
Chcę podzielić się tutaj czymś szczerym: kiedy początkowo rozmawiałem z zespołami danych o liniowości, ośmiu na dziesięciu pytało mnie: “Dlaczego nie mielibyśmy wyświetlać wszystkich połączeń, które mają w swojej hurtowni danych na jednym ekranie?”. Szczerze mówiąc, zawsze mnie to dezorientowało, ponieważ nie rozumiałem, jaki problem próbują w ten sposób rozwiązać. Prawdopodobnie będzie to wyglądało jak kilka niepołączonych ze sobą węzłów lub, co bardziej prawdopodobne, bałagan, który nałożyłby się na nasz backend…
To również skłoniło mnie do refleksji nad uwagą Henry’ego Forda o szybszych koniach, uświadamiając mi, że cytat ten jest tak samo prawdziwy teraz, jak w przeszłości.
Kiedy tworzyliśmy interfejs użytkownika dla Masthead, nie mogliśmy nie zauważyć niepokojącego trendu: Produkty danych B2B wydają się zasadniczo ignorować doświadczenia użytkowników końcowych. Chodzi mi o to, że w naszej niszy to nie inżynierowie danych – którzy faktycznie wchodzą w interakcję z naszymi produktami – podejmują decyzje zakupowe. Zamiast tego są to dyrektorzy ds. danych lub wiceprezesi ds. danych, których oczy częściej skierowane są na zestawienia P&L i arkusze kalkulacyjne. Doświadczenie użytkownika nie jest dla nich priorytetem przy podejmowaniu decyzji o zakupie rozwiązania. Pomimo tej rzeczywistości, pozostaliśmy nieugięci w naszej odmowie poświęcenia jakości UX i UI dla użytkowników końcowych.
Wyzwanie polega na tym, że linia danych jest co najmniej bardzo specyficzną bestią. Proszę mnie posłuchać; jeśli myślimy o produktach mniej abstrakcyjnych niż dane, na przykład o usługach dostarczania jedzenia, handlu elektronicznym, edukacji, a nawet fintechach, z tych produktów korzystają wszyscy projektanci. Powiedzmy, że znają je i rozumieją zadanie do wykonania znacznie łatwiej niż praca z przepływami danych, ETL, zestawami danych, widokami czy czymkolwiek innym. Tak więc, nawet jeśli projektant nie może zrozumieć produktu, prawdopodobnie zostanie wysłany do pracy w dziale wsparcia, aby napiąć swoje mięśnie emocjonalne i lepiej zrozumieć użytkownika końcowego i zadanie do wykonania (JTBD), podczas gdy nie jest to coś, co może zrobić natychmiast z linią danych i zadaniami inżynierii danych.
W naszym przypadku Nastiia, nasza projektantka, poruszała się po koncepcjach, które były dla niej dość abstrakcyjne. To było jak próba wyjaśnienia złożonych pomysłów babci. Wyzwanie nie leży wyłącznie po stronie słuchacza; chodzi również o jasność i wysiłek osób wyjaśniających. Aby umieścić to w kontekście, założyciele mają głęboką wiedzę techniczną, spędzając całą swoją karierę w danych, podczas gdy Nastiia – nasz projektant produktu, została niedawno wprowadzona w ekscytujący i błyszczący świat ETL, zadań, zapytań, kolumn, przebiegów i tak dalej. Zasadniczo wymagało to od nas wszystkich znacznego wysiłku, aby wypełnić tę lukę i naprawdę zrozumieć się nawzajem.
To, co okazało się dla nas skuteczne, to opracowanie wspólnej metafory, która jest wystarczająco bliska, aby połączyć zrozumienie wszystkich. Ponadto wszyscy założyliśmy, że to zadanie zostało już gdzieś rozwiązane, niekoniecznie w danych. Nie jesteśmy pierwszymi, którzy próbują mapować trudne, unikalne i rozproszone jednostki na dużą skalę.
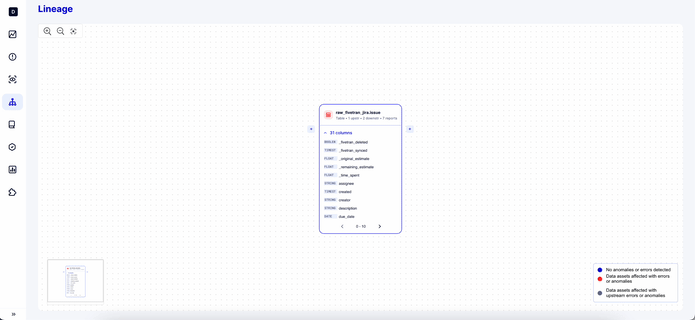
Dla nas rozwiązaniem było postrzeganie linii danych jako mapy świata, a dokładniej Google Maps. Dążyliśmy do stworzenia narzędzia, które mogłoby rozwiązywać problemy związane z wyszukiwaniem w różnych skalach. Szukaliśmy rozwiązania, które zmienia kontekst i łatwo przybliża i oddala, w naszym przypadku całkiem dosłownie. Od samego początku było dla nas jasne, że można wyszukiwać wszystko na podstawie danych, podobnie jak w Google Maps. Nie oznacza to jednak, że można zobaczyć wszystko naraz; na przykład nie można zobaczyć konkretnej ulicy na poziomie świata lub kraju; trzeba szukać w określonym kontekście, takim jak miasto. Oznacza to również, że narzędzie musi być wystarczająco elastyczne, aby obsługiwać różne konteksty.
Poruszanie się po przepływie danych przypomina kreślenie podróży na Mapach Google z punktu A do B, a następnie do C. Śledzenie ścieżki określonej kolumny z jednej tabeli do widoku, a na koniec do miejsca docelowego na pulpicie nawigacyjnym, wymaga precyzyjnego kontekstu, podobnie jak nie można oczekiwać nawigacji po szczegółach ulicy w skali kontynentu w Mapach Google.
Ponadto ważne jest to, że lineage zawiera mnóstwo informacji (tabele upstream, downstream, dashboardy, czy jest to tabela, widok czy duża tabela, liczba kolumn i lista jest długa). Naprawdę łatwo jest podążać za chęcią dostarczenia jak największej ilości informacji, ale wiele informacji w rzeczywistości osłabia uwagę użytkownika i często skutkuje nieudanym JTBD (Job To Be Done), gdzie nie pomagamy inżynierom danych, ale bombardujemy ich setkami nowych punktów danych, o które nie prosili. Zrównoważenie tego na linii produkcyjnej było dla nas wyzwaniem, zwłaszcza biorąc pod uwagę fakt, że każda tabela może mieć swój własny unikalny upstream i każdy lineage może przerodzić się w nieskończoność zadań i tabel na ekranie, których tak naprawdę nikt nie potrzebuje, zamiast zrozumieć konkretny przepływ danych.
Mieliśmy szczęście, ponieważ Nastiia szybko zrozumiała, że zrozumienie podstaw danych jest kluczowe dla rozwijania empatii dla naszych użytkowników. Jesteśmy przekonani, że możemy stworzyć coś naprawdę wartościowego tylko wtedy, gdy jest to kochane przez naszych użytkowników. To przekonanie napędza nas do wspierania wspólnego zrozumienia w naszym zespole, jednocześnie szukając inspiracji z najlepszych praktyk zaobserwowanych w produktach takich jak Intercom, Mixpaneli Dropbox. Produkty te pokazały nam, że złożone i nieintuicyjne zadania mogą być dostępne i przyjazne dla użytkownika. Służą one jako przypomnienie, że dążenie do eleganckiego interfejsu użytkownika nie powinno odbywać się kosztem doświadczenia użytkownika, ale raczej powinno skutecznie zaspokajać jego potrzeby.