
W miarę jak świat przyjmuje wielowarstwowe podejście do przechowywania danych, następuje zmiana w sposobie, w jaki organizacje przekształcają dane. Zmusiło to firmy do integracji wyodrębniania, ładowania i przekształcania (ELT) z architekturą Medallion. Trend ten zmienia sposób, w jaki dane są pozyskiwane i przekształcane w różnych liniach biznesowych, a także przez użytkowników departamentalnych, analityków danych i kadrę kierowniczą wyższego szczebla. Stosowanie sztywnych reguł transformacji danych i udostępnianie danych Państwa zespołom za pośrednictwem hurtownię danych może nie w pełni zaspokoić zmieniające się i eksploracyjne potrzeby Państwa firmy w zakresie integracji danych.
W zależności od ilości danych wytwarzanych przez Państwa organizację i tempa ich generowania, przetwarzanie danych bez znajomości wzorców konsumpcji może okazać się kosztowne. Transformacja danych w oparciu o przypadki może być bardziej opłacalna ekonomicznie, ponieważ każdego dnia pojawia się więcej zapytań i analiz ad-hoc. Nie oznacza to, że przechowują Państwo dane w postaci nieprzetworzonej. Zamiast tego konieczne jest dodanie kilku warstw transformacji, wzbogacania i reguł biznesowych w celu optymalizacji kosztów i wydajności.
Jak wymagania biznesowe kształtują technologie baz danych
Przyjrzyjmy się, jak ewoluowało zarządzanie danymi. Zaczęliśmy od hurtowni danych w chmurze. Tradycyjne hurtownie danych, takie jak te oparte na relacyjnych systemach baz danych, od lat stanowią podstawę zarządzania danymi w przedsiębiorstwach. Są one zoptymalizowane pod kątem danych strukturalnych i zazwyczaj wykorzystywane do analizy biznesowej i raportowania.
Następnie wkroczyliśmy w erę jezior danych. Jeziora danych stały się popularne do obsługi dużych ilości ustrukturyzowanych i nieustrukturyzowanych danych. Oferują one elastyczność w przechowywaniu i przetwarzaniu danych, umożliwiając organizacjom przechowywanie surowych i różnorodnych danych w ich natywnym formacie.
Teraz, mamy hurtownie danych. Koncepcja data lakehouse pojawiła się jako odpowiedź na niektóre wyzwania związane z jeziorami danych, takie jak jakość danych, zarządzanie danymi i potrzeba możliwości transakcyjnych. Architektura data lakehouse ma na celu połączenie najlepszych cech jezior danych i hurtowni danych, łącząc skalowalność i elastyczność jezior danych z niezawodnością i wydajnością hurtowni danych. Technologie takie jak Delta Lake i Apache Iceberg przyczyniły się do rozwoju koncepcji data lakehouse poprzez dodanie możliwości transakcyjnych i egzekwowania schematów do jezior danych.
Aby w pełni wykorzystać potencjał tej rozwijającej się architektury, zalecamy wdrożenie najlepszych praktyk, z których jedną jest architektura medalionowa.
Czym jest architektura medalionowa?
Architektura medalionowa zyskuje na popularności w świecie danych. W przeciwieństwie do tradycyjnych architektur jezior danych, w których surowe lub nieustrukturyzowane dane są przechowywane bez żadnego egzekwowania schematu lub silnych gwarancji spójności, architektura medalionowa wprowadza strukturę i organizację do Państwa danych. Umożliwia ona dodanie możliwości ewolucji schematu do zbiorów danych przechowywanych w Delta Lake, ułatwiając efektywne wyszukiwanie i analizowanie danych.
Jednym z powodów, dla których architektura medalionowa zyskuje na popularności, jest jej zdolność do obsługi dużych ilości różnorodnych typów danych w skalowalny sposób. Wykorzystując możliwości transakcyjne Delta Lake, mogą Państwo zapewnić Atomowość, spójność, niezależność i trwałość (ACID) dla Państwa operacji na ogromnych zbiorach danych.
Czym jednak różnią się one od tradycyjnych architektur data lake? Podczas gdy oba podejścia przechowują surowe lub nieustrukturyzowane dane, architektura medalionu wprowadza systematyczną metodę definiowania brązowych, srebrnych i złotych warstw w ramach jeziora danych. Pozwala to inżynierom danych na wyselekcjonowanie odpowiednich danych dla właściwych odbiorców. Ułatwia to również użytkownikom wyszukiwanie i analizowanie ich zbiorów danych bez poświęcania wydajności lub niezawodności.
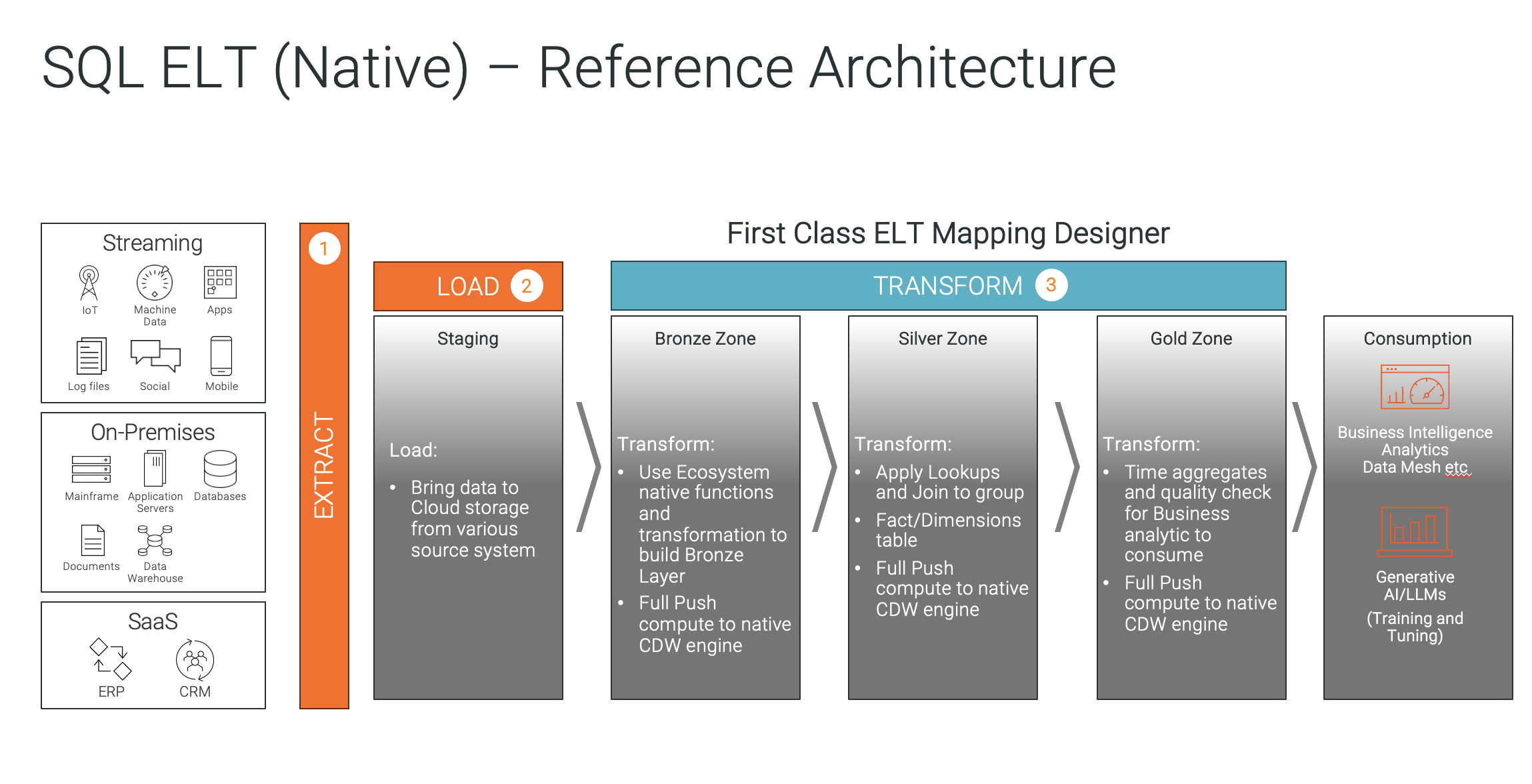
Przedstawia architekturę referencyjną SQL ELT (natywną).
Właśnie dlatego architektura medalionowa zyskuje na popularności w dziedzinie Delta Lake i hurtowni danych w chmurze. Oferuje ona potężne połączenie skalowalności, niezawodności, wydajności i uporządkowanej pamięci masowej dla Państwa cennych zbiorów danych. Przeanalizujmy teraz, w jaki sposób przetwarzanie danych musi się zmieniać wraz ze zmianami w architekturze.
Dlaczego ELT jest właściwym procesem transformacji danych dla architektury Medallion?
Zgodnie z definicją, w architekturze danych Medallion istnieje kilka warstw. Dane są stopniowo przetwarzane i udoskonalane w miarę przechodzenia przez te warstwy. Korzystanie z tradycyjnego wyodrębniania, przekształcania i ładowania (ETL) może być nieefektywne, ponieważ często wymaga przenoszenia danych z hurtowni danych lub jeziora dla każdej transformacji, która jest potrzebna do następnego poziomu przetwarzania.
Zamiast tego, bardziej efektywnym podejściem jest wykorzystanie technologii pushdown, w której kod jest wypychany do celu/źródła, umożliwiając przetwarzanie danych tam, gdzie się znajdują. W tym przypadku przenoszony jest tylko kod transformacji danych, a nie same dane. ELT dodatkowo usprawnia ten proces, umożliwiając przekształcanie danych dowolną liczbę razy, dzięki czemu system jest bardziej wydajny. Dzięki ELT zmniejszają Państwo obciążenie systemu źródłowego, ponieważ dane są wprowadzane tylko raz do jeziora danych / magazynu danych.
Optymalna konstrukcja ELT zapewnia kilka przewag konkurencyjnych. Umożliwia szybsze przetwarzanie dużych ilości danych, przyspieszając analizę i podejmowanie decyzji. Zmniejsza również koszty operacyjne, minimalizując niepotrzebny przepływ danych między sieciami i systemami.
Niezbędne możliwości integracji danych do uruchomienia ELT w architekturze danych Medallion
Kilka konkretnych możliwości integracji danych umożliwi Państwu pomyślne uruchomienie ELT w architekturze danych Medallion. Obejmują one:
- Przetwarzanie równoległe na dużą skalę: Jest to niezbędna technologia, która uruchamia kod ELT na wielu maszynach w tym samym czasie, co może poprawić wydajność zadań związanych z danymi. Silnik przetwarzania, taki jak Spark, może obsługiwać ogromne zbiory danych poprzez skalowanie do większych klastrów i dodawanie większej liczby węzłów. Harmonogram dystrybuuje zadania do węzłów roboczych, równoważąc obciążenie pracą i maksymalizując wykorzystanie zasobów.
- Wzorce ładowania danych: Proszę upewnić się, że narzędzie nie opiera się wyłącznie na ładowaniu wsadowym, ale obsługuje również strumieniowanie w czasie rzeczywistym oraz ładowanie pełne i przyrostowe. Przechwytywanie danych zmian (CDC) i dryf schematu są najczęściej używanymi funkcjami podczas przesyłania danych ze źródeł do hurtowni danych.
- Zoptymalizowane przetwarzanie danych na każdym etapie: Architektura Medallion to system logicznej organizacji danych w ramach data lakehouse. Każda warstwa w architekturze Medallion służy innemu celowi, a transformacje są stosowane z uwzględnieniem granic bezpieczeństwa, zasad przechowywania, zasad dostępu użytkowników, wymaganych opóźnień i poziomu wpływu biznesowego. Powinni Państwo być w stanie przetwarzać dane na poziomie granularnym, optymalizując je pod kątem kolejnego etapu logicznego przetwarzania danych.
- Podgląd kodu podczas projektowania: Ta funkcja pozwala zobaczyć wyniki kodu ELT przed jego uruchomieniem, co może pomóc w wychwyceniu błędów i upewnieniu się, że kod robi to, co chcesz.
- Obsługa wielu chmur: Proszę nie ograniczać możliwości integracji do jednego konkretnego ekosystemu. Należy upewnić się, że można uruchamiać zadania potoku danych w wielu środowiskach chmurowych, takich jak Snowflake, Databricks, Amazon Web Services (AWS), Microsoft Azure i Google Cloud.
- Automatyczne dostrajanie: Umożliwia to narzędziu ELT automatyczne dostosowywanie ustawień zadań w celu poprawy ich wydajności. Narzędzie powinno obsługiwać sztuczną inteligencję w celu gromadzenia statystyk uruchomieniowych i dostosowywania strategii wykonania w oparciu o charakterystykę danych.
- Elastyczna transformacja: Narzędzia ELT muszą umożliwiać elastyczną logikę transformacji, ponieważ transformacje mogą być wykonywane przy użyciu szerszego zakresu narzędzi i technik, w tym SQL, Python i Spark. Może to być przydatne, jeśli trzeba wykonać złożone transformacje nieobsługiwane przez SQL.
- Łączenie kodu SQL z kodem zastrzeżonym: Umożliwia to użycie zarówno kodu SQL, jak i kodu zastrzeżonego w pojedynczym potoku ELT. Może to być przydatne, jeśli trzeba wykonać zadania nieobsługiwane przez SQL. Na przykład można użyć SQL do zapytania bazy danych i pobrania danych, a następnie napisać funkcję Python, aby zaimplementować kontrolę jakości danych, stosując niestandardową logikę w celu zidentyfikowania i rozwiązania wszelkich problemów z danymi.
- Kompleksowy przepływ pracy: Ta funkcja zapewnia wizualny interfejs, który umożliwia projektowanie i wykonywanie zadań ELT w ramach kompletnego przepływu zadań. Narzędzie powinno umożliwiać planowanie i orkiestrację zestawu zadań, począwszy od wyodrębniania danych do wyzwalania dalszych zadań, zarządzania zależnościami i umożliwienia obserwacji danych.
- Bezpieczeństwo, kontrola dostępu i możliwości maskowania: Pozwala to kontrolować, kto ma dostęp do Państwa danych i maskować dane wrażliwe. Jest to ważne dla ochrony Państwa danych przed nieautoryzowanym dostępem.
- Możliwość wdrożenia DataOps: Daje to Państwu możliwość integracji procesów ETL z procesami DevOps. Może to pomóc w poprawie jakości i niezawodności danych.
- Łatwe przełączanie między ETL i ELT: Ułatwia to przełączanie między przetwarzaniem ETL i ELT. Może to być przydatne w przypadku konieczności zmiany strategii przetwarzania danych.
- Transformacja danych jako kod: Umożliwia to przechowywanie kodu ETL w repozytorium, co ułatwia zarządzanie i wersjonowanie kodu.
- Zaawansowana transformacja: Gdy ELT staje się głównym sposobem przetwarzania danych, należy upewnić się, że nie trzeba korzystać z różnych narzędzi do złożonych transformacji.
- Jakość danych: Daje to Państwu możliwość identyfikowania i rozwiązywania problemów związanych z jakością danych na wczesnym etapie procesu ELT. Może to pomóc w poprawie jakości danych.
- Integracja z linią danych i zarządzaniem: Ta funkcja umożliwia śledzenie pochodzenia i przekształceń danych. Może to pomóc w zapewnieniu zgodności danych z zasadami zarządzania danymi. Narzędzie ELT powinno płynnie integrować się z Państwa strukturą zarządzania danymi, aby zachować identyfikowalność, spójność i bezpieczeństwo danych. Powinno zapewniać wgląd w pochodzenie, transformacje i miejsca docelowe danych, umożliwiając skuteczny audyt danych i zgodność z zasadami zarządzania danymi.
Kolejne kroki
Kluczowe dla Państwa firmy jest wybranie narzędzia ELT, które jest wydajne i kompatybilne z architekturą danych Medallion. Zwiększy to możliwości integracji danych, umożliwiając pełne wykorzystanie ustrukturyzowanego, warstwowego podejścia architektury Medallion. Takie dostosowanie zapewni Państwa firmie przewagę konkurencyjną dzięki wydajnej obsłudze dużych ilości danych, poprawie skalowalności, usprawnieniu procesów przepływu pracy i osiągnięciu efektywności kosztowej.