
Szum informacyjny to zabawna rzecz. Czasami można znaleźć się w sytuacji z części 2 Ojca Chrzestnego, w której szum jest całkowicie uzasadniony. Słyszy pan o tym. Próbuje pan. Życie się zmienia. Hurra!
Innym razem znajdziesz się bardziej w sytuacji Avatar: The Way of Water… gdzie wszyscy wokół ciebie mruczą rzeczy takie jak “oszałamiająco wciągające”, a ty jesteś na uboczu, zastanawiając się, ile czasu możesz spędzić na oglądaniu niebieskich kosmitów źle pływających.
Niewiele jest modnych haseł w branży danych, które były bardziej popularne w ciągu ostatnich czterech lat niż ulubieniec samoobsługi, “siatka danych”. Podcasty. Newslettery. Całe grupy Slack poświęcone są zdecentralizowanej architekturze. To było dużo.
Proszę pozwolić mi powiedzieć, że siatka danych nie jest sytuacją z Avatara 2. (14 lat, James. Ugh.) Siatka danych to przemyślane, zdecentralizowane podejście, które ułatwia tworzenie opartych na domenie, samoobsługowych produktów danych.
Problem polega na tym, że nie każda organizacja powinna zorganizować swoją architekturę w ten sposób – lub może ją wspierać.
Siatka danych – w tym siatka danych zarządzanie-wymaga odpowiedniego połączenia procesów, narzędzi i zasobów wewnętrznych, aby było skuteczne. Niezależnie od tego, czy chodzi o projekt platformy, czy strukturę organizacyjną, są chwile, kiedy siatka danych nie ma sensu dla Państwa firmy – i to jest w porządku!
Nasuwa się jednak pytanie, skąd Państwo to wiedzą?
W tym artykule powrócimy do siatki danych, aby omówić, czym ona jest, dlaczego ma sens dla niektórych zespołów i kiedy nie ma sensu dla Państwa!
Proszę wskoczyć na hype cycle i zacząć działać.
Co to jest siatka danych?
Dostęp do danych jest krzykiem organizacji już od jakiegoś czasu. Jak szybciej uzyskać potrzebne dane? Skąd mamy wiedzieć, co się w nich znajduje? Jak możemy zweryfikować dokładność i przydatność tych danych dla naszych przypadków użycia?
Przez chwilę siatka danych była najważniejszą odpowiedzią na te pytania.
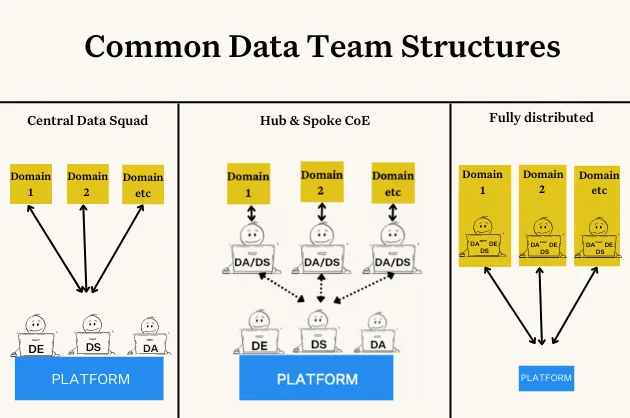
W ten sam sposób, w jaki zespoły inżynierów oprogramowania przeszły od monolitycznych aplikacji do architektur mikrousługowych, siatka danych jest pod wieloma względami wersją platformy danych mikrousług.
Jak po raz pierwszy zdefiniował Zhamak Dehghani w 2019 r., siatka danych to siatka danych to zdecentralizowane podejście, które obejmuje wszechobecność danych w przedsiębiorstwie poprzez wykorzystanie zorientowanego na domenę, samoobsługowego projektu.
Składa się zasadniczo z czterech kluczowych komponentów:
- Dane jako produkt: Zdefiniowanie krytycznych zasobów danych, w tym analitycznych, operacyjnych i związanych z klientami, które generują wartość dla każdej domeny.
- Własność zorientowana na domenę: Własność danych i wynikające z niej produkty danych są federowane między właścicielami domen, w tym odpowiedzialność za własne potoki ETL w oparciu o ujednolicony zestaw możliwości.
- Funkcjonalność samoobsługowa: Siatka danych pozwala użytkownikom na abstrakcyjną złożoność techniczną i skupienie się na samoobsłudze ich indywidualnych przypadków użycia danych za pomocą centralnej platformy, która obejmuje silniki potoku danych, pamięć masową i infrastrukturę przesyłania strumieniowego.
- Interoperacyjność i standaryzacja: U podstaw każdej domeny leży uniwersalny zestaw standardów danych, który ułatwia współpracę między domenami ze współdzielonymi danymi, w tym formatowanie, zarządzanie siatką danych, możliwość wyszukiwania i pola metadanych, a także inne cechy danych.
W rzeczywistych wdrożeniach często przekłada się to na niewielki centralny zespół platformy zapewniający wspólną infrastrukturę i podstawowe standardy, które zespoły danych osadzone w każdej domenie mogą budować i dostosowywać do swoich potrzeb.
Jednak w miarę jak teoria siatki danych przeszła przez cykl hype’u, stało się jasne, że przypadek użycia siatki danych jest znacznie węższy niż początkowo sugerowała koncepcja. I o wiele trudniejsze.
Tak więc, choć siatka danych jest fantastycznie elastyczna – i naprawdę ją uwielbiamy – poniżej przedstawiamy kilka sytuacji, w których siatka danych prawdopodobnie nie ma sensu.
Kiedy siatka danych nie działa
Brak gęstości talentów w domenie
Zdjęcie dzięki uprzejmości Monte Carlo.
Podczas gdy głównym celem siatki danych jest federacja własności produktu w różnych domenach, działa to tylko wtedy, gdy dany zespół domeny wie, co zrobić z tymi obowiązkami w zakresie danych, gdy już je otrzyma.
Nawet przy całej swojej abstrakcyjnej złożoności technicznej, siatka danych nadal wymaga wystarczającej ilości danych osadzonych w każdej domenie, aby działała. Bez doświadczenia na czele, siatka danych będzie nękana niskiej jakości, źle utrzymanymi produktami danych, które ostatecznie i tak będą musiały zostać przebudowane.
Tak więc, zanim zespół ds. danych wskoczy od razu do projektu siatki danych, proszę poświęcić chwilę na rozważenie kontekstu swojej organizacji. Czy każdy zespół domeny ma umiejętności i kompetencje, aby odnieść sukces? Jeśli nie, co trzeba zrobić, aby je zdobyć? I czy będą Państwo mieli poparcie ze strony interesariuszy domeny, aby ułatwić tę zmianę?
Jeśli odpowiedź na te pytania brzmi “nie” lub “nie w najbliższym czasie”, proszę nie wstydzić się pominąć na razie siatki danych i wrócić do niej, gdy organizacja będzie lepiej przygotowana do realizacji jej wartości.
Domeny biznesowe mają pokrywające się potrzeby produktowe
Innym przypadkiem, w którym siatka danych może nie mieć sensu, jest sytuacja, w której produkty danych pokrywają się w różnych domenach biznesowych.
Niezależnie od tego, czy jest to współdzielony pulpit nawigacyjny przychodów, czy operacyjny model ML, który jest wykorzystywany przez użytkowników zewnętrznych, współdzielone produkty danych stanowią interesujący problem organizacyjny dla zdemokratyzowanej architektury.
Jak Sisterhood of the Travelling Pants bez przyciągania tłumu.
Ponownie, głównym założeniem siatki danych jest demokratyzacja własności. Jeśli więc nie może Pan wyznaczyć wyraźnej granicy z właścicielem produktu danych, jak zdecyduje Pan, kto otrzyma złoty bilet? (Trochę mieszając metafory).
Jeśli chodzi o nakładające się produkty danych, mają Państwo zasadniczo dwie opcje.
- Opcja 1: Proszę zaprojektować domeny danych niezależnie od domen biznesowych. Chociaż jest to absolutnie realna opcja, o ile reszta solilokwium “do siatki danych lub nie do siatki danych” działa, prawdopodobnie spowoduje to również kilka organizacyjnych bólów głowy – przynajmniej na etapach wdrażania programu.
- Opcja 2: Proszę nadal zarządzać tymi produktami danych z poziomu centralnego zespołu ds. danych. Można to osiągnąć, utrzymując w pełni scentralizowaną architekturę lub po prostu zarządzając tymi indywidualnymi produktami danych w ramach centralnego zespołu ds. danych – chociaż to drugie rozwiązanie nadal może powodować pewne organizacyjne bóle głowy w tym procesie.
Dodatkowo, Sanne Group wyznaczyła opiekunów danych do zarządzania współdzielonymi zasobami danych. Chociaż idea stewarda danych nieco wyszła z mody na przestrzeni lat, jest to świetny przykład rozszerzenia siatki danych dla danego przypadku użycia.
Ale ponownie, jeśli nie są Państwo pewni, jak odpowiedzieć na to pytanie, proszę rozważyć utrzymanie na razie scentralizowanej architektury i powrócić do dyskusji na temat siatki danych w późniejszym terminie.
Państwa organizacja danych jest zbyt mała
Nie ma nic złego w byciu małym. W rzeczywistości bycie małą organizacją często oznacza większą zwinność, większą kontrolę i zdolność do bardziej wydajnej iteracji.
Oznacza to jednak również, że siatka danych może nie być najbardziej pragmatyczną inicjatywą w najbliższym czasie.
Zbyt szybkie przejście do decentralizacji może wydawać się świetnym pomysłem na pierwszy rzut oka. Może Pan pomyśleć: “Jeśli uruchomię siatkę danych wcześnie, będę mógł teraz wbudować odpowiedzialność w kulturę i uniknąć bałaganu związanego z późniejszym dostosowaniem się do większej organizacji!”.
Niestety, jest bardziej prawdopodobne, że okaże się, że jest to o wiele więcej kłopotów niż jest to warte.
Po pierwsze, tworzenie siatki danych jest kosztowne-nie tylko dla Państwa budżetu, ale także dla krytycznego czasu inżynieryjnego zespołu danych odpowiedzialnego za ułatwienie zmiany. Jest to wydatek, który trudno uzasadnić w obliczu bardziej pierwotnych priorytetów początkującego zespołu ds. danych – takich jak dostarczanie krytycznych produktów danych i ustanawianie standardów jakości.
Zanim zaczną Państwo myśleć o architekturze, która je umożliwi, potrzebują Państwo najpierw podstawowych funkcji i infrastruktury do zarządzania.
Siatka danych będzie wymagała miesięcy poświęconych planowaniu, określaniu zakresu, budowaniu i szkoleniom, aby ją uruchomić – i to przy założeniu, że mają Państwo wystarczający budżet, aby za nią zapłacić.
Zamiast kręcić się w kółko, aby nadążyć za szumem informacyjnym, proszę przeznaczyć swoje zasoby na dostarczanie wczesnej wartości zamiast funkcji i produktów danych, które rozwiązują nowe przypadki użycia biznesowego dla interesariuszy.
Co więcej, nierzadko zdarza się, że większe organizacje, które zdemokratyzowały własność danych, narzekają, że stały się zbyt zdecentralizowane i że ich demokratyzacja w rzeczywistości stworzyła nowe silosy, które utrudniają ujednolicenie i wykorzystanie danych w całej organizacji – jeden z kluczowych elementów, które ma zapewnić siatka danych.
Ogólnie, małe organizacje mają niewielkie potrzeby w zakresie danych. A jeśli mogą Państwo łatwo utrzymać scentralizowaną kontrolę (bez poświęcania wartości biznesowej), prawdopodobnie powinni Państwo to zrobić. Zawsze łatwiej jest egzekwować standardy zarządzania i jakości w jednym zespole niż w pięciu – i przy mniejszym obciążeniu infrastruktury (i budżetu).
Jeśli są Państwo szczupłym zespołem, proszę zdecydować się na szczupłe rozwiązania. Proszę zacząć od scentralizowanej struktury własności i jechać tym pociągiem do ostatniego przystanku. I następnie proszę kupić bilet na pociąg demokratyzacji.
Mają Państwo rozdrobnioną platformę danych

Eksplozja nowych zarządzanych i open-source’owych narzędzi do obsługi danych nadal sprawia, że dostarczenie ujednoliconej platformy stanowi wyzwanie dla zespołów zajmujących się platformami. Zdjęcie dzięki uprzejmości Lakefs.io.
Proszę przypomnieć, że jednym z krytycznych aspektów siatki danych jest standaryzacja i interoperacyjność.
Głównym powodem, dla którego siatka danych umożliwia scentralizowanym zespołom danych uwolnienie kontroli nad swoimi produktami danych, jest to, że nadal kontrolują one infrastrukturę która je obsługuje. Oznacza to, że aby zespoły platformy mogły skutecznie regulować siatkę danych i umożliwiać udostępnianie danych między zespołami, każda domena musi działać na pojedynczej platformie ze znormalizowanymi narzędziami i praktykami zarządzania siatką danych.
Jeśli narzędzia Państwa platformy są rozdrobnione – zespół ds. marketingu wybiera “specjalne” narzędzie ETL, a zespół ds. finansów wybiera preferowane rozwiązanie BI – przegrali Państwo bitwę o siatkę danych jeszcze przed jej rozpoczęciem.
Tak więc priorytetem numer jeden jest zdefiniowanie “złotej ścieżki” dla sposobu, w jaki Państwa produkty danych powinny a następnie przetestowanie tego procesu w jak największym stopniu ze scentralizowanym zespołem ds. danych, zanim pomyślą Państwo o federacji własności w różnych domenach.
I proszę pamiętać: Siatka danych jest bardziej związana z procesem niż z narzędziami. Jeśli nie mają Państwo możliwości wpływania na kulturę, która będzie realizować te procesy, to zdefiniowanie odpowiednich narzędzi również nie pomoże.
Każda niezawodna architektura danych wymaga niezawodnych danych
Czasami odpowiedź na siatkę danych jest mniej “nie”, a bardziej “nie teraz”. Jeśli naprawdę zależy Państwu na wdrożeniu architektury samoobsługowej, proszę zacząć od małych kroków. Proszę zidentyfikować konkretny obszar organizacji z jasno określonymi produktami danych i kontrolowanymi potokami i spróbować najpierw włączyć tylko ten jeden zespół. Proszę sprawdzić, czy są Państwo w stanie sprawdzić każdą z kwestii na tej liście i nadal zapewniać poziom wartości, jakiego oczekują Państwo od projektu siatki danych.
Narzędzia takie jak data lineage i data observability mogą pomóc liderom danych zrozumieć wzorce konsumpcji w ich organizacjach i pomóc im przejść na bardziej zdecentralizowaną strukturę.
Może się zdarzyć, że zdadzą sobie Państwo sprawę, że scentralizowane podejście jest jednak najlepszym rozwiązaniem dla Państwa zespołu i podwoją Państwo swoje wysiłki w zakresie umów SLA lub lepszych produktów związanych z danymi, zamiast włączać model samoobsługowy.
Jednak najlepszą rzeczą, jaką mogą Państwo zrobić dla swojej architektury danych – niezależnie od tego, czy zdecydują się Państwo na demokratyzację czy centralizację – jest wsparcie swoich produktów danych wysokiej jakości i niezawodnymi danymi.