
Firma badawcza Forrester definiuje platformy strumieniowania danych jako nową kategorię oprogramowania w nowym raporcie Forrester Wave. Apache Kafka jest de facto standardem używanym przez ponad 100 000 organizacji. Wielu dostawców oferuje platformy Kafka i usługi w chmurze. Pojawiło się wiele uzupełniających się frameworków przetwarzania strumieniowego typu open-source, takich jak Apache Flink i powiązane oferty chmurowe. Konkurencyjne technologie, takie jak Pulsar, Redpanda czy WarpStream, próbują zdobyć udział w rynku, wykorzystując protokół Kafka. Ten wpis na blogu analizuje krajobraz strumieniowego przesyłania danych w 2024 r., aby podsumować istniejące rozwiązania i trendy rynkowe. Na końcu artykułu przedstawiono prognozy dotyczące potencjalnych nowych uczestników rynku w 2025 roku.

Dołącz do społeczności strumieniowego przesyłania danych i bądź na bieżąco z nowymi wpisami na blogu przez subskrybując mój newsletter.
Strumieniowe przesyłanie danych to nowa kategoria oprogramowania
Dane w czasie rzeczywistym przewyższają dane powolne. Dotyczy to niemal wszystkich przypadków użycia w każdej branży. Aplikacje sterowane zdarzeniami oparte na strumieniowym przesyłaniu danych to nowy trend. Takie podejście zwiększa wartość biznesową jako ogólny cel poprzez zwiększenie przychodów, redukcję kosztów, zmniejszenie ryzyka lub poprawę jakości obsługi klienta.
Istnieje wiele kategorii oprogramowania i powiązanych platform danych do przetwarzania i analizowania danych:
- Baza danych: Przechowywanie i wykonywanie obciążeń transakcyjnych.
- Hurtownia danych: Przetwarzanie ustrukturyzowanych danych historycznych w celu tworzenia powtarzających się raportów i unikalnych spostrzeżeń.
- Data Lake: Przetwarzanie ustrukturyzowanych i częściowo lub nieustrukturyzowanych dużych zbiorów danych za pomocą przetwarzania wsadowego w celu tworzenia powtarzających się raportów i unikalnych spostrzeżeń.
- Lakehouse: Połączenie hurtowni danych i jeziora danych w celu przetwarzania wszystkich danych na jednej platformie.
- Strumieniowe przesyłanie danych: Ciągłe przetwarzanie danych w ruchu i zapewnienie spójności danych w różnych paradygmatach komunikacji (takich jak czas rzeczywisty, wsadowy i żądanie-odpowiedź) zamiast przechowywania i analizowania danych tylko w spoczynku.
Oczywiście te platformy danych często nieco się pokrywają. Stworzyłem kompletną serię blogów badających przypadki użycia i ich wzajemne uzupełnianie się.
- Hurtownia danych vs. Data Lake vs. Data Streaming – przyjaciele, wrogowie, frenemies?
- Strumieniowe przesyłanie danych do hurtowni danych i jeziora danych
- Modernizacja hurtowni danych: Od starszej infrastruktury lokalnej do infrastruktury natywnej dla chmury
- Studia przypadków: Strumieniowe przesyłanie danych natywne dla chmury w celu modernizacji hurtowni danych
- Wnioski wyciągnięte z budowania natywnej dla chmury hurtowni danych
The Forrester Wave™: Platformy strumieniowego przesyłania danych, 4. kwartał 2023 r.
Forrester jest wiodącą firmą badawczą i doradczą, która zapewnia wgląd i analizę różnych aspektów technologii, biznesu i trendów rynkowych.
Firma znana jest z dogłębnych analiz, raportów z badań rynkowych i ram, które pomagają organizacjom poruszać się w szybko zmieniającym się krajobrazie technologii i biznesu. Firmy i liderzy IT często korzystają z badań Forrester, aby zrozumieć trendy rynkowe, ocenić rozwiązania technologiczne i opracować strategie, aby pozostać konkurencyjnymi w swoich branżach.
W grudniu 2023 roku firma badawcza opublikowała “The Forrester Wave™: Streaming Data Platforms, Q4 2023”. Proszę pobrać bezpłatny dostęp do raportu tutaj. Liderami są Microsoft, Google i Confluent, a następnie Oracle, Amazon, Cloudera i kilka innych.
Mogą Państwo zgadzać się lub nie ze stanowiskiem konkretnego dostawcy w odniesieniu do jego oferty lub siły strategii. Jednak pojawienie się tej nowej fali jest dowodem na to, że strumieniowe przesyłanie danych to nowa kategoria oprogramowania, a nie tylko kolejny hype lub narzędzie ETL / ESB / iPaaS nowej generacji.
Przypadki użycia strumieniowego przesyłania danych według wartości biznesowej
Nowa kategoria oprogramowania otwiera przypadki użycia i dodaje wartość biznesową we wszystkich branżach:
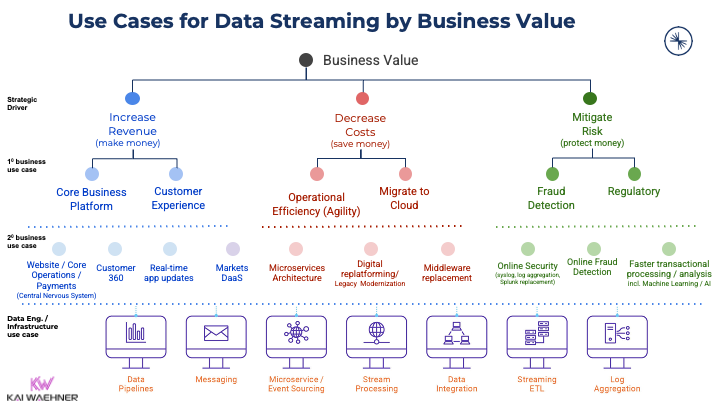
Dodawanie wartości biznesowej ma kluczowe znaczenie dla każdego przedsiębiorstwa. Przy tak wielu potencjalnych przypadkach użycia, nie jest zaskoczeniem, że coraz więcej producentów oprogramowania dodaje obsługę Kafki do swoich produktów. Proszę wyszukać na moim blogu swoją ulubioną branżę, aby znaleźć wiele studiów przypadków i architektur. Lub proszę przeczytać o przypadkach użycia Apache Kafka w różnych branżach aby rozpocząć.
Krajobraz strumieniowego przesyłania danych w 2024 r.
Strumieniowe przesyłanie danych to osobna kategoria oprogramowania platform danych. Wielu dostawców oprogramowania zbudowało całą swoją działalność wokół tej kategorii. Krajobraz strumieniowego przesyłania danych pokazuje, że większość dostawców korzysta z Kafki lub implementuje jej protokół, ponieważ Apache Kafka stała się de facto standardem strumieniowego przesyłania danych.
W ciągu ostatnich kilku lat w tej kategorii pojawiły się nowe firmy programistyczne. Kilku dojrzałych graczy na rynku danych dodało wsparcie dla strumieniowego przesyłania danych na swoich platformach lub w ekosystemie usług w chmurze. Większość dostawców oprogramowania wykorzystuje Kafkę w swoich platformach do strumieniowego przesyłania danych. Istnieje jednak coś więcej niż Kafka. Niektórzy dostawcy używają tylko protokołu Kafka (Azure Event Hubs) lub zupełnie innych interfejsów API (jak Amazon Kinesis).
Poniższe zestawienie Data Streaming Landscape 2024 podsumowuje aktualny stan odpowiednich produktów i usług w chmurze.

Proszę zauważyć: Celowo nie jest to pełna lista frameworków, usług w chmurze lub dostawców. Nie jest to oficjalny krajobraz badawczy. Nie zawiera dowodów statystycznych. Jeśli Państwa ulubionej technologii nie ma na tym diagramie, to nie widziałem jej w moich rozmowach z klientami, potencjalnymi klientami, partnerami, analitykami lub szerszą społecznością strumieniowego przesyłania danych.
Proszę również zauważyć, że skupiam się na ogólnej infrastrukturze strumieniowego przesyłania danych. Istnieją doskonałe rozwiązania do wykorzystywania i analizowania danych strumieniowych w określonych scenariuszach, takich jak bazy danych szeregów czasowych, silniki uczenia maszynowego lub platformy obserwowalności. Są one komplementarne i często połączone z klastrem strumieniowym.
Modele wdrażania: Samodzielnie zarządzane vs. w pełni zarządzane
Istnieją różne kategorie strumieniowego przesyłania danych w odniesieniu do modelu wdrażania:
- Samozarządzanie: Węzły takie jak Kafka Broker, Kafka Connect i Schema Registry można obsługiwać samodzielnie za pomocą ulubionych skryptów i narzędzi. Może to odbywać się lokalnie lub w chmurze publicznej w Państwa VPC.
- Częściowo zarządzane: Zmniejszenie obciążenia operacyjnego poprzez natywną platformę chmurową (zwykle Kubernetes) i powiązane narzędzia operatorskie, które automatyzują zadania operacyjne, takie jak aktualizacje kroczące lub równoważenie partycji Kafka. Może to odbywać się lokalnie lub w chmurze publicznej, w Państwa VPC lub w VPC dostawcy.
- W pełni zarządzane: Proszę skorzystać z (prawdziwie) w pełni zarządzanych ofert SaaS, które wykonują 100% operacji i zapewniają krytyczne umowy SLA oraz wsparcie, aby skupić się na integracji i logice biznesowej.
Co z usługą Bring Your Own Cloud (BYOC)?
Niektórzy dostawcy oferują czwarty model wdrożenia: Bring Your Own Cloud (BYOC), czyli podejście, w którym dostawca oprogramowania obsługuje klaster w Państwa środowisku. BYOC to model wdrożenia, który plasuje się gdzieś pomiędzy usługą chmurową SaaS a samodzielnie zarządzanym wdrożeniem.
NIE wierzę w to podejście, ponieważ w przypadku BYOC istnieje zbyt wiele pytań i wyzwań związanych z bezpieczeństwem, wsparciem i umowami SLA w przypadku biletów P1 i P2 oraz przestojów. Dlatego umieściłem to w kategorii samodzielnie zarządzanych. Tak właśnie jest, nawet jeśli sprzedawca dotyka Państwa infrastruktury. Ostatecznie to Państwo ponoszą ryzyko, ponieważ muszą i chcą kontrolować swoje środowisko.
Jack Vanlightly napisał doskonały artykuł “O przyszłości usług w chmurze i BYOC.” Jack bada następujące mity:
- Mit 1: BYOC zapewnia lepsze bezpieczeństwo dzięki przechowywaniu danych na koncie użytkownika.
- Mit 2: BYOC jest tańszy, z niższym całkowitym kosztem posiadania (TCO).
Podsumowuję historię tymi dwoma rysunkami i gorąco polecam przeczytanie szczegółowego artykułu Jacka na temat BYOC i jego kompromisów:

Źródło: Jack Vanlightly

Oto konkluzja Jacka: “Tak jak klienci odeszli od stawiania własnego sprzętu, aby przenieść się do chmury, tak ci, którzy próbują BYOC, będą podobnie migrować do SaaS ze względu na jego prostotę, niezawodność, skalowalność i opłacalność.” W pełni się z Panem zgadzam.
Kategorie streamingu: Natywna Kafka vs. Kompatybilność protokołów vs. Przetwarzanie strumieniowe
Apache Kafka stała się de facto standardem strumieniowego przesyłania danych, podobnie jak Amazon S3 jest de facto standardem przechowywania obiektów:

Kiedy badają Państwo świat strumieniowego przesyłania danych, nie sposób nie spojrzeć na ekosystem Apache Kafka.
Krajobraz strumieniowania danych obejmuje trzy kategorie strumieniowania:
- Natywny Apache Kafka: Produkt lub usługa w chmurze wykorzystuje platformę open-source do przesyłania wiadomości w czasie rzeczywistym i przechowywania zdarzeń. Interfejs API Kafka jest w 100% zgodny. Nie obejmuje Kafka Streams i Kafka Connect; wielu dostawców wyklucza te funkcje Kafka.
- Protokół Kafka: Produkt lub usługi w chmurze implementują własny kod, ale obsługują interfejs API Kafka. Oferty te zazwyczaj NIE są w 100% zgodne. Zazwyczaj Kafka Connect i Kafka Streams nie są częścią oferty.
- Przetwarzanie strumieniowe: Frameworki i usługi w chmurze korelują dane w sposób bezstanowy lub stanowy. Rozwiązania są natywne dla Kafki, współpracują z protokołem Kafka lub działają całkowicie niezależnie.
Naprawdę trudno jest zdefiniować te kategorie. Na przykład, mógłbym dodać kolejną sekcję dla Kafka Connect lub bardziej ogólnie, integracji danych. Kolejna debata dotyczy tego, jak wyjaśnić, czy dostawca obsługuje pełne API Kafka (z lub bez Kafka Connect lub Kafka Streams). Nie chcę jednak tworzyć niekończącej się listy rozwiązań. Dlatego też skupię się na protokole Kafka (będącym de facto standardem przesyłania i przechowywania wiadomości) i powiązanym przetwarzaniu strumieniowym za pomocą technologii Kafka i innych niż Kafka.
Zmiany w krajobrazie strumieniowego przesyłania danych w latach 2023-2024
Moim celem NIE jest rosnący krajobraz z dziesiątkami, a nawet setkami dostawców i usług w chmurze. Wiele z tych obrazów już istnieje. Zamiast tego skupiam się na kilku technologiach, dostawcach i ofertach bezserwerowych, które naprawdę widzę w praktyce, z podekscytowaniem szerszej społeczności open source i chmury. W związku z tym wprowadzono następujące zmiany w porównaniu z krajobrazem strumieniowego przesyłania danych 2023 opublikowanym rok temu:
Zastąpiono
- Kategoria: Zmieniłem “Non-Kafka” na “Stream Processing”, aby skupić się na strumieniowym przesyłaniu danych, nie uwzględniając podstawowych rozwiązań do przesyłania wiadomości, takich jak Google Pub/Sub czy Amazon Kinesis.
- Red Hat: Zmiana strategii w IBM (ponownie). Red Hat zamyka swoją ofertę chmurową “Red Hat OpenShift Streams for Apache Kafka” i przenosi rozmowy na produkty IBM. Zastąpiłem logo firmą IBM, która nadal oferuje produkty chmurowe Kafka. Ale żeby było jasne: Red Hat AMQ Streams (tj. samodzielnie zarządzany operator Kafka + Strimzi Kubernetes) nadal jest produktem sprzedawanym.
Dodano
- WarpStream: Nowy podmiot oferujący w pełni zarządzane usługi w chmurze wykorzystujące protokół Kafka.
- Confluent: Dodano do kategorii przetwarzania strumieniowego wraz z Kafka Streams, ksqlDB i Apache Flink (poprzez przejęcie Immerok).
- Ververica: Od wielu lat dostarcza platformę Flink. Szczerze mówiąc, nie jestem pewien, dlaczego przegapiłem ich w zeszłym roku.
- Amazon Managed Service for Apache Flink (MSF). Wcześniej znana jako Amazon Kinesis Data Analytics (KDA). Dodano do częściowo zarządzanego przetwarzania strumieniowego.
- Google DataFlow: Dodano do w pełni zarządzanego przetwarzania strumieniowego.
Usunięto
To kontrowersyjna sekcja. Dlatego jeszcze raz podkreślam, że jest to tylko to, co widzę w terenie, a nie jako badanie statystyczne lub ankieta.
- Google Pub/Sub: Proszę skupić się na strumieniowym przesyłaniu danych, a nie na brokerach wiadomości.
- TIBCO: Nie używany do strumieniowego przesyłania danych (poza TIBCO StreamBase na rynku usług finansowych do handlu o niskim opóźnieniu).
- DataStax: Nie widzę zbyt wiele open-source Apache Pulsar. Nie zauważyłem też, by Pulsar firmy DataStax oferujący Luna Streaming w ogóle zyskał popularność na rynku. Wygląda również na to, że sprzedawca dokonał kolejnej strategicznej zmiany i koncentruje się teraz znacznie bardziej na wektorowych bazach danych i generatywnej sztucznej inteligencji (GenAI).
- Lenses + Conduktor: Powodem, dla którego je usunąłem, nie jest to, że nie są używane. Są to świetne narzędzia. Ale ten krajobraz koncentruje się na platformach do strumieniowego przesyłania danych, a nie na komplementarnych narzędziach do zarządzania, monitorowania lub proxy. W międzyczasie wokół Kafki istnieje tak wiele narzędzi – zasługuje to na własny artykuł krajobrazowy lub porównawczy.
- Pravega: Nie widziałem tej technologii w terenie ani razu w 2023 roku.
- Immerok: Przejęty przez Confluent.
- Hazelcast: Nie widziałem go w prawdziwym świecie w scenariuszach strumieniowego przesyłania danych. Technologia ta jest dobrze znana jako siatka danych w pamięci, ale nie do przetwarzania strumieniowego.
Ponieważ wspomniałem powyżej o Forrester Wave, mogą Państwo zdawać sobie sprawę, że nie uwzględniłem każdego “silnego wykonawcy” z raportu. Na przykład TIBCO, SAS lub Hazelcast. Ponieważ w moich rozmowach na temat architektur sterowanych zdarzeniami i przetwarzania strumieniowego nie widzę żadnej trakcji wśród tych dostawców. Nie jest to dowód statystyczny ani próba uczynienia innych narzędzi złymi.
Kryteria oceny platform strumieniowego przesyłania danych
Często zalecam korzystanie z następujących czterech aspektów, aby przyjrzeć się różnym ramom, platformom i usługom w chmurze w celu oceny technologii dla Państwa projektu biznesowego lub strategii architektury korporacyjnej:
- Cloud-native: Czy rozwiązanie można elastycznie skalować w górę i w dół? Czy jest w pełni zarządzane / bezserwerowe, czy tylko kilka instancji serwerów hostowanych w chmurze? Czy mogą Państwo zautomatyzować proces rozwoju, operacji i testowania przy użyciu DevOps, GitOps, rozwoju opartego na testach i podobnych zasad?
- Proszę wypełnić: Czy rozwiązanie oferuje wszystkie wymagane funkcje? Strumieniowe przesyłanie danych wymaga czegoś więcej niż tylko przesyłania wiadomości lub pozyskiwania danych. W związku z tym, czy rozwiązanie zapewnia konektory, przetwarzanie danych, zarządzanie, bezpieczeństwo, samoobsługę, otwarte interfejsy API itp.
- Wszędzie: Gdzie mogą Państwo korzystać z rozwiązania? Tylko w chmurze? Czy obsługiwani są wszyscy wymagani dostawcy usług w chmurze? Czy istnieje opcja wdrożenia w centrum danych lub nawet na obrzeżach (tj. poza centrum danych), takich jak fabryka, wieża komórkowa lub sklep detaliczny? W jaki sposób można udostępniać dane między regionami, chmurami lub centrami danych? Jakie przypadki użycia obsługuje (np. agregacja, odzyskiwanie danych po awarii, integracja hybrydowa, migracja itp.)
- Obsługiwane: Czy rozwiązanie jest dojrzałe i sprawdzone w praktyce? Czy dostępne są publiczne studia przypadków dla Państwa przypadku użycia lub branży? Czy dostawca w pełni wspiera produkt? Jakie są umowy SLA? Czy określone funkcje są wyłączone z komercyjnego wsparcia dla przedsiębiorstw? Niektórzy dostawcy oferują usługi strumieniowania danych w chmurze (takie jak zarządzana usługa Kafka) i wykluczają wsparcie w warunkach (których niestety wiele osób nie czyta w publicznych usługach w chmurze).
Przyjrzyjmy się bliżej różnym kategoriom strumieniowania danych i zacznijmy od wiodącej technologii: Native Apache Kafka…
Natywna Apache Kafka dla strumieniowego przesyłania danych
Zaczynając od wiodącej technologii strumieniowego przesyłania danych, Apache Kafka, oraz powiązanych dostawców i ofert SaaS.
Rozwój społeczności Apache Kafka w ciągu ostatnich kilku lat jest imponujący. Oto kilka statystyk, które Jay Kreps przedstawił w zeszłym roku na konferencji poświęconej strumieniowaniu danych “Current – The Next Generation of Kafka Summit” w Austin w Teksasie:
- 100 000 organizacji korzystających z Apache Kafka
- >41 000 uczestników spotkań Kafka
- >32 000 pytań Stack Overflow
- >12 000 Jiras dla Apache Kafka
- >31 000 otwartych ofert pracy z prośbą o umiejętności Kafka
Proszę spojrzeć na zwiększoną liczbę aktywnych miesięcznych unikalnych użytkowników pobierających bibliotekę kliencką Kafka Java z Maven:
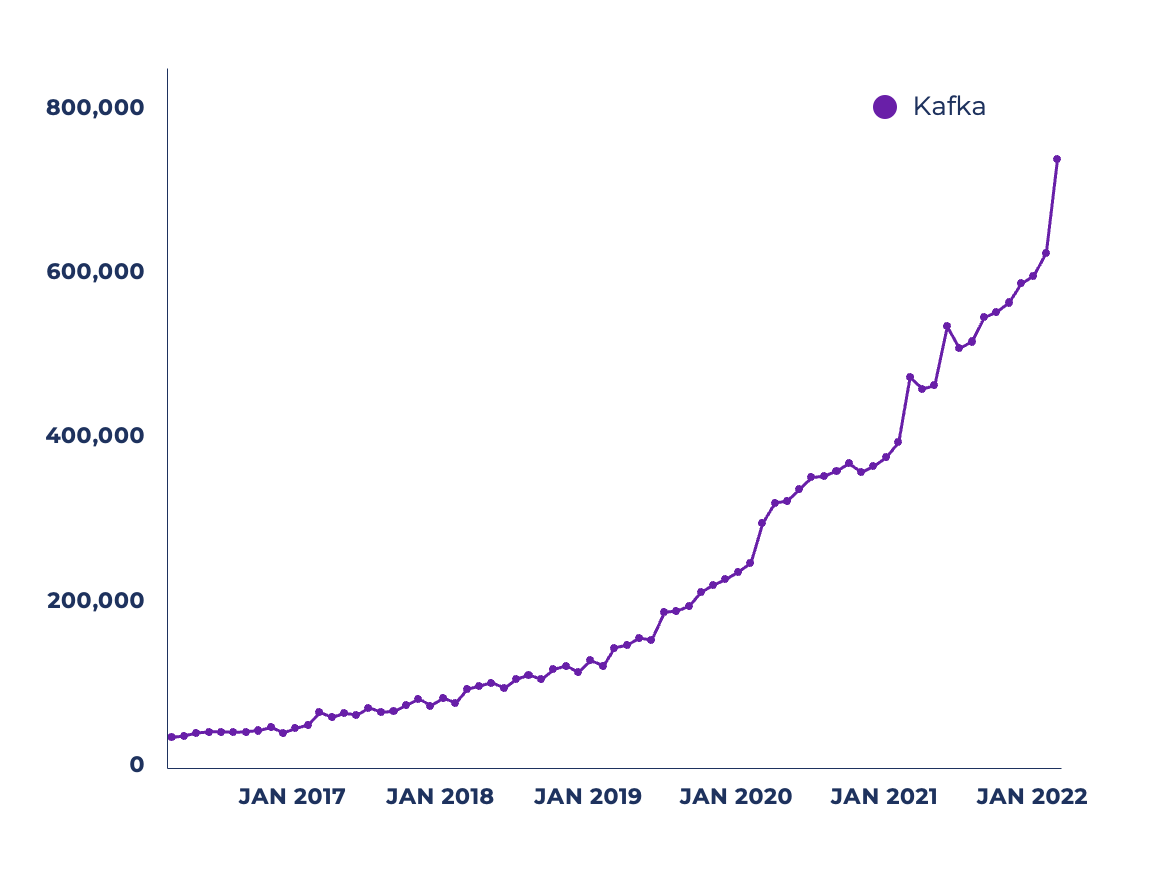 Źródło: Sonatype
Źródło: Sonatype
Dostawcy Apache Kafka: Samodzielne zarządzanie a oferty w chmurze
Nowe firmy programistyczne koncentrują się na strumieniowym przesyłaniu danych. W ciągu ostatnich kilku lat nawet firmy o długiej tradycji, takie jak IBM i Oracle, podążyły za tym trendem. Na najwyższym poziomie – upraszczając – istnieją trzy rodzaje ofert dla Apache Kafka:

Zrobiłem szczegółowy porównanie lokalnych dostawców Kafka i usług w chmurze używając tej analogii do samochodu. Tylko Amazon MSK Serverless (tj. w pełni zarządzana usługa, a nie częściowo zarządzana MSK) nie była dostępna podczas pisania tego porównania. Dlatego proszę również przeczytać Confluent Cloud kontra Amazon MSK Serverless.
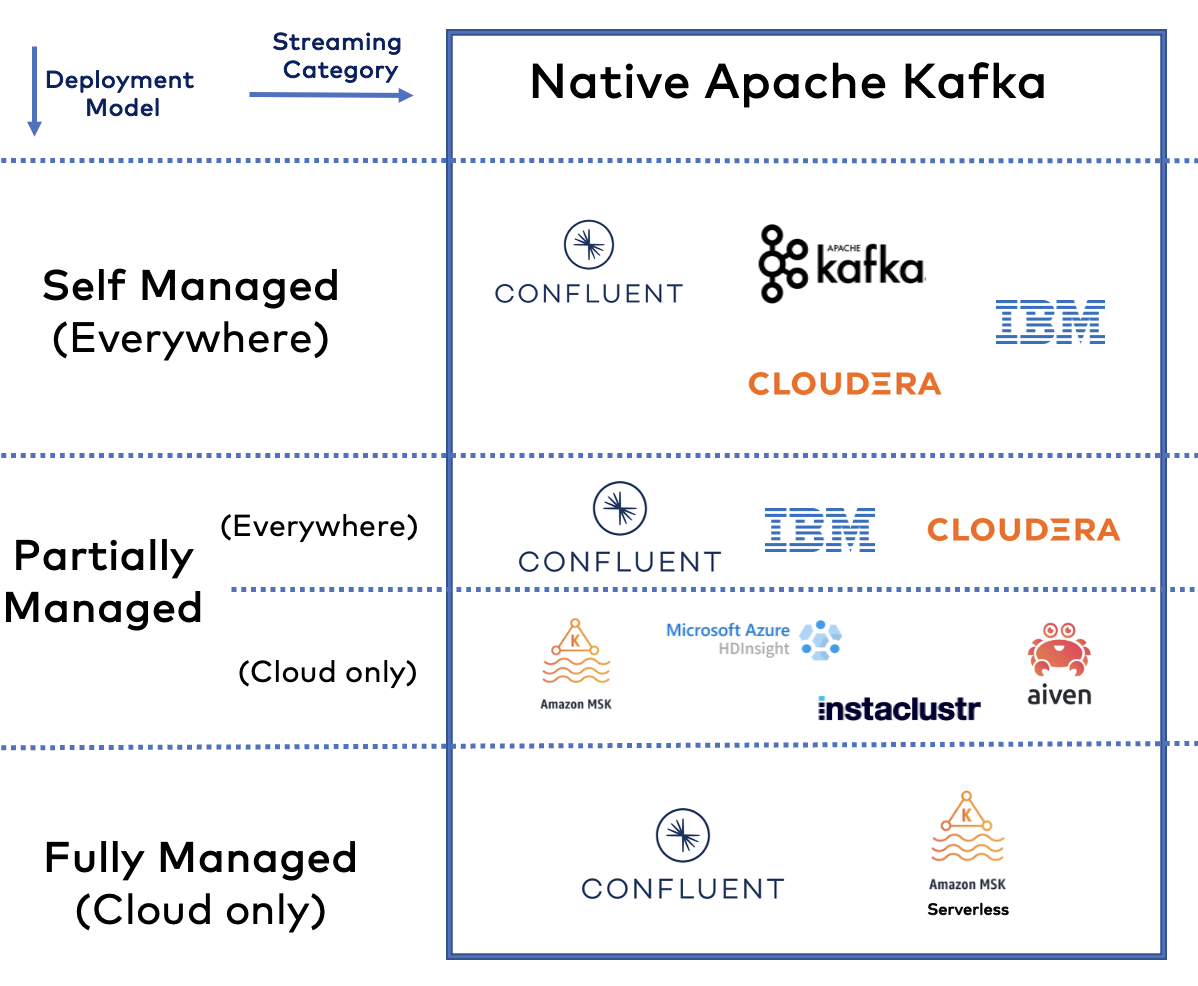
Oto kilka uwag na temat każdej technologii jako podsumowanie.
- Apache Kafka: Faktyczny standard strumieniowego przesyłania danych. Otwarte oprogramowanie z ogromną społecznością. Wszyscy dostawcy na tej liście polegają na (części) tego projektu.
- Confluent: Zapewnia strumieniowe przesyłanie danych w dowolnym miejscu dzięki Confluent Platform (samodzielnie zarządzanej) i Confluent Cloud (w pełni zarządzanej i dostępnej u wszystkich głównych dostawców usług w chmurze).
- Cloudera: Dostarcza Kafkę jako samodzielnie zarządzaną ofertę. Koncentruje się na łączeniu wielu technologii danych, takich jak Kafka, Hadoop, Spark, Flink, NiFi i wiele innych.
- IBM: Dostarcza Kafkę jako częściowo zarządzaną ofertę w chmurze i samodzielnie zarządzaną Kafkę na Kubernetes za pośrednictwem OpenShift (przez Red Hat). Kafka jest częścią portfolio integracyjnego, które obejmuje inne frameworki open-source, takie jak Apache Camel.
- AWS: Zapewnia dwa oddzielne produkty Amazon MSK (częściowo zarządzany) i Amazon MSK Serverless (w pełni zarządzany). Oba produkty mają bardzo różne funkcjonalności i ograniczenia. Obie oferty MSK wykluczają obsługę Kafki (proszę przeczytać warunki). AWS oferuje setki usług w chmurze, a Kafka jest częścią tego szerokiego spektrum. Dostępne tylko w publicznych regionach chmury AWS; nie w Outposts, Local Zones, Wavelength itp.
- Instaclustr i Aiven: Częściowo zarządzane oferty chmury Kafka od dostawców usług w chmurze. Portfele produktów oferują różne hostowane usługi technologii open-source. Instaclustr oferuje również (częściowo) zarządzaną ofertę dla infrastruktury lokalnej.
- Microsoft Azure HDInsight: Część infrastruktury Hadoop platformy Azure. Nie jest przeznaczony do innych zastosowań. Dostępne tylko w publicznych regionach chmury Azure.
To nie jest porównanie. To tylko lista z kilkoma uwagami. Proszę dokonać własnej oceny swoich ulubionych dostawców. Proszę sprawdzić, czego Państwo potrzebują: Natywne dla chmury? Kompletny? Wszędzie? Obsługiwane?
Proszę pamiętać, że wielu dostawców wyklucza lub nie koncentruje się na Kafka Streams i Kafka Connect i oferuje tylko niekompletną Kafkę; zamiast tego chcą sprzedawać własne produkty do integracji i przetwarzania. Proszę nie porównywać jabłek i pomarańczy!
Open Source Frameworks i SaaS wykorzystujące protokół Kafka
Kilku dostawców z różnych powodów nie polega na otwartym oprogramowaniu Apache Kafka, ale zbudowało własne implementacje na bazie protokołu Kafka.
Marketing tego Państwu nie powie, ale kompatybilność protokołu Kafka jest ograniczona. Może to stwarzać ryzyko w obsłudze istniejących obciążeń Kafka względem klastra i różnić się w operacjach i wykonaniu (co może być dobre lub złe).
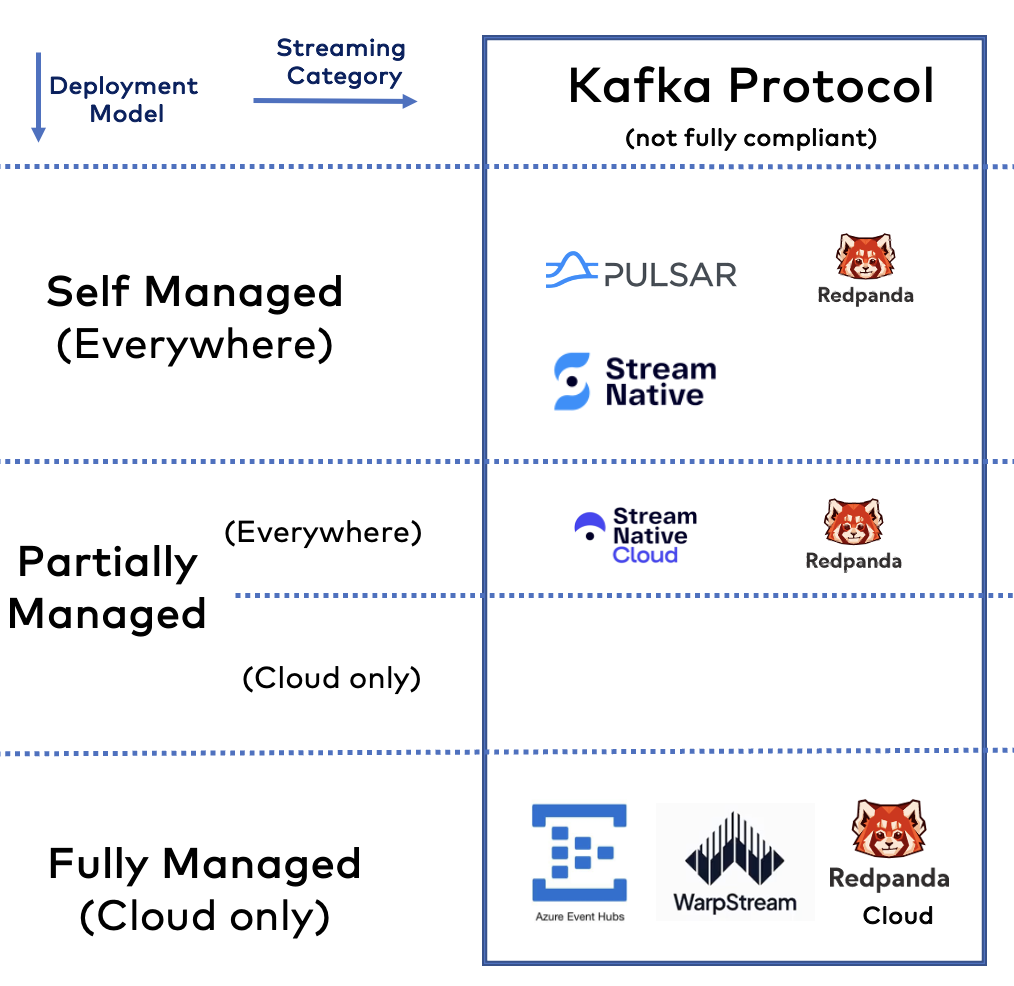
Oto kilka uwag na temat każdej technologii jako podsumowanie:
- Apache Pulsar: Konkurent dla Apache Kafka. Podobna historia i przypadki użycia, ale inna architektura. Kafka to pojedynczy rozproszony klaster – po usunięciu zależności ZooKeepera w 2022 roku. Pulsar to trzy (!) rozproszone klastry: Brokery Pulsar, ZooKeeper i BookKeeper. Teraz jest już za późno na zdobycie większej popularności na rynku. A Kafka dogania niektóre brakujące funkcje, takie jak kolejki dla Kafki.
- StreamNative: Główny dostawca stojący za Apache Pulsar. Oferuje samodzielnie zarządzane i w pełni zarządzane rozwiązania. StreamNative Cloud for Kafka jest wciąż na bardzo wczesnym etapie dojrzałości, nie wiadomo, czy kiedykolwiek się wzmocni. Nic dziwnego, że teraz mogą Państwo również wybrać BYOC.
- Redpanda: Stosunkowo nowy gracz na rynku streamingu danych, oferujący samodzielnie zarządzane i w pełni zarządzane produkty. Ciekawe podejście do implementacji protokołu Kafka w C++. Redpanda może przejąć część rynku, jeśli uda jej się znaleźć odpowiednie przypadki użycia i wyróżniki. Obecnie nie widzę Redpandy jako alternatywy dla natywnej oferty Kafki ze względu na jej wczesny etap w krzywej dojrzałości i brak wartości dodanej w rozwiązywaniu problemów biznesowych w porównaniu z dodatkowym ryzykiem w porównaniu do Apache Kafka.
- Azure Event Hubs: Dojrzała, w pełni zarządzana usługa w chmurze. Usługa robi jedną rzecz i to bardzo dobrze: Pobieranie danych za pośrednictwem protokołu Kafka. W związku z tym nie jest to kompletna platforma streamingowa, ale jest bardziej porównywalna do Amazon Kinesis lub Google Cloud PubSub. Dostępna tylko w publicznych regionach chmury Azure. Ograniczona kompatybilność z protokołem Kafka i wysoki koszt usługi to dwa czynniki blokujące, które regularnie słyszę.
- WarpStream: Nowy gracz na rynku streamingu danych. Usługa w chmurze to platforma strumieniowania danych kompatybilna z Kafka, zbudowana bezpośrednio na S3. Gorsze opóźnienie jest prawdopodobnie w porządku dla niektórych przypadków użycia Kafki. Ale dopiero przyszłość pokaże, czy ta różnicująca architektura odegra kluczową rolę po tym, jak inne usługi chmurowe Kafka przyjmą KIP-405 dla Tiered Storage (który jest dostępny we wczesnym dostępie od wersji Kafka 3.6).
Proszę uważać na oświadczenia dostawców, którzy ponownie implementują protokół Kafka. Większość z nich przesadnie reklamuje kompatybilność z protokołem Kafka. Ponadto “benchmarketing” (tj. wybieranie słodkiego miejsca lub niszowego scenariusza, w którym działają Państwo lepiej niż konkurencja) jest ulubioną techniką marketingową mającą na celu “udowodnienie” różnic w stosunku do prawdziwego Apache Kafka.
Technologie przetwarzania strumieniowego
Podczas gdy Apache Kafka jest de facto standardem przechowywania wiadomości i zdarzeń, istnieje wiele uzupełniających i konkurencyjnych technologii przetwarzania strumieniowego:
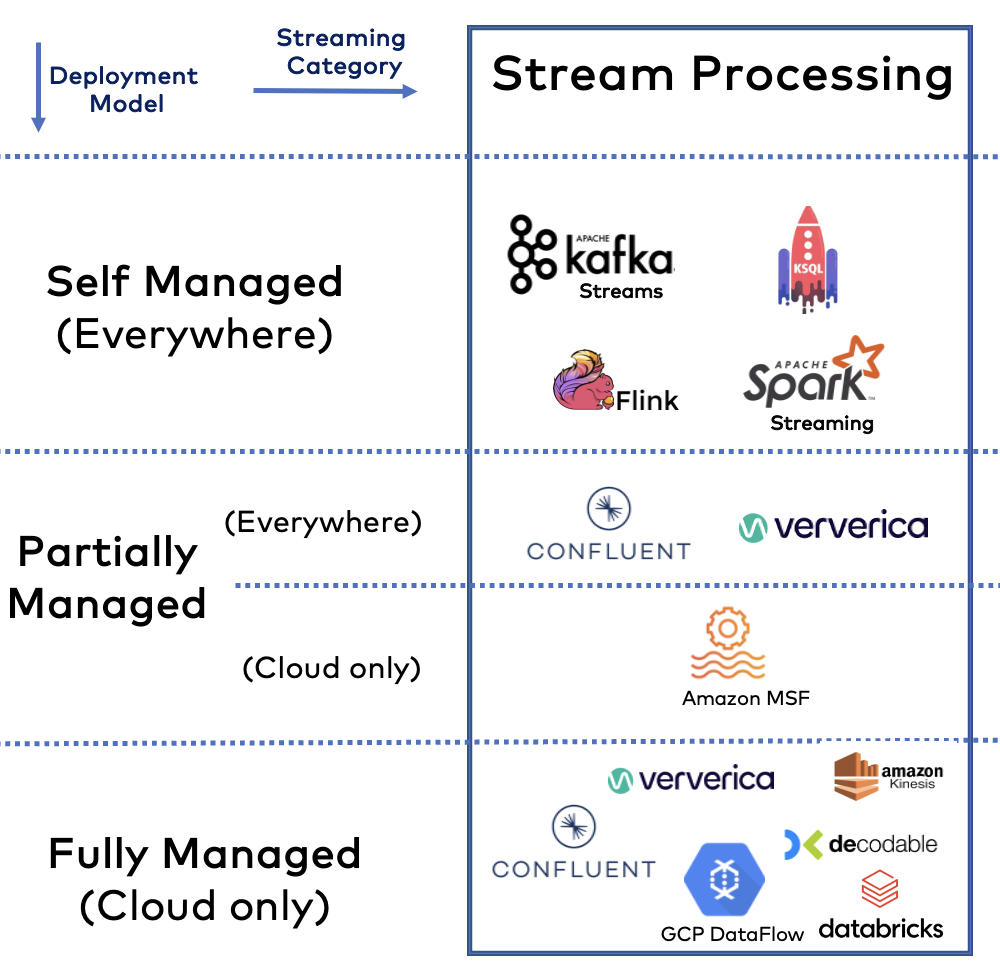
Obecnie pojawia się jeszcze więcej technologii ze względu na rozwój tej kategorii oprogramowania na całym świecie i we wszystkich branżach. To doskonała wiadomość. Strumieniowe przesyłanie danych pozostanie i będzie się rozwijać.
Sytuacja jest trudna do zbadania w ramach krajobrazu strumieniowego przesyłania danych, ponieważ niektóre produkty są komplementarne i konkurencyjne dla ekosystemu Apache Kafka.
Przyjęcie i rozwój Apache Flink
Ciekawostka: Wiodąca konferencja Kafka została przemianowana z “Kafka Summit” na “Current – The Next Generation of Kafka Summit” w 2022 roku. Dlaczego? Ponieważ strumieniowanie danych to coś więcej niż Kafka. Obecnych było wiele komplementarnych i konkurencyjnych technologii, w tym dostawcy, stoiska, pokazy i studia przypadków klientów. To niezwykła ewolucja strumieniowego przesyłania danych dla społeczności i przedsiębiorstw na całym świecie!
Apache Flink staje się de facto standardem przetwarzania strumieniowego. Rozwój Flink wygląda bardzo podobnie do przyjęcia Kafki kilka lat temu:
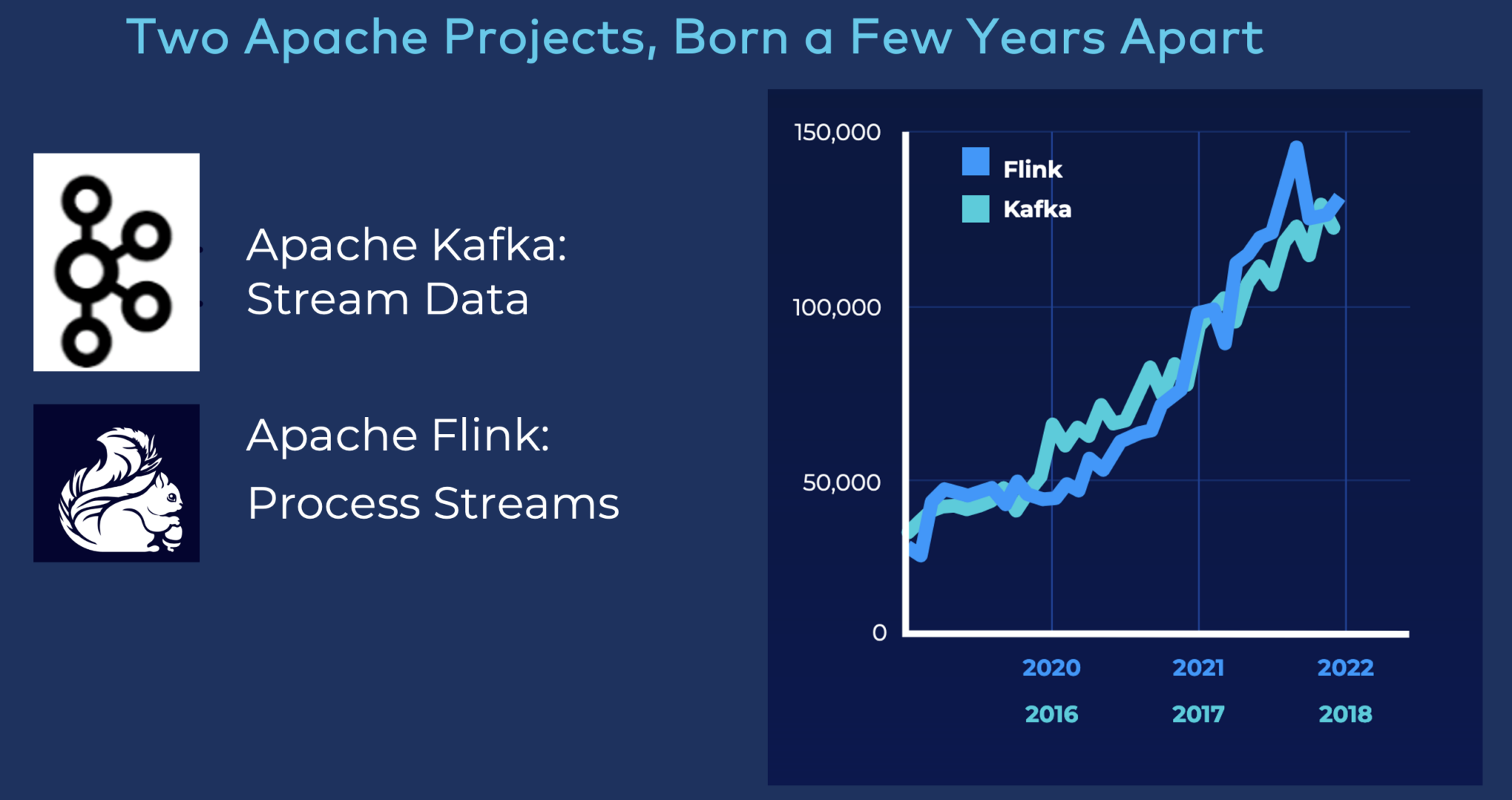
Proszę jednak nie lekceważyć mocy i przypadków użycia natywnego przetwarzania strumieniowego Kafka z Kafka Streams. Wskaźnik adopcji jest ogromny, ponieważ Kafka Streams jest łatwa w użyciu. I jest częścią Apache Kafka.
Niektóre produkty do przetwarzania strumieniowego stanowią uzupełnienie Kafki
Każda platforma przetwarzania strumieniowego lub usługa w chmurze ma swoje wady. Podczas gdy Flink cieszy się dużą popularnością, istnieją również inne. Nie ma jednego rozmiaru, który pasowałby do wszystkich przypadków użycia. Oto kilka dojrzałych i nowych technologii, które uzupełniają Apache Kafka.
Open Source Stream Processing Frameworks
- Kafka Streams: Część otwartego oprogramowania Apache Kafka. W związku z tym, jeśli pobierają Państwo Kafkę ze strony Apache, zawsze zawiera ona tę bibliotekę. Należy zawsze zadać sobie pytanie, czy do przetwarzania strumieniowego potrzebny jest inny framework niż Kafka Streams. Istotna korzyść: jedna technologia, jeden dostawca, jedna infrastruktura.
- ksqlDB (zwykle nazywany KSQL, nawet po rebrandingu): Warstwa abstrakcji na szczycie Kafka Streams w celu zapewnienia przetwarzania strumieniowego ze strumieniowym SQL. Stąd też natywna dla Kafki. Jest dostarczany z licencją Confluent Community i jest darmowy. Sweet spot: Streaming ETL.
- Apache Flink: Wiodący framework przetwarzania strumieniowego typu open-source. Zaawansowane funkcje obejmują potężny skalowalny silnik obliczeniowy (oddzielony od Kafki), swobodę wyboru dla programistów między ANSI SQL, Javą i Pythonem, interfejsy API do kompleksowego przetwarzania zdarzeń (CEP) oraz ujednolicone interfejsy API dla obciążeń strumieniowych i wsadowych.
- Spark Streaming: Streamingowa część open-source’owego frameworka do przetwarzania dużych zbiorów danych Apache Spark. Nadal nie jestem w 100% przekonany. Kafka Streams i Apache Flink są lepszym wyborem do przetwarzania strumieniowego. Jednak ogromna baza zainstalowanych klastrów Spark w przedsiębiorstwach poszerza ich zastosowanie.
Dostawcy usług przetwarzania strumieniowego i usług w chmurze
- Ververica: Dobrze znana firma Flink. Przejęta przez chińskiego giganta Alibaba w 2019 roku. Niewielka trakcja w Europie i Stanach Zjednoczonych, ale zdecydowanie ekspert w dziedzinie Flink w Azji. Osobiście nigdy nie widziałem tego dostawcy używanego poza Azją.
- Decodable: Nowa usługa w chmurze. Na bardzo wczesnym etapie. Mimo to dodałem ją, ponieważ uważam, że jest to doskonały ruch strategiczny, aby zbudować usługę strumieniowania danych w chmurze na bazie Apache Flink. Ogromny potencjał, jeśli zostanie połączona z istniejącą infrastrukturą Kafka w przedsiębiorstwach. Zapewnia również gotowe konektory dla systemów innych niż Kafka.
- Amazon Managed Service for Apache Flink (MSF): (Prawie) w pełni zarządzana usługa AWS, która umożliwia klientom przekształcanie i analizowanie danych strumieniowych w czasie rzeczywistym za pomocą Apache Flink. Nadal zapewnia pewne (kosztowne) luki w automatycznym skalowaniu i nie jest prawdziwie bezserwerowa. Obsługuje wszystkie interfejsy Flink, tj. SQL, Java i Python. A także konektory inne niż Kafka. Dostępne tylko na AWS.
- Confluent Cloud: Prawdziwie bezserwerowa oferta Flink, która jest elastyczna i skaluje się do zera, jeśli nie jest używana. Na początku obsługuje tylko SQL. Obsługa Java i Python pojawi się w 2024 roku. Zaczyna się na AWS, ale oczekuje się, że będzie dostępny na GCP i Azure na początku 2024 roku. Głęboka integracja z w pełni zarządzanymi usługami Kafka, Schema Registry, Connectors, Data Governance i innymi funkcjami Confluent. Zapewnia płynne, kompleksowe środowisko programistyczne dla potoków strumieniowego przesyłania danych.
- Databricks: Był wiodącym dostawcą stojącym za Apache Spark. Dziś nikt już nie mówi o Sparku (nawet jeśli jest to kluczowy element technologiczny platformy chmurowej Databricks). Próbuje znacznie bardziej zaangażować się w biznes danych w czasie rzeczywistym. Podoba mi się platforma do analityki, raportowania i sztucznej inteligencji/uczenia maszynowego. Nie przekonuje mnie jednak historia o “robieniu wszystkiego w ramach jednego dużego jeziora danych”.
Większość z tych usług dobrze współpracuje z rozwiązaniami innych dostawców. Na przykład Databricks łatwo integruje się z dowolnym środowiskiem Kafka, a Amazon MSF łączy się bezpośrednio z Kafką Confluent.
Apache Flink (lub Spark Streaming) BEZ Kafki?
Większość technologii przetwarzania strumieniowego uzupełnia Apache Kafka. Jednak frameworki przetwarzania strumieniowego, takie jak Flink lub usługi w chmurze, takie jak Databricks, NIE potrzebują Kafki jako warstwy pobierania. Istnieją inne opcje…
Flink, Spark i inne mogą pobierać dane z innych platform strumieniowych lub bezpośrednio z magazynów danych, takich jak pliki lub bazy danych. Proszę uważać na tę drugą opcję: Jeśli używają Państwo Flink lub Spark Streaming do przetwarzania strumieniowego, to w porządku. Ale jeśli pierwszą rzeczą do zrobienia jest odczytanie danych z magazynu obiektów S3, cóż, są to dane w spoczynku.
ALE: Powszechnym trendem na rynku strumieniowania danych jest długoterminowe przechowywanie (niektórych) zdarzeń w ramach platformy strumieniowania zdarzeń. Zwłaszcza wprowadzenie Tiered Storage dla Kafki zmieniło możliwości i przypadki użycia. Obsługa przechowywania obiektów przez niektórych dostawców za pośrednictwem interfejsu S3 może całkowicie zmienić zasady gry w zakresie przechowywania i przetwarzania zdarzeń w czasie rzeczywistym za pomocą protokołu Kafka lub z innymi silnikami analitycznymi i bazami danych w czasie zbliżonym do rzeczywistego lub wsadowym. Apache Iceberg może być kolejnym trendem, o którym będziemy mówić w kontekście streamingu w 2025 roku.

Proszę zrozumieć, że aplikacje przetwarzające strumieniowo mogą również utrzymywać stan: The backend Państwa aplikacji Kafka Streams lub Flink może przechowywać stan dla Państwa zadań, takich jak wzbogacanie danych. Aplikacja do przetwarzania strumieniowego to nie tylko strumienie danych w czasie rzeczywistym. Koreluje ona również te dane w czasie rzeczywistym z (już pozyskanymi) danymi historycznymi. Jest to powszechne podejście w przypadku metadanych lub danych biznesowych, które są aktualizowane rzadziej (np. z systemu SAP ERP).
Niektóre produkty przetwarzania strumieniowego są konkurencyjne dla Kafki
W niektórych sytuacjach muszą Państwo ocenić, czy Apache Kafka lub inna technologia jest właściwym wyborem. Poniżej przedstawiamy kilku konkurentów open-source i chmurowych:
- Amazon Kinesis: Pozyskiwanie danych do magazynów danych AWS. Dojrzały produkt dla konkretnego problemu. Dostępny tylko w AWS.
- Google Cloud DataFlow: W pełni zarządzana usługa do wykonywania potoków Apache Beam w ekosystemie Google Cloud Platform. Dojrzały produkt dla konkretnego problemu. Dostępny tylko na GCP.
- Wiele konkurencyjnych startupów pojawia się wokół przetwarzania strumieniowego poza światem Kafki i Flink. Zobaczmy, czy niektóre z nich zyskają popularność w 2024 roku.
Amazon Kinesis i Google Cloud DataFlow to doskonałe usługi w chmurze, jeśli chcą Państwo “tylko” pozyskiwać dane do określonej pamięci masowej w chmurze. Jeśli nie ma innych przypadków użycia, narzędzia te mogą być właściwym wyborem (jeśli ceny w skali i inne ograniczenia działają dla Państwa).
Apache Kafka to znacznie bardziej elastyczna i strategiczna platforma do strumieniowego przesyłania danych. Wiele projektów nadal rozpoczyna się od pozyskania danych i zbudowania pierwszego potoku. Jednak zapewnienie dostępu do tego samego strumienia zdarzeń do dowolnego innego zlewu danych lub do wydajnego przetwarzania strumieniowego za pomocą narzędzi takich jak Kafka Streams lub Apache Flink jest znaczącą zaletą.
Potencjał dla krajobrazu strumieniowego przesyłania danych w 2025 r.
Strumieniowe przesyłanie danych to podróż. Podobnie jak rozwój platform do strumieniowego przesyłania zdarzeń i usług w chmurze. Kilku uznanych dostawców oprogramowania i usług w chmurze może zyskać większą popularność dzięki swojej ofercie strumieniowego przesyłania danych. A niektóre startupy mogą znacznie się rozwinąć. Poniżej przedstawiono kilka technologii, które mogą ewoluować i odnotować rosnącą popularność w 2024 roku:
- Dodatkowe usługi w chmurze Kafka, takie jak Digital Ocean lub Oracle Cloud Infrastructure (OCI) Streaming, mogą zyskać większą popularność. Nie widziałem ich jeszcze w praktyce. Ale np. połączenie Oracle GoldenGate z OCI Streaming może być interesujące dla niektórych organizacji w niektórych przypadkach użycia.
- Hazelcast znacząco zmienia markę i jest częścią Forrester Streaming Data Wave. Dzięki ofercie zarówno lokalnej, jak i bezserwerowej chmury, technologia ta może zyskać na popularności w zakresie strumieniowego przesyłania danych i powrócić do mojego krajobrazu w przyszłym roku.
- Streamingowe bazy danych, takie jak Materialize czy RisingWave, mogą stać się własną kategorią. Moje odczucia: Bardzo wczesny etap cyklu hype. Zobaczymy w 2024 roku, czy i gdzie ta technologia zostanie szerzej przyjęta i jakie są przypadki użycia. Trudno jest odpowiedzieć na pytanie, w jaki sposób będą one konkurować z powstającymi bazami danych do analizy w czasie rzeczywistym, takimi jak Apache Druid, Apache Pinot, ClickHouse, Rockset, Timeplus itp. Wiem, że istnieją różnice, ale szersza społeczność i firmy muszą a) zrozumieć te różnice i b) znaleźć dla nich problemy biznesowe.
- Pojawiły się startupy SaaS, takie jak Quix i Bytewax (oba przetwarzają strumienie w Pythonie), DeltaStream (zasilany przez Apache Flink) i wiele innych. Zobaczmy, który z nich zdobędzie popularność na rynku dzięki innowacyjnemu produktowi i modelowi biznesowemu.
- Istniejące przedsiębiorstwa wieloproduktowe rozszerzają swoją ofertę wokół Kafki o oddzielne usługi Flink. Na przykład Aiven ma już w międzyczasie produkt Flink, który może zyskać popularność, podobnie jak jego oferta Kafka.
- Tradycyjni dostawcy usług zarządzania danymi, tacy jak MongoDB czy Snowflake, próbują wejść głębiej w biznes strumieniowania danych. Wciąż jestem fanem rozdzielania obaw, więc myślę, że powinni oni zachować swoje słodkie miejsce i (tylko) zapewniać strumieniowe pozyskiwanie i CDC jako przypadki użycia, ale nie (próbować) konkurować z dostawcami strumieniowego przesyłania danych.
Ciekawostka: Model biznesowy prawie wszystkich powstających startupów to w pełni zarządzane usługi w chmurze, a nie sprzedaż licencji na wdrożenia lokalne. Wiele z nich opiera się na oprogramowaniu typu open-source lub open-core, a inne zapewniają jedynie zastrzeżoną implementację.
Podróż w strumieniowym przesyłaniu danych jest długa…
Streaming danych to nie wyścig, to podróż! Architektury i technologie sterowane zdarzeniami, takie jak Apache Kafka czy Apache Flink, wymagają zmiany sposobu myślenia przy tworzeniu, rozwijaniu, wdrażaniu i monitorowaniu aplikacji. Starsza integracja, natywne dla chmury mikrousługi i udostępnianie danych w konfiguracjach hybrydowych i wielochmurowych są normą, a nie wyjątkiem.
Krajobraz strumieniowego przesyłania danych w 2024 roku pokazuje, jak wyłania się nowa kategoria oprogramowania. Wciąż jesteśmy na wczesnym etapie. Stworzenie nowej kategorii oprogramowania wymaga czasu. W większości rozmów z klientami, partnerami i społecznością słyszę stwierdzenia takie jak: “Widzimy wartość, ale jeszcze jej nie osiągnęliśmy – teraz zaczynamy od budowania pierwszych potoków strumieniowania danych i mamy mapę drogową na kolejne lata, aby dodać bardziej zaawansowane przetwarzanie strumieniowe”.