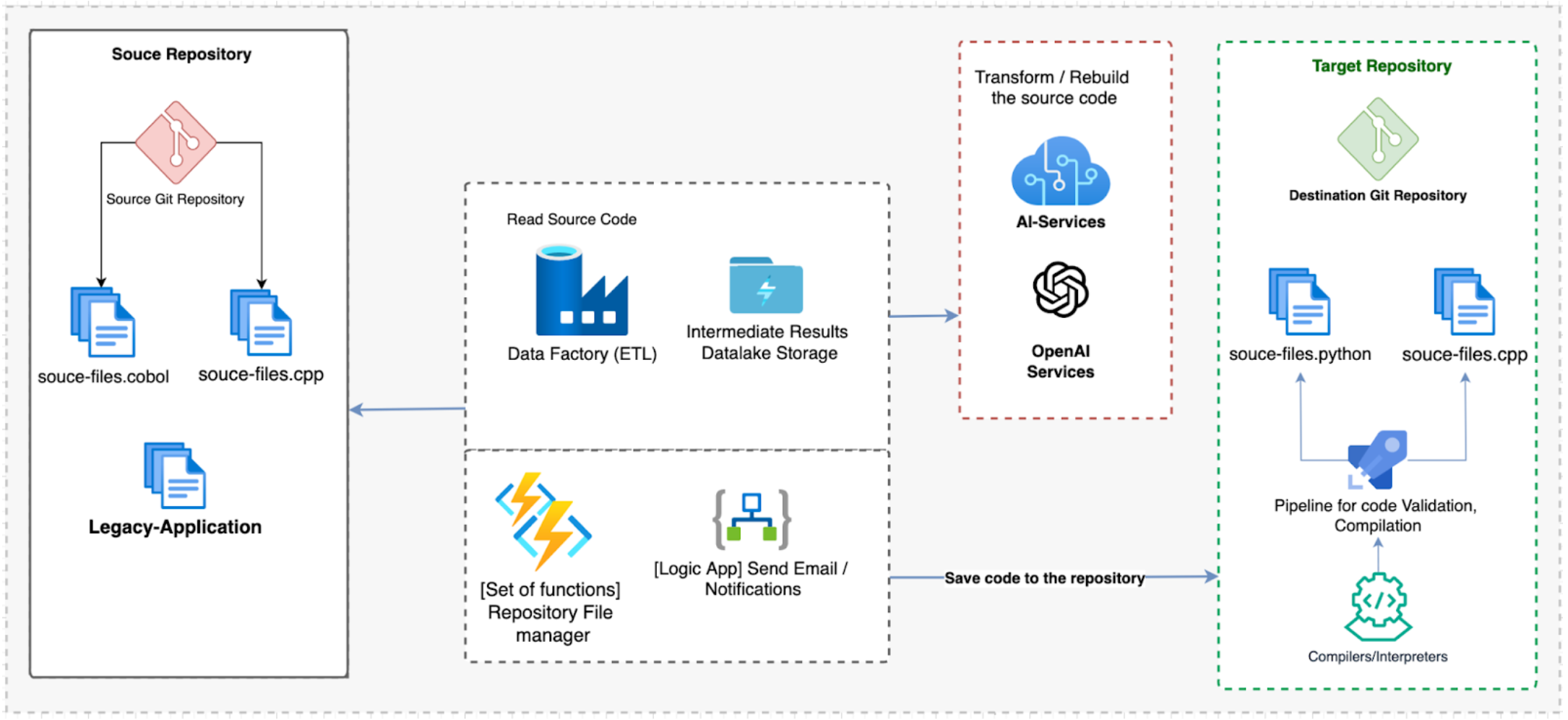
Powyższa architektura opiera się na następujących komponentach i przepływie pracy:
- Azure Data Factory jest głównym narzędziem ETL (extract, transform, load) do orkiestracji i transformacji danych. Łączy się z repozytoriami źródłowymi Git. Alternatywnie, możemy użyć AWS Glue do integracji danych i Google Cloud Data Fusion dla operacji ETL na danych.
- OpenAI to usługa generatywnej sztucznej inteligencji służąca do przekształcania języków Cobol i C++ na Python, C# i Golang (lub dowolny inny język). Usługa OpenAI jest połączona z Data Factory. Alternatywy dla OpenAI to Amazon SageMaker lub Google Cloud AI Platforma.
- Azure Logic Apps oraz Google Cloud Functions to usługi narzędziowe, które zapewniają mapowanie danych i możliwości zarządzania plikami.
- DevOps CI/CD zapewnia potoki do walidacji, kompilacji i interpretacji wygenerowanego kodu.
Walidacja danych i sztuczna inteligencja: przypadek użycia Chatbot Call Center
Zautomatyzowana konfiguracja call center to świetny przypadek użycia do zademonstrowania walidacji danych. Poniższy przykład przedstawia automatyzację i rozwiązanie bazodanowe dla call center:
Rysunek 2. Architektura chatbota call center
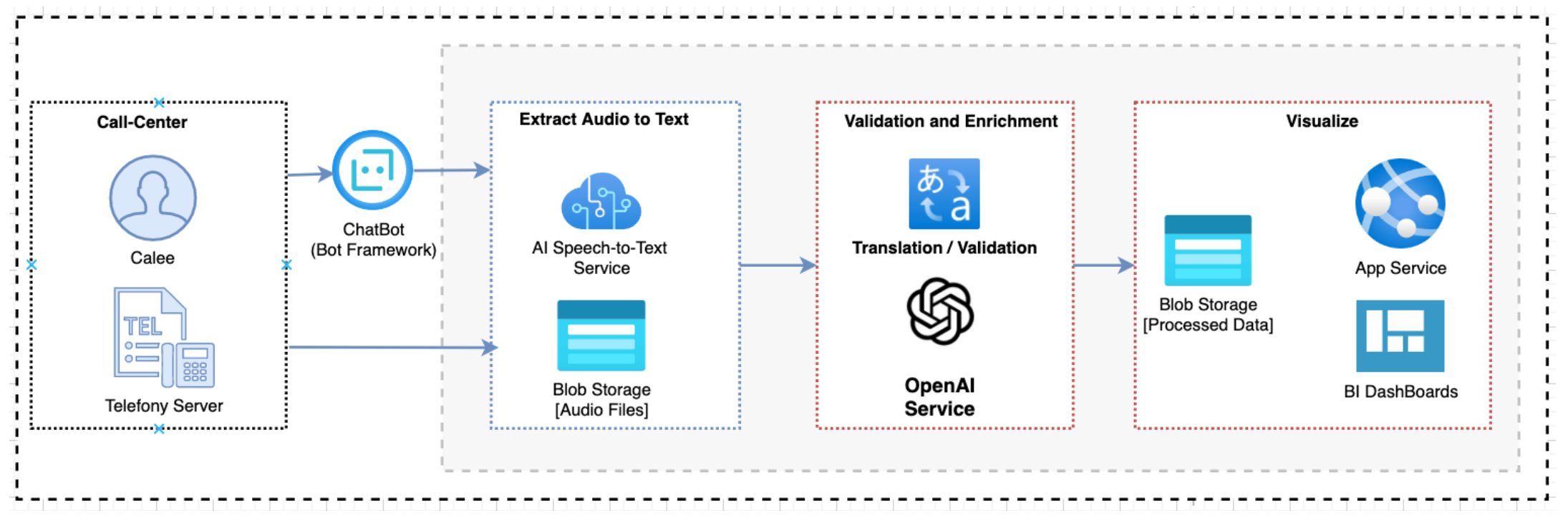
Rozwiązanie automatyzacji i bazy danych wyodrębnia dane z bota mowy wdrożonego w call center lub z interakcji z prawdziwymi ludźmi. Następnie przechowuje, analizuje i weryfikuje te dane za pomocą ChatGPT OpenAI i usługi analizy nastrojów AI. Następnie analizowane dane są wizualizowane za pomocą pulpitów analityki biznesowej (BI) w celu uzyskania kompleksowego wglądu. Przetworzone informacje są również integrowane z systemami zarządzania relacjami z klientami (CRM) w celu weryfikacji przez człowieka i dalszych działań.
Rozwiązanie zapewnia dokładne zrozumienie i interpretację interakcji z klientami dzięki wykorzystaniu ChatGPT, zaawansowanego modelu NLP. Korzystanie z pulpitów nawigacyjnych BI oferuje intuicyjne i interaktywne możliwości wizualizacji danych, umożliwiając interesariuszom uzyskanie praktycznych spostrzeżeń na pierwszy rzut oka. Integracja analizowanych danych z systemami CRM umożliwia płynną współpracę między zautomatyzowaną analizą a walidacją przez człowieka.
Wnioski
W stale ewoluującym krajobrazie korporacyjnej sztucznej inteligencji kluczowe znaczenie ma osiągnięcie doskonałości danych. Usługi w zakresie danych i generatywnej sztucznej inteligencji, które zapewniają analizę danych, ETL i NLP, umożliwiają solidne strategie integracji w celu uwolnienia pełnego potencjału zasobów danych. Łącząc podejście oparte na danych i zaawansowane technologie, firmy mogą utorować drogę do lepszego podejmowania decyzji, produktywności i innowacji dzięki tym usługom AI i danych.
Jest to fragment raportu DZone na temat trendów w 2024 roku,
Sztuczna inteligencja w przedsiębiorstwie: wyłaniający się krajobraz inżynierii wiedzy.