
W tym artykule opisano, jak zaimplementować moduł konsensusu serwera Raft w C++20 bez korzystania z dodatkowych bibliotek. Narracja podzielona jest na trzy główne sekcje:
- Kompleksowy przegląd algorytmu Raft
- Szczegółowy opis rozwoju serwera Raft
- Opis niestandardowej biblioteki sieciowej opartej na koroutynach
Implementacja wykorzystuje solidne możliwości C++20, w szczególności korutyn, aby przedstawić skuteczną i nowoczesną metodologię budowania krytycznego komponentu biblioteki sieciowej. systemów rozproszonych. Ekspozycja ta nie tylko demonstruje praktyczne zastosowanie i zalety procedur współbieżnych C++20 w zaawansowanych środowiskach programistycznych, ale także zapewnia dogłębną analizę wyzwań i rozwiązań napotkanych podczas budowania modułu konsensusu od podstaw, takiego jak Raft Server. Raft Server i repozytoria bibliotek sieciowych, miniraft-cpp oraz coroiosą dostępne do dalszej eksploracji i praktycznych zastosowań.
Wprowadzenie
Zanim zagłębimy się w zawiłości algorytmu Raft, rozważmy rzeczywisty przykład. Naszym celem jest opracowanie sieciowego systemu przechowywania kluczy-wartości (K/V). W C++, można to łatwo osiągnąć za pomocą funkcji unordered_map<string, string>. Jednakże, w rzeczywistych zastosowaniach, wymóg dotyczący system pamięci masowej odporny na uszkodzenia zwiększa złożoność. Pozornie proste podejście może wiązać się z wdrożeniem trzech (lub więcej) maszyn, z których każda obsługuje replikę tej usługi. Oczekuje się, że użytkownicy będą zarządzać replikacją i spójnością danych. Metoda ta może jednak prowadzić do nieprzewidywalnych zachowań. Na przykład możliwe jest zaktualizowanie danych przy użyciu określonego klucza, a następnie pobranie starszej wersji później.
To, czego użytkownicy naprawdę chcą, to system rozproszony, potencjalnie rozproszony na wielu maszynach, który działa tak płynnie, jak system z jednym hostem. Aby spełnić ten wymóg, moduł konsensusu jest zwykle umieszczany przed magazynem K/V (lub dowolną podobną usługą, zwaną dalej “maszyną stanu”). Taka konfiguracja zapewnia, że wszystkie interakcje użytkownika z maszyną stanu są kierowane wyłącznie przez moduł konsensusu, a nie bezpośredni dostęp. Mając na uwadze ten kontekst, przyjrzyjmy się teraz, jak zaimplementować taki moduł konsensusu, używając algorytmu Raft jako przykładu.
Przegląd algorytmu Raft
W algorytmie Raft istnieje nieparzysta liczba uczestników znanych jako rówieśników. Każdy peer prowadzi własny dziennik rekordów. Istnieje jeden lider peer, a pozostali są obserwatorami. Użytkownicy kierują wszystkie żądania (odczytu i zapisu) do lidera. Po otrzymaniu żądania zapisu w celu zmiany maszyny stanów, lider rejestruje je jako pierwsze, zanim przekaże je do obserwatorów, którzy również je rejestrują. Gdy większość użytkowników odpowie pomyślnie, lider uznaje ten wpis za zatwierdzony, stosuje go do maszyny stanów i powiadamia użytkownika o jego powodzeniu.
The Termin jest kluczową koncepcją w Raft i może się tylko rozwijać. The Termin zmienia się, gdy następują zmiany w systemie, takie jak zmiana przywództwa. Dziennik w Raft ma specyficzną strukturę, z każdym wpisem składającym się z Termin oraz Ładunek. Termin ten odnosi się do lidera, który napisał pierwszy wpis. The Payload reprezentuje zmiany, które należy wprowadzić w maszynie stanów. Raft gwarantuje, że dwa wpisy z tym samym indeksem i terminem są identyczne. Dzienniki Raft nie są tylko załącznikami i mogą zostać obcięte. Na przykład w poniższym scenariuszu lider S1 zreplikował dwa wpisy przed awarią. S2 przejął inicjatywę i rozpoczął replikację wpisów, a dziennik S1 różnił się od dzienników S2 i S3. W rezultacie ostatni wpis w dzienniku S1 zostanie usunięty i zastąpiony nowym.

Raft RPC API
Przeanalizujmy Raft RPC. Warto zauważyć, że interfejs API Raft jest dość prosty i zawiera tylko dwa wywołania. Zaczniemy od przyjrzenia się API wyborów lidera. Proszę zauważyć, że Raft gwarantuje, że w każdej kadencji może być tylko jeden lider. Mogą również istnieć kadencje bez lidera, na przykład w przypadku niepowodzenia wyborów. Aby zapewnić, że odbędą się tylko jedne wybory, peer zapisuje swój głos w trwałej zmiennej o nazwie VotedFor. RPC wyborów nazywa się RequestVote i ma trzy parametry: Term, LastLogIndex, oraz LastLogTerm. Odpowiedź zawiera Term oraz VoteGranted. Warto zauważyć, że każde żądanie zawiera Term, a w Raft peery mogą skutecznie komunikować się tylko wtedy, gdy ich Warunki są zgodne.
Kiedy peer inicjuje wybory, wysyła komunikat RequestVote żądanie do innych peerów i zbiera ich głosy. Jeśli większość odpowiedzi jest pozytywna, peer awansuje do roli lidera.
Przyjrzyjmy się teraz AppendEntries request. Akceptuje ono parametry takie jak Term, PrevLogIndex, PrevLogTerm, oraz Entries, a odpowiedź zawiera Term oraz Success. Jeśli Entries w żądaniu jest puste, działa ono jak pole Heartbeat.
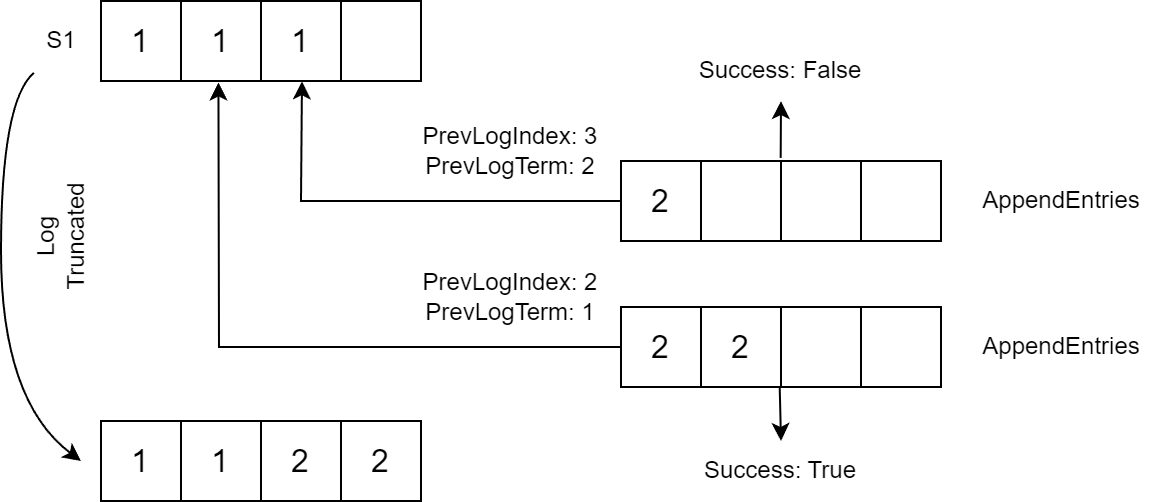
Kiedy AppendEntries żądanie zostanie odebrane, obserwujący sprawdza PrevLogIndex dla Term. Jeśli pasuje PrevLogTerm, obserwujący dodaje Entries do swojego logu zaczynającego się od PrevLogIndex + 1 (wpisy po PrevLogIndex są usuwane, jeśli istnieją):
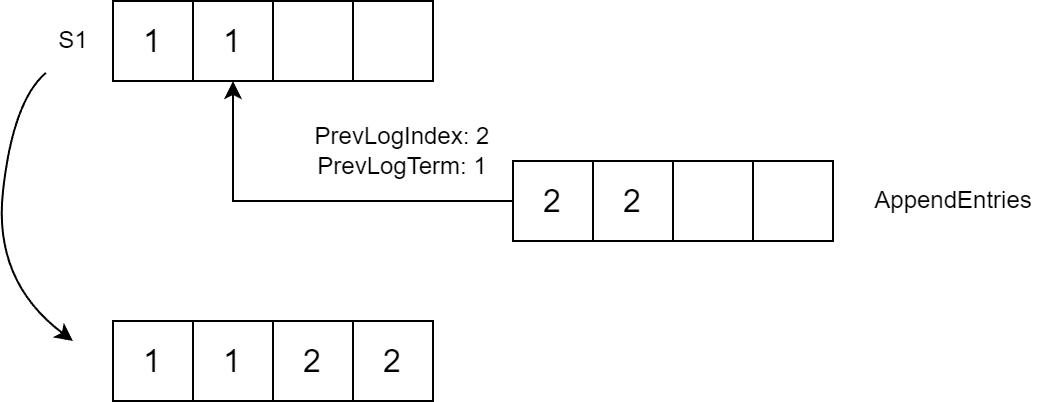
Jeśli warunki nie pasują, element podążający zwraca Success=false. W takim przypadku lider ponawia wysłanie żądania, obniżając wartość PrevLogIndex o jeden.
Gdy peer otrzyma żądanie RequestVote porównuje swoje żądanie LastTerm i LastLogIndex do najnowszego wpisu w dzienniku. Jeśli para jest mniejsza lub równa parze żądającego, peer zwraca VoteGranted=true.
State Transitions in Raft
Przejścia stanów w Raft wyglądają następująco. Każdy peer rozpoczyna się w stanie Follower . Jeśli Follower nie otrzyma AppendEntries w określonym czasie, przedłuża on swój Term i przenosi się do Candidate uruchamiając wybory. Peer może przejść ze stanu Candidate do stanu Leader stanu, jeśli wygra wybory, lub powrócić do stanu Follower stanu, jeśli otrzyma AppendEntries żądanie. A Candidate może również powrócić do bycia Candidate jeśli nie przejdzie do Follower lub Leader w okresie limitu czasu. Jeśli peer w dowolnym stanie otrzyma żądanie RPC z parametrem Term większy niż jego aktualny, przechodzi do stanu Follower stanu.
Zobowiązanie
Rozważmy teraz przykład, który pokazuje, że Raft nie jest tak prosty, jak mogłoby się wydawać. Przykład ten zaczerpnąłem z pracy doktorskiej Diego Ongaro. S1 był liderem w Termin 2, gdzie powielił dwa wpisy przed awarią. Następnie S5 objął prowadzenie w Term 3, dodał wpis, a następnie uległ awarii. Następnie, S2 przejął przywództwo w Terminie 4, powielił wpis od Termin 2, dodano własny wpis dla Termin 4, a następnie uległ awarii. Daje to dwa możliwe wyniki: S5 odzyskuje przywództwo i obcina wpisy z Termin 2, lub S1 odzyskuje przywództwo i zatwierdza wpisy z Termin 2. Wpisy z Termin 2 są bezpiecznie zatwierdzane dopiero po ich pokryciu przez kolejny wpis od nowego lidera.

Ten przykład pokazuje, jak algorytm Raft działa w dynamicznych i często nieprzewidywalnych okolicznościach. Sekwencja zdarzeń, która obejmuje wielu liderów i awarie, pokazuje złożoność utrzymywania spójnego stanu w systemie rozproszonym. Złożoność ta nie jest od razu widoczna, ale staje się ważna w sytuacjach obejmujących zmiany liderów i awarie systemu. Przykład ten podkreśla znaczenie solidnego i przemyślanego podejścia do radzenia sobie z takimi złożonościami, co jest dokładnie tym, co Raft stara się rozwiązać.
Materiały dodatkowe
W celu dalszego studiowania i głębszego zrozumienia Raft, polecam następujące materiały: oryginalny dokument Raft, który jest idealny do wdrożenia. Rozprawa doktorska Diego Ongaro dostarcza bardziej szczegółowych informacji. Wykład Maxima Babenko jest jeszcze bardziej szczegółowy.
Wdrożenie tratwy
Przejdźmy teraz do implementacji serwera Raft, która moim zdaniem w znacznym stopniu korzysta z procedur C++20. W mojej implementacji stan trwały jest przechowywany w pamięci. Jednak w rzeczywistych scenariuszach powinien on być zapisywany na dysku. Powiem więcej na temat MessageHolder później. Działa on podobnie do shared_ptr, ale jest specjalnie zaprojektowany do obsługi wiadomości Raft, zapewniając wydajne zarządzanie i przetwarzanie tej komunikacji.
struct TState {
uint64_t CurrentTerm = 1;
uint32_t VotedFor = 0;
std::vector<TMessageHolder<TLogEntry>> Log;
};W Volatile Stateoznaczyłem wpisy za pomocą L dla “lidera” lub F dla “zwolennika”, aby wyjaśnić ich użycie. The CommitIndex oznacza ostatni wpis dziennika, który został zatwierdzony. Dla kontrastu, LastApplied jest ostatnim wpisem dziennika zastosowanym do maszyny stanów i jest zawsze mniejszy lub równy wartości CommitIndex. The NextIndex jest ważny, ponieważ identyfikuje następny wpis dziennika, który ma zostać wysłany do urządzenia równorzędnego. Podobnie, MatchIndex śledzi ostatni wpis dziennika, który wykrył dopasowanie. The Votes zawiera identyfikatory użytkowników, którzy na mnie głosowali. Limity czasu są ważnym aspektem do zarządzania: HeartbeatDue i RpcDue zarządzać limitami czasu liderów, podczas gdy ElectionDue obsługuje przekroczenia limitu czasu obserwujących.
using TTime = std::chrono::time_point<std::chrono::steady_clock>;
struct TVolatileState {
uint64_t CommitIndex = 0; // L,F
uint64_t LastApplied = 0; // L,F
std::unordered_map<uint32_t, uint64_t> NextIndex; // L
std::unordered_map<uint32_t, uint64_t> MatchIndex; // L
std::unordered_set<uint32_t> Votes; // C
std::unordered_map<uint32_t, TTime> HeartbeatDue; // L
std::unordered_map<uint32_t, TTime> RpcDue; // L
TTime ElectionDue; // F
};Raft API
Moja implementacja algorytmu Raft ma dwie klasy. Pierwsza z nich to INode, która oznacza peera. Klasa ta zawiera dwie metody: Send, która przechowuje wychodzące wiadomości w wewnętrznym buforze, oraz Drain, która obsługuje faktyczną wysyłkę wiadomości. Raft jest drugą klasą i zarządza bieżącym stanem peera. Zawiera również dwie metody: Process, która obsługuje połączenia przychodzące, oraz ProcessTimeout, która musi być regularnie wywoływana w celu zarządzania limitami czasu, takimi jak limit czasu wyborów lidera. Użytkownicy tych klas powinni używać Process, ProcessTimeout, oraz Drain metody w razie potrzeby. INode‘s Send jest wywoływana wewnętrznie w klasie Raft, zapewniając, że obsługa wiadomości i zarządzanie stanem są płynnie zintegrowane z frameworkiem Raft.
struct INode {
virtual ~INode() = default;
virtual void Send(TMessageHolder<TMessage> message) = 0;
virtual void Drain() = 0;
};
class TRaft {
public:
TRaft(uint32_t node,
const std::unordered_map<uint32_t, std::shared_ptr<INode>>& nodes);
void Process(TTime now,
TMessageHolder<TMessage> message,
const std::shared_ptr<INode>& replyTo = {});
void ProcessTimeout(TTime now);
};Komunikaty Raft
Przyjrzyjmy się teraz, jak wysyłam i odczytuję wiadomości Raft. Zamiast korzystać z biblioteki serializacji, odczytuję i wysyłam nieprzetworzone struktury w formacie TLV. Tak wygląda nagłówek wiadomości:
struct TMessage {
uint32_t Type;
uint32_t Len;
char Value[0];
};Dla dodatkowej wygody wprowadziłem nagłówek drugiego poziomu:
struct TMessageEx: public TMessage {
uint32_t Src = 0;
uint32_t Dst = 0;
uint64_t Term = 0;
};Zawiera on identyfikator nadawcy i odbiorcy w każdej wiadomości. Z wyjątkiem LogEntry, wszystkie wiadomości dziedziczą po TMessageEx. LogEntry oraz AppendEntries są realizowane w następujący sposób:
struct TLogEntry: public TMessage {
static constexpr EMessageType MessageType = EMessageType::LOG_ENTRY;
uint64_t Term = 1;
char Data[0];
};
struct TAppendEntriesRequest: public TMessageEx {
static constexpr EMessageType MessageType
= EMessageType::APPEND_ENTRIES_REQUEST;
uint64_t PrevLogIndex = 0;
uint64_t PrevLogTerm = 0;
uint32_t Nentries = 0;
};
Aby ułatwić obsługę wiadomości, używam klasy o nazwie MessageHolder, przypominającej klasę shared_ptr:
template<typename T>
requires std::derived_from<T, TMessage>
struct TMessageHolder {
T* Mes;
std::shared_ptr<char[]> RawData;
uint32_t PayloadSize;
std::shared_ptr<TMessageHolder<TMessage>[]> Payload;
template<typename U>
requires std::derived_from<U, T>
TMessageHolder<U> Cast() {...}
template<typename U>
requires std::derived_from<U, T>
auto Maybe() { ... }
};Ta klasa zawiera tablicę znaków zawierającą samą wiadomość. Może również zawierać tablicę Payload (który jest używany tylko dla AppendEntry), a także metody bezpiecznego rzutowania wiadomości typu bazowego na konkretną wiadomość (metoda Maybe ) i niebezpiecznego rzutowania (metoda Cast method). Oto typowy przykład użycia metody MessageHolder:
void SomeFunction(TMessageHolder<TMessage> message) {
auto maybeAppendEntries = message.Maybe<TAppendEntriesRequest>();
if (maybeAppendEntries) {
auto appendEntries = maybeAppendEntries.Cast();
}
// if we are sure
auto appendEntries = message.Cast<TAppendEntriesRequest>();
// usage with overloaded operator->
auto term = appendEntries->Term;
auto nentries = appendEntries->Nentries;
// ...
}I przykład z życia wzięty Candidate state handler:
void TRaft::Candidate(TTime now, TMessageHolder<TMessage> message) {
if (auto maybeResponseVote = message.Maybe<TRequestVoteResponse>()) {
OnRequestVote(std::move(maybeResponseVote.Cast()));
} else
if (auto maybeRequestVote = message.Maybe<TRequestVoteRequest>())
{
OnRequestVote(now, std::move(maybeRequestVote.Cast()));
} else
if (auto maybeAppendEntries = message.Maybe<TAppendEntriesRequest>())
{
OnAppendEntries(now, std::move(maybeAppendEntries.Cast()));
}
}To podejście projektowe poprawia wydajność i elastyczność obsługi wiadomości w implementacjach Raft.
Serwer Raft
Omówmy implementację serwera Raft. Serwer Raft skonfiguruje procedury dla interakcji sieciowych. Najpierw przyjrzymy się procedurom, które obsługują odczyt i zapis wiadomości. Prymitywy używane dla tych procedur zostały omówione w dalszej części artykułu, wraz z analizą biblioteki sieciowej. Procedura zapisu jest odpowiedzialna za zapisywanie wiadomości do gniazda, podczas gdy procedura odczytu jest nieco bardziej złożona. Aby odczytać, musi najpierw pobrać plik Type i Len zmienne, a następnie przydzielić tablicę Len bajtów, a na koniec odczytać resztę wiadomości. Struktura ta ułatwia wydajne i efektywne zarządzanie komunikacją sieciową w ramach serwera Raft.
template<typename TSocket>
TValueTask<void>
TMessageWriter<TSocket>::Write(TMessageHolder<TMessage> message) {
co_await TByteWriter(Socket).Write(message.Mes, message->Len);
auto payload = std::move(message.Payload);
for (uint32_t i = 0; i < message.PayloadSize; ++i) {
co_await Write(std::move(payload[i]));
}
co_return;
}
template<typename TSocket>
TValueTask<TMessageHolder<TMessage>> TMessageReader<TSocket>::Read() {
decltype(TMessage::Type) type; decltype(TMessage::Len) len;
auto s = co_await Socket.ReadSome(&type, sizeof(type));
if (s != sizeof(type)) { /* throw */ }
s = co_await Socket.ReadSome(&len, sizeof(len));
if (s != sizeof(len)) { /* throw */}
auto mes = NewHoldedMessage<TMessage>(type, len);
co_await TByteReader(Socket).Read(mes->Value, len - sizeof(TMessage));
auto maybeAppendEntries = mes.Maybe<TAppendEntriesRequest>();
if (maybeAppendEntries) {
auto appendEntries = maybeAppendEntries.Cast();
auto nentries = appendEntries->Nentries; mes.InitPayload(nentries);
for (uint32_t i = 0; i < nentries; i++) mes.Payload[i] = co_await Read();
}
co_return mes;
}Aby uruchomić serwer Raft, należy utworzyć instancję aplikacji RaftServer i wywołać klasę Serve metodę. The Serve uruchamia dwie procedury. The Idle jest odpowiedzialna za okresowe przetwarzanie timeoutów, podczas gdy InboundServe zarządza połączeniami przychodzącymi.
class TRaftServer {
public:
void Serve() {
Idle();
InboundServe();
}
private:
TVoidTask InboundServe();
TVoidTask InboundConnection(TSocket socket);
TVoidTask Idle();
}Połączenia przychodzące są odbierane za pośrednictwem połączenia akceptującego. Po tym następuje wywołanie InboundConnection coroutine, która odczytuje przychodzące wiadomości i przekazuje je do instancji Raft w celu przetworzenia. Taka konfiguracja zapewnia, że serwer Raft może skutecznie obsługiwać zarówno wewnętrzne timeouty, jak i komunikację zewnętrzną.
TVoidTask InboundServe() {
while (true) {
auto client = co_await Socket.Accept();
InboundConnection(std::move(client));
}
co_return;
}
TVoidTask InboundConnection(TSocket socket) {
while (true) {
auto mes = co_await TMessageReader(client->Sock()).Read();
Raft->Process(std::chrono::steady_clock::now(), std::move(mes),
client);
Raft->ProcessTimeout(std::chrono::steady_clock::now());
DrainNodes();
}
co_return;
}The Idle coroutine działa w następujący sposób: wywołuje funkcję ProcessTimeout co sekundę. Warto zauważyć, że ten coroutine używa asynchronicznego uśpienia. Ten projekt umożliwia serwerowi Raft efektywne zarządzanie operacjami wrażliwymi na czas bez blokowania innych procesów, poprawiając ogólną szybkość reakcji i wydajność serwera.
while (true) {
Raft->ProcessTimeout(std::chrono::steady_clock::now());
DrainNodes();
auto t1 = std::chrono::steady_clock::now();
if (t1 > t0 + dt) {
DebugPrint();
t0 = t1;
}
co_await Poller.Sleep(t1 + sleep);
}Coroutine został stworzony do wysyłania wiadomości wychodzących i został zaprojektowany tak, aby był prosty. Wielokrotnie wysyła wszystkie zgromadzone wiadomości do gniazda w pętli. W przypadku błędu, uruchamia kolejną procedurę coroutine, która jest odpowiedzialna za nawiązanie połączenia (za pośrednictwem funkcji connect function). Struktura ta zapewnia płynną i wydajną obsługę wiadomości wychodzących przy jednoczesnym zachowaniu niezawodności dzięki obsłudze błędów i zarządzaniu połączeniami.
try {
while (!Messages.empty()) {
auto tosend = std::move(Messages); Messages.clear();
for (auto&& m : tosend) {
co_await TMessageWriter(Socket).Write(std::move(m));
}
}
} catch (const std::exception& ex) {
Connect();
}
co_return;Dzięki zaimplementowanemu serwerowi Raft, przykłady te pokazują, jak coroutines znacznie upraszczają rozwój. Chociaż nie przyglądałem się implementacji Raft (proszę mi wierzyć, jest ona znacznie bardziej złożona niż Raft Server), ogólny algorytm jest nie tylko prosty, ale także kompaktowy.
Następnie przyjrzymy się kilku przykładom serwera Raft. Następnie opiszę bibliotekę sieciową, którą stworzyłem od podstaw specjalnie dla serwera Raft. Biblioteka ta ma kluczowe znaczenie dla umożliwienia wydajnej komunikacji sieciowej w ramach Raft.
Oto przykład uruchomienia klastra Raft z trzema węzłami. Każda instancja otrzymuje swój własny identyfikator jako argument, a także adresy i identyfikatory innych instancji. W tym przypadku klient komunikuje się wyłącznie z liderem. Wysyła losowe ciągi znaków, utrzymując określoną liczbę wiadomości w locie i czekając na ich zaangażowanie. Ta konfiguracja przedstawia interakcję między klientem a liderem w wielowęzłowym środowisku Raft, demonstrując obsługę rozproszonych danych i konsensusu przez algorytm.
$ ./server --id 1 --node 127.0.0.1:8001:1 --node 127.0.0.1:8002:2 --node 127.0.0.1:8003:3
...
Kandydat, Termin: 2, Index: 0, CommitIndex: 0,
...
Lider, Termin: 3, Indeks: 1080175, CommitIndex: 1080175, Delay: 2:0 3:0
MatchIndex: 2:1080175 3:1080175 NextIndex: 2:1080176 3:1080176
....
$ ./server --id 2 --node 127.0.0.1:8001:1 --node 127.0.0.1:8002:2 --node 127.0.0.1:8003:3
...
$ ./server --id 3 --node 127.0.0.1:8001:1 --node 127.0.0.1:8002:2 --node 127.0.0.1:8003:3
...
Follower, Term: 3, Index: 1080175, CommitIndex: 1080175,
...
$ dd if=/dev/urandom | base64 | pv -l | ./client --node 127.0.0.1:8001:1 >log1
198k 0:00:03 [159.2k/s] [ <=>I measured the commit latency for configurations of both 3-node and 5-node clusters. As expected, the latency is higher for the 5-node setup:
- 3 Nodes
- 50 percentile (median): 292,872 ns
- 80 percentile: 407,561 ns
- 90 percentile: 569,164 ns
- 99 percentile: 40,279,001 ns
-
5 Nodes
- 50 percentile (median): 425,194 ns
- 80 percentile: 672,541 ns
- 90 percentile: 1,027,669 ns
- 99 percentile: 38,578,749 ns
I/O Library
Let’s now look at the I/O library that I created from scratch and used in the Raft server’s implementation. I began with the example below, taken from cppreference.com, which is an implementation of an echo server:
task<> tcp_echo_server() {
char data[1024];
while (true) {
std::size_t n = co_await socket.async_read_some(buffer(data));
co_await async_write(socket, buffer(data, n));
}
}Pętla zdarzeń, prymityw gniazda i metody takie jak read_some/write_some (o nazwie ReadSome/WriteSome w mojej bibliotece) były wymagane dla mojej biblioteki, a także wrappery wyższego poziomu, takie jak async_write/async_read (o nazwie TByteReader/TByteWriter w mojej bibliotece).
Aby zaimplementować ReadSome metodę gniazda, musiałem utworzyć metodę Awaitable w następujący sposób:
auto ReadSome(char* buf, size_t size) {
struct TAwaitable {
bool await_ready() { return false; /* always suspend */ }
void await_suspend(std::coroutine_handle<> h) {
poller->AddRead(fd, h);
}
int await_resume() {
return read(fd, b, s);
}
TSelect* poller; int fd; char* b; size_t s;
};
return TAwaitable{Poller_,Fd_,buf,size};
}Kiedy co_await jest wywoływana, procedura coroutine zawiesza się, ponieważ await_ready zwraca false. W await_suspendmożemy uchwycić coroutine_handle i przekazujemy go wraz z uchwytem gniazda do pollera. Gdy gniazdo jest gotowe, poller wywołuje funkcję coroutine_handle w celu ponownego uruchomienia procedury. Po wznowieniu, await_resume która wykonuje odczyt i zwraca liczbę bajtów odczytanych do coroutine. The WriteSome, Accept, oraz Connect metody są wdrażane w podobny sposób.
Poller jest skonfigurowany w następujący sposób:
struct TEvent {
int Fd; int Type; // READ = 1, WRITE = 2;
std::coroutine_handle<> Handle;
};
class TSelect {
void Poll() {
for (const auto& ch : Events) { /* FD_SET(ReadFds); FD_SET(WriteFds);*/ }
pselect(Size, ReadFds, WriteFds, nullptr, ts, nullptr);
for (int k = 0; k < Size; ++k) {
if (FD_ISSET(k, WriteFds)) {
Events[k].Handle.resume();
}
// ...
}
}
std::vector<TEvent> Events;
// ...
};Przechowuję tablicę par (deskryptor gniazda, uchwyt coroutine), które są używane do inicjalizacji struktur dla backendu pollera (w tym przypadku select). Wznowienie jest wywoływane, gdy budzą się procedury odpowiadające gotowym gniazdom.
Jest to stosowane w głównej funkcji w następujący sposób:
TSimpleTask task(TSelect& poller) {
TSocket socket(0, poller);
char buffer[1024];
while (true) {
auto readSize = co_await socket.ReadSome(buffer, sizeof(buffer));
}
}
int main() {
TSelect poller;
task(poller);
while (true) { poller.Poll(); }
}Uruchamiamy korutynę (lub korutynę), która przechodzi w tryb uśpienia w dniu co_await, a sterowanie jest następnie przekazywane do nieskończonej pętli, która wywołuje mechanizm poller. Jeśli gniazdo stanie się gotowe w pollerze, odpowiednia procedura jest uruchamiana i wykonywana do następnego gniazda. co_await.
Aby odczytywać i zapisywać wiadomości Raft, musiałem stworzyć wysokopoziomowe wrappery nad ReadSome/WriteSome, podobne do:
TValueTask<T> Read() {
T res; size_t size = sizeof(T);
char* p = reinterpret_cast<char*>(&res);
while (size != 0) {
auto readSize = co_await Socket.ReadSome(p, size);
p += readSize;
size -= readSize;
}
co_return res;
}
// usage
T t = co_await Read<T>();Aby je zaimplementować, musiałem stworzyć coroutine, który działa również jako Awaitable. Coroutine składa się z pary: coroutine_handle i promise. The coroutine_handle służy do zarządzania coroutine z zewnątrz, podczas gdy promise służy do zarządzania wewnętrznego. The coroutine_handle może zawierać Awaitable metody, które umożliwiają oczekiwanie na wynik coroutine za pomocą co_await. The promise można wykorzystać do przechowywania wyniku zwróconego przez co_return i do wybudzenia wywołującej go procedury.
W coroutine_handle, w ramach await_suspend przechowujemy metodę coroutine_handle wywołującej procedury. Jego wartość zostanie zapisana w pliku promise:
template<typename T>
struct TValueTask : std::coroutine_handle<> {
bool await_ready() { return !!this->promise().Value; }
void await_suspend(std::coroutine_handle<> caller) {
this->promise().Caller = caller;
}
T await_resume() { return *this->promise().Value; }
using promise_type = TValuePromise<T>;
};W ramach promise sam return_value będzie przechowywać zwróconą wartość. Coroutine wywołujący jest budzony za pomocą awaitable, które jest zwracane w final_suspend. Dzieje się tak, ponieważ kompilator po co_returnwywołuje co_await na final_suspend.
template<typename T>
struct TValuePromise {
void return_value(const T& t) { Value = t; }
std::suspend_never initial_suspend() { return {}; }
// resume Caller here
TFinalSuspendContinuation<T> final_suspend() noexcept;
std::optional<T> Value;
std::coroutine_handle<> Caller = std::noop_coroutine();
};W await_suspendwywoływana procedura może zostać zwrócona i zostanie automatycznie wybudzona. Proszę zauważyć, że wywołana procedura będzie teraz w stanie uśpienia, a jej funkcja coroutine_handle musi zostać zniszczona za pomocą funkcji destroy, aby uniknąć wycieku pamięci. Można to osiągnąć na przykład w destruktorze funkcji TValueTask.
template<typename T>
struct TFinalSuspendContinuation {
bool await_ready() noexcept { return false; }
std::coroutine_handle<> await_suspend(
std::coroutine_handle<TValuePromise<T>> h) noexcept
{
return h.promise().Caller;
}
void await_resume() noexcept { }
};Po ukończeniu opisu biblioteki, przeniosłem do niej benchmark libevent, aby zapewnić jej wydajność. Ten benchmark generuje łańcuch N uniksowych potoków, z których każdy jest połączony z następnym. Następnie inicjuje on 100 operacji zapisu do łańcucha, które są kontynuowane aż do uzyskania 1000 wszystkich wywołań zapisu. Poniższy obrazek przedstawia czas działania benchmarku jako funkcję N dla różnych backendów mojej biblioteki (coroio) w porównaniu do libevent. Ten test pokazuje, że moja biblioteka działa podobnie do libevent, potwierdzając jej wydajność i skuteczność w zarządzaniu operacjami wejścia/wyjścia.

Wnioski
Podsumowując, w tym artykule opisano implementację serwera Raft przy użyciu procedur C++20, podkreślając wygodę i wydajność zapewnianą przez tę nowoczesną funkcję C++. Niestandardowa biblioteka I/O, która została napisana od podstaw, ma kluczowe znaczenie dla tej implementacji, ponieważ skutecznie obsługuje asynchroniczne operacje I/O. Wydajność biblioteki została zweryfikowana w porównaniu z benchmarkiem libevent, demonstrując jej kompetencje.
Dla tych, którzy chcieliby dowiedzieć się więcej o tych narzędziach lub z nich skorzystać, biblioteka I/O jest dostępna pod adresem coroio, a biblioteka Raft pod adresem miniraft-cpp (link na początku artykułu). Oba repozytoria zapewniają szczegółowe spojrzenie na to, jak można wykorzystać koroutyny C++20 do tworzenia solidnych, wysokowydajnych systemów rozproszonych.