
Ten artykuł opowiada o tym, jak marka sklepu spożywczego wykorzystuje Replikacja międzyklastrowa (CCR) Apache Doris, aby oddzielić obciążenia związane z odczytem i zapisem danych. W tym przypadku, gdzie świeżość artykułów spożywczych jest gwarantowana przez świeżość danych, firma używa Apache Doris jako hurtowni danych do monitorowania i analizowania zamówień, sprzedaży i zapasów w czasie rzeczywistym dla wszystkich swoich sklepów i łańcuchów dostaw.
Dlaczego potrzebują CCR
Znaczna część hurtowni danych użytkownika (w tym warstwy ODS, DWD, DWS i ADS) jest zbudowana w ramach Apache Doris, który wykorzystuje mechanizm harmonogramowania mikropartii do koordynowania danych w warstwach hurtowni danych. Jest to jednak wymuszone przez rozwijającą się działalność marki sklepów spożywczych. Rozmiar danych, które muszą odbierać, przechowywać i analizować, staje się coraz większy. Oznacza to, że ich hurtownia danych musi obsługiwać większe partie zapisu danych i częstsze zapytania o dane. Jednak planowanie zadań podczas wykonywania zapytań może prowadzić do wywłaszczania zasobów, więc każdy niedobór zasobów może łatwo zagrozić wydajności, a nawet spowodować awarię zadania lub zakłócenie działania systemu.
Naturalnie, użytkownik pomyślał o oddzieleniu obciążenia związanego z odczytem i zapisem. W szczególności chcą replikować dane z warstwy ADS (która jest czyszczona, przekształcana, agregowana i gotowa do zapytania) do zapasowego klastra dedykowanego usługom zapytań. Jest to realizowane przez CCR w Apache Doris. Zapobiega ona przerywaniu zapisu danych przez nieprawidłowe zapytania i zapewnia stabilność klastra.
Przed CCR
Zanim CCR był dostępny, innowacyjnie przyjęli oni metodę Multi-Catalog funkcja Doris do tego samego celu. Multi-Catalog pozwala użytkownikom wygodnie łączyć Doris z różnymi źródłami danych. W rzeczywistości jest on przeznaczony do federacyjnych zapytań, ale użytkownik czerpał z niego inspirację. Napisali oni skrypt i spróbowali pobrać przyrostowe dane za pośrednictwem Catalog. Ich potok synchronizacji danych wygląda następująco:
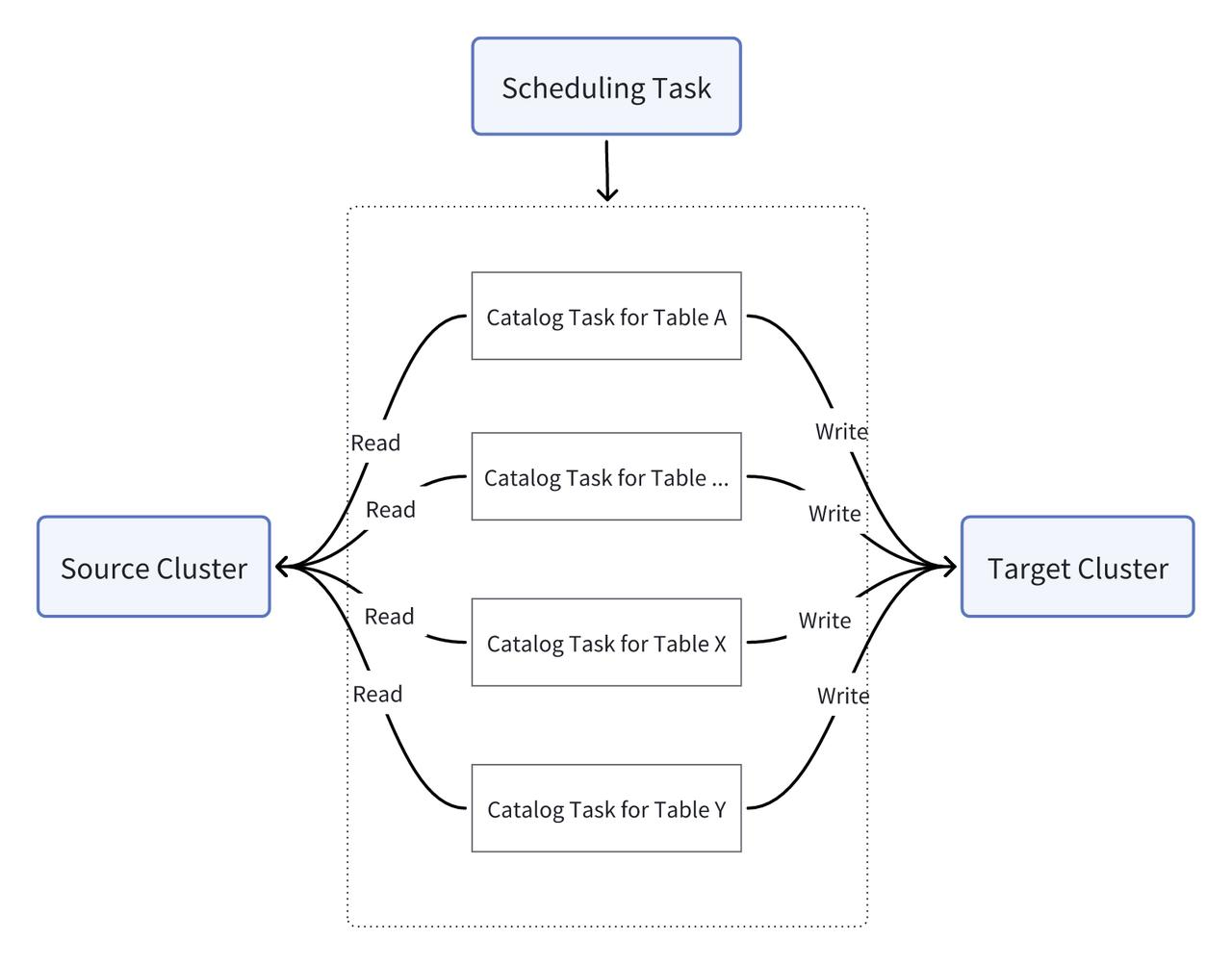
Załadowali oni dane z klastra źródłowego do klastra docelowego poprzez regularne planowanie zadań. Aby zidentyfikować dane przyrostowe, dodano funkcję last_update_time do tabel. Miało to dwie wady. Po pierwsze, świeżość danych klastra docelowego była zależna od zadań harmonogramowania i utrudniona przez nie. Po drugie, w przypadku pozyskiwania danych przyrostowych, aby zidentyfikować dane przyrostowe, instrukcja SQL importu dla każdej tabeli musi zawierać logikę sprawdzania pola last_update_time w przeciwnym razie system po prostu usunie i ponownie zaimportuje całą tabelę. Taki wymóg zwiększa złożoność programowania i poziom błędów danych.
CCR w Apache Doris
Właśnie wtedy, gdy szukali lepszego rozwiązania, Apache Doris wydał CCR w wersji 2.0. W porównaniu z alternatywami, których próbowali, CCR w Apache Doris jest:
- Lekka konstrukcja: Zadania synchronizacji danych zużywają bardzo mało zasobów maszynowych. Działają one płynnie bez zmniejszania ogólnej wydajności Apache Doris.
- Łatwy w użyciu: Można go skonfigurować za pomocą jednego prostego
POSTżądanie. - Nieograniczona migracja: Użytkownicy mogą podnieść górny limit możliwości migracji danych w CCR poprzez optymalizację konfiguracji klastra.
- Spójność danych: Instrukcje DDL wykonywane w klastrze źródłowym mogą być automatycznie synchronizowane z klastrem docelowym, zapewniając spójność danych.
- Elastyczność w synchronizacji: Jest w stanie wykonać zarówno pełną synchronizację danych, jak i przyrostową synchronizację danych.
Uruchomienie CCR w Doris wymaga po prostu dwóch kroków. Krok pierwszy to włączenie binlogów zarówno w klastrze źródłowym, jak i docelowym. Krok drugi to wysłanie nazwy bazy danych lub tabeli, która ma być replikowana. Następnie system rozpocznie synchronizację pełnych lub przyrostowych danych. Szczegółowa procedura wygląda następująco:
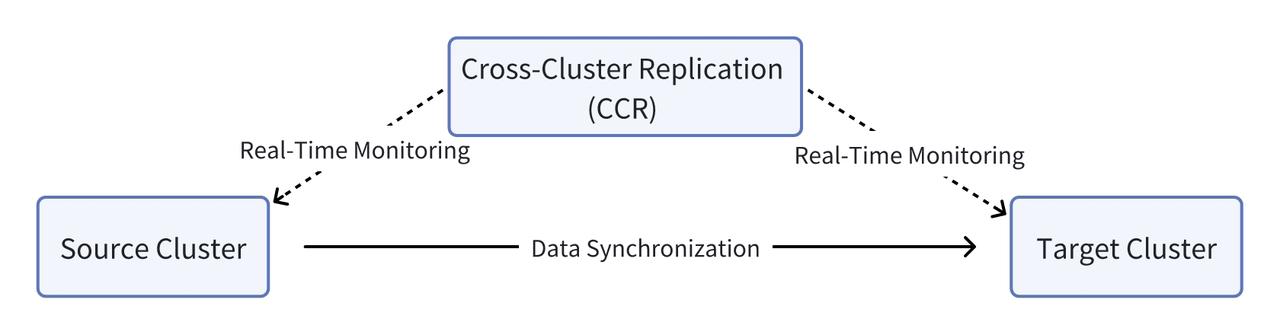
W przypadku marki sklepu spożywczego muszą oni zsynchronizować kilka tabel z klastra źródłowego do klastra docelowego, przy czym każda tabela ma przyrostowy rozmiar danych wynoszący około 50 milionów wierszy. Po miesiącu prób mechanizm Doris CCR okazał się stabilny i wydajny:
- Wyższa stabilność i dokładność danych: W okresie próbnym nie wystąpiła żadna awaria replikacji. Każdy wiersz danych jest przesyłany i trafia dokładnie do klastra docelowego.
- Usprawnione przepływy pracy:
- Przed CCR: Użytkownik musiał napisać SQL dla każdej tabeli i zapisać dane za pośrednictwem Catalog; Dla tabel bez
last_update_timeprzyrostowa synchronizacja danych może być realizowana tylko poprzez pełne usunięcie i ponowne zaimportowanie tabeli.
- Przed CCR: Użytkownik musiał napisać SQL dla każdej tabeli i zapisać dane za pośrednictwem Catalog; Dla tabel bez
Insert into catalog1.db.destination_table_1 select * from catalog1.db.source_table1 where time > xxx
Insert into catalog1.db.destination_table_2 select * from catalog1.db.source_table2 where time > xxx
…
Insert into catalog1.db.destination_table_x select * from catalog1.db.source_table_x
- Po CCR: Wymaga tylko jednego
POSTaby zsynchronizować całą bazę danych.
curl -X POST -H "Content-Type: application/json" -d '{
"name": "ccr_test",
"src": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "demo",
"table": ""
},
"dest": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "ccrt",
"table": ""
}
}' http://127.0.0.1:9190/create_ccr
- Szybsze ładowanie danych: Dzięki CCR zajmuje to tylko 3~4 sekundy na pozyskanie dziennych danych przyrostowych, w porównaniu do ponad 30 sekund w przypadku metody Catalog. Jeśli chodzi o synchronizację w czasie rzeczywistym, CCR może zakończyć pozyskiwanie danych w ciągu 1 sekundy, bez polegania na ręcznych aktualizacjach lub regularnym planowaniu.
Wnioski
Korzystając z CCR w Apache Doris, marka sklepu spożywczego rozdziela obciążenia odczytu i zapisu na różne klastry, a tym samym poprawia ogólną stabilność systemu. Rozwiązanie to zapewnia opóźnienie synchronizacji danych w czasie rzeczywistym na poziomie około 1 sekundy. Aby dodatkowo zapewnić normalne funkcjonowanie, posiada ono mechanizm monitorowania i ostrzegania w czasie rzeczywistym, dzięki czemu wszelkie problemy będą natychmiast zgłaszane i obsługiwane, a także plan awaryjny gwarantujący nieprzerwane działanie usług zapytań. Obsługuje również synchronizację danych opartą na partycjach (np. ALTER TABLE tbl1 REPLACE PARTITION). Dzięki wykazanej skuteczności CCR, planują replikację większej ilości swoich zasobów danych w celu wydajnego i bezpiecznego wykorzystania danych.
CCR ma również zastosowanie, gdy trzeba zbudować wiele centrów danych lub uzyskać testowy zestaw danych ze środowiska produkcyjnego. Aby uzyskać więcej informacji na temat CCR, prosimy dołączyć do Społeczność Apache Doris.