
MongoDB jest jedną z najbardziej niezawodnych i solidnych baz danych zorientowanych na dokumenty. Bazy danych NoSQL. Umożliwia ona deweloperom dostarczanie bogatych w funkcje aplikacji i usług z różnymi nowoczesnymi wbudowanymi funkcjami, takimi jak uczenie maszynowe, przesyłanie strumieniowe, wyszukiwanie pełnotekstowe itp. Choć nie jest to klasyczna relacyjna baza danych, MongoDB jest jednak wykorzystywana przez wiele różnych sektorów biznesowych, a jej przypadki użycia obejmują wszystkie rodzaje scenariuszy architektonicznych i typów danych.
Bazy danych zorientowane na dokumenty z natury różnią się od tradycyjnych relacyjnych baz danych, w których dane są przechowywane w tabelach, a pojedynczy podmiot może być rozproszony w kilku takich tabelach. W przeciwieństwie do nich, dokumentowe bazy danych przechowują dane w oddzielnych, niepowiązanych ze sobą tabelach. zbiorach, co eliminuje wewnętrzną ciężkość modelu relacyjnego. Biorąc jednak pod uwagę, że modele domen świata rzeczywistego nigdy nie są tak uproszczone, aby składały się z niepowiązanych oddzielnych bytów, dokumentowe bazy danych (w tym MongoDB) zapewniają kilka sposobów definiowania połączeń wielu kolekcji podobnych do klasycznych relacji baz danych, ale znacznie lżejszych, bardziej ekonomicznych i wydajniejszych.
Quarkus, “naddźwiękowy i subatomowy” Java jest nowym dzieckiem na rynku, które najbardziej modni i wpływowi deweloperzy desperacko chwytają i o które walczą. Jego nowoczesne funkcje natywne dla chmury, a także jego pomysłowość (zgodna z najlepszymi w swojej klasie standardowymi bibliotekami), wraz z możliwością tworzenia natywnych plików wykonywalnych, od kilku lat uwodzą programistów Java, architektów, inżynierów i projektantów oprogramowania.
Nie możemy tutaj wchodzić w dalsze szczegóły ani MongoDB, ani Quarkus: czytelnik zainteresowany dowiedzeniem się więcej jest proszony o zapoznanie się z dokumentacją na oficjalnej stronie stronie MongoDB lub Strona internetowa Quarkus. To, co staramy się tutaj osiągnąć, to zaimplementowanie stosunkowo złożonego przypadku użycia polegającego na CRUDing a customer-order-product przy użyciu Quarkus i jego rozszerzenia MongoDB. Starając się zapewnić rozwiązanie inspirowane światem rzeczywistym, staramy się unikać uproszczonych i karykaturalnych przykładów opartych na modelu jednego podmiotu z zerową liczbą połączeń (obecnie są ich dziesiątki).
A więc zaczynamy!
Model domeny
Poniższy diagram przedstawia nasz customer-order-product model domeny: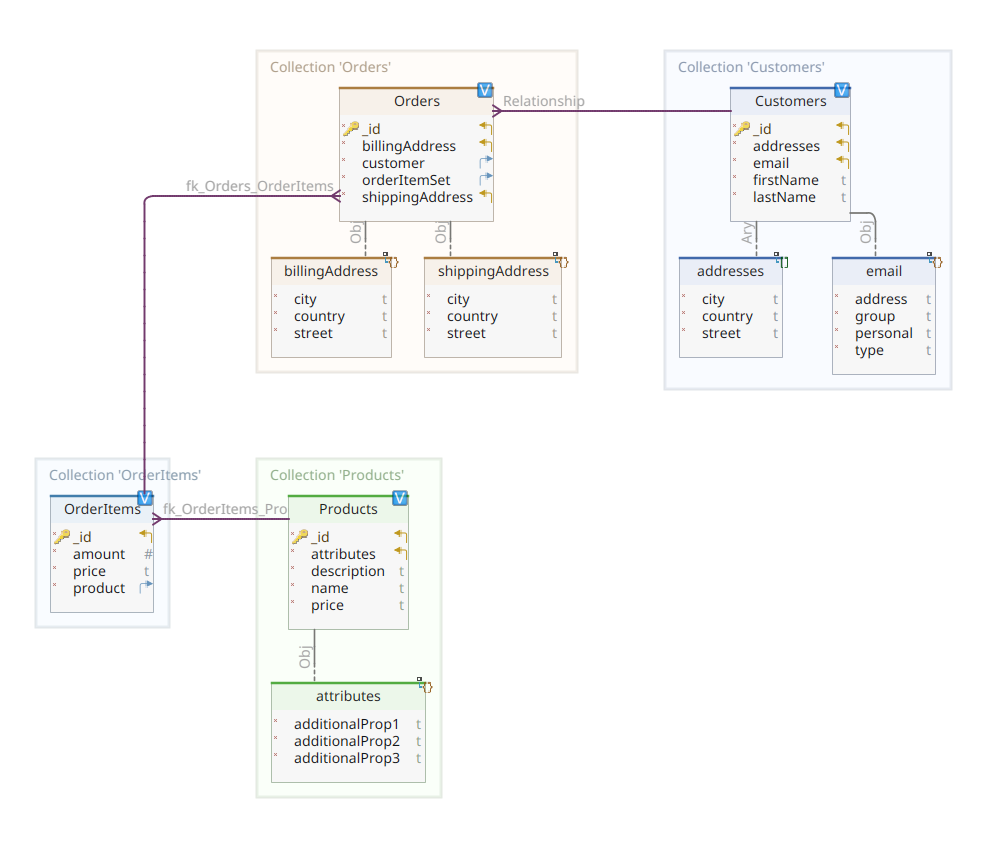
Jak widać, centralnym dokumentem modelu jest Orderprzechowywany w dedykowanej kolekcji o nazwie Orders. An Order jest agregatem OrderItem dokumentów, z których każdy wskazuje na powiązany z nim Product. An Order dokument odnosi się również do Customer który go umieścił. W Javie jest to zaimplementowane w następujący sposób:
@MongoEntity(database = "mdb", collection="Customers")
public class Customer
{
@BsonId
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}Powyższy kod pokazuje fragment kodu Customer class. Jest to POJO (Plain Old Java Object) z adnotacją @MongoEntity adnotacją, której parametry definiują nazwę bazy danych i nazwę kolekcji. The @BsonId jest używana w celu skonfigurowania unikalnego identyfikatora dokumentu. Podczas gdy najczęstszym przypadkiem użycia jest zaimplementowanie identyfikatora dokumentu jako instancji atrybutu ObjectID wprowadziłoby to bezużyteczne sprzężenie pływowe między klasami specyficznymi dla MongoDB a naszym dokumentem. Pozostałe właściwości to imię i nazwisko klienta, adres e-mail oraz zestaw adresów pocztowych.
Spójrzmy teraz na Order dokument.
@MongoEntity(database = "mdb", collection="Orders")
public class Order
{
@BsonId
private Long id;
private DBRef customer;
private Address shippingAddress;
private Address billingAddress;
private Set<DBRef> orderItemSet = new HashSet<>()
...
}Tutaj musimy utworzyć powiązanie między zamówieniem a klientem, który je złożył. Moglibyśmy osadzić powiązanie Customer w naszym dokumencie Order ale byłby to kiepski projekt, ponieważ niepotrzebnie zdefiniowałby ten sam obiekt dwa razy. Musimy użyć odniesienia do powiązanego obiektu Customer i zrobimy to za pomocą funkcji DBRef class. To samo dzieje się w przypadku zestawu powiązanych pozycji zamówienia, gdzie zamiast osadzać dokumenty, używamy zestawu odniesień.
Reszta naszego modelu domeny jest dość podobna i oparta na tych samych pomysłach normalizacji; na przykład, klasa OrderItem document:
@MongoEntity(database = "mdb", collection="OrderItems")
public class OrderItem
{
@BsonId
private Long id;
private DBRef product;
private BigDecimal price;
private int amount;
...
}Musimy skojarzyć produkt, który tworzy obiekt bieżącej pozycji zamówienia. Wreszcie, co nie mniej ważne, mamy Product dokument:
@MongoEntity(database = "mdb", collection="Products")
public class Product
{
@BsonId
private Long id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}To prawie wszystko, jeśli chodzi o nasz model domeny. Istnieje jednak kilka dodatkowych pakietów, którym musimy się przyjrzeć: serializers i codecs.
Aby móc wymieniać dane w sieci, wszystkie nasze obiekty, czy to biznesowe, czy czysto techniczne, muszą być serializowane i deserializowane. Za te operacje odpowiedzialne są specjalnie wyznaczone komponenty zwane serializery/deserializery. Jak widzieliśmy, używamy funkcji DBRef w celu zdefiniowania powiązania między różnymi kolekcjami. Jak każdy inny obiekt, typ DBRef instancja powinna być w stanie być serializowana/deserializowana.
Sterownik MongoDB zapewnia serializatory/deserializatory dla większości typów danych, które mają być używane w najczęstszych przypadkach. Jednak z jakiegoś powodu nie zapewnia serializatorów/deserializatorów dla typów danych DBRef . W związku z tym musimy zaimplementować własny, i to jest właśnie to, czego potrzebujemy serializers . Przyjrzyjmy się tym klasom:
public class DBRefSerializer extends StdSerializer<DBRef>
{
public DBRefSerializer()
{
this(null);
}
protected DBRefSerializer(Class<DBRef> dbrefClass)
{
super(dbrefClass);
}
@Override
public void serialize(DBRef dbRef, JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException
{
if (dbRef != null)
{
jsonGenerator.writeStartObject();
jsonGenerator.writeStringField("id", (String)dbRef.getId());
jsonGenerator.writeStringField("collectionName", dbRef.getCollectionName());
jsonGenerator.writeStringField("databaseName", dbRef.getDatabaseName());
jsonGenerator.writeEndObject();
}
}
}To jest nasz DBRef i jak Państwo widzą, jest to serializator Jackson. Dzieje się tak, ponieważ quarkus-mongodb-panache którego tutaj używamy, opiera się na Jackson. Być może w przyszłym wydaniu JSON-B będzie używany, ale na razie utknęliśmy z Jacksonem. Rozszerza on rozszerzenie StdSerializer jak zwykle i serializuje powiązaną z nią klasę DBRef za pomocą generatora JSON, przekazanego jako argument wejściowy, w celu zapisania w strumieniu wyjściowym wartości DBRef tj. identyfikator obiektu, nazwę kolekcji i nazwę bazy danych. Aby uzyskać więcej informacji dotyczących DBRef struktury, proszę zapoznać się z dokumentacją MongoDB.
Deserializator wykonuje operację uzupełniającą, jak pokazano poniżej:
public class DBRefDeserializer extends StdDeserializer<DBRef>
{
public DBRefDeserializer()
{
this(null);
}
public DBRefDeserializer(Class<DBRef> dbrefClass)
{
super(dbrefClass);
}
@Override
public DBRef deserialize(JsonParser jsonParser, DeserializationContext deserializationContext) throws IOException, JacksonException
{
JsonNode node = jsonParser.getCodec().readTree(jsonParser);
return new DBRef(node.findValue("databaseName").asText(), node.findValue("collectionName").asText(), node.findValue("id").asText());
}
}To właściwie wszystko, co można powiedzieć o serializatorach/deserializatorach. Przejdźmy dalej, aby zobaczyć, co codecs .
Obiekty Java są przechowywane w bazie danych MongoDB przy użyciu formatu BSON (Binary JSON). Aby przechowywać informacje, sterownik MongoDB musi mieć możliwość mapowania obiektów Java na powiązaną z nimi reprezentację BSON. Robi to w imieniu Codec który zawiera wymagane metody abstrakcyjne do mapowania obiektów Java na BSON i odwrotnie. Implementując ten interfejs, można zdefiniować logikę konwersji między Javą a BSON i odwrotnie. Sterownik MongoDB zawiera wymagane Codec implementację dla najpopularniejszych typów, ale ponownie, z jakiegoś powodu, jeśli chodzi o DBRef, ta implementacja jest tylko atrapą, która podnosi UnsupportedOperationException. Po skontaktowaniu się z implementatorami sterownika MongoDB nie udało mi się znaleźć innego rozwiązania niż wdrożenie własnego Codec mappera, jak pokazuje klasa DocstoreDBRefCodec. Ze względu na zwięzłość, nie będziemy tutaj odtwarzać kodu źródłowego tej klasy.
Gdy nasza dedykowana klasa Codec musimy zarejestrować go w sterowniku MongoDB, tak aby korzystał z niego podczas mapowania typów DBRef na obiekty Java i odwrotnie. Aby to zrobić, musimy zaimplementować interfejs CoderProvider który, jak pokazuje klasa DocstoreDBRefCodecProviderzwraca poprzez swoją abstrakcję get() metodę, konkretną klasę odpowiedzialną za wykonanie mapowania; tj. w naszym przypadku, DocstoreDBRefCodec. I to wszystko, co musimy tutaj zrobić, ponieważ Quarkus automatycznie wykryje i użyje naszego CodecProvider niestandardowej implementacji. Proszę spojrzeć na te klasy, aby zobaczyć i zrozumieć, jak to się robi.
Repozytoria danych
Quarkus Panache znacznie upraszcza proces utrwalania danych, obsługując zarówno metodę aktywny rekord oraz repozytorium wzorców projektowych. Tutaj będziemy używać drugiego z nich.
W przeciwieństwie do podobnych stosów trwałości, Panache opiera się na ulepszeniach kodu bajtowego encji w czasie kompilacji. Zawiera procesor adnotacji, który automatycznie wykonuje te ulepszenia. Wszystko, czego potrzebuje ten procesor adnotacji, aby wykonać swoje zadanie ulepszeń, to interfejs taki jak ten poniżej:
@ApplicationScoped
public class CustomerRepository implements PanacheMongoRepositoryBase<Customer, Long>{}Powyższy kod jest wszystkim, czego potrzeba, aby zdefiniować kompletną usługę zdolną do utrzymywania Customer instancji dokumentu. Państwa interfejs musi rozszerzać PanacheMongoRepositoryBase i sparametryzować go swoim typem ID obiektu, w naszym przypadku a Long. Procesor adnotacji Panache wygeneruje wszystkie wymagane punkty końcowe wymagane do wykonania najczęstszych czynności. operacji CRUD, w tym między innymi zapisywanie, aktualizowanie, usuwanie, odpytywanie, stronicowanie, sortowanie, obsługa transakcji itp. Wszystkie te szczegóły zostały w pełni wyjaśnione tutaj. Inną możliwością jest rozszerzenie PanacheMongoRepository zamiast PanacheMongoRepositoryBase i proszę użyć podanego ObjectID zamiast dostosowywać je jako Long, jak to zrobiliśmy w naszym przykładzie. Niezależnie od tego, czy wybrali Państwo pierwszą czy drugą alternatywę, jest to tylko kwestia preferencji.
API REST
Aby nasza usługa trwałości wygenerowana przez Panache stała się skuteczna, musimy ją udostępnić za pośrednictwem interfejsu API REST API. W najczęstszym przypadku musimy ręcznie stworzyć to API, wraz z jego implementacją, składającą się z pełnego zestawu wymaganych punktów końcowych REST. Tej żmudnej i powtarzalnej operacji można uniknąć, korzystając z funkcji quarkus-mongodb-rest-data-panache którego procesor adnotacji jest w stanie automatycznie wygenerować wymagane punkty końcowe REST z interfejsów o następującym wzorcu:
public interface CustomerResource
extends PanacheMongoRepositoryResource<CustomerRepository, Customer, Long> {}Proszę wierzyć: to wszystko, czego potrzeba do wygenerowania pełnej implementacji API REST ze wszystkimi punktami końcowymi wymaganymi do wywołania usługi trwałości wygenerowanej wcześniej przez procesor adnotacji. mongodb-panache procesor adnotacji rozszerzenia. Teraz jesteśmy gotowi do zbudowania naszego REST API jako mikrousługi Quarkus. Zdecydowaliśmy się zbudować tę mikrousługę jako obraz Docker w imieniu usługi quarkus-container-image-jib extension. Wystarczy dołączyć następującą zależność Maven:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-container-image-jib</artifactId>
</dependency>The quarkus-maven-plugin utworzy lokalny obraz Docker do uruchomienia naszej mikrousługi. Parametry tego obrazu Docker są definiowane przez parametr application.properties w następujący sposób:
quarkus.container-image.build=true
quarkus.container-image.group=quarkus-nosql-tests
quarkus.container-image.name=docstore-mongodb
quarkus.mongodb.connection-string = mongodb://admin:admin@mongo:27017
quarkus.mongodb.database = mdb
quarkus.swagger-ui.always-include=true
quarkus.jib.jvm-entrypoint=/opt/jboss/container/java/run/run-java.shTutaj definiujemy nazwę nowo utworzonego pliku Docker obraz jako quarkus-nosql-tests/docstore-mongodb. Jest to konkatenacja parametrów quarkus.container-image.group i quarkus.container-image.name oddzielone znakiem “https://dzone.com/”. Właściwość quarkus.container-image.build mająca wartość true instruuje wtyczkę Quarkus, aby powiązała operację kompilacji z plikiem package phase of maven. W ten sposób można po prostu wykonać mvn package generujemy obraz Docker zdolny do uruchomienia naszej mikrousługi. Można to przetestować uruchamiając docker images . Właściwość o nazwie quarkus.jib.jvm-entrypoint definiuje polecenie, które ma zostać uruchomione przez nowo wygenerowany obraz Docker. quarkus-run.jar jest standardowym plikiem startowym mikrousługi Quarkus używanym, gdy obraz bazowy to ubi8/openjdk-17-runtime, jak w naszym przypadku. Inne właściwości to quarkus.mongodb.connection-string oraz quarkus.mongodb.database = mdb które definiują ciąg połączenia z bazą danych MongoDB i nazwę bazy danych. Ostatnia, ale nie mniej ważna, właściwość quarkus.swagger-ui.always-include zawiera interfejs Swagger UI w naszej przestrzeni mikrousług, dzięki czemu możemy go łatwo przetestować.
Zobaczmy teraz, jak uruchomić i przetestować całość.
Uruchamianie i testowanie naszych mikrousług
Teraz, gdy przyjrzeliśmy się szczegółom naszej implementacji, zobaczmy, jak ją uruchomić i przetestować. Zdecydowaliśmy się zrobić to w imieniu docker-compose utility. Oto powiązane docker-compose.yml plik:
version: "3.7"
services:
mongo:
image: mongo
environment:
MONGO_INITDB_ROOT_USERNAME: admin
MONGO_INITDB_ROOT_PASSWORD: admin
MONGO_INITDB_DATABASE: mdb
hostname: mongo
container_name: mongo
ports:
- "27017:27017"
volumes:
- ./mongo-init/:/docker-entrypoint-initdb.d/:ro
mongo-express:
image: mongo-express
depends_on:
- mongo
hostname: mongo-express
container_name: mongo-express
links:
- mongo:mongo
ports:
- 8081:8081
environment:
ME_CONFIG_MONGODB_ADMINUSERNAME: admin
ME_CONFIG_MONGODB_ADMINPASSWORD: admin
ME_CONFIG_MONGODB_URL: mongodb://admin:admin@mongo:27017/
docstore:
image: quarkus-nosql-tests/docstore-mongodb:1.0-SNAPSHOT
depends_on:
- mongo
- mongo-express
hostname: docstore
container_name: docstore
links:
- mongo:mongo
- mongo-express:mongo-express
ports:
- "8080:8080"
- "5005:5005"
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jarTen plik instruuje aplikację docker-compose uruchomienie trzech usług:
- Usługa o nazwie
mongouruchamiająca bazę danych Mongo DB 7 - Usługa o nazwie
mongo-expressuruchamiająca interfejs administracyjny MongoDB - Usługa o nazwie
docstoreuruchamiająca nasz mikroserwis Quarkus
Powinniśmy zauważyć, że mongo używa skryptu inicjalizacyjnego zamontowanego na serwerze docker-entrypoint-initdb.d katalogu kontenera. Ten skrypt inicjalizacyjny tworzy bazę danych MongoDB o nazwie mdb aby mogła być używana przez mikrousługi.
db = db.getSiblingDB(process.env.MONGO_INITDB_ROOT_USERNAME);
db.auth(
process.env.MONGO_INITDB_ROOT_USERNAME,
process.env.MONGO_INITDB_ROOT_PASSWORD,
);
db = db.getSiblingDB(process.env.MONGO_INITDB_DATABASE);
db.createUser(
{
user: "nicolas",
pwd: "password1",
roles: [
{
role: "dbOwner",
db: "mdb"
}]
});
db.createCollection("Customers");
db.createCollection("Products");
db.createCollection("Orders");
db.createCollection("OrderItems");Jest to inicjalizacyjny JavaScript, który tworzy użytkownika o nazwie nicolas i nową bazę danych o nazwie mdb. Użytkownik ma uprawnienia administracyjne do bazy danych. Cztery nowe kolekcje, odpowiednio nazwane Customers, Products, Orders oraz OrderItems, są również tworzone.
Aby przetestować mikrousługi, proszę postępować w następujący sposób:
- Proszę sklonować powiązane repozytorium GitHub:
$ git clone https://github.com/nicolasduminil/docstore.git
- Proszę przejść do projektu:
$ cd docstore
- Proszę zbudować projekt:
$ mvn clean install
- Proszę sprawdzić, czy wszystkie wymagane kontenery Docker są uruchomione:
$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 7882102d404d quarkus-nosql-tests/docstore-mongodb:1.0-SNAPSHOT "/opt/jboss/containe…" 8 seconds ago Up 6 seconds 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore 786fa4fd39d6 mongo-express "/sbin/tini -- /dock…" 8 seconds ago Up 7 seconds 0.0.0.0:8081->8081/tcp, :::8081->8081/tcp mongo-express 2e850e3233dd mongo "docker-entrypoint.s…" 9 seconds ago Up 7 seconds 0.0.0.0:27017->27017/tcp, :::27017->27017/tcp mongo
- Proszę uruchomić testy integracyjne:
$ mvn -DskipTests=false failsafe:integration-test
To ostatnie polecenie uruchomi wszystkie testy integracyjne, które powinny zakończyć się powodzeniem. Te testy integracyjne są zaimplementowane przy użyciu RESTassured biblioteki. Poniższa lista przedstawia jeden z tych testów integracyjnych znajdujący się w bibliotece docstore-domain project:
@QuarkusIntegrationTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
public class CustomerResourceIT
{
private static Customer customer;
@BeforeAll
public static void beforeAll() throws AddressException
{
customer = new Customer("John", "Doe", new InternetAddress("john.doe@gmail.com"));
customer.addAddress(new Address("Gebhard-Gerber-Allee 8", "Kornwestheim", "Germany"));
customer.setId(10L);
}
@Test
@Order(10)
public void testCreateCustomerShouldSucceed()
{
given()
.header("Content-type", "application/json")
.and().body(customer)
.when().post("/customer")
.then()
.statusCode(HttpStatus.SC_CREATED);
}
@Test
@Order(20)
public void testGetCustomerShouldSucceed()
{
assertThat (given()
.header("Content-type", "application/json")
.when().get("/customer")
.then()
.statusCode(HttpStatus.SC_OK)
.extract().body().jsonPath().getString("firstName[0]")).isEqualTo("John");
}
@Test
@Order(30)
public void testUpdateCustomerShouldSucceed()
{
customer.setFirstName("Jane");
given()
.header("Content-type", "application/json")
.and().body(customer)
.when().pathParam("id", customer.getId()).put("/customer/{id}")
.then()
.statusCode(HttpStatus.SC_NO_CONTENT);
}
@Test
@Order(40)
public void testGetSingleCustomerShouldSucceed()
{
assertThat (given()
.header("Content-type", "application/json")
.when().pathParam("id", customer.getId()).get("/customer/{id}")
.then()
.statusCode(HttpStatus.SC_OK)
.extract().body().jsonPath().getString("firstName")).isEqualTo("Jane");
}
@Test
@Order(50)
public void testDeleteCustomerShouldSucceed()
{
given()
.header("Content-type", "application/json")
.when().pathParam("id", customer.getId()).delete("/customer/{id}")
.then()
.statusCode(HttpStatus.SC_NO_CONTENT);
}
@Test
@Order(60)
public void testGetSingleCustomerShouldFail()
{
given()
.header("Content-type", "application/json")
.when().pathParam("id", customer.getId()).get("/customer/{id}")
.then()
.statusCode(HttpStatus.SC_NOT_FOUND);
}
}Mogą Państwo również użyć interfejsu Swagger UI do celów testowych, uruchamiając preferowaną przeglądarkę pod adresem http://localhost:8080/q:swagger-ui. Następnie, aby przetestować punkty końcowe, można użyć ładunków w plikach JSON znajdujących się w folderze src/resources/data katalogu docstore-api projektu.
Można również użyć interfejsu administracyjnego MongoDB UI, przechodząc do http://localhost:8081 i uwierzytelniając się przy użyciu domyślnych poświadczeń (admin/pass).
Kod źródłowy projektu można znaleźć w moim repozytorium GitHub.
Proszę się cieszyć!