
Ponieważ technologia nieustannie ewoluuje, a przetwarzanie danych wymagania rosną wykładniczo, wiele przedsiębiorstw migruje swoje starsze hurtownie danych do najnowszych technologii. Jednak niezgodności między starszymi i najnowszymi technologiami oraz wielkość obciążenia pracą mają duży wpływ na harmonogram i koszt projektu.
W niniejszym artykule przedstawiono charakterystyczne wyzwania napotkane podczas migracji dużej hurtowni danych. hurtowni danych i szczegółowo opisuje, w jaki sposób skutecznie poradzono sobie z tymi wyzwaniami poprzez wdrożenie innowacyjnych rozwiązań. Wysiłki zostały zoptymalizowane, co doprowadziło do znacznej redukcji kosztów o współczynnik 50.
Duży bank podjął się projektu przejścia ze starszej technologii hurtowni danych na najnowszą platformę. Projekt obejmował przede wszystkim migrację starszej architektury obejmującej Oracle i IBM PDOA do IBM IIAS (Db2).
Architektura źródłowa miała Oracle jako strefę lądowania, podczas gdy stan docelowy miał Db2 jako strefę lądowania. Wiązało się to ze złożonością techniczną integracji z przechwytywaniem danych zmian, które było odpowiedzialne za przenoszenie danych do strefy docelowej, oraz ETL odpowiedzialnymi za ładowanie danych do przemieszczania.
System zbierał dane z 20 źródeł za pośrednictwem 60 subskrypcji/zadań CDC i istniało ponad 2000 ETL odpowiedzialnych za etapowanie z lądowania. Niezgodności między Oracle i Db2 miały wpływ na wszystkie te elementy. Refaktoryzacja 60 subskrypcji CDC i ponad 2000 ETL nie była pragmatyczna, ponieważ miałaby duży wpływ na harmonogram i koszty.
W niniejszym artykule opisano unikalne rozwiązania wdrożone w celu uniknięcia wszystkich tych zmian i zoptymalizowania ogólnych wysiłków i kosztów o współczynnik 50.
Opis problemu
Starsza architektura, przedstawiona na poniższym diagramie, obejmowała IBM Infosphere Change Data Capture (CDC) do zbierania danych z różnych źródeł i wstawiania ich do Landing Zone w Oracle oraz IBM DataStage ETL aby zbudować Staging przy użyciu danych z Landing Zone, a następnie zbudować Datamart w IBM PDOA (Db2).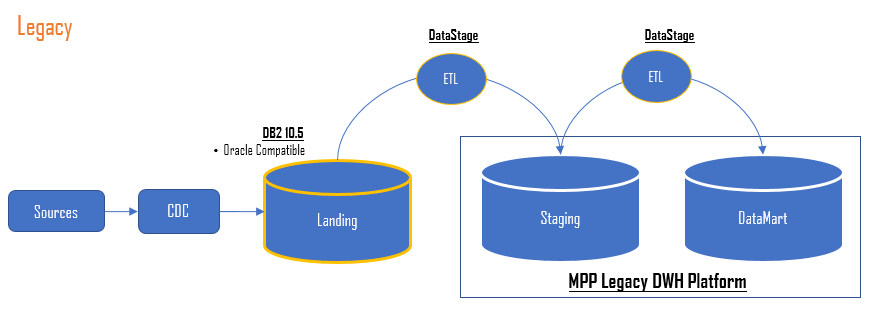
Docelowa architektura, przedstawiona na poniższym diagramie, obejmowała IBM Infosphere Change Data Capture (CDC) do zbierania danych z różnych źródeł i wstawiania ich do Landing Zone w IIAS (Db2) oraz DataStage ETL do budowania Staging przy użyciu danych z Landing Zone, a następnie Datamart w IIAS (Db2).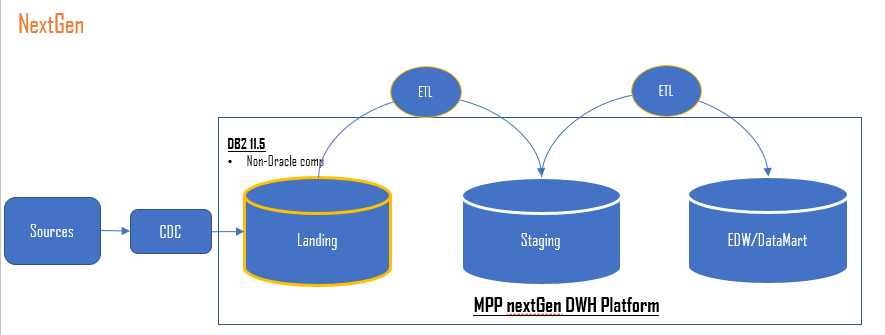
Jednak po zastąpieniu Oracle przez Db2 znaczna część zadań ETL (Extract, Transform, Load) między obszarami lądowania i magazynowania zaczęła zawodzić, co spowodowało znaczne rozbieżności w danych.
Problemy wynikały głównie z niezgodności między Oracle i Db2. Naprawienie tych problemów wymagało zmiany zadań ETL. Ponieważ liczba zadań ETL wynosiła ponad 2000, a wolumen danych ponad 600 TB, naprawienie każdego ETL było ogromnym zadaniem i wymagało kilku osobolat wysiłku. Miało to znaczący wpływ na ogólne koszty i harmonogram projektu.
W związku z tym wymagane było alternatywne i innowacyjne podejście, aby zmniejszyć wysiłki z kilku lat do kilku tygodni.
Ten dokument daje wgląd w to, jak poradzono sobie z kwestią niekompatybilności i naprawiono problemy w ciągu kilku tygodni.
Podejście do rozwiązania
Na początku przeprowadzono szczegółową analizę istniejącego środowiska i zidentyfikowano kluczowe różnice między Oracle i Db2:
- Różnica w zachowaniu 20 wbudowanych funkcji
- Różnica w obsłudze pustych ciągów znaków
- Niezgodności w typach danych
- Różnica w składni SQL
Po drugie, za pomocą skryptów automatyzacji zidentyfikowano przypadki wszystkich tych niezgodności we wszystkich zadaniach ETL.
Odkrycie i analiza ujawniły, że niezgodności z wbudowanymi funkcjami prowadziły do zmian w prawie każdym ETL. W związku z tym oceniono następujące opcje:
- Ręczna zmiana każdego ETL
- Opracowanie automatyzacji w celu zmiany każdego ETL
Jednak oba te działania wymagały ogromnego wysiłku, dlatego też przyjęto innowacyjne podejście, które drastycznie zmniejszyło wysiłek z kilku lat do mniej niż czterech tygodni.
Szczegóły rozwiązania
Ogólne rozwiązanie zostało zaprojektowane i wdrożone przy użyciu 3 funkcji IBM Db2, a mianowicie nadpisywania/ przeciążania funkcji, CONNECT_PROC i FUNCTION_PATH.
Zadania ETL w dużym stopniu wykorzystywały ponad 20 wbudowanych funkcji, takich jak TRANSLATE, RPAD, LPADktóre były niekompatybilne między Oracle i Db2. Aby rozwiązać te niezgodności, opracowano nowe funkcje pasujące do zachowania Oracle i zostały one zastąpione / przeciążone wbudowanymi funkcjami.
Nie było to jednak proste ze względu na następujące wyzwania:
- Poprawka była wymagana tylko w operacjach odczytu ETL, a nie w operacjach zapisu, ponieważ przejściowa baza danych nie miała problemów z niekompatybilnością.
- Funkcje miały również obsługiwać różnice null i empty string
- Każda funkcja miała specyficzne różnice
Aby odnieść się do pierwszej kwestii, CONNECT_PROC oraz FUNCTION_PATH funkcje Db2 zostały wykorzystane do zastosowania zmian tylko do użytkowników czytających, a pozostałe dwa wyzwania zostały obsłużone w projektach funkcji.
Poniższe sekcje przedstawiają implementację krok po kroku:
Segregacja użytkowników do odczytu i zapisu oraz odpowiednia konfiguracja na poziomie ETL
Ponieważ nadpisane funkcje miały mieć zastosowanie tylko podczas odczytu danych ze strefy lądowania, a nie podczas zapisu danych do strefy przejściowej, w ETL skonfigurowano dwóch oddzielnych użytkowników do odczytu i zapisu danych.
"user": użytkownik odczytujący dane ze strefy lądowania."user": użytkownik zapisujący dane w docelowej strefie przejściowej.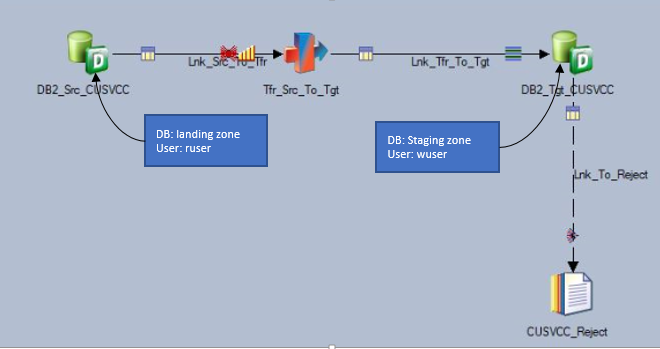
Rozwój funkcji nadpisywania/przeciążania
Priorytetowe funkcje do nadpisania/przeciążenia na podstawie liczby wystąpień w ETL i opracowane funkcje, w tym obsługa różnic NULL i pustych ciągów znaków.
Podczas opracowywania funkcji nadrzędnych wzięto pod uwagę następujące kwestie
- Opracowane funkcje dla każdego typu danych, np.
SUBSTRfunkcja została opracowana dlaCHARjak równieżVARCHARponieważ był używany dla obu typów danych we wszystkich ETL. - Zachowano maksymalną możliwą długość dla każdego typu danych zmiennej funkcyjnej, aby pomieścić pełny ciąg z kolumny. np. długość 256 dla
CHARtyp danych kolumny, ponieważ funkcja była używana dla zmiennych długości w różnych ETL.
Aby omówić to bardziej szczegółowo, oto kilka przykładów funkcji:
SUBSTR Funkcja
Kiedy SUBSTR funkcja w Db2 jest używana jako SUBSTR (‘ABCD’, 3, 5) i jeśli długość zwracanego ciągu jest większa niż długość ciągu wejściowego, Db2 wyświetla błąd “SQL0138N Instrukcja nie została wykonana, ponieważ argument liczbowy funkcji skalarnej jest poza zakresem” Natomiast w Oracle daje to wynik, tj. “CD”.
Zostało to rozwiązane poprzez nadpisanie funkcji SUBSTR która wewnętrznie wywołuje funkcję SUBSTRING na atrybutach przekazanych do funkcji SUBSTR po uruchomieniu przez “ruser”. Funkcja SUBSTRING funkcja zachowuje się tak, jakby długość zwracanego ciągu była większa niż długość ciągu wejściowego jako SUBSTRING (‘ABCD’, 3, 5) daje wynik jako ‘CD’
The overridden SUBSTR została również zaprojektowana do obsługi różnic w zachowaniu NULL i pustych ciągów między Oracle i Db2.
Przykładowy kod dla SUBSTR funkcja:
CREATE OR REPLACE FUNCTION RUSER.SUBSTR(SUB_EXPR VARCHAR(10000),SUB_POS INT, SUB_LENGTH INT)
RETURNS VARCHAR (500)
language sql
BEGIN
DECLARE SUB_VALUE VARCHAR (500);
SET SUB_VALUE=SYSIBM.SUBSTRING(SUB_EXPR, SUB_POS, SUB_LENGTH);
IF SYSIBM.LENGTH(SUB_VALUE)=0 AND SUB_VALUE='' THEN
SET SUB_VALUE=NULL;
END IF;
RETURN SUB_VALUE;
ENDTRANSLATE Funkcja
Składnia funkcji TRANSLATE jest inna w Oracle i Db2. Funkcja wymaga trzech argumentów, ale między Oracle i Db2, pozycja 2i i 3rd argument jest zamieniany.
Składnia Oracle
TRANSLATE(char-string-exp, from-string-exp, to-string-exp,' ',pad-char-exp)Składnia DB2
TRANSLATE(char-string-exp, to-string-exp, from-string-exp,' ',pad-char-exp)Opracowano nową funkcję z podobnymi typami wejściowymi i wyjściowymi, ale zamieniono argumenty 2 i 3. Przykładowy kod wygląda następująco:
CREATE OR REPLACE FUNCTION RUSER.TRANSLATE(TRAN_EXPR VARCHAR(1000),TRAN_FROM VARCHAR(10),TRAN_TO VARCHAR(10))
RETURNS VARCHAR(1000)
language sql
BEGIN
DECLARE TRAN_VALUE VARCHAR(1000);
DECLARE CNTR_ZERO SMALLINT DEFAULT 0;
SET TRAN_VALUE=TRANSLATE(TRAN_EXPR,TRAN_TO,TRAN_FROM);
IF TRAN_VALUE='' THEN
SET TRAN_VALUE=NULL;--
END IF;--
RETURN TRAN_VALUE;
ENDLPAD Funkcja
The LPAD po zastosowaniu do liczb dziesiętnych o wartości dziesiętnej 0, wykazuje różne zachowanie między Db2 oraz Oracle z wynikami podanymi poniżej.
- Oracle: LPAD (1.0, 4, 0) => 0001
- DB2: LPAD (1.0, 4, 0) => 01.0
Zostało to rozwiązane poprzez nadpisanie funkcji LPAD dla liczb dziesiętnych. Nowa funkcja sprawdza, czy wartość dziesiętna danej liczby dziesiętnej wynosi 0, czy nie, a jeśli wartość dziesiętna wynosi 0, stosuje funkcję LPAD funkcję tylko do części całkowitej liczby dziesiętnej, w przeciwnym razie LPAD jest stosowana do całej liczby dziesiętnej.
Przykładowy kod:
CREATE OR REPLACE FUNCTION RUSER.LPAD (P_EXPP DECIMAL(25,3),P_LEN INT,P_VALUE INT)
RETURNS VARCHAR(4000)
LANGUAGE SQL
SPECIFIC TESTLPAD10
BEGIN
DECLARE RESULT_VALUE VARCHAR(50);--
DECLARE NUM_OUTPUT decimal(25,3);--
DECLARE NUM_EXPR VARCHAR(50);--
DECLARE P_EXPR VARCHAR(50);--
DECLARE C_P_EXPP BIGINT;--
SET C_P_EXPP= CAST (P_EXPP as BIGINT);
SET NUM_OUTPUT = P_EXPP - C_P_EXPP;
IF NUM_OUTPUT >0 THEN
SET P_EXPR=TRIM(BOTH '0' FROM P_EXPP);--
SET RESULT_VALUE = SYSIBM.LPAD(P_EXPR,P_LEN,P_VALUE);
ELSE
SET RESULT_VALUE = SYSIBM.LPAD(C_P_EXPP,P_LEN,P_VALUE);
END IF;--
RETURN RESULT_VALUE;--
ENDDzięki temu podejściu prawie 20 wbudowanych funkcji Db2 zostało zastąpionych / przeciążonych bez uszczerbku dla jakości danych i wydajności.
Poniższa tabela opisuje listę funkcji i różnice w zachowaniu, które zostały zastąpione.
|
Nazwa funkcji |
Db2 (wbudowana) |
Oracle (nadpisane) |
Obsługiwane zmiany zachowania |
|
TRANSLATE |
Translate(“String”,Search, Replace) |
Translate(“String”, Replace, Search) |
|
|
RPAD |
RPAD( string-expression , integer, pad) |
RPAD (string-expression , integer, pad) |
Oracle: rpad(1.0, 4, 0) => 1000 |
|
SUBSTR |
SUBSTR( string-expression , start , length ) |
SUBSTR (string-expression , start , length ) |
|
|
TO_CHAR |
TO_CHAR( string-expression) |
TO_CHAR( string-expression) |
|
|
oraz LPAD, CHAR, UPPER, SUBSTRING, REPLACE, NVL, VARCHAR, COALESCE, LEFT, RIGHT, RTRM, LTRIM, TRIM, NULLIF, TO_NUMBER, LENGTH,
|
|||
Proszę włączyć funkcję nadpisaną/przeciążoną, aby odczytywać tylko użytkownika
Ostatnią i najbardziej krytyczną częścią rozwiązania było włączenie nadpisanych/przeciążonych funkcji tylko dla użytkowników do odczytu.
Zgodnie z architekturą Db2, wbudowane funkcje w ramach SYSIBM schematu są traktowane priorytetowo. Db2 wykorzystuje parametr o nazwie FUNCTION_PATH do określenia tej preferencji. Domyślna wartość FUNCTION_PATH jest ustawiona jako "SYSIBM", "SYSFUN", "SYSPROC", "SYSIBMADM", "X" po którym następuje wartość schematu użytkownika oznaczona jako X.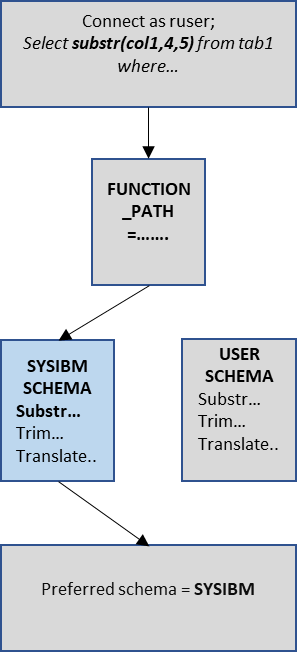
Jednak nadpisane funkcje znajdują się w schemacie użytkownika. W związku z tym, aby korzystać z nadpisanych funkcji, i to tylko do odczytu użytkownika ruser, the FUNCTION_PATH wartość musiała zostać zmieniona w momencie wywołania funkcji przez użytkownika odczytującego. Jednak globalna zmiana wartości miałaby wpływ na użytkownika zapisującego. Stąd inna funkcja Db2, zwana CONNECT_PROC został użyty.
The CONNECT_PROC jest parametrem konfiguracyjnym, a procedura skonfigurowana do tego parametru jest wykonywana, gdy dowolny użytkownik łączy się z bazą danych. W związku z tym utworzono nową procedurę składowaną, w której znajduje się parametr FUNCTION_PATH została ustawiona na użytkownika RUSER schemat pierwszy i procedura została skonfigurowana do CONNECT_PROC parametr.
Dzięki temu, jak i kiedy “ruser” podłączony do bazy danych, a FUNCTION_PATH został ustawiony na użycie RUSER a dla pozostałych użytkowników zastosowano domyślną ścieżkę.
Poniższy kod wyjaśnia, w jaki sposób zmiana FUNCTION_PATH, tylko dla ruser, w czasie działania.
db2 connect to <dbname> ; db2 update db cfg using CONNECT_PROC DB2TEST.TESTPROCCREATE or replace procedure DB2TEST.TESTPROC
LANGUAGE SQL
BEGIN
IF UPPER(SESSION_USER) = 'RUSER'
THEN
SET CURRENT FUNCTION PATH "RUSER","SYSIBM","SYSFUN","SYSPROC","SYSIBMADM";
END IF;
END
Po zastosowaniu tego CONNECT_PROC, kolejność preferencji dla “ruser” zmieniła się dynamicznie w następujący sposób:
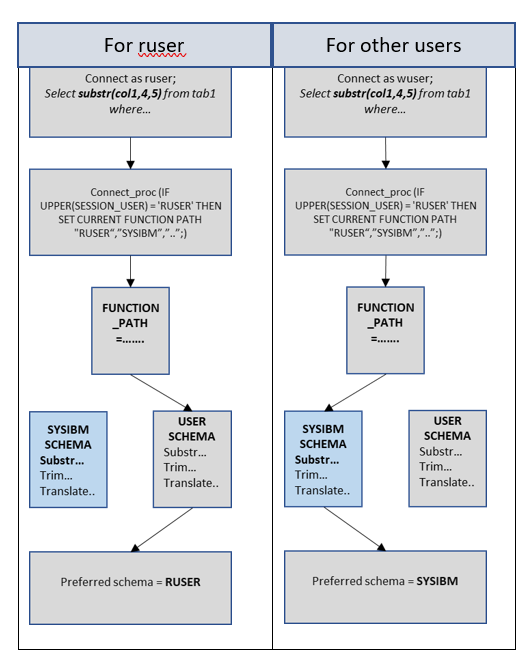
Dzięki tej ostatniej zmianie, nadpisywanie i przeciążanie funkcji dla niekompatybilnych funkcji wbudowanych zostało pomyślnie osiągnięte dla użytkowników odczytu i uniknięto zmian w zadaniach ETL.
Wnioski
Zazwyczaj w projektach migracji baz danych migracja kodu aplikacji (aplikacje, zadania ETL, procedury składowane, wyzwalacze, funkcje) jest uważana za najbardziej skomplikowane, czasochłonne i kosztowne zadanie.
Chociaż dostępna jest automatyzacja do migracji różnych obiektów kodu, nie rozwiązuje ona wszystkich wyzwań. W tym projekcie wyzwania były wyjątkowe, wydawały się nie do pokonania ze względu na objętość, a konwencjonalne rozwiązania nie wydawały się wykonalne.
Jednak innowacyjne myślenie o wykorzystaniu różnych funkcji Db2 w połączeniu – nadpisywanie funkcji / przeciążanie, CONNECT_PROC i FUNCTION_PATHzaowocowało bezprecedensowym rozwiązaniem i zoptymalizowało ogólne wysiłki z kilku osób rocznie do mniej niż 4 tygodni.