
JuiceFS osiągnął 40-krotny wzrost wydajności w zakresie tworzenia kopii zapasowych i odzyskiwania metadanych dzięki optymalizacjom od wersji 0.15.2 do wersji 1.0 RC2. Kluczowe optymalizacje koncentrowały się na zmniejszeniu ziarnistości przetwarzania danych, minimalizacji operacji we/wy i analizie wąskich gardeł czasowych. Ogólne ulepszenia zaowocowały skróceniem czasu działania procesu zrzutu o 2300% i zmniejszeniem wykorzystania pamięci o 4200%, podczas gdy proces ładowania osiągnął skrócenie czasu działania o 230% i zmniejszenie wykorzystania pamięci o 330%.
Jako natywny dla chmury rozproszony system plików o otwartym kodzie źródłowym, JuiceFS wspiera różne silniki przechowywania metadanych, każdy z unikalnym formatem zarządzania danymi. Aby ułatwić zarządzanie, JuiceFS wprowadził dump w wersji 0.15.2, umożliwiając jednolite formatowanie wszystkich metadanych do postaci JSON do tworzenia kopii zapasowych. Dodatkowo, plik load umożliwia przywrócenie lub migrację kopii zapasowych do dowolnego mechanizmu przechowywania metadanych. Aby uzyskać szczegółowe informacje na temat tych poleceń, proszę zobaczyć Odnośnik do poleceń. Podstawowe użycie jest następujące:
$ juicefs dump redis://192.168.1.6:6379/1 meta.json
$ juicefs load redis://192.168.1.6:6379/2 meta.jsonTa funkcja przeszła trzy znaczące optymalizacje od wersji 0.15.2 do 1.0 RC2, co skutkuje 40-krotny wzrost wydajności. Optymalizacje koncentrowały się głównie na trzech aspektach:
- Zmniejszenie ziarnistości przetwarzania danych: Dzielenie dużych obiektów na mniejsze znacznie zmniejszyło zużycie pamięci i pozwoliło na precyzyjne przetwarzanie współbieżne.
- Minimalizacja operacji wejścia/wyjścia: Zastosowanie podejścia potokowego dla żądań wsadowych skróciło czas operacji we/wy w sieci.
- Analiza wąskich gardeł czasowych w systemie: Przejście z przetwarzania szeregowego na równoległe zwiększyło wykorzystanie procesora.
Te strategie optymalizacji są dość typowe i mają szerokie zastosowanie w scenariuszach obejmujących liczne żądania sieciowe. W tym poście podzielimy się naszymi konkretnymi praktykami w nadziei, że zainspirujemy innych.
Format metadanych
Przed zagłębieniem się w dump i load funkcjonalności, proszę najpierw zrozumieć strukturę systemu plików. Jak pokazano na poniższym schemacie, system plików ma strukturę drzewa z katalogiem głównym najwyższego poziomu. Katalog główny zawiera podkatalogi lub pliki, a te podkatalogi z kolei mogą mieć własne podkatalogi lub pliki. Dlatego, aby uzyskać informacje o wszystkich plikach i folderach w systemie plików, musimy po prostu przejść przez to drzewo.
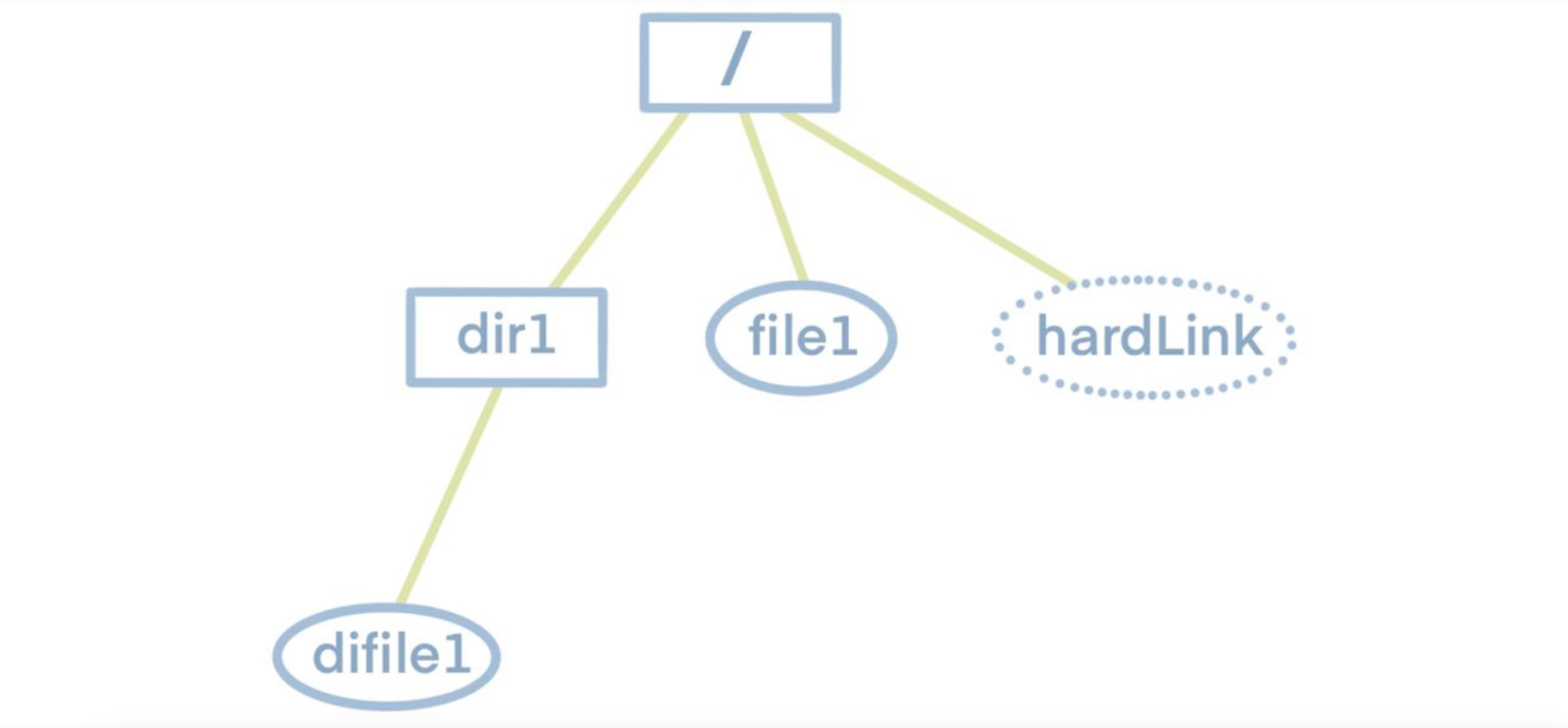
Wiedząc to, możemy zbadać charakterystykę magazynu metadanych JuiceFS. Magazyn metadanych JuiceFS składa się głównie z kilku tabel mieszających. Kluczem każdej tabeli jest inode pojedynczego pliku. Informacje o inodzie można uzyskać, przechodząc przez drzewo plików. Dlatego też, przechodząc przez drzewo plików w celu zebrania wszystkich i-węzłów i używając ich jako indeksów, możemy pobrać wszystkie metadane.
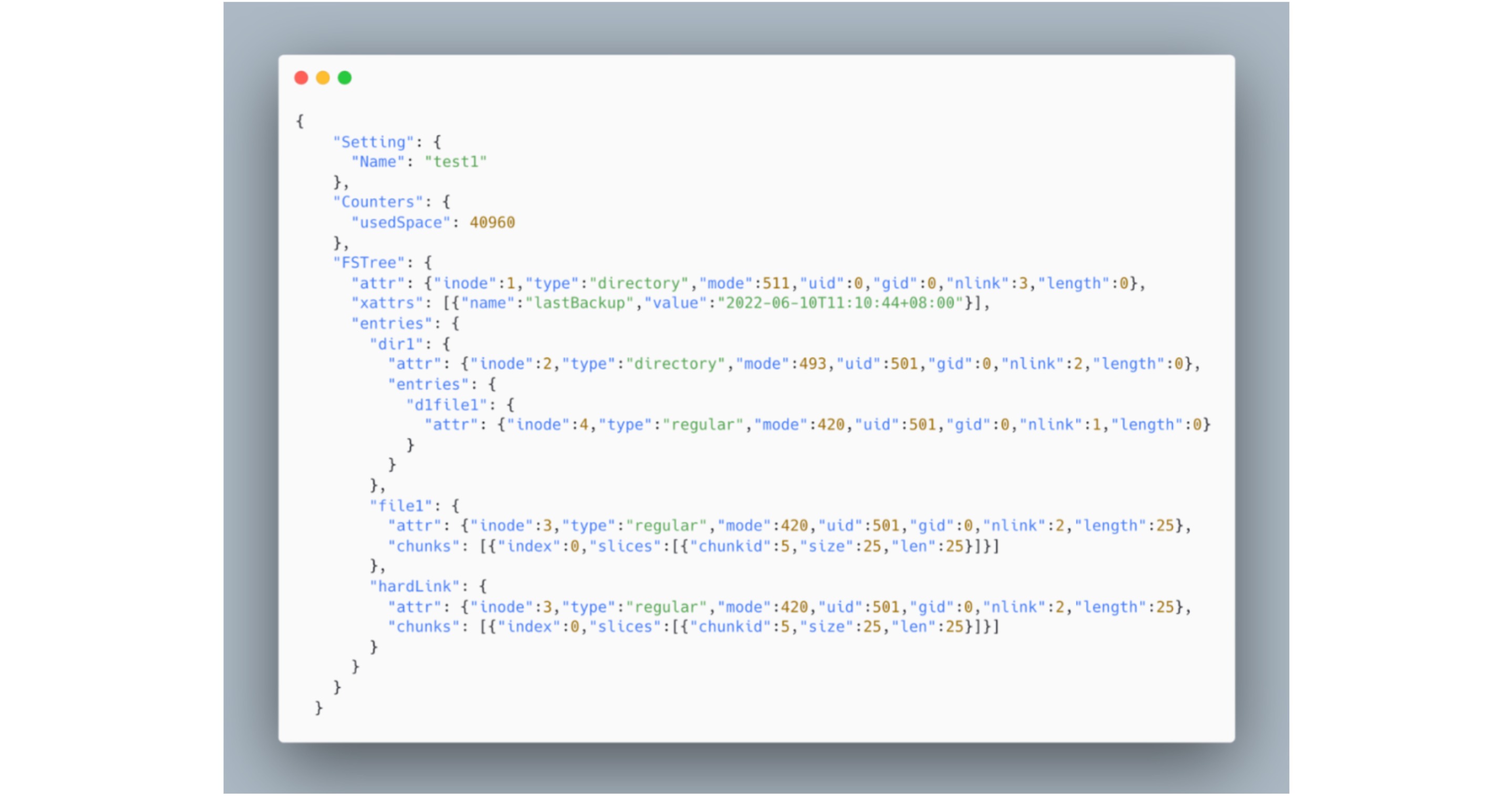
Aby zwiększyć czytelność i zachować oryginalną strukturę drzewa systemu plików, format eksportu jest ustawiony jako JSON. Poniżej znajduje się przykład pliku JSON zrzuconego z wyżej wymienionego systemu plików, gdzie hardLink oznacza twardy link do pliku.
Optymalizacja procesu zrzutu
Przed optymalizacją zrzutu
Implementacja Dump
Wdrożyliśmy dump poprzez następujące kroki:
- Analiza formatu metadanych ujawnia, że wszystkie metadane używają inode jako częściowego klucza zmiennej. Oznacza to, że znajomość konkretnej wartości i-węzła pozwala nam pobrać wszystkie informacje metadanych z Redis. Dlatego też, w oparciu o charakterystykę systemu plików, skonstruowaliśmy drzewo FSTree, wykonując skanowanie wgłębne, wypełniając to drzewo, skanując najpierw katalog główny (i-węzeł 1), a następnie skanując wszystkie wpisy poniżej niego.
- Podczas tego procesu, jeśli wpis był katalogiem, skanowaliśmy go rekurencyjnie.
- W przeciwnym razie wysyłaliśmy żądania do Redis w celu pobrania różnych wymiarów jego metadanych, składaliśmy informacje w strukturę wpisu i dołączaliśmy je do listy wpisów katalogu nadrzędnego.
Po zakończeniu rekurencyjnego przechodzenia, drzewo FSTree zostało w pełni skonstruowane.
2. Dodaliśmy względnie statyczne metadane, takie jak ustawienia jako obiekt, i serializowaliśmy całe drzewo do ciągu JSON.
3. Zapisaliśmy ciąg JSON do pliku.
Wydajność
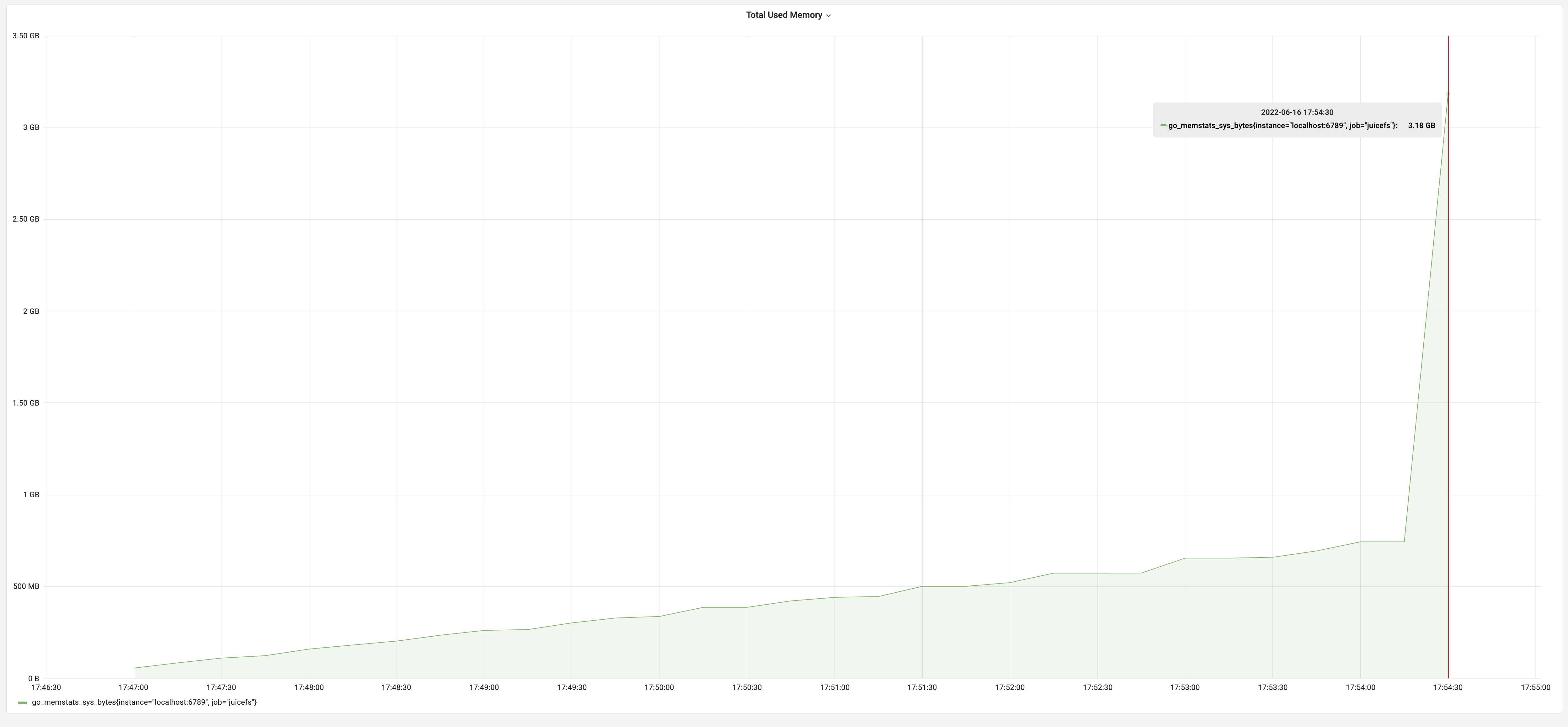
Jako przykład do testów wzięliśmy Redis zawierający metadane 1,1 miliona plików. Wyniki testów wykazały, że proces zrzucania danych trwał 7 minut i 47 sekund, a zużycie pamięci wyniosło 3,18 GB. Proszę zauważyć, że aby zapewnić porównywalność wyników testów, wszystkie testy w tym artykule wykorzystywały te same metadane.
Wyniki testu:
- Zużycie pamięci początkowo rosło powoli, gdy każdy wpis był skanowany podczas przechodzenia w głąb.
- Po skonstruowaniu całego obiektu FSTree rozpoczął się proces serializacji JSON. W tym momencie obiekt FSTree zajmował około 750 MB. Serializacja obiektu do łańcucha JSON wymagała około dwukrotności rozmiaru obiektu.
- Wreszcie, ciąg JSON był mniej więcej wielkości oryginalnego obiektu.
- W rezultacie zużycie pamięci wzrosło o około trzykrotność rozmiaru obiektu FSTree, szybko osiągając 3,18 GB. Oszacowano, że ostateczne szczytowe użycie pamięci wymagało około czterokrotności rozmiaru FSTree.
Problemy z powyższą implementacją
Rdzeniem naszego podejścia było skonstruowanie obiektu FSTree. Metoda serializacji JSON mogła bezpośrednio serializować obiekt do łańcucha w formacie JSON. Dlatego po zbudowaniu obiektu FSTree reszta mogła zostać wykonana przez pakiet JSON, co było wygodne.
W przypadku systemu plików z wieloma dużymi plikami, metadane były znaczne. FSTree zapisywało informacje metadanych wpisów całego systemu, więc pamięć zajmowana przez proces zrzutu byłaby wysoka.
Dodatkowo, po serializacji obiektu do łańcucha JSON, rozmiar łańcucha był duży, zasadniczo równoważny dwukrotności rozmiaru metadanych. Jeśli klient hostujący proces zrzutu nie ma wystarczającej ilości pamięci, system operacyjny może zabić proces z powodu problemów z brakiem pamięci (OOM).
Optymalizacja wykorzystania pamięci zrzutu
Jak zmniejszyliśmy użycie pamięci
Aby rozwiązać kwestię wysokiego zużycia pamięci, zmniejszyliśmy ziarnistość przetwarzania danych. Zamiast serializować cały obiekt FSTree, podzieliliśmy go na mniejsze obiekty i serializowaliśmy każdy wpis osobno, dołączając wynikowe ciągi JSON do pliku.
Przeprowadziliśmy rekurencyjne skanowanie drzewa FSTree.
- Dla każdego napotkanego wpisu serializowaliśmy go i zapisywaliśmy do pliku JSON.
- Jeśli wpis był katalogiem, przeszukiwaliśmy go ponownie.
W rezultacie wynikowy plik JSON zachował zgodność jeden do jednego z obiektem FSTree, zachowując strukturę drzewa i kolejność wpisów. W ten sposób w pamięci zrzutu, zachowywaliśmy tylko obiekt o rozmiarze metadanych, co skutkowało znaczną oszczędnością pamięci.
Zaoszczędziliśmy również pozostałą połowę pamięci, serializując i zapisując każdy wpis do pliku JSON, gdy tylko został skonstruowany. Robiąc to podczas całego przechodzenia przez system plików, wszystkie wpisy były serializowane bez potrzeby konstruowania i przechowywania całego drzewa FSTree.
Wreszcie, nie musieliśmy budować obiektu FSTree, a każdy wpis był dostępny tylko raz, serializowany, a następnie odrzucany. Zaowocowało to jeszcze mniejszym zużyciem pamięci.
Wydajność po optymalizacji zużycia pamięci
Po optymalizacji wykorzystania pamięci wyniki testu dla procesu zrzutu wyniosły 8 minut, przy wykorzystaniu pamięci 62 MB. Chociaż zużycie czasu pozostało takie samo, pamięć zmniejszyła się znacząco z 3,18 GB do 62 MB, osiągając imponującą poprawę o 5100%! Zmiany w wykorzystaniu pamięci zostały zilustrowane na poniższym wykresie:
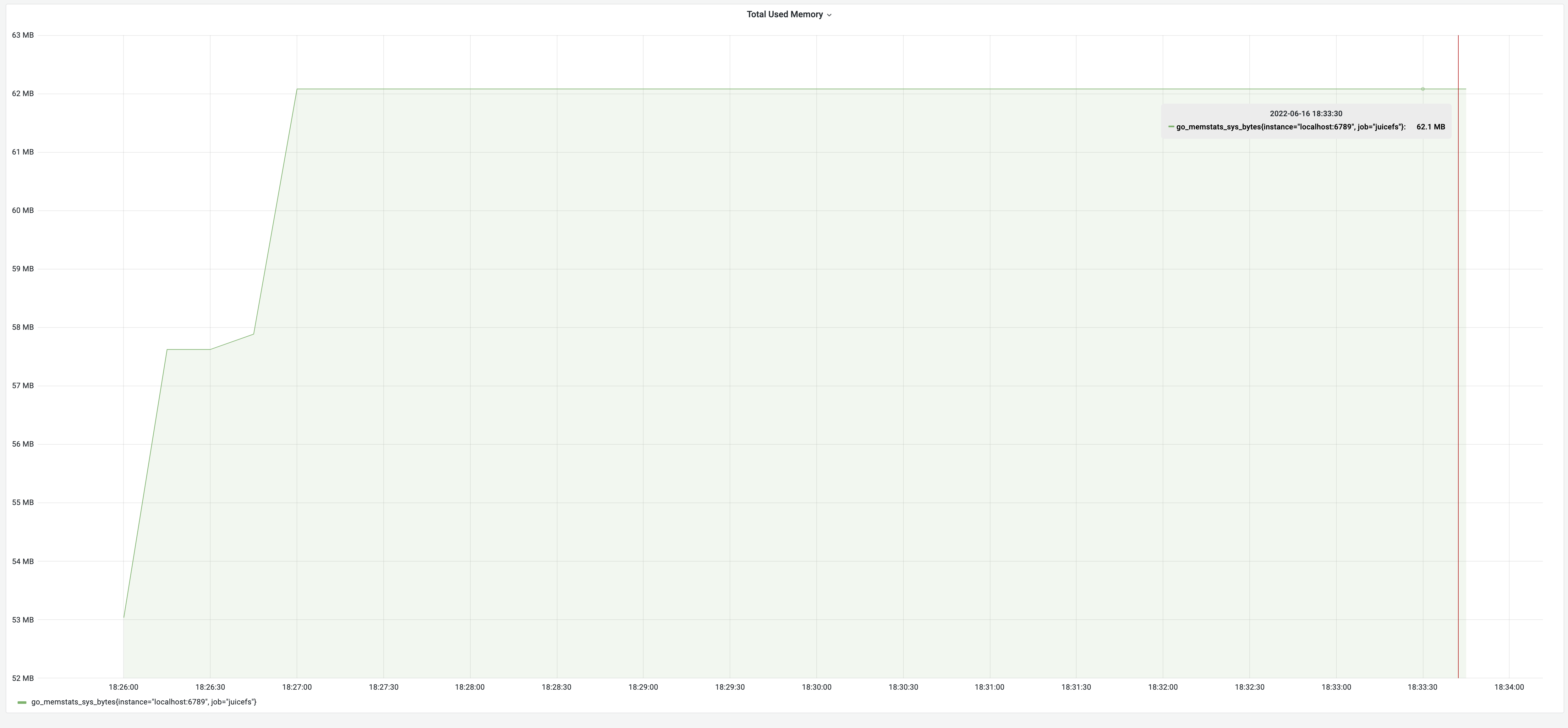 Wykorzystanie pamięci po optymalizacji
Wykorzystanie pamięci po optymalizacjiOptymalizacja środowiska uruchomieniowego zrzutu
Jak zoptymalizowaliśmy czas wykonywania zrzutu
Z powyższych wyników testu wynika, że wykonanie miliona zrzutów zajęło około 8 minut. Gdyby było sto milionów plików, zajęłoby to 13 godzin. Tak długi czas był niedopuszczalny w produkcji. Podczas gdy niewystarczająca ilość pamięci mogła zostać rozwiązana poprzez “wyrzucenie pieniędzy w błoto”, zbyt długi czas przetwarzania zmniejszał skuteczność tego podejścia. Rozwiązanie wymagało zatem optymalizacji wewnętrznej logiki programu.
Przeanalizujmy, który krok pochłaniał najwięcej czasu.
Zazwyczaj zużycie czasu można podzielić na dwa aspekty:
- Znacząca liczba operacji obliczeniowych
- Liczne operacje wejścia/wyjścia
W naszym przypadku oczywiste jest, że mieliśmy do czynienia z dużą liczbą sieciowych operacji wejścia/wyjścia. Proces zrzutu wymagał żądania informacji o metadanych dla każdego napotkanego wpisu, a czas każdego żądania składał się z czasu podróży w obie strony (RTT) oraz czasu obliczania poleceń. Redis, będąc w pamięci, szybko obliczał polecenia. Tak więc, głównym czynnikiem czasochłonnym był RTT. Przy N wpisach istniało N RTT, co prowadziło do znacznych kosztów czasowych.
Aby zmniejszyć liczbę RTT, mogliśmy użyć technologii potokowej Redis. Podstawową zasadą potoku było wysłanie N poleceń jednocześnie. Redis przetwarzał wszystkie N poleceń i zwracał wyniki do klienta za jednym razem, łącząc wyniki w kolejności wykonania. W ten sposób koszt czasowy dla N poleceń został zredukowany do 1 RTT plus czas na obliczenie N poleceń. W praktyce optymalizacja osiągnięta dzięki zastosowaniu potoku była znacząca.
Zgodnie z tą logiką użyliśmy potoku do pobrania wszystkich metadanych z Redis do pamięci. Przypominało to tworzenie migawki Redis w pamięci. Pod względem kodowym wymagało to umieszczenia metadanych w mapie, skutecznie zastępując oryginalną logikę, która wymagała żądań Redis, odczytem z mapy.
Dzięki temu pomysłowi użyliśmy potoku do pobrania wszystkich metadanych w Redis do pamięci, tworząc swego rodzaju migawkę Redis w pamięci. W kodzie zostało to zaimplementowane poprzez przechowywanie metadanych w mapie, umożliwiając oryginalnej logice, która wcześniej żądała danych z Redis, bezpośrednie pobieranie ich z mapy. Podejście to wykorzystywało potok do masowego pobierania danych, zmniejszając RTT i wymagało minimalnych zmian w oryginalnej logice – po prostu zastępując operacje żądania Redis odczytami z mapy.
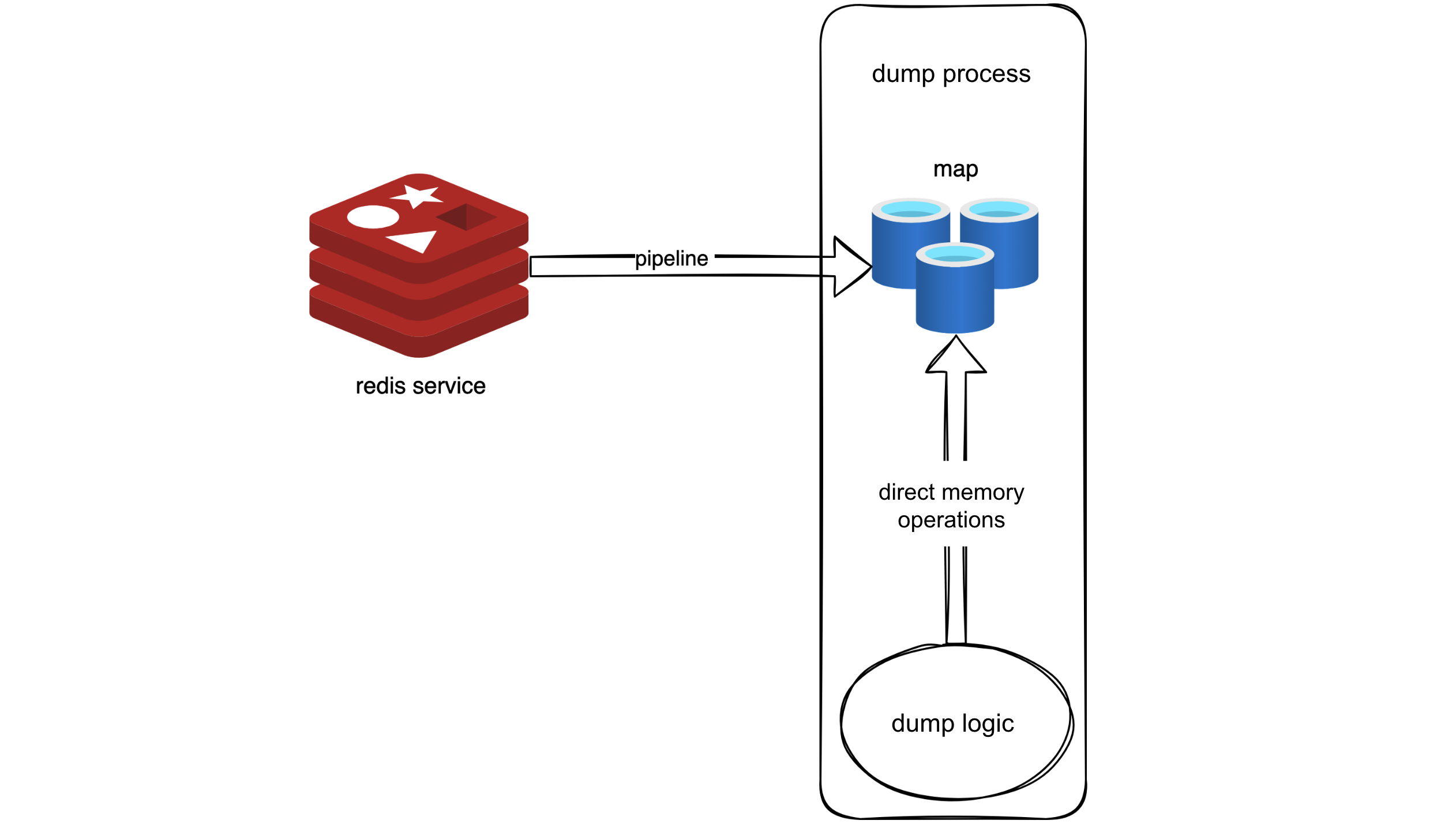 Używanie potoku do pobierania wszystkich metadanych w Redis do pamięci
Używanie potoku do pobierania wszystkich metadanych w Redis do pamięciWydajność po optymalizacji za pomocą podejścia “Snapshot”
Po optymalizacji metodą “snapshot” proces zrzutu trwał 35 sekund, a zużycie pamięci wyniosło 700 MB. Zużycie czasu znacznie spadło z 8 minut do 35 sekund, co stanowi znaczną poprawę o 1270%. Zużycie pamięci wzrosło jednak do 700 MB z powodu skonstruowania pamięci podręcznej metadanych w pamięci, w przybliżeniu wielkości metadanych, jak wskazały wcześniejsze wyniki testów. Spełniło to nasze oczekiwania.
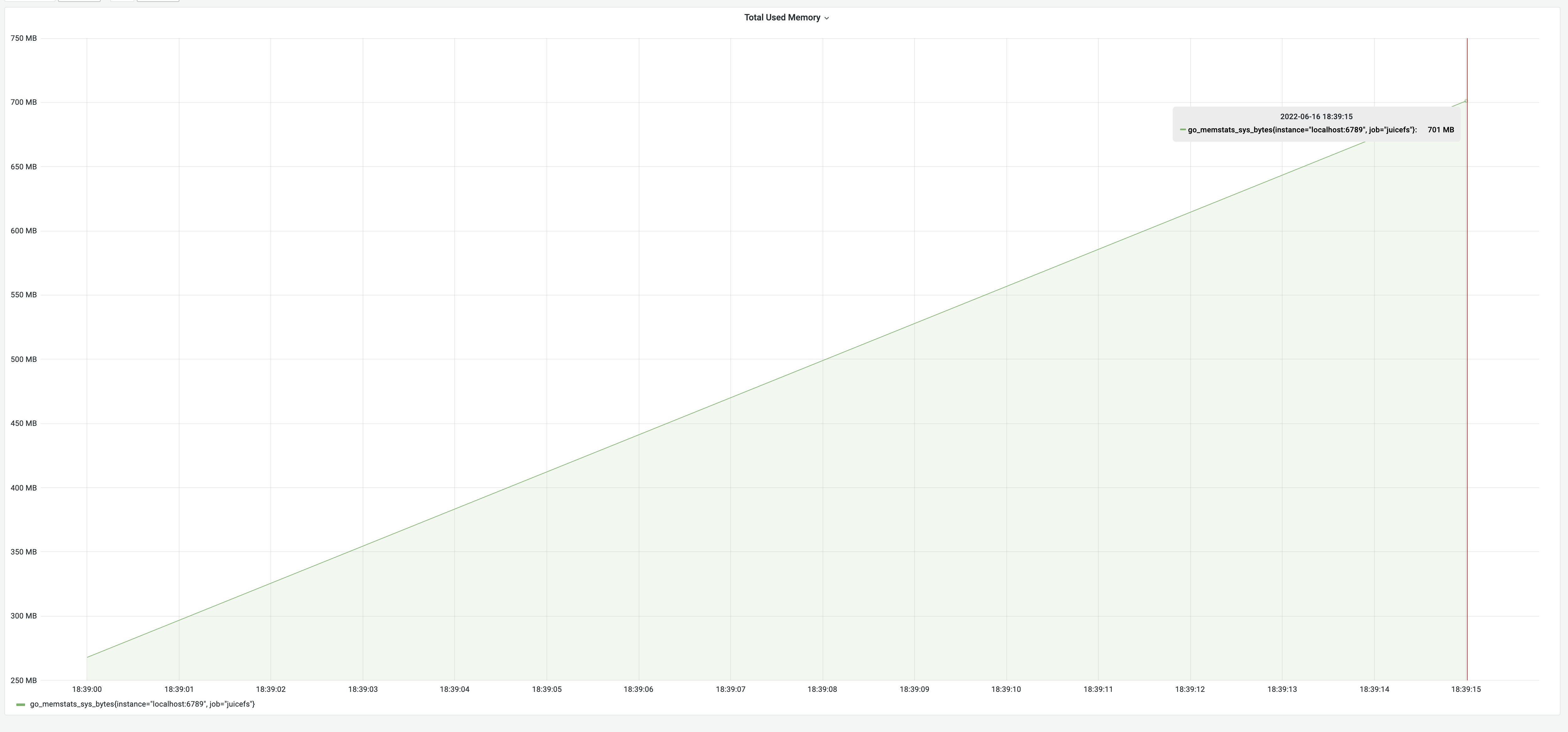 Wydajność po optymalizacji z wykorzystaniem podejścia “snapshot”
Wydajność po optymalizacji z wykorzystaniem podejścia “snapshot”Jak osiągnęliśmy zarówno niskie zużycie pamięci, jak i czas działania?
Podczas gdy podejście “migawkowe” znacznie poprawiło szybkość, zasadniczo umieszczało wszystkie dane Redis w pamięci. Skutkowało to wysokim zużyciem pamięci, zasadniczo rozmiarem metadanych. Tak więc optymalizacja pod kątem zużycia czasu poświęciła wykorzystanie pamięci. Rozmiar wykorzystania pamięci i długi czas przetwarzania były niedopuszczalne w produkcji. Potrzebny był zatem kompromis.
Zastanawiając się nad dwiema poprzednimi optymalizacjami, zapis strumieniowy zajął się wysokim zużyciem pamięci, a użycie potoku Redis zmniejszyło liczbę RTT. Obie optymalizacje były konieczne, a kluczem było ich skuteczne połączenie.
Połączenie potoku z zapisem strumieniowym w celu zmniejszenia zużycia pamięci
Rozważaliśmy dodanie funkcjonalności potoku do wersji zapisu strumieniowego. Wersja zapisu strumieniowego może być postrzegana jako proces potokowy, w którym koniec źródłowy był odpowiedzialny za sekwencyjne konstruowanie wpisów, a koniec odbiorczy był odpowiedzialny za sekwencyjną serializację wpisów. Kolejność wpisów odpowiadała kolejności przechodzenia w głąb drzewa FSTree. Aby użyć potoku, musimy przejść przez przetwarzanie wsadowe. Dlatego możemy logicznie podzielić wpisy na wiele partii, każda o długości 100. Każda partia była jednostką przetwarzania w potoku. Proces stał się:
- Koniec źródłowy powiadomił koniec odbierający, aby rozpoczął serializację partii po przetworzeniu jednej partii.
- Koniec odbierający powiadomił koniec źródłowy, aby skonstruował następną partię po serializacji bieżącej partii.
- Powyższe kroki były powtarzane aż do skutku.
Każda partia korzystała z potoku, aby przyspieszyć uzyskiwanie wyników. W ten sposób potok i zapis strumieniowy współistniały. W ten sposób zoptymalizowaliśmy wykorzystanie pamięci.
Zrównoleglanie wstawiania potoku w celu skrócenia czasu wykonania
Mogliśmy również dodatkowo zoptymalizować zużycie czasu. Przeanalizowaliśmy bieżącą operację potoku i stwierdziliśmy, że gdy koniec źródłowy wysłał żądanie potoku dla metadanych, koniec odbierający był bezczynny, ponieważ nie było danych do serializacji. Podobnie, gdy koniec odbierający serializował, koniec źródłowy był bezczynny. W związku z tym potok działał w sposób przerywany, co skutkowało obliczeniami szeregowymi. Aby jeszcze bardziej zmniejszyć zużycie czasu, zrównolegliliśmy wstawianie potoku, aby zwiększyć wykorzystanie procesora i przyspieszyć proces.
Następnie zastanawialiśmy się, jak sprawić, by źródło i serializacja działały równolegle. W przypadku tej samej partii generowanie i przetwarzanie danych z pewnością nie było równoległe. Tylko partie z metadanymi, które nie zostały jeszcze zażądane i partie do serializacji mogły być przetwarzane równolegle. Innymi słowy, strona źródłowa nie musiała czekać na zakończenie serializacji. Końcówka źródłowa musiała jedynie pobrać dane, a pobrane dane zostały umieszczone w potoku w odpowiedniej kolejności. Serializacja kończy się serializacją danych w kolejności.
Jeśli okazało się, że partia nie została jeszcze pobrana, czekała, aż strona źródłowa poinformuje ją, że partia jest gotowa. Biorąc pod uwagę, że szybkość tworzenia partii była wolniejsza niż czas potrzebny na serializację partii, mogliśmy również dodać współbieżność do końca źródła. Koniec źródłowy jednocześnie serializował wiele partii, aby skrócić czas oczekiwania końca serializacji.
Zwizualizujmy ten proces za pomocą poniższego diagramu. Załóżmy, że bieżący poziom współbieżności końca źródła wynosi 2.
- Coroutine 1 i Coroutine 2 jednocześnie konstruują Batch 1 i Batch 2. W międzyczasie koniec serializacji czeka na skonstruowanie partii 1. Gdy Coroutine 1 zakończy konstruowanie Batch 1, powiadamia on koniec serializacji, aby rozpocząć serializację Batch 1 sekwencyjnie.
- Gdy Batch 1 jest serializowany, koniec serializacji powiadamia Coroutine 1, aby rozpoczął konstruowanie Batch 3. Dzieje się tak, ponieważ Batch 2 i Batch 4 są obsługiwane przez Coroutine 2, a każdy coroutine ma przypisane partie dla końca serializacji, aby wywnioskować, który z nich powiadomić jako następny zgodnie z pewnymi zasadami.
- Po powiadomieniu Coroutine 1, serialization end rozpoczyna serializację Batch 2. Najpierw sprawdza, czy Batch 2 jest gotowy; jeśli nie jest gotowy, oczekuje się, że powiadomi Coroutine 2.
- Po serializacji Batch 2, koniec serializacji powiadamia Coroutine 2 o rozpoczęciu konstruowania Batch 4 i tak dalej. W ten sposób koniec serializacji może serializować wpisy równolegle z przetwarzaniem wpisów przez koniec źródła, nadążając za szybkością serializacji.
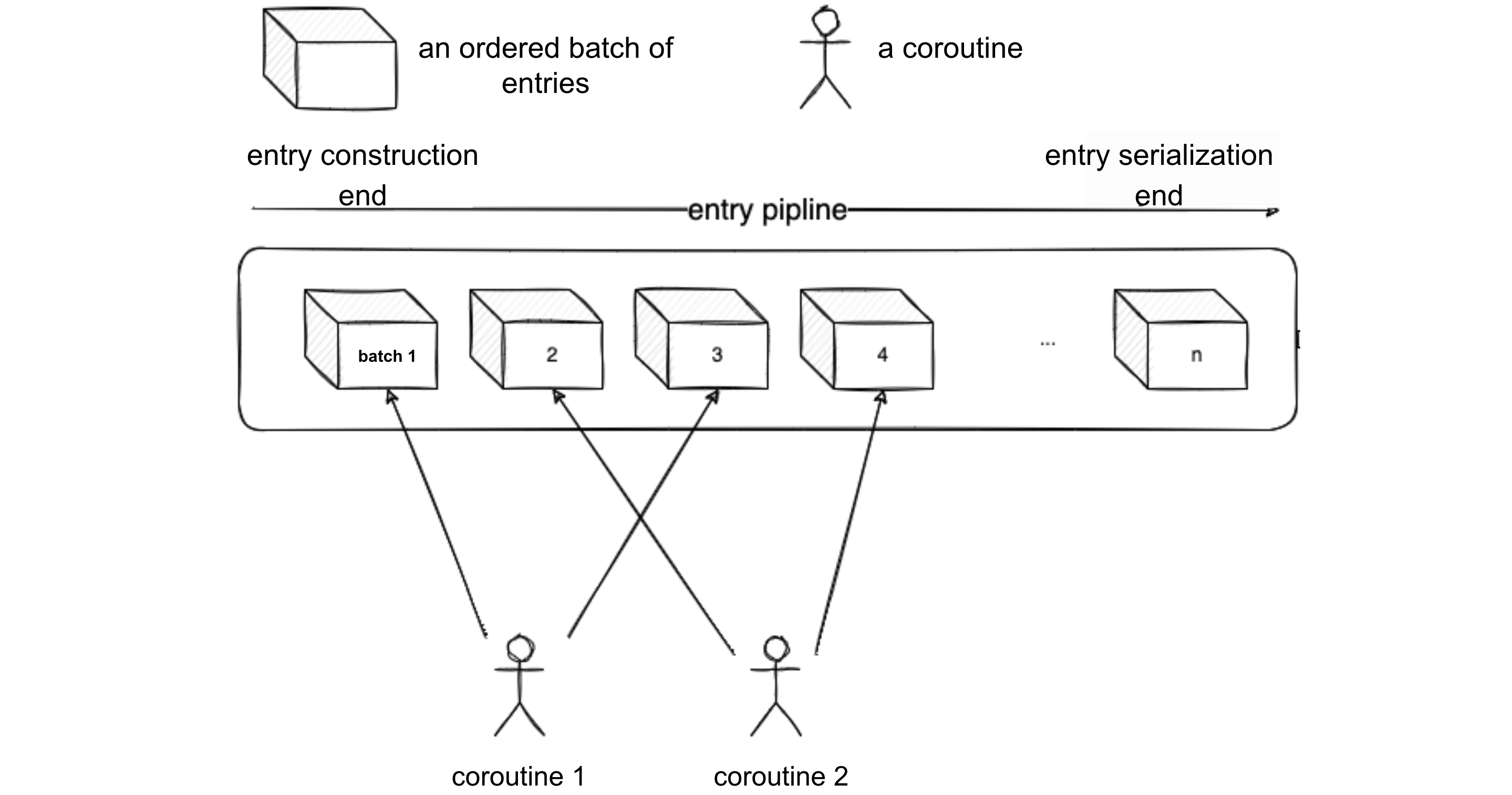 Koniec źródłowy i koniec serializacji działają równolegle
Koniec źródłowy i koniec serializacji działają równolegleWydajność po optymalizacji użycia pamięci i czasu wykonywania
Po zoptymalizowaniu zużycia pamięci i czasu, wyniki testów wyniosły 19 sekund i zużycie pamięci na poziomie 75 MB. Pozwoliło to uzyskać optymalne efekty każdej indywidualnej optymalizacji. Naprawdę udało się osiągnąć cel, jakim było uzyskanie tego, co najlepsze z obu światów.
Optymalizacja procesu ładowania
Przed optymalizacją obciążenia
Metoda niewykonalna
W porównaniu do zrzutu, logika obciążenia była prosta.
Najprostszą metodą było:
- Odczytanie całego pliku JSON do pamięci.
- Proszę deserializować go do obiektu FSTree.
- Przechodzenie przez drzewo FSTree w kolejności głębokości.
- Proszę wstawić wymiary metadanych każdego wpisu do Redis osobno.
Metoda ta miała jednak pewien problem. Biorąc za przykład drzewo plików w zawartości pliku JSON wspomnianego wcześniej, podczas zrzutu tego systemu plików wystąpiła sytuacja: plik1 został już zeskanowany, a Redis zwrócił nlink dla pliku1 jako 2 (ponieważ hardLink był na stałe powiązany z plikiem1). W tym momencie użytkownik usunął hardLinki nlink dla file1 został zmodyfikowany na 1 w Redis. Ponieważ jednak został on już przeskanowany w zrzucie, wartość nlink w zrzuconym pliku JSON nadal pozostawał 2, co prowadziło do błędu nlink błąd. nlink był kluczowy dla systemu plików, a błędy w jego wartości mogły powodować problemy, takie jak niemożność usunięcia lub utrata danych. Dlatego ta metoda, która może prowadzić do nlink błędów była niewykonalna.
Rozwiązanie
Aby rozwiązać ten problem, musieliśmy ponownie obliczyć wartość nlink podczas ładowania. Wymagało to od nas zapisania wszystkich informacji o i-węźle przed załadowaniem.
- Zbudowaliśmy mapę w pamięci, z kluczem będącym i-węzłem i wartością będącą wszystkimi metadanymi wpisu.
- Podczas przeglądania drzewa wpisów, umieszczaliśmy wszystkie zeskanowane wpisy typu plik w mapie, zamiast wstawiać je bezpośrednio do Redis. Przed umieszczeniem wpisów w mapie za każdym razem system sprawdzał, czy dany i-węzeł już istniał. Jeśli istniał, oznaczało to, że był to twardy link i musieliśmy inkrementować wartość
nlinktego i-węzła. Ta sama sytuacja może również wystąpić w podkatalogach. Dlatego przejście do podkatalogu wymagało inkrementacji wartościnlinkkatalogu nadrzędnego. Po przejściu do wpisu,nlinkzostał ponownie obliczony. - Przeszliśmy przez mapę wpisów i wstawiliśmy wszystkie metadane wpisów do Redis. Aby przyspieszyć wstawianie, musieliśmy użyć metody potokowej.
Wydajność w oparciu o powyższe rozwiązanie
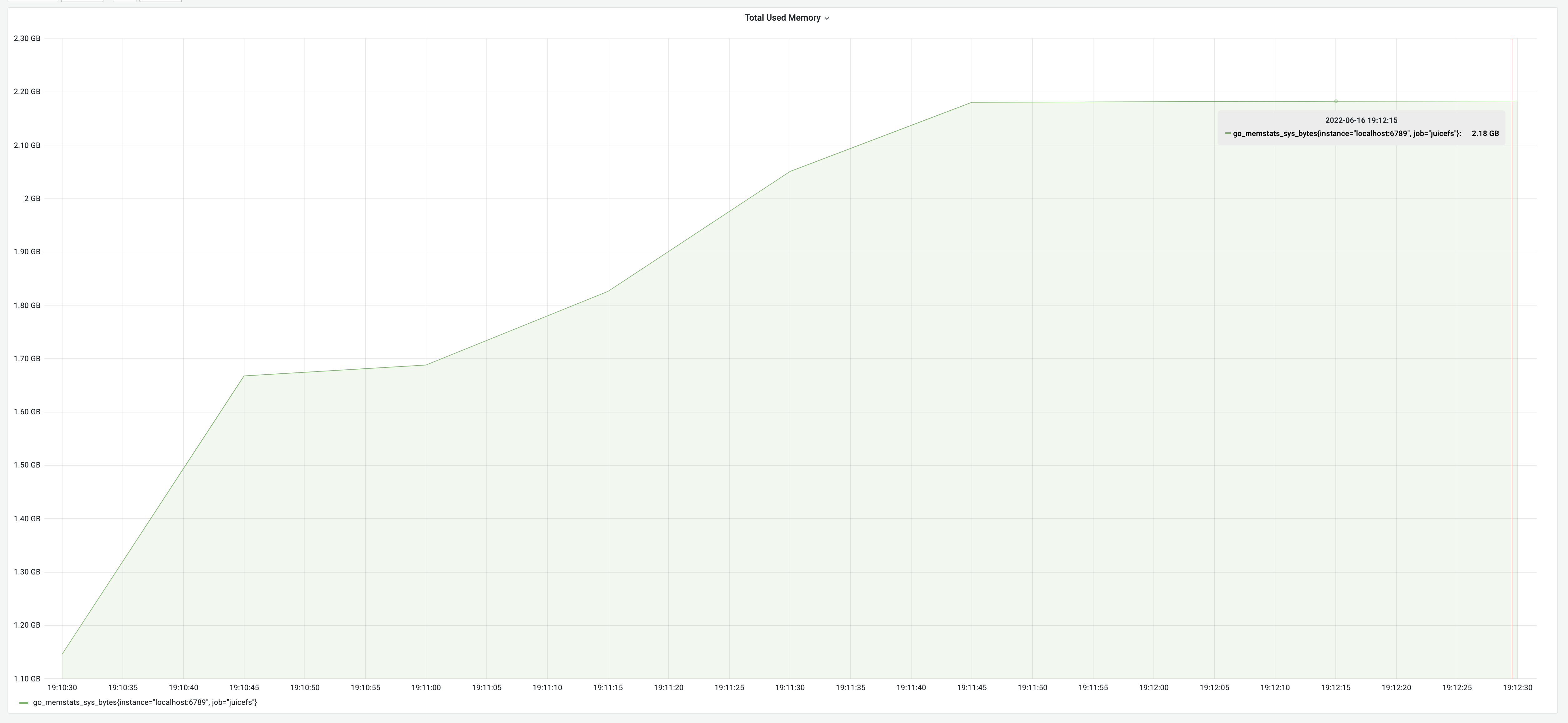
Wynik testu jest zgodny z powyższą logiką: czas działania 2 minuty i 15 sekund, przy zużyciu pamięci 2,18 GB.
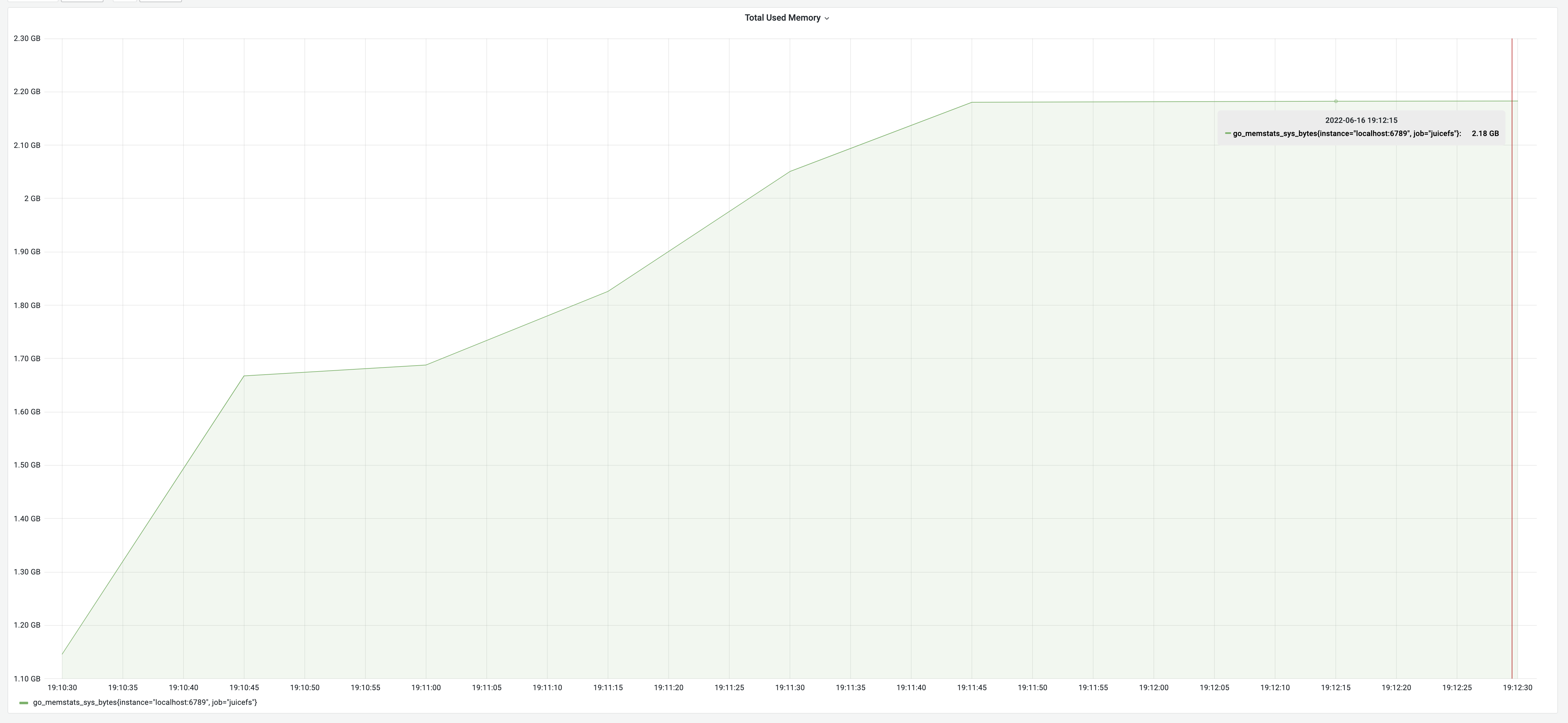
Optymalizacja czasu działania obciążenia
Jak zredukowaliśmy czas uruchamiania obciążenia
Samo użycie potoku nie skróciło czasu działania do ekstremum. Mogliśmy jeszcze bardziej skrócić czas za pomocą innych metod. Redis był bardzo szybki; nawet przy użyciu potoku szybkość przetwarzania poleceń była nadal znacznie niższa niż czas RTT. Co więcej, proces ładowania potoku był również operacją pamięciową, a czas tworzenia potoku był znacznie krótszy niż czas RTT.
Możemy przeanalizować, gdzie czas został zmarnowany, podając skrajny przykład: załóżmy, że czas tworzenia potoku i czas przetwarzania potoku przez Redis wynoszą 10 ms, a czas RTT wynosi 80 ms. Oznacza to, że na każde 10 ms spędzone przez proces ładowania na budowaniu potoku dla Redis, przed skonstruowaniem następnego potoku trzeba było dodatkowo czekać 90 ms. W rezultacie wykorzystanie procesora zarówno dla procesu ładowania, jak i Redis wynosiło zaledwie 10%. Podkreśliło to niskie wykorzystanie zasobów procesora po obu stronach.
Aby temu zaradzić, zwiększyliśmy wydajność poprzez jednoczesne wstawianie potoków, zwiększając w ten sposób wykorzystanie procesora na obu końcach i oszczędzając czas.
Wydajność po optymalizacji środowiska uruchomieniowego
Po wdrożeniu optymalizacji współbieżnej, wyniki testu wykazały czas działania na poziomie 1 minuty, przy wykorzystaniu pamięci na poziomie 2,17 GB. Przyniosło to poprawę wydajności o 125%.
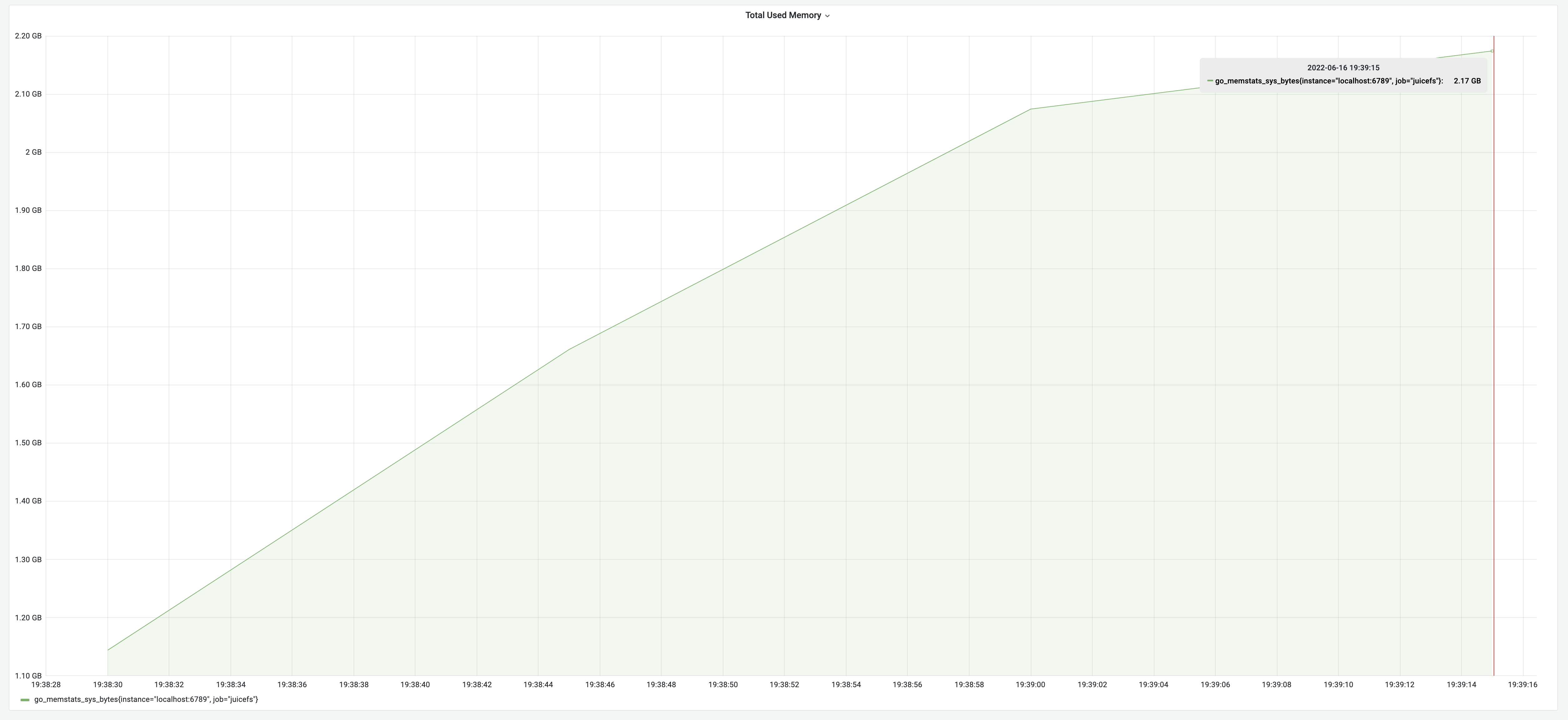
Optymalizacja wykorzystania pamięci
Jak zoptymalizowaliśmy użycie pamięci
Dzięki poprzednim testom stało się oczywiste, że optymalizacja wykorzystania pamięci koncentrowała się głównie na wysiłkach związanych z serializacją. Początkowe działanie polegające na odczytaniu całego pliku JSON i deserializacji go do struktury wymagało około dwa razy więcej pamięci niż metadane, w tym rozmiar ciągu JSON i rozmiar struktury. Uznając znaczny koszt odczytu całego pliku, przyjęliśmy podejście strumieniowe, odczytując i deserializując najmniejszy obiekt JSON na raz. To znacznie zmniejszyło zużycie pamięci.
Innym problemem podczas procesu ładowania było przechowywanie wszystkich wpisów w pamięci w celu ponownego obliczenia nlink. Przyczyniało się to znacząco do wysokiego zużycia pamięci. Rozwiązanie było proste: podczas gdy nlink musiały zostać ponownie obliczone, nie było potrzeby rejestrowania wszystkich atrybutów wpisu. Zmieniając typ wartości mapy na int64, każde wstawienie zwiększało wartość o 1. Wyeliminowało to potrzebę dużej mapy, dodatkowo zmniejszając zużycie pamięci.
Wydajność po wdrożeniu odczytu strumieniowego
Po wdrożeniu optymalizacji odczytu strumieniowego wyniki testu wykazały czas działania wynoszący 40 sekund, przy zużyciu pamięci wynoszącym 518 MB. Optymalizacja pamięci osiągnęła znaczną poprawę o 330%.
Podsumowanie
Porównanie JuiceFS 1.0-rc2 z v0.15.2:
- Proces zrzutu:
- Oryginał: czas działania 7 minut i 47 sekund, użycie pamięci 3,18 GB
- Zoptymalizowany: czas działania 19 sekund, użycie pamięci 75 MB
- Poprawa: 2300% czasu działania, 4200% wykorzystania pamięci
- Proces ładowania:
- Oryginał: czas działania 2 minuty i 15 sekund, użycie pamięci 2,18 GB
- Zoptymalizowany: czas działania 40 sekund, użycie pamięci 518 MB
- Poprawa: 230% czasu działania, 330% wykorzystania pamięci

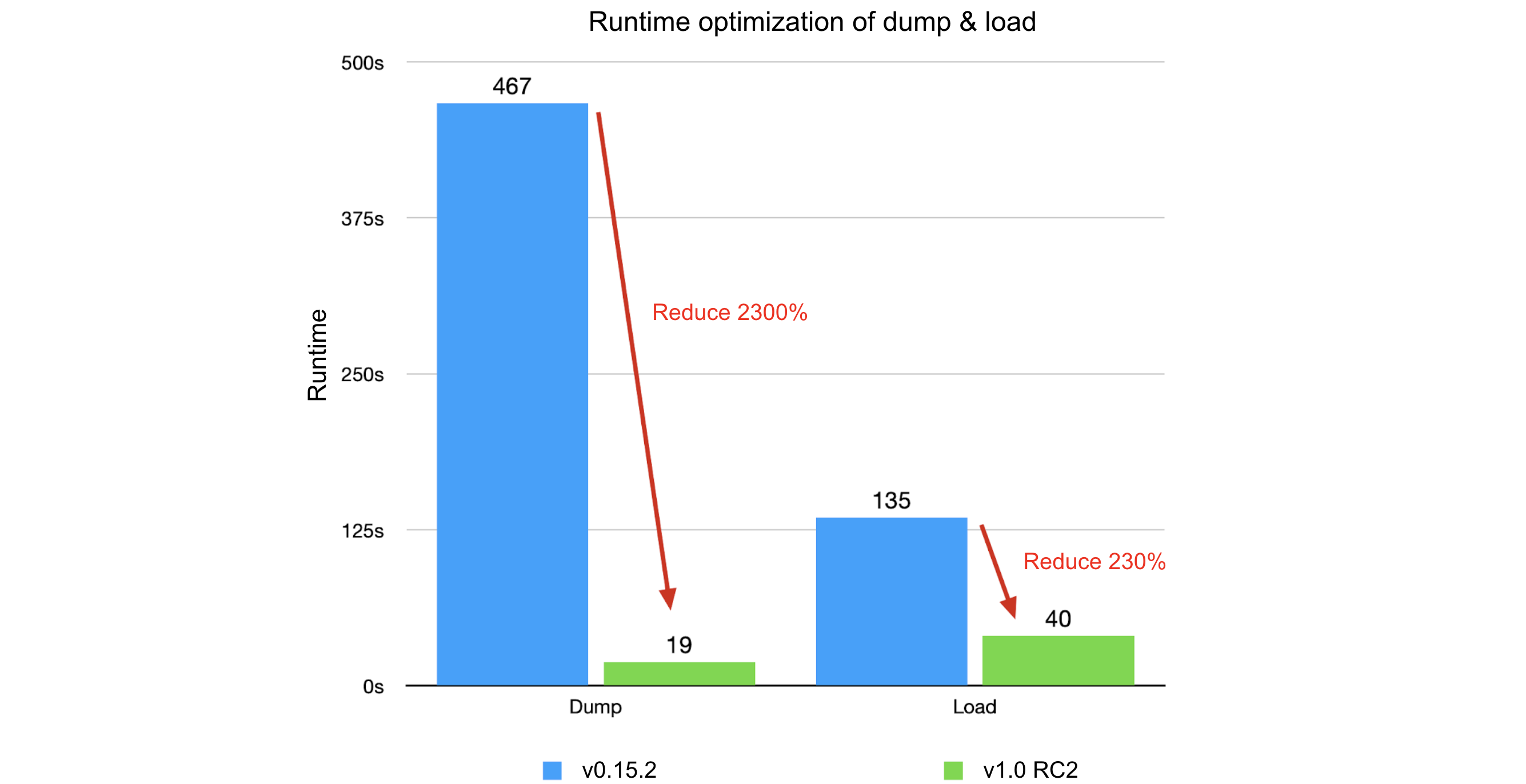
Wyniki optymalizacji były znaczące. Mamy nadzieję, że nasze doświadczenie pomoże Państwu ulepszyć strategie optymalizacji i zwiększyć wydajność systemu.