
W Część 1 tej serii przyjrzeliśmy się MongoDB, jednej z najbardziej niezawodnych i solidnych baz danych NoSQL zorientowanych na dokumenty. W części 2 przyjrzymy się innej, dość nieuniknionej bazie danych NoSQL: Elasticsearch.
Więcej niż tylko popularna i potężna rozproszona baza danych NoSQL typu open source, Elasticsearch to przede wszystkim silnik wyszukiwania i analizy. Jest on zbudowany na bazie Apache Lucene, najbardziej znana wyszukiwarka Java i jest w stanie wykonywać operacje wyszukiwania i analizy w czasie rzeczywistym na ustrukturyzowanych i nieustrukturyzowanych danych. Został zaprojektowany do wydajnej obsługi dużych ilości danych.
Po raz kolejny musimy zastrzec, że ten krótki post nie jest w żadnym wypadku samouczkiem Elasticsearch. W związku z tym cierpliwym czytelnikom zdecydowanie zaleca się obszerne korzystanie z oficjalnej dokumentacji, a także doskonałej książki “Elasticsearch w akcji” autorstwa Madhusudhan Konda (Manning, 2023), aby dowiedzieć się więcej o architekturze i działaniu produktu. Tutaj po prostu ponownie wdrażamy ten sam przypadek użycia, co poprzednio, ale tym razem używamy Elasticsearch zamiast MongoDB.
No to zaczynamy!
Model domeny
Poniższy diagram przedstawia nasz *customer-order-product*. model domeny:
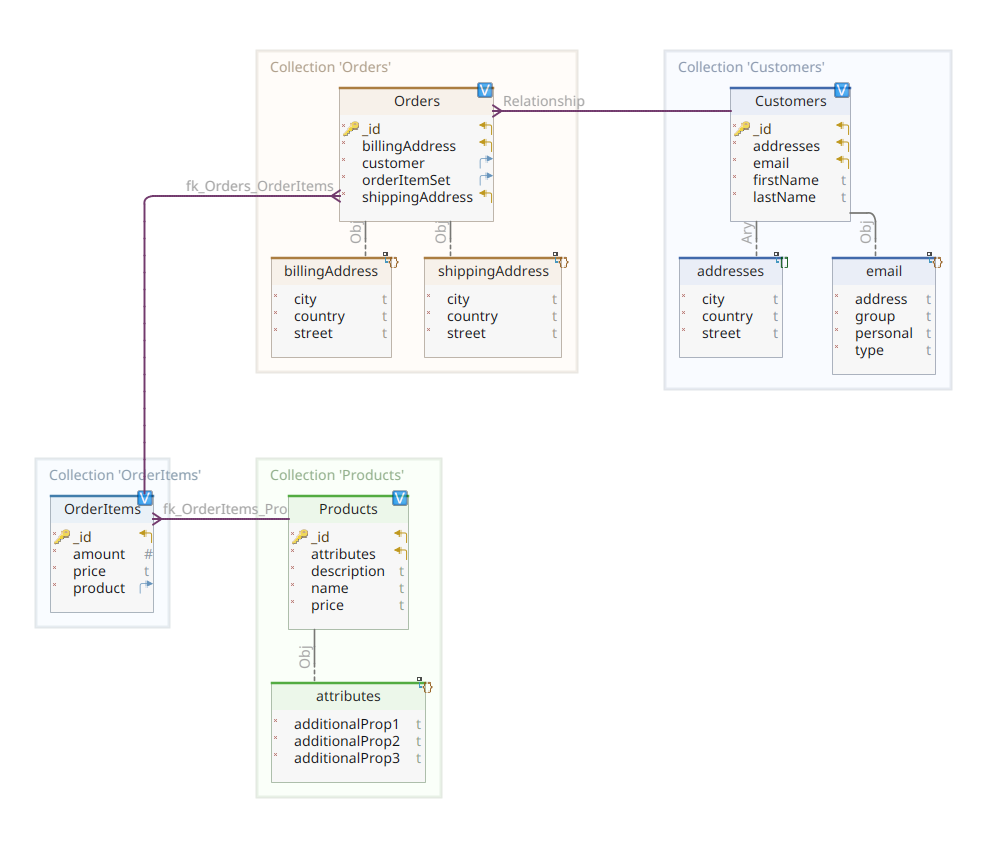
Ten diagram jest taki sam jak ten przedstawiony w części 1. Podobnie jak MongoDB, Elasticsearch jest również magazynem danych dokumentów i jako taki oczekuje, że dokumenty będą prezentowane w formacie JSON notacja. Jedyną różnicą jest to, że aby obsłużyć dane, Elasticsearch musi je zindeksować.
Istnieje kilka sposobów indeksowania danych w magazynie danych Elasticsearch; na przykład potokowanie ich z relacyjnej bazy danych, wyodrębnianie ich z systemu plików, przesyłanie strumieniowe ze źródła w czasie rzeczywistym itp. Niezależnie jednak od metody pozyskiwania danych, ostatecznie polega ona na wywołaniu interfejsu API RESTful Elasticsearch za pośrednictwem dedykowanego klienta. Istnieją dwie kategorie takich dedykowanych klientów:
- Klienty oparte na REST jak
curl,Postman, moduły HTTP dla Java, JavaScript, Node.js itp. - Zestawy SDK dla języków programowania (Software Development Kit): Elasticsearch zapewnia zestawy SDK dla wszystkich najczęściej używanych języków programowania, w tym między innymi Java, Python itp.
Indeksowanie nowego dokumentu za pomocą Elasticsearch oznacza utworzenie go przy użyciu pliku POST w specjalnym punkcie końcowym RESTful API o nazwie _doc. Na przykład poniższe żądanie utworzy nowy indeks Elasticsearch i zapisze w nim nową instancję klienta.
POST customers/_doc/
{
"id": 10,
"firstName": "John",
"lastName": "Doe",
"email": {
"address": "john.doe@gmail.com",
"personal": "John Doe",
"encodedPersonal": "John Doe",
"type": "personal",
"simple": true,
"group": true
},
"addresses": [
{
"street": "75, rue Véronique Coulon",
"city": "Coste",
"country": "France"
},
{
"street": "Wulfweg 827",
"city": "Bautzen",
"country": "Germany"
}
]
}Uruchomienie powyższego żądania przy użyciu curl lub konsoli Kibana (jak zobaczymy później) da następujący wynik:
{
"_index": "customers",
"_id": "ZEQsJI4BbwDzNcFB0ubC",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
Jest to standardowa odpowiedź Elasticsearch na zapytanie POST żądanie. Potwierdza ona utworzenie indeksu o nazwie customersi utworzenie nowego indeksu customer dokument, identyfikowany przez automatycznie wygenerowany identyfikator ( w tym przypadku, ZEQsJI4BbwDzNcFB0ubC).
Pojawiają się tutaj również inne ciekawe parametry, takie jak _version a w szczególności _shards. Bez wchodzenia w zbyt wiele szczegółów, Elasticsearch tworzy indeksy jako logiczne kolekcje dokumentów. Podobnie jak przechowywanie dokumentów papierowych w szafce na dokumenty, Elasticsearch przechowuje dokumenty w indeksie. Każdy indeks składa się z odłamków, które są fizycznymi instancjami Apache Lucene, silnika za kulisami odpowiedzialnego za pobieranie danych do lub z pamięci masowej. Mogą to być podstawoweprzechowywanie dokumentów lub repliki, przechowujące, jak sama nazwa wskazuje, kopie podstawowych shardów. Więcej na ten temat w dokumentacji Elasticsearch – na razie musimy zauważyć, że nasz indeks o nazwie customers składa się z dwóch shardów, z których jeden jest oczywiście podstawowy.
Ostatnia uwaga: plik POST nie wspomina o wartości ID, ponieważ jest ona generowana automatycznie. Chociaż jest to prawdopodobnie najczęstszy przypadek użycia, mogliśmy podać własną wartość ID. W każdym przypadku żądanie HTTP do użycia nie jest POST ale PUT.
Wracając do naszego diagramu modelu domeny, jak Państwo widzą, jego centralnym dokumentem jest Orderprzechowywany w dedykowanej kolekcji o nazwie Orders. An Order jest agregatem OrderItem dokumentów, z których każdy wskazuje na powiązany z nim Product. An Order dokument odnosi się również do Customer który go umieścił. W Javie jest to zaimplementowane w następujący sposób:
public class Customer
{
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}
Powyższy kod pokazuje fragment kodu Customer . Jest to prosty obiekt POJO (Plain Old Java Object) posiadający właściwości takie jak identyfikator klienta, imię i nazwisko, adres e-mail oraz zestaw adresów pocztowych.
Przyjrzyjmy się teraz klasie Order dokument.
public class Order
{
private Long id;
private String customerId;
private Address shippingAddress;
private Address billingAddress;
private Set<String> orderItemSet = new HashSet<>()
...
}
Tutaj można zauważyć pewne różnice w porównaniu do wersji MongoDB. W rzeczywistości w MongoDB używaliśmy odniesienia do instancji klienta powiązanej z tym zamówieniem. To pojęcie referencji nie istnieje w Elasticsearch i dlatego używamy tego identyfikatora dokumentu, aby utworzyć powiązanie między zamówieniem a klientem, który je złożył. To samo odnosi się do orderItemSet która tworzy powiązanie między zamówieniem a jego pozycjami.
Reszta naszego modelu domeny jest dość podobna i oparta na tych samych pomysłach normalizacji. Na przykład OrderItem document:
public class OrderItem
{
private String id;
private String productId;
private BigDecimal price;
private int amount;
...
}
Tutaj musimy skojarzyć produkt, który tworzy obiekt bieżącej pozycji zamówienia. Wreszcie, co nie mniej ważne, mamy Product document:
public class Product
{
private String id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}Repozytoria danych
Quarkus Panache znacznie upraszcza trwałość danych poprzez wspieranie zarówno procesu aktywny rekord oraz repozytorium wzorce projektowe. W części 1 użyliśmy rozszerzenia Quarkus Panache dla MongoDB do wdrożenia naszych repozytoriów danych, ale nie ma jeszcze odpowiednika rozszerzenia Quarkus Panache dla Elasticsearch. W związku z tym, czekając na możliwe przyszłe rozszerzenie Quarkus dla Elasticsearch, musimy ręcznie zaimplementować nasze repozytoria danych za pomocą dedykowanego klienta Elasticsearch.
Elasticsearch jest napisany w języku Java, a zatem nie jest zaskoczeniem, że oferuje natywne wsparcie dla wywoływania interfejsu API Elasticsearch za pomocą biblioteki klienta Java. Biblioteka ta oparta jest na płynnych wzorcach projektowych API Builder i zapewnia zarówno synchroniczne, jak i asynchroniczne modele przetwarzania. Wymaga ona co najmniej Java 8.
Jak zatem wyglądają nasze repozytoria danych oparte na fluent API builder? Poniżej znajduje się fragment CustomerServiceImpl która działa jako repozytorium danych dla klasy Customer dokumentu.
@ApplicationScoped
public class CustomerServiceImpl implements CustomerService
{
private static final String INDEX = "customers";
@Inject
ElasticsearchClient client;
@Override
public String doIndex(Customer customer) throws IOException
{
return client.index(IndexRequest.of(ir -> ir.index(INDEX).document(customer))).id();
}
...
Jak widzimy, nasza implementacja repozytorium danych musi być fasolą CDI posiadającą zakres aplikacji. Klient Elasticsearch Java jest po prostu wstrzykiwany dzięki funkcji quarkus-elasticsearch-java-client Quarkus extension. W ten sposób unikamy wielu dzwonków i gwizdków, których musielibyśmy użyć w innym przypadku. Jedyną rzeczą, której potrzebujemy, aby móc wstrzyknąć klienta, jest zadeklarowanie następującej właściwości:
quarkus.elasticsearch.hosts = elasticsearch:9200Proszę, elasticsearch to nazwa DNS (Domain Name Server), którą kojarzymy z serwerem bazy danych Elastic search w pliku docker-compose.yaml . 9200 to numer portu TCP używanego przez serwer do nasłuchiwania połączeń.
Metoda doIndex() powyżej tworzy nowy indeks o nazwie customers jeśli nie istnieje i indeksuje (przechowuje) w nim nowy dokument reprezentujący instancję klasy Customer. Proces indeksowania jest wykonywany na podstawie IndexRequest przyjmując jako argumenty wejściowe nazwę indeksu i treść dokumentu. Jeśli chodzi o identyfikator dokumentu, jest on generowany automatycznie i zwracany do wywołującego w celu dalszego odniesienia.
Poniższa metoda umożliwia pobranie klienta zidentyfikowanego przez ID podane jako argument wejściowy:
...
@Override
public Customer getCustomer(String id) throws IOException
{
GetResponse<Customer> getResponse = client.get(GetRequest.of(gr -> gr.index(INDEX).id(id)), Customer.class);
return getResponse.found() ? getResponse.source() : null;
}
...
Zasada jest taka sama: używając tej metody fluent API builder, konstruujemy wzorzec GetRequest w podobny sposób jak w przypadku wzorca IndexRequesti uruchamiamy ją przeciwko klientowi Elasticsearch Java. Pozostałe punkty końcowe naszego repozytorium danych, umożliwiające nam wykonywanie pełnych operacji wyszukiwania lub aktualizowanie i usuwanie klientów, są zaprojektowane w ten sam sposób.
Proszę poświęcić trochę czasu na przyjrzenie się kodowi, aby zrozumieć, jak to działa.
API REST
Nasz interfejs API REST MongoDB był prosty do wdrożenia dzięki funkcji quarkus-mongodb-rest-data-panache w którym procesor adnotacji automatycznie wygenerował wszystkie wymagane punkty końcowe. W przypadku Elasticsearch nie korzystamy jeszcze z tego samego komfortu, a zatem musimy go ręcznie wdrożyć. Nie jest to duży problem, ponieważ możemy wstrzyknąć poprzednie repozytoria danych, pokazane poniżej:
@Path("customers")
@Produces(APPLICATION_JSON)
@Consumes(APPLICATION_JSON)
public class CustomerResourceImpl implements CustomerResource
{
@Inject
CustomerService customerService;
@Override
public Response createCustomer(Customer customer, @Context UriInfo uriInfo) throws IOException
{
return Response.accepted(customerService.doIndex(customer)).build();
}
@Override
public Response findCustomerById(String id) throws IOException
{
return Response.ok().entity(customerService.getCustomer(id)).build();
}
@Override
public Response updateCustomer(Customer customer) throws IOException
{
customerService.modifyCustomer(customer);
return Response.noContent().build();
}
@Override
public Response deleteCustomerById(String id) throws IOException
{
customerService.removeCustomerById(id);
return Response.noContent().build();
}
}Jest to implementacja REST API klienta. Pozostałe repozytoria związane z zamówieniami, pozycjami zamówień i produktami są podobne.
Zobaczmy teraz, jak uruchomić i przetestować całość.
Uruchamianie i testowanie naszych mikrousług
Teraz, gdy przyjrzeliśmy się szczegółom naszej implementacji, zobaczmy, jak ją uruchomić i przetestować. Zdecydowaliśmy się zrobić to w imieniu docker-compose utility. Oto powiązane docker-compose.yml plik:
version: "3.7"
services:
elasticsearch:
image: elasticsearch:8.12.2
environment:
node.name: node1
cluster.name: elasticsearch
discovery.type: single-node
bootstrap.memory_lock: "true"
xpack.security.enabled: "false"
path.repo: /usr/share/elasticsearch/backups
ES_JAVA_OPTS: -Xms512m -Xmx512m
hostname: elasticsearch
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- node1-data:/usr/share/elasticsearch/data
networks:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.6.2
hostname: kibana
container_name: kibana
environment:
- elasticsearch.url=http://elasticsearch:9200
- csp.strict=false
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 5601:5601
networks:
- elasticsearch
depends_on:
- elasticsearch
links:
- elasticsearch:elasticsearch
docstore:
image: quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT
depends_on:
- elasticsearch
- kibana
hostname: docstore
container_name: docstore
links:
- elasticsearch:elasticsearch
- kibana:kibana
ports:
- "8080:8080"
- "5005:5005"
networks:
- elasticsearch
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jar
volumes:
node1-data:
driver: local
networks:
elasticsearch:
Ten plik instruuje aplikację docker-compose uruchomienie trzech usług:
- Usługa o nazwie
elasticsearchuruchamiająca bazę danych Elasticsearch 8.6.2 - Usługa o nazwie
kibanauruchamiająca wielofunkcyjną konsolę internetową zapewniającą różne opcje, takie jak wykonywanie zapytań, tworzenie agregacji oraz opracowywanie pulpitów nawigacyjnych i wykresów - Usługa o nazwie
docstoreuruchamiająca nasz mikroserwis Quarkus
Teraz mogą Państwo sprawdzić, czy wszystkie wymagane procesy są uruchomione:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
005ab8ebf6c0 quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT "/opt/jboss/containe…" 3 days ago Up 3 days 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore
9678c0a04307 docker.elastic.co/kibana/kibana:8.6.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
805eba38ff6c elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
$
Aby potwierdzić, że serwer Elasticsearch jest dostępny i może uruchamiać zapytania, można połączyć się z Kibaną pod adresem http://localhost:601. Po przewinięciu strony w dół i wybraniu opcji Dev Tools w menu preferencji można uruchamiać zapytania, jak pokazano poniżej:
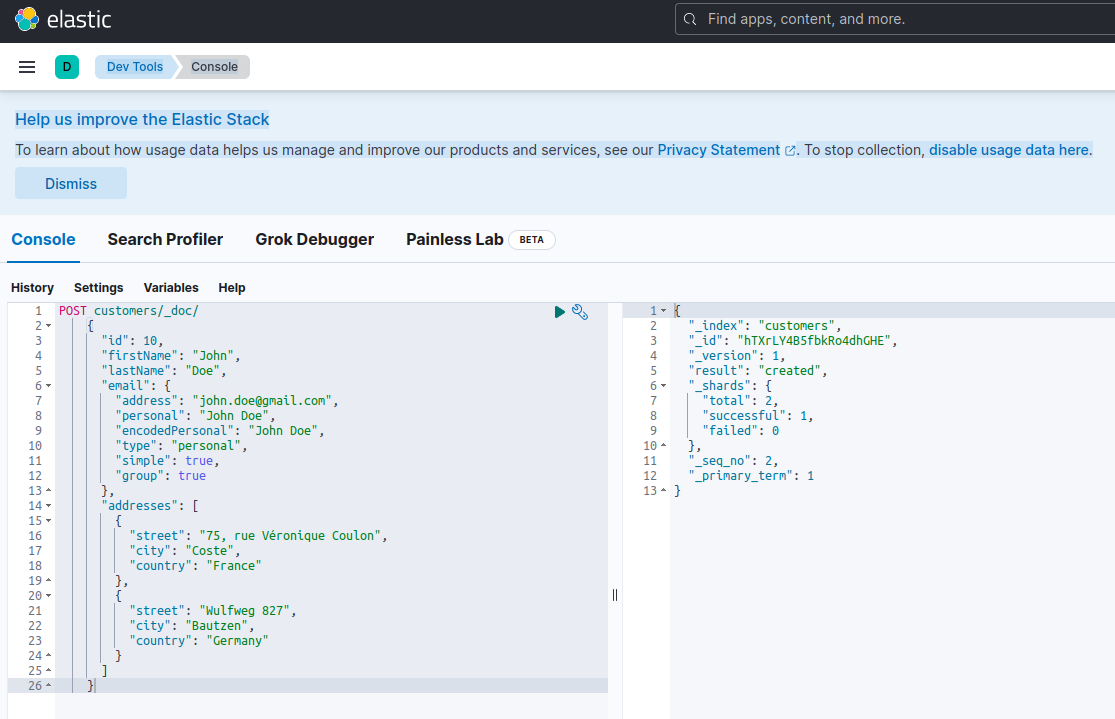
Aby przetestować mikrousługi, proszę postępować w następujący sposób:
1. Proszę sklonować powiązane repozytorium GitHub:
$ git clone https://github.com/nicolasduminil/docstore.git2. Proszę przejść do projektu:
3. Proszę sprawdzić właściwą gałąź:
$ git checkout elastic-search4. Proszę zbudować:
5. Proszę uruchomić testy integracyjne:
$ mvn -DskipTests=false failsafe:integration-testTo ostatnie polecenie uruchomi 17 dostarczonych testów integracyjnych, które powinny zakończyć się sukcesem. Mogą Państwo również użyć interfejsu Swagger UI do celów testowych, uruchamiając preferowaną przeglądarkę pod adresem http://localhost:8080/q:swagger-ui. Następnie, aby przetestować punkty końcowe, można użyć ładunku w plikach JSON znajdujących się w folderze src/resources/data katalogu docstore-api projektu.
Proszę się cieszyć!