
Dane częściowo ustrukturyzowane to dane ułożone w elastycznych formatach. W przeciwieństwie do danych ustrukturyzowanych, nie wymagają one od użytkowników danych wstępnego definiowania schematu tabeli, dzięki czemu zapewniają wygodę przechowywania i analizy danych. Typowe formy danych częściowo ustrukturyzowanych obejmują XML, JSON i pliki dziennika. Są one powszechnie spotykane w następujących scenariuszach branżowych:
- Handel elektroniczny platformy przechowują opinie użytkowników o produktach jako częściowo ustrukturyzowane dane do analizy nastrojów i eksploracji wzorców zachowań użytkowników.
- Telekomunikacja Przypadki użycia często wymagają bezschematycznej obsługi danych sieciowych i skomplikowanych zagnieżdżonych danych JSON.
- Aplikacje mobilne przechowują zapisy zachowań użytkowników w postaci danych częściowo ustrukturyzowanych, ponieważ po wprowadzeniu nowych funkcji atrybuty zachowań użytkowników mogą się zmieniać. Niestały schemat może łatwo dostosować się do tych zmian i zaoszczędzić kłopotów związanych z częstymi ręcznymi modyfikacjami.
- Internet pojazdów (IoV) i Internet rzeczy (IoT) otrzymują w czasie rzeczywistym dane z czujników pojazdu, takie jak prędkość, lokalizacja i zużycie paliwa, na podstawie których monitorują w czasie rzeczywistym, ostrzegają o usterkach i planują trasy. Takie dane są również przechowywane jako dane częściowo ustrukturyzowane.
Jako hurtownia danych czasu rzeczywistego typu open-source, Apache Doris zapewnia możliwości przetwarzania danych częściowo ustrukturyzowanych, a nowo wydana aplikacja wersja 2.1.0 stanowi krok w tym kierunku. Przed wersją V2.1 Apache Doris przechowywał częściowo ustrukturyzowane dane jako pliki JSON. Jednak podczas wykonywania zapytań analizowanie danych JSON w czasie rzeczywistym prowadzi do wysokiego zużycia procesora i operacji we / wy, a także dużych opóźnień zapytań, zwłaszcza gdy zbiór danych jest ogromny i skomplikowany. Co więcej, brak wstępnie zdefiniowanego schematu oznacza, że nie ma możliwości optymalizacji zapytań.
Nowo dodany typ danych: Variant
W Apache Doris 2.1.0 wprowadziliśmy nowy typ danych: Variant. Pola typu danych Variant mogą zawierać liczby całkowite, ciągi znaków, wartości logiczne i dowolną ich kombinację. Dzięki Variant nie trzeba z góry definiować konkretnych kolumn w schemacie tabeli.
Typ danych Variant dobrze nadaje się do obsługi zagnieżdżonych struktur, które mają tendencję do dynamicznych zmian. Po zapisaniu danych typ Variant automatycznie pobiera informacje o kolumnach na podstawie danych i ich struktury w kolumnach, a następnie łączy je z istniejącym schematem tabeli. Przechowuje klucze JSON i odpowiadające im wartości jako dynamiczne podkolumny.
Tymczasem w tej samej tabeli można umieścić zarówno kolumny Variant, jak i kolumny statyczne predefiniowanych typów danych. Ta metoda Schema-on-Write zapewnia większą elastyczność w przechowywaniu i zapytaniach. Zasilany przez kolumnową pamięć masową, wektorowy silnik wykonawczy i optymalizator zapytań Doris, typ Variant zapewnia wysoką wydajność zapytań i pamięci masowej.
W porównaniu do typu JSON, przechowywanie danych w typie Variant pozwala zaoszczędzić do 65% miejsca na dysku i 8-krotnie zwiększyć szybkość zapytań. (Proszę zapoznać się ze szczegółami w dalszej części tego wpisu)
Przewodnik użytkowania
Utwórz tabelę: słowo kluczowe składni variant
-- No index
CREATE TABLE IF NOT EXISTS ${table_name} (
k BIGINT,
v VARIANT
)
table_properties;
-- Create index for the v column, specify the parser
CREATE TABLE IF NOT EXISTS ${table_name} (
k BIGINT,
v VARIANT,
INDEX idx_var(v) USING INVERTED [PROPERTIES("parser" = "english|unicode|chinese")] [COMMENT 'your comment']
)
table_properties;
-- Create Bloom Filter for the v column
CREATE TABLE IF NOT EXISTS ${table_name} (
k BIGINT,
v VARIANT
)
...
properties("replication_num" = "1", "bloom_filter_columns" = "v");Zapytanie: dostęp do podkolumny poprzez []. Podkolumny są również typu Variant.
SELECT v["properties"]["title"] from ${table_name}Teraz pokażemy Państwu, jak utworzyć tabelę zawierającą typ danych Variant i przeprowadzić pozyskiwanie danych oraz zapytania do niej. Zbiór danych to rekordy GitHub Events. To jest jeden ze sformatowanych rekordów:
{
"id": "14186154924",
"type": "PushEvent",
"actor": {
"id": 282080,
"login": "brianchandotcom",
"display_login": "brianchandotcom",
"gravatar_id": "",
"url": "https://api.github.com/users/brianchandotcom",
"avatar_url": "https://avatars.githubusercontent.com/u/282080?"
},
"repo": {
"id": 1920851,
"name": "brianchandotcom/liferay-portal",
"url": "https://api.github.com/repos/brianchandotcom/liferay-portal"
},
"payload": {
"push_id": 6027092734,
"size": 4,
"distinct_size": 4,
"ref": "refs/heads/master",
"head": "91edd3c8c98c214155191feb852831ec535580ba",
"before": "abb58cc0db673a0bd5190000d2ff9c53bb51d04d",
"commits": [""]
},
"public": true,
"created_at": "2020-11-13T18:00:00Z"
}1. Proszę utworzyć tabelę
- Proszę utworzyć 3 kolumny typu Variant:
actor,repoorazpayload - W międzyczasie proszę utworzyć odwrócony indeks dla pliku
payloadkolumny:idx_payload USING INVERTEDokreśla indeks jako indeks odwrócony, co przyspiesza filtrowanie warunkowe na podkolumnach.
CREATE DATABASE test_variant;
USE test_variant;
CREATE TABLE IF NOT EXISTS github_events (
id BIGINT NOT NULL,
type VARCHAR(30) NULL,
actor VARIANT NULL,
repo VARIANT NULL,
payload VARIANT NULL,
public BOOLEAN NULL,
created_at DATETIME NULL,
INDEX idx_payload (`payload`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for payload'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(id) BUCKETS 10
properties("replication_num" = "1");Uwaga: Jeśli Payload kolumna ma zbyt wiele podkolumn, tworzenie indeksów na niej może prowadzić do nadmiernej liczby kolumn indeksu i zmniejszenia wydajności zapisu danych. Jeśli analiza danych obejmuje tylko zapytania o równoważność, zaleca się utworzenie indeksu Bloom Filter na kolumnach Variant. Może to przynieść lepszą wydajność niż indeks odwrócony. W przypadku pojedynczej kolumny Variant, jeśli właściwości parsowania są takie same, ale mają Państwo wiele wymagań dotyczących parsowania, można zreplikować kolumnę i określić różne indeksy dla każdej z nich.
2. Pozyskiwanie danych przez ładowanie strumieniowe
Proszę załadować gh_2022-11-07-3.json który jest zapisem zdarzeń GitHub z godziny. Jeden sformatowany wiersz wygląda następująco:
wget http://doris-build-hk-1308700295.cos.ap-hongkong.myqcloud.com/regression/variant/gh_2022-11-07-3.json
curl --location-trusted -u root: -T gh_2022-11-07-3.json -H "read_json_by_line:true" -H "format:json" http://127.0.0.1:18148/api/test_variant/github_events/_strea
m_load
{
"TxnId": 2,
"Label": "086fd46a-20e6-4487-becc-9b6ca80281bf",
"Comment": "",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 139325,
"NumberLoadedRows": 139325,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 633782875,
"LoadTimeMs": 7870,
"BeginTxnTimeMs": 19,
"StreamLoadPutTimeMs": 162,
"ReadDataTimeMs": 2416,
"WriteDataTimeMs": 7634,
"CommitAndPublishTimeMs": 55
}Proszę sprawdzić, czy ładowanie danych powiodło się:
-- Check the number of rows
mysql> select count() from github_events;
+----------+
| count(*) |
+----------+
| 139325 |
+----------+
1 row in set (0.25 sec)
-- View a random row
mysql> select * from github_events limit 1;
+-------------+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------+---------------------+
| id | type | actor | repo | payload | public | created_at |
+-------------+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------+---------------------+
| 25061821748 | PushEvent | {"gravatar_id":"","display_login":"jfrog-pipelie-intg","url":"https://api.github.com/users/jfrog-pipelie-intg","id":98024358,"login":"jfrog-pipelie-intg","avatar_url":"https://avatars.githubusercontent.com/u/98024358?"} | {"url":"https://api.github.com/repos/jfrog-pipelie-intg/jfinte2e_1667789956723_16","id":562683829,"name":"jfrog-pipelie-intg/jfinte2e_1667789956723_16"} | {"commits":[{"sha":"334433de436baa198024ef9f55f0647721bcd750","author":{"email":"98024358+jfrog-pipelie-intg@users.noreply.github.com","name":"jfrog-pipelie-intg"},"message":"commit message 10238493157623136117","distinct":true,"url":"https://api.github.com/repos/jfrog-pipelie-intg/jfinte2e_1667789956723_16/commits/334433de436baa198024ef9f55f0647721bcd750"}],"before":"f84a26792f44d54305ddd41b7e3a79d25b1a9568","head":"334433de436baa198024ef9f55f0647721bcd750","size":1,"push_id":11572649828,"ref":"refs/heads/test-notification-sent-branch-10238493157623136113","distinct_size":1} | 1 | 2022-11-07 11:00:00 |
+-------------+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------+---------------------+
1 row in set (0.23 sec) Proszę wyświetlić informacje o schemacie poprzez desc. Podkolumny zostaną automatycznie rozszerzone w warstwie przechowywania, a typy danych podkolumn zostaną automatycznie wywnioskowane.
-- No display of extended columns
mysql> desc github_events;
+------------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-------+---------+-------+
| id | BIGINT | No | true | NULL | |
| type | VARCHAR(30) | Yes | false | NULL | NONE |
| actor | VARIANT | Yes | false | NULL | NONE |
| repo | VARIANT | Yes | false | NULL | NONE |
| payload | VARIANT | Yes | false | NULL | NONE |
| public | BOOLEAN | Yes | false | NULL | NONE |
| created_at | DATETIME | Yes | false | NULL | NONE |
+------------+-------------+------+-------+---------+-------+
7 rows in set (0.01 sec)
-- Displaying extended columns of Variant columns
mysql> set describe_extend_variant_column = true;
Query OK, 0 rows affected (0.01 sec)
mysql> desc github_events;
+----------------------------------------+------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------------------------------+------------+------+-------+---------+-------+
| id | BIGINT | No | true | NULL | |
| type | VARCHAR(*) | Yes | false | NULL | NONE |
| actor | VARIANT | Yes | false | NULL | NONE |
| actor.avatar_url | TEXT | Yes | false | NULL | NONE |
| actor.display_login | TEXT | Yes | false | NULL | NONE |
| actor.id | INT | Yes | false | NULL | NONE |
| actor.login | TEXT | Yes | false | NULL | NONE |
| actor.url | TEXT | Yes | false | NULL | NONE |
| created_at | DATETIME | Yes | false | NULL | NONE |
| payload | VARIANT | Yes | false | NULL | NONE |
| payload.action | TEXT | Yes | false | NULL | NONE |
| payload.before | TEXT | Yes | false | NULL | NONE |
| payload.comment.author_association | TEXT | Yes | false | NULL | NONE |
| payload.comment.body | TEXT | Yes | false | NULL | NONE |
....
+----------------------------------------+------------+------+-------+---------+-------+
406 rows in set (0.07 sec)Dzięki funkcji desc można określić partycję, której schemat ma zostać sprawdzony:
DESCRIBE ${table_name} PARTITION ($partition_name);3. Zapytanie
Proszę zauważyć: Podczas filtrowania i agregowania podkolumn wymagana jest dodatkowa operacja CAST w celu zapewnienia spójności typu danych. Dzieje się tak, ponieważ typy przechowywania mogą nie być stałe, a operacja CAST wyrażenie w SQL może ujednolicić typy danych. Na przykład, SELECT * FROM tbl WHERE CAST(var['title'] AS TEXT) MATCH 'hello world'.
Poniżej znajdują się proste przykłady zapytań dotyczących kolumn Variant:
1. Proszę pobrać 5 najlepszych repozytoriów z największą liczbą gwiazdek od github_events.
mysql> SELECT
-> cast(repo["name"] as text) as repo_name, count() AS stars
-> FROM github_events
-> WHERE type = 'WatchEvent'
-> GROUP BY repo_name
-> ORDER BY stars DESC LIMIT 5;
+--------------------------+-------+
| repo_name | stars |
+--------------------------+-------+
| aplus-framework/app | 78 |
| lensterxyz/lenster | 77 |
| aplus-framework/database | 46 |
| stashapp/stash | 42 |
| aplus-framework/image | 34 |
+--------------------------+-------+
5 rows in set (0.03 sec)2. Proszę policzyć liczbę zdarzeń zawierających słowo kluczowe doris.
mysql> SELECT
-> count() FROM github_events
-> WHERE cast(payload['comment']['body'] as text) MATCH 'doris';
+---------+
| count() |
+---------+
| 3 |
+---------+
1 row in set (0.04 sec)3. Proszę sprawdzić ID zgłoszenia, które ma najwięcej komentarzy i repozytorium, do którego należy.
mysql> SELECT
-> cast(repo["name"] as string) as repo_name,
-> cast(payload["issue"]["number"] as int) as issue_number,
-> count() AS comments,
-> count(
-> distinct cast(actor["login"] as string)
-> ) AS authors
-> FROM github_events
-> WHERE type = 'IssueCommentEvent' AND (cast(payload["action"] as string) = 'created') AND (cast(payload["issue"]["number"]as int) > 10)
-> GROUP BY repo_name, issue_number
-> HAVING authors >= 4
-> ORDER BY comments DESC, repo_name
-> LIMIT 50;
+--------------------------------------+--------------+----------+---------+
| repo_name | issue_number | comments | authors |
+--------------------------------------+--------------+----------+---------+
| facebook/react-native | 35228 | 5 | 4 |
| swsnu/swppfall2022-team4 | 27 | 5 | 4 |
| belgattitude/nextjs-monorepo-example | 2865 | 4 | 4 |
+--------------------------------------+--------------+----------+---------+
3 rows in set (0.03 sec)4. Uwagi
Na podstawie wyników naszych testów można śmiało stwierdzić, że nie ma różnicy w wydajności między dynamicznymi kolumnami Variant a wstępnie zdefiniowanymi kolumnami statycznymi. Jednak w przypadku przetwarzania danych dziennika, gdy użytkownicy muszą dodawać pola do tabeli, takie jak etykiety kontenerów w Kubernetes, parsowanie JSON i wnioskowanie o typie podczas zapisu danych powodują dodatkowy narzut.
Aby zachować równowagę między elastycznością a wydajnością typu danych Variant, zalecamy utrzymanie liczby kolumn poniżej 1000. Niewielka liczba kolumn zmniejszy narzut spowodowany parsowaniem danych i wnioskowaniem o typie, a tym samym zwiększy wydajność zapisu danych.
Zaleca się również zapewnienie spójności typów pól, gdy tylko jest to możliwe. Wynika to z faktu, że Doris automatycznie wykonuje konwersję zgodnych typów w celu ujednolicenia pól różnych typów danych. Jeśli nie znajdzie zgodnego typu, przekonwertuje dane na typ JSONB, co może spowodować obniżenie wydajności w porównaniu do typu int lub tekstowego.
Variant vs. JSON
Aby sprawdzić, jak nowo dodany typ Variant wpływa na przechowywanie danych i zapytania, przeprowadziliśmy testy porównawcze wstępnie zdefiniowanych kolumn statycznych, kolumn Variant i kolumn JSON za pomocą ClickBench.
Środowisko testowe: 16 rdzeni, 64GB, instancja AWS EC2, 1TB ESSD
Wynik testu:
1. Miejsce do przechowywania
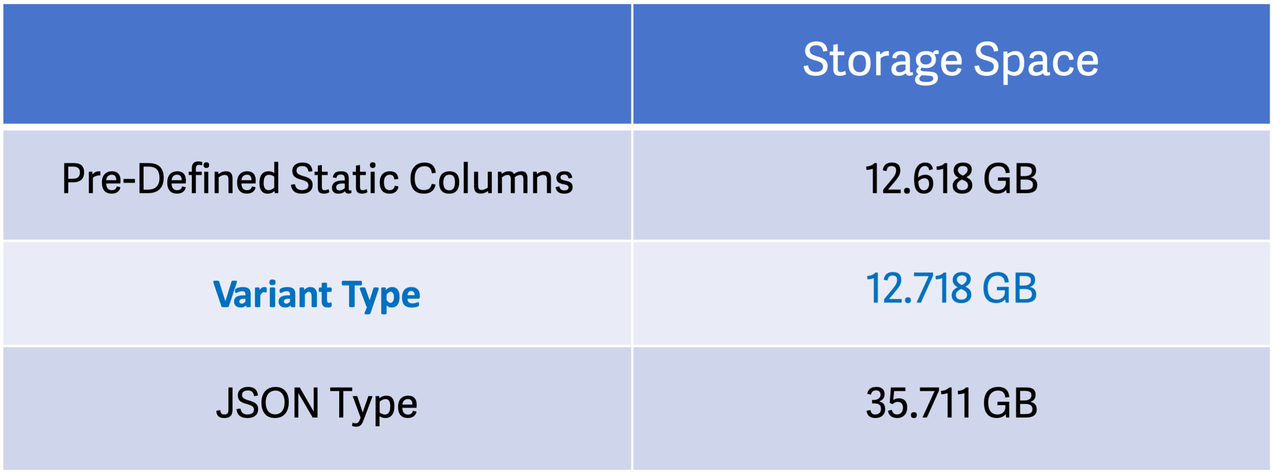
Jak pokazują wyniki, przechowywanie danych jako kolumn Variant zajmuje podobną przestrzeń dyskową, jak przechowywanie ich jako wstępnie zdefiniowanych kolumn statycznych. W porównaniu z typem JSON, typ Variant wymaga 65% mniej miejsca. Innymi słowy, typ Variant zajmuje tylko jedną trzecią przestrzeni dyskowej, którą zajmuje JSON. Różnica będzie jeszcze bardziej zauważalna w przypadku danych o niskiej kardynalności ze względu na przechowywanie kolumnowe.
2. Wydajność zapytań
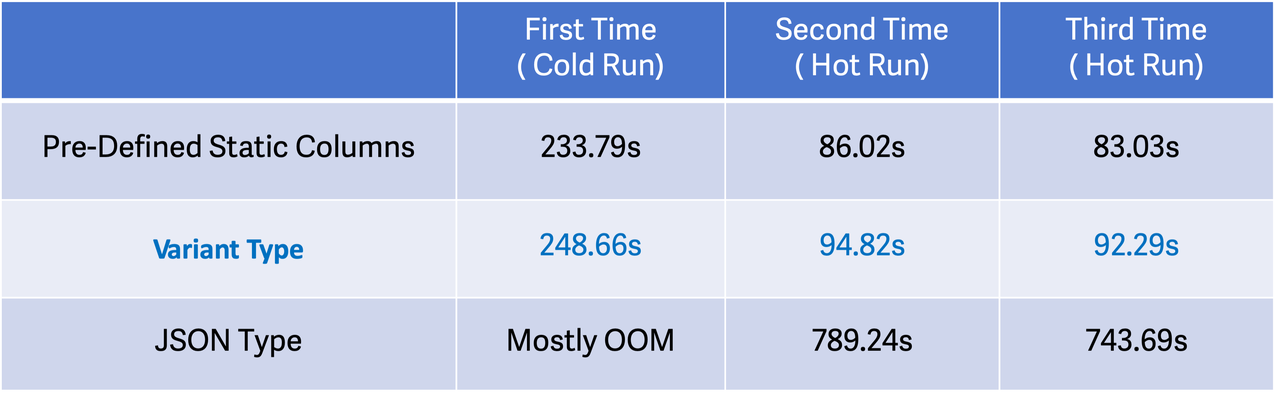
Przetestowaliśmy 43 Clickbench Zapytania SQL. Zapytania dotyczące kolumn Variant są o około 10% wolniejsze niż te dotyczące wstępnie zdefiniowanych kolumn statycznych i 8 razy szybsze niż te na JSON kolumny. (Z powodów I/O, większość zimnych przebiegów na danych JSONB nie powiodła się z OOM).
Projektowanie i wdrażanie wariantów
1. Pisanie danych i wnioskowanie o typie
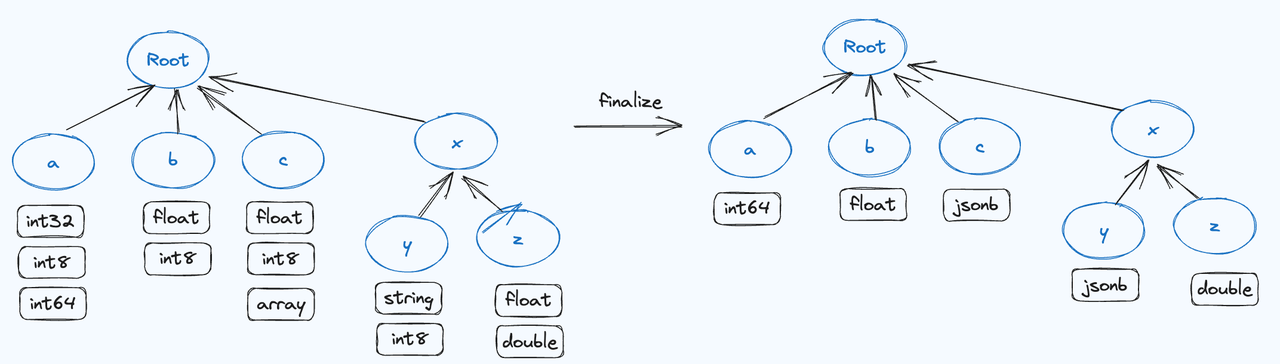
W Apache Doris jest to normalny proces zapisu: sortowanie danych, scalanie i generowanie pliku Segment w Memtable. Zapis wariantów działa podobnie. Obejmuje on wnioskowanie o typie i scalanie danych tych samych kluczy JSON w Memtable, co skutkuje utworzeniem drzewa prefiksów. Drzewo przechowuje informacje o typie i kolumnie każdego pola JSON i łączy wszystkie informacje o typie tej samej kolumny w najmniej wspólny typ, generuje kolumny, koduje je do formatów przechowywania Doris i dołącza je do segmentu.
Każdy plik segmentu zawiera nie tylko dane po zakodowaniu typu i zagęszczeniu, ale także metadane dynamicznie generowanych kolumn. Taka konstrukcja zapewnia integralność danych i możliwość zapytań, jednocześnie poprawiając wydajność przechowywania. Dzięki wnioskowaniu o typie i łączeniu w pamięci, typ Variant znacznie zmniejsza zużycie miejsca na dysku w porównaniu do tradycyjnego przechowywania surowego tekstu.
2. Zmiana kolumny (dodanie kolumny lub zmiana typu kolumny)
Podczas procesu zapisu wszystkie metadane i dane węzłów liści w drzewie prefiksów zostaną dołączone do pliku Segment, a metadane zestawów wierszy zostaną scalone. Poniżej znajduje się przykład procesu scalania:

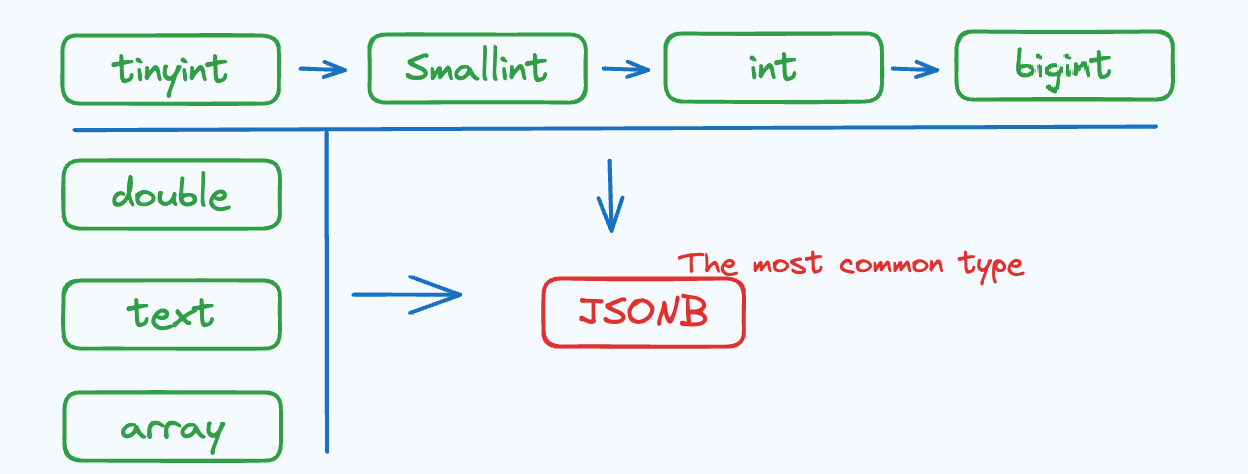
Ostatecznie zestaw wierszy będzie używał rozszerzenia Least Common Column Schema jako metadanych po scaleniu danych. (Najmniej powszechny schemat kolumn to schemat z największą liczbą podkolumn i typem podkolumny będącym najmniej powszechnym typem). Pozwala to na dynamiczne rozszerzanie kolumn i zmiany typu.
W oparciu o ten mechanizm przechowywany schemat dla Variant można uznać za oparty na danych. Oferuje on większą elastyczność w porównaniu do procesu zmiany schematu w Doris. Poniższy diagram ilustruje kierunki zmian typów (zmiany typów mogą być wykonywane tylko w kierunku wskazanym strzałkami, przy czym JSONB jest typem wspólnym dla wszystkich typów):
3. Przyspieszenie indeksów i zapytań
W Variant węzły liści są przechowywane w formacie kolumnowym w pliku Segment, który jest dokładnie taki sam jak format przechowywania statycznych predefiniowanych kolumn. W związku z tym zapytania dotyczące kolumn Variant można również przyspieszyć za pomocą kodowania słownikowego, wektoryzacji i indeksów (ZoneMap, odwrócony indeks, BloomFilter itp.). Ponieważ ta sama kolumna może mieć różne typy w różnych plikach, użytkownicy muszą określić typ jako podpowiedź podczas wykonywania zapytania. Oto przykładowe zapytanie:
-- var['title'] is to access the 'title' sub-column of var, which is a Variant column. If there is inverted index for var, the queries will be accelerated by inverted index.
SELECT * FROM tbl where CAST(var['titile'] as text) MATCH "hello world"
-- If there is Bloom Filter for var, equivalence queries will be accelerated by Bloom Filter.
SELECT * FROM tbl where CAST(var['id'] as bigint) = 1010101Predykaty zostaną zepchnięte w dół do warstwy przechowywania (Segment), gdzie typ przechowywania jest sprawdzany względem typu docelowego operacji CAST. Jeśli typy są zgodne, wykorzystany zostanie bardziej wydajny mechanizm filtrowania predykatów. Takie podejście redukuje niepotrzebny odczyt i konwersję danych, poprawiając tym samym wydajność zapytań.
4. Optymalizacja pamięci masowej dla rzadkich kolumn
Przykłady rzadkich kolumn JSON:
{"a":[1], "b":2, "c":3, "x_1" : 1,"x_2": "3"}
{"a":1, "b":2, "c":3, "x_1" : 1,"x_2": "3"}
{"a":4, "b":5, "c":6, "x_3" : 1,"x_4": "3"}
{"a":7, "b":8, "c":9, "x_5" : 1,"x_6": "3"}
...The a, b, c kolumny są gęste. Są one zawarte w prawie każdym wierszu. Podczas gdy x_? kolumny są nieliczne. Tylko kilka z nich nie ma wartości null. Jeśli system będzie przechowywał każdą kolumnę w sposób kolumnowy, będzie odczuwał ogromną presję na przechowywanie i eksplodującą metę.
Aby rozwiązać ten problem, Doris wykrywa rzadkość kolumn na podstawie procentu wartości null podczas pobierania danych. Bardzo rzadkie kolumny (z wysokim odsetkiem wartości null) zostaną spakowane do kodowania JSONB i zapisane w osobnej kolumnie.
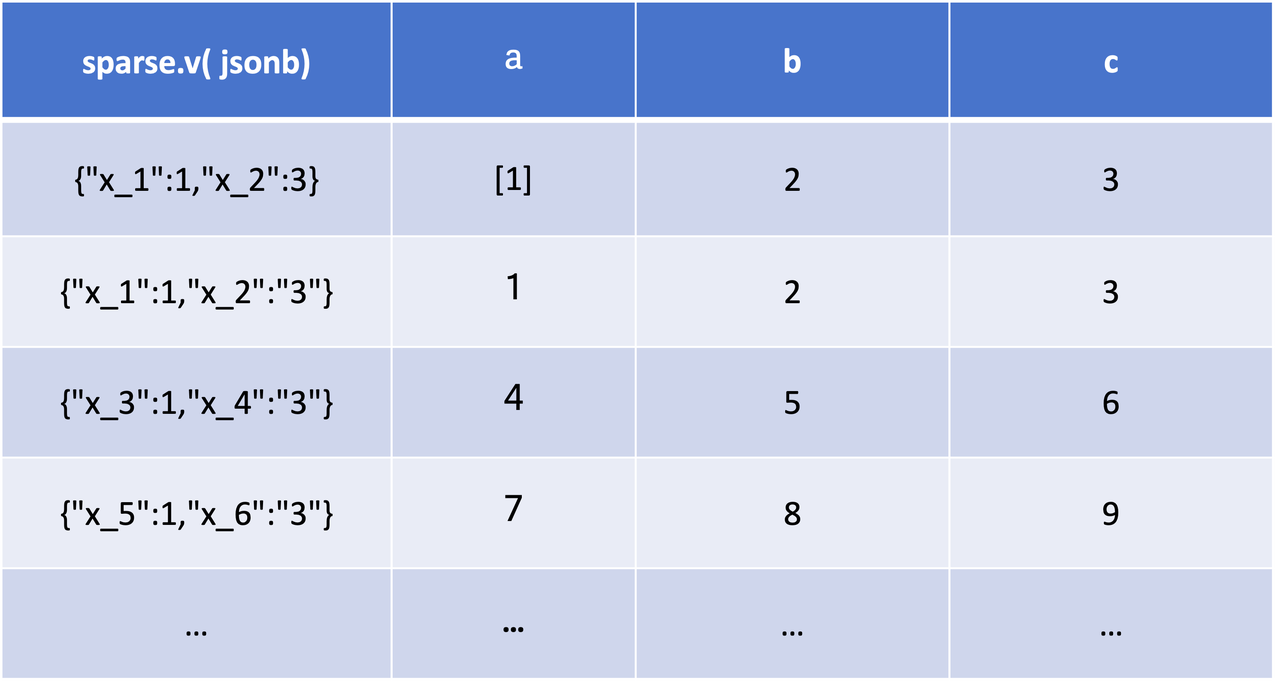
Taka optymalizacja przechowywania rzadkich kolumn zmniejszy presję na meta i zagęszczanie danych oraz zwiększy elastyczność.
Zapytania dotyczące nieliczbowanych kolumn są implementowane dokładnie w taki sam sposób, jak zapytania dotyczące innych kolumn.
Przypadek użycia
GuanceDB, platforma obserwowalności, wykorzystywała rozwiązanie oparte na Elasticsearch do przechowywania logów i danych o zachowaniu użytkowników. Jednak Elasticsearch ma niewystarczającą obsługę schematów, więc jest nieefektywny w przetwarzaniu dużych ilości pól zdefiniowanych przez użytkownika. W ramach mechanizmu dynamicznego mapowania w Elasticsearch częste konflikty typów pól prowadziły do utraty danych i wymagały wielu interwencji człowieka. W międzyczasie proces zapisu w Elasticsearch wymagał dużej ilości zasobów, a wydajność masowej agregacji danych była mniejsza niż idealna.
W celu ulepszenia architektury danych, GuanceDB współpracuje z VeloDB i buduje rozwiązanie obserwowalności oparte na Apache Doris. Wykorzystują one typ danych Variant do realizacji zmian schematu opartych na partycjach, co jest bardziej elastyczne i wydajne. Ponadto Doris nie nakłada górnego limitu na liczbę kolumn, co oznacza, że może lepiej obsługiwać dane bez schematu.
Rozwiązanie oparte na Doris zapewnia również niższe zużycie procesora podczas zapisu danych i większą szybkość w skomplikowanych agregacjach danych (przyspieszane przez odwrócony indeks i techniki optymalizacji zapytań). Po aktualizacji, GuanceDB zmniejszyła koszty maszynowe o 70% i podwoiła ogólną szybkość zapytań, z ponad 4-krotnym wzrostem wydajności w prostych zapytaniach.
Wnioski
Typ danych Variant został przetestowany przez wielu użytkowników przed oficjalnym wydaniem Apache Doris 2.1.0. Teraz jest dostępny produkcyjnie. W przyszłości planujemy wprowadzić więcej lekkich zmian dla Variant, aby ułatwić modelowanie danych.
Aby uzyskać więcej informacji na temat Variant i przewodników na temat tworzenia pół-strukturalnego rozwiązania do analizy danych dla Państwa przypadku, prosimy porozmawiać z Zespół programistów Apache Doris.