
Patrząc na dwie poniższe tabele, który format uważa Pan/Pani za bardziej intuicyjny i łatwiejszy do odczytania?
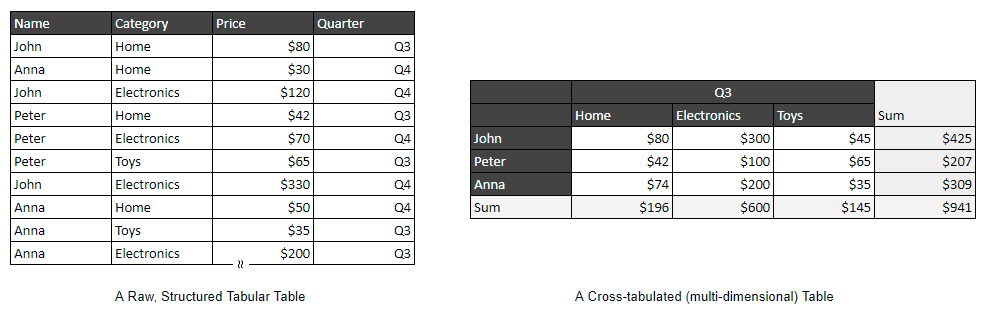
Od lat ludzie używają arkuszy kalkulacyjnych do tworzenia tabel krzyżowych (lub warunkowe, wielowymiarowe) raporty lub formularze wypełnienia. Raporty te starannie organizują kategorie, daty i inne punkty danych w poziomy wierszy i kolumn, dzięki czemu są łatwe do odczytania i analizy.
Jednak każdy raport przedstawia tylko jeden punkt widzenia danych bazowych, takich jak całkowity przychód ze sprzedaży każdego sprzedawcy w każdym kwartale roku. Aby pokazać inny punkt widzenia zebranych danych (np. średni przychód ze sprzedaży w każdym kwartale dla każdego sprzedawcy w roku 2023), musimy następnie utworzyć nowy raport lub ponownie wypełnić formularz od podstaw za pomocą oprogramowania arkusza kalkulacyjnego, co jest żmudne i podatne na błędy.
Rozwiązanie w postaci tabeli przestawnej
Aby zaradzić ograniczeniom statycznych raportów z tabelami krzyżowymi, inżynier oprogramowania Pito Salas wprowadził koncepcję tabeli przestawnej w 1989 roku w Lotus Improv. Tabele przestawne pozwalają użytkownikom na dynamiczną restrukturyzację danych, umożliwiając im łatwe przeglądanie raportów pod różnymi kątami.
Wymagania wstępne dla tabel przestawnych
Korzystanie z tabel przestawnych wymaga jednak dobrze ustrukturyzowanego modelu danych źródłowych w stylu tabelarycznym, co może stanowić wyzwanie dla zwykłych użytkowników. W przeciwieństwie do tworzenia raportów z tabelami krzyżowymi, projektowanie takiego modelu danych wymaga szkolenia inżynierskiego i może być czasochłonne i złożone.
Odchylanie tabeli z tabelą krzyżową
Aby uwolnić pełny potencjał danych z tabel krzyżowych, potrzebujemy sposobu na szybką analizę istniejących raportów z tabelami krzyżowymi i przekształcenie ich w ustrukturyzowane tabele. modele danych do dalszej analizy. Proces ten, znany jako “unpivoting”, obejmuje podział tabeli krzyżowej na różne części, a następnie ich reorganizację do ustrukturyzowanego formatu.
Identyfikując i organizując etykiety boczne, etykiety górne i liczby, możemy stworzyć ustrukturyzowany model danych w stylu tabelarycznym, który reprezentuje oryginalną tabelę krzyżową w bardziej elastycznym formacie.
Przykład przekształcenia krok po kroku
Proszę wziąć pod uwagę prosty przykład: wykonany w arkuszu kalkulacyjnym ad hoc raport z tabelą krzyżową dla wyników uczniów wygląda następująco.
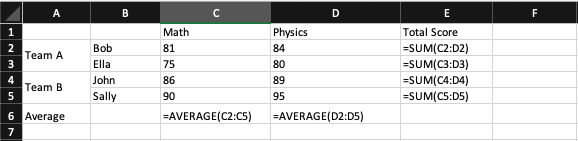
Przy podziale uczniów na dwa zespoły w kolumnach po lewej stronie i przedmiotach w górnym wierszu, środkowy obszar macierzy krzyżowej to odpowiednie wyniki z przedmiotu dla każdego ucznia. W kolumnach po prawej stronie (kolumna E) znajdują się wzory na łączny wynik każdego ucznia. W dolnym wierszu (wiersz 6) znajduje się wzór na średni wynik dla wszystkich uczniów dla każdego przedmiotu.
Aby przekonwertować powyższy prostoliniowy raport tabeli krzyżowej na odpowiedni ustrukturyzowany model danych źródłowych w stylu tabelarycznym, musimy najpierw podzielić tabelę krzyżową na trzy części, tj. etykiety boczne, etykiety górne i liczby.
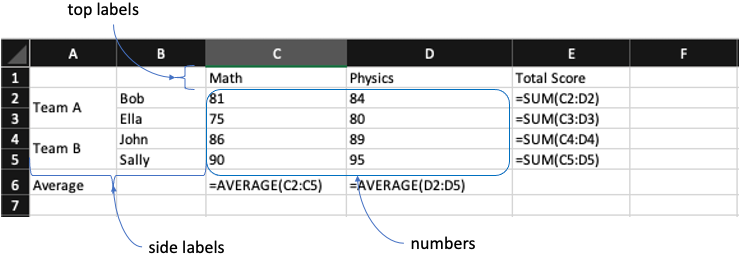
Każdy poziom etykiet bocznych i etykiet górnych odpowiada polu w rozwiązanym ustrukturyzowanym modelu danych w stylu tabelarycznym. Sama liczba jest również polem ustrukturyzowanego modelu danych w stylu tabelarycznym.
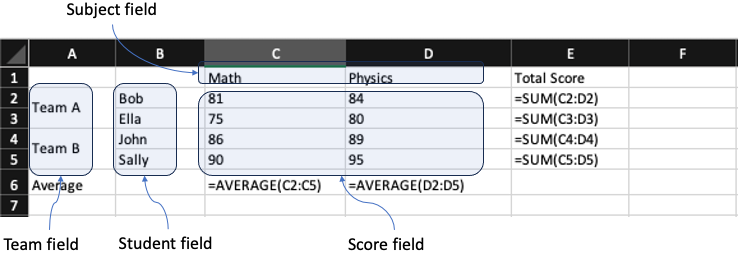
W powyższej przykładowej tabeli krzyżowej znajduje się pole “Zespół” (kolumna A) dla “Zespołu A” i “Zespołu B”, pole “Uczeń” (kolumna B) dla “Boba”, “Elli”, “Johna” i “Sally”, pole “Przedmiot” (wiersz 1) dla “Matematyki” i “Fizyki” oraz pole “Wynik” (obszar C2:D5) dla każdej odpowiedniej liczby dla każdego powiązanego ucznia i przedmiotu; jak pokazano w poniższym rozwiązanym modelu danych w stylu tabelarycznym:
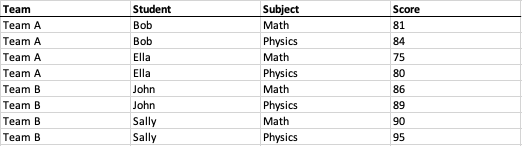
Proszę zauważyć, że każdy numer jest jednoznacznie powiązany z kombinacją etykiet bocznych i górnych, więc najważniejsze jest, aby najpierw zidentyfikować obszar numeru. Tak długo, jak identyfikujemy obszar liczbowy, obszary etykiet bocznych (po lewej stronie obszaru liczbowego) i obszary etykiet górnych (u góry obszaru liczbowego) są łatwe do zidentyfikowania.
Identyfikacja obszaru numerycznego
Aby zidentyfikować obszar liczbowy, najbardziej bezpośrednim sposobem jest przeskanowanie raportów wiersz po wierszu i wybranie komórek z liczbami, a następnie połączenie takich komórek w obszary. Tak jak w przykładzie, możemy od razu wiedzieć, że obszar liczbowy to C2:D5. Jednak w przypadku złożonych raportów mogą występować inne liczby rozproszone, co utrudnia identyfikację rzeczywistego obszaru liczbowego.
Innym sposobem jest wykorzystanie informacji dostarczanych przez formuły podsumowujące. Ludzie piszą formuły agregujące w raportach, takie jak SUMA lub ŚREDNIA, aby podsumować rzeczywiste liczby będące przedmiotem zainteresowania, a my możemy wykorzystać takie informacje do zlokalizowania obszaru liczb. W przykładowym raporcie z tabelą krzyżową, w kolumnie E, widzieliśmy cztery formuły SUM, które odnoszą się do C2:D2, C3:D3, C4:D4 i C5:D5, które łączą się w C2:D5, pomagając nam zidentyfikować obszar liczbowy. W wierszu 6 widzieliśmy dwie formuły ŚREDNIA, które odwołują się do C2: C5 i D2: D5, które łączą się w C2: D5, co pozwala nam ponownie zidentyfikować obszar liczbowy.
Identyfikacja obszaru etykiety
Po uzyskaniu obszaru liczbowego, wystarczy skanować kolumna po kolumnie od lewej granicy obszaru liczbowego, aż do braku kolumny lub pustej kolumny, aby znaleźć boczne etykiety; skanować wiersz po wierszu od górnej granicy obszaru liczbowego, aż do braku wiersza lub pustego wiersza, aby znaleźć górne etykiety.
Radzenie sobie z etykietami wielopoziomowymi
Etykiety boczne i/lub górne mogą mieć wiele poziomów. Każda z nich naturalnie tworzy drzewo grup od wyższego poziomu do niższego. Każdy poziom jest polem dla rozwiązanego modelu danych w stylu tabelarycznym. Na przykład etykiety boczne w przykładzie tworzą drzewo grup w następujący sposób:
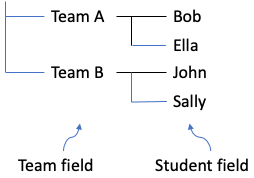
A etykiety górne (z tylko jednym poziomem w przykładzie) tworzą drzewo grup, jak poniżej:

Następnie łączymy i rozwijamy dwa drzewa w jedno drzewo główne i dołączyć odpowiedni numer do ścieżki każdej kombinacji etykiet bocznych i etykiet górnych, jak pokazano poniżej:
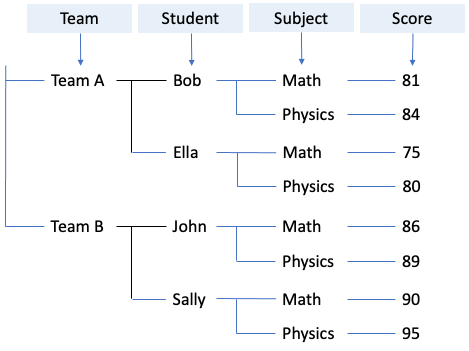
Proszę zauważyć, że każdy poziom drzewa jest powiązany z polem w rozwiązanym modelu danych w stylu tabelarycznym. Teraz po prostu przechodzimy przez drzewo od korzenia do liścia i wypełniamy wartość w każdym powiązanym polu:
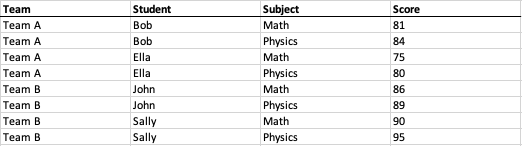
W tym momencie przekształciliśmy tabelę krzyżową w surowy, ustrukturyzowany format tabelaryczny.
Cieszę się, że mogę podzielić się tym artykułem, ponieważ badałem różne techniki analizy danych dla mojego projektu, ottava.io. Niedawno wdrożyliśmy tę technikę unpivoting, która moim zdaniem może być pomocna również dla innych deweloperów.
Włączając tę metodę do naszej platformy, ottava.io ma na celu uproszczenie analizę danych i manipulowania nimi, eliminując potrzebę ręcznego przygotowywania danych lub polegania na zaawansowanych narzędziach, takich jak Power Query lub Python Pandas. Naszym celem jest usprawnienie tego procesu i umożliwienie użytkownikom zagłębiania się w ich dane w celu odkrycia cennych spostrzeżeń. Państwa opinie i uwagi na temat tego podejścia są mile widziane.