
Strumieniowe przesyłanie danych to jedno z najważniejszych haseł w branży technologicznej, które umożliwia tworzenie skalowalnych aplikacji czasu rzeczywistego i innowacyjnych modeli biznesowych. Czy zastanawiają się Państwo nad moimi przewidywaniami dotyczącymi TOP 5 trendów w zakresie strumieniowego przesyłania danych w 2024 roku? Dowiedz się, jaką rolę odgrywają Apache Kafka i Apache Flink. Odkryją Państwo nowe trendy technologiczne i najlepsze praktyki w zakresie architektur sterowanych zdarzeniami, w tym udostępnianie danych, kontrakty na dane, bezserwerowe przetwarzanie strumieniowe, architektury wielochmurowe i GenAI.
Niektórzy obserwatorzy mogą zauważyć, że stało się to serią z poprzednimi postami na temat 5 najważniejszych trendów w strumieniowym przesyłaniu danych w 2021 r., the top 5 na 2022 r.oraz top 5 na 2023 rok. Trendy zmieniają się w czasie, ale ogromna wartość posiadania skalowalnej infrastruktury czasu rzeczywistego jako centralnego centrum danych pozostaje. Strumieniowanie danych z Apache Kafka to podróż i ewolucja aby wprawić dane w ruch.

Najważniejsze strategiczne trendy technologiczne Gartnera w 2024 r.
Firma badawczo-konsultingowa Gartner co roku definiuje najważniejsze strategiczne trendy technologiczne. Tym razem trendy dotyczą budowania nowych platform (AI) i dostarczania wartości poprzez automatyzację, ale także ochrony inwestycji. Na wyższym poziomie chodzi o automatyzację, skalowanie i pionierstwo. Oto, co Gartner spodziewa się w 2024 r.:

To zabawne (ale nie zaskakujące): Prognozy Gartnera pokrywają się i uzupełniają pięć trendów, na których skupiam się w odniesieniu do strumieniowego przesyłania danych za pomocą Apache Kafka w perspektywie do 2024 roku. Badam, w jaki sposób strumieniowe przesyłanie danych umożliwia szybsze wprowadzanie produktów na rynek, dobrą jakość danych w niezależnych produktach danych oraz innowacje dzięki technologiom takim jak generatywna sztuczna inteligencja.
5 najważniejszych trendów w strumieniowym przesyłaniu danych w 2024 roku
Następujące tematy pojawiają się coraz częściej w rozmowach z klientami, potencjalnymi klientami i szerszą społecznością strumieniowania danych na całym świecie:
- Udostępnianie danych w celu szybszego wprowadzania innowacji dzięki niezależnym produktom danych
- Umowy dotyczące danych dla lepszego zarządzania danymi i egzekwowania polityki
- Bezserwerowe przetwarzanie strumieniowe dla łatwiejszego tworzenia skalowalnych i elastycznych aplikacji strumieniowych
- Wdrożenia w wielu chmurach w celu efektywnego kosztowo dostarczania wartości tam, gdzie znajdują się klienci
- Niezawodna generatywna sztuczna inteligencja (GenAI) z wbudowanymi dokładnymi, aktualnymi informacjami, aby uniknąć halucynacji
Poniższe sekcje opisują każdy trend bardziej szczegółowo. Trendy te są istotne dla wielu scenariuszy, niezależnie od tego, czy korzystają Państwo z otwartego oprogramowania Apache Kafka lub Apache Flink, platformy komercyjnej, czy w pełni zarządzanej usługi w chmurze, takiej jak Confluent Cloud. Każdą sekcję rozpoczynam od rzeczywistego studium przypadku. Na końcu artykułu znajdą Państwo kompletną prezentację slajdów i nagranie wideo.
Udostępnianie danych między jednostkami biznesowymi i organizacjami
Udostępnianie danych odnosi się do procesu wymiany lub zapewniania dostępu do danych między różnymi osobami, organizacjami lub systemami. Może to obejmować udostępnianie danych wewnątrz organizacji lub udostępnianie danych podmiotom zewnętrznym. Celem udostępniania danych jest udostępnienie informacji tym, którzy ich potrzebują, czy to do współpracy, analizy, podejmowania decyzji, czy do innych celów. Oczywiście dane w czasie rzeczywistym przewyższają powolne dane dla prawie wszystkich przypadków użycia udostępniania danych.
NASA: Udostępnianie danych w czasie rzeczywistym za pomocą Apache Kafka
NASA umożliwia wymianę danych w czasie rzeczywistym pomiędzy obserwatoriami kosmicznymi i naziemnymi. The Ogólna sieć współrzędnych (GCN) umożliwia powiadomienia w czasie rzeczywistym w społeczności astronomicznej. Dzięki temu systemowi, badacze NASA, prywatne firmy kosmiczne, a nawet entuzjaści astronomii mogą publikować i otrzymywać informacje o bieżącej aktywności na niebie.

Apache Kafka odgrywa istotną rolę w badaniach astronomicznych w zakresie udostępniania danych. Szczególnie tam, gdzie w grę wchodzą czarne dziury i gwiazdy neutronowe, astronomowie coraz częściej poszukują “domeny czasowej” i chcą badać wybuchowe stany przejściowe i zmienność. W odpowiedzi na te potrzeby, obserwatoria coraz częściej wykorzystują technologie strumieniowe do wysyłania alertów do astronomów i przekazywania danych użytkownikom naukowym w czasie rzeczywistym.
Wykład “General Coordinates Network: Wykorzystanie Kafki do otwartej astronomii w czasie rzeczywistym w NASA” analizuje wybory architektoniczne, wyzwania i wnioski wyciągnięte z adaptacji Kafki do otwartej nauki i otwartego udostępniania danych w NASA.
Podejście NASA do OpenID Connect / OAuth2 w Kafce ma na celu bezpieczne skalowanie Kafki od dostępu wewnątrz jednej organizacji do dostępu dla ogółu społeczeństwa.
Stream Data Exchange With Kafka Using Cluster Linking, Stream Sharing, and AsyncAPI (Strumieniowa wymiana danych z Kafką przy użyciu łączenia klastrów, współdzielenia strumieni i AsyncAPI)
Ekosystem Kafka zapewnia różne funkcje udostępniania danych w czasie rzeczywistym w dowolnej skali. Niektóre z nich są specyficzne dla danego dostawcy. Patrzę na to z perspektywy Confluent, aby mogli Państwo zobaczyć wiele innowacyjnych opcji (nawet jeśli chcą Państwo zbudować je samodzielnie przy użyciu Kafki open-source):
- Ekosystem konektorów Kafka Connect do integracji z innymi źródłami danych i zlewami po wyjęciu z pudełka.
- Serwery proxy HTTP/REST i konektory dla Kafki do korzystania z prostych i dobrze rozumianych żądań-odpowiedzi (HTTP jest niestety również anty-wzorcem dla danych strumieniowych).
- Cluster Linking do replikacji między klastrami Kafka przy użyciu natywnego protokołu Kafka (zamiast oddzielnej infrastruktury, takiej jak MirrorMaker).
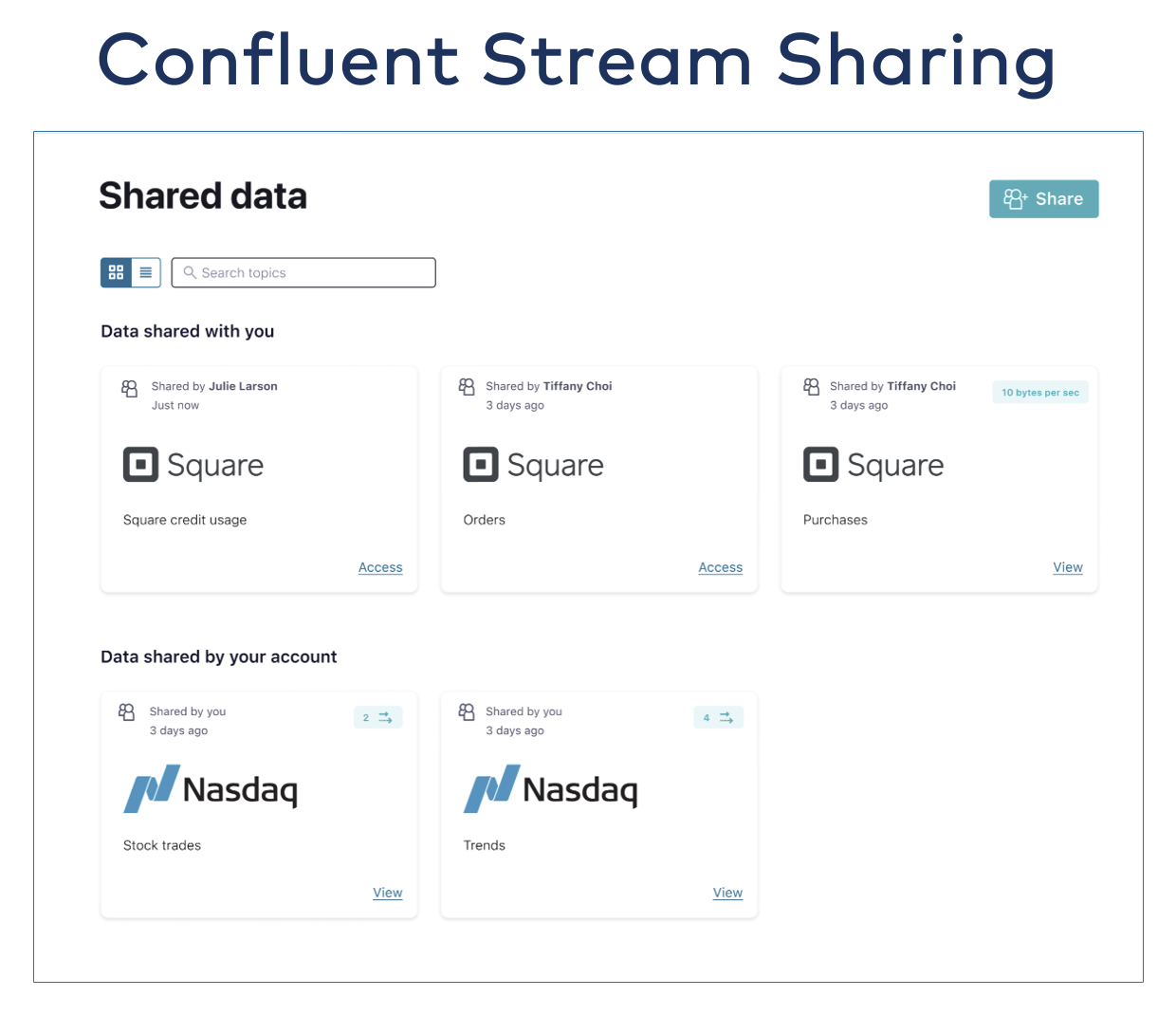
- Stream Sharing do udostępniania tematu Kafki za pomocą prostego kliknięcia przycisku z kontrolą dostępu, szyfrowaniem, kwotami i interfejsami API rozliczania opłat zwrotnych.
- Generowanie specyfikacji AsyncAPI w celu udostępniania danych aplikacjom spoza Kafki (takim jak inne brokery komunikatów lub bramy API obsługujące AsyncAPI, które są otwartymi danymi dla kontraktu na asynchroniczne przesyłanie komunikatów opartych na zdarzeniach (podobnie jak Swagger dla interfejsów API HTTP/REST).
Oto przykład Cluster Linking do dwukierunkowej replikacji między klastrami Kafka w branży motoryzacyjnej:
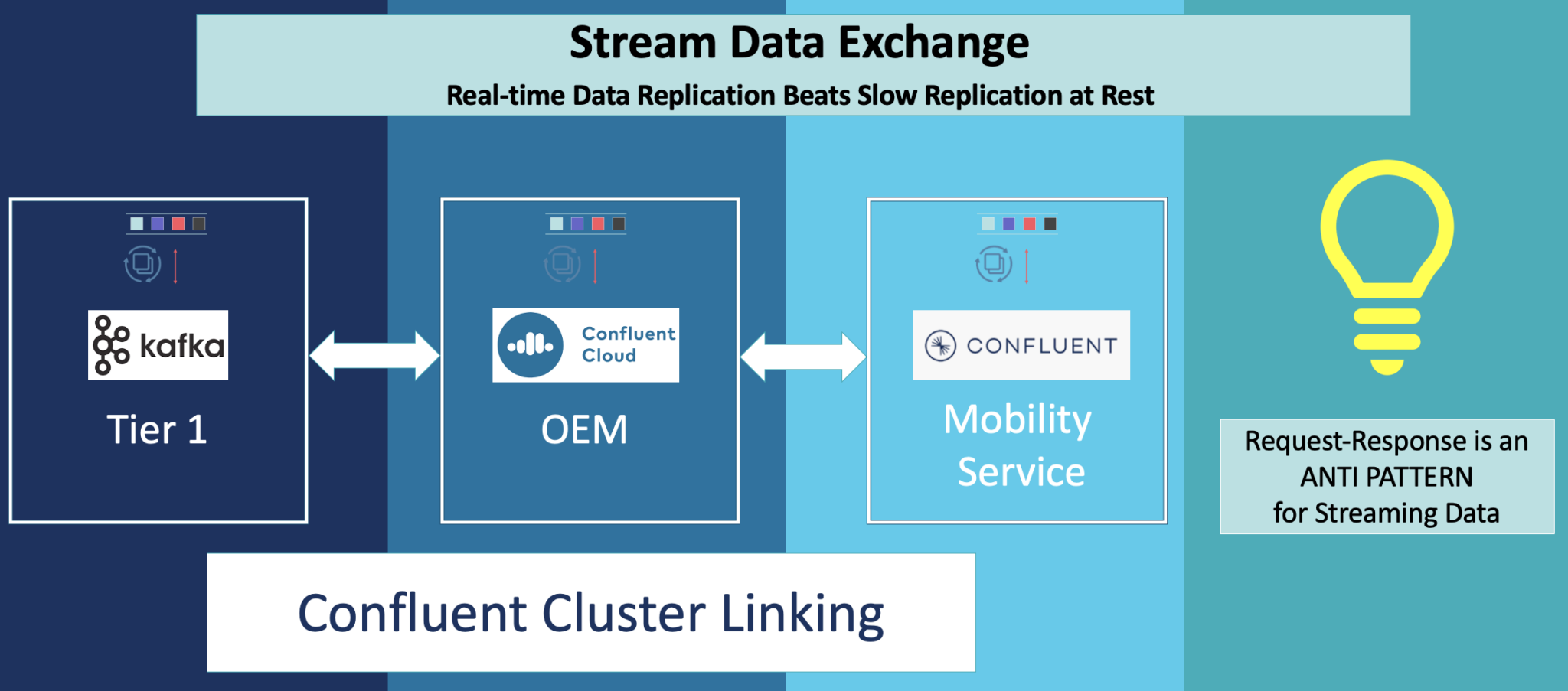
Inny przykład współdzielenia strumienia w celu łatwego dostępu do Kafka Topic w usługach finansowych:
Umowy dotyczące danych na potrzeby zarządzania danymi i egzekwowania polityk
Umowa dotycząca danych to umowa lub porozumienie, które określa zasady i warunki regulujące wymianę lub udostępnianie danych między stronami. Jest to formalne porozumienie określające, w jaki sposób dane będą obsługiwane, wykorzystywane, chronione i udostępniane między podmiotami. Umowy dotyczące danych mają kluczowe znaczenie, gdy wiele stron musi wchodzić w interakcje ze współdzielonymi danymi i wykorzystywać je, zapewniając jasność i zgodność z uzgodnionymi zasadami.
Raiffeisen Bank International: Umowy o udostępnianiu danych między krajami
Raiffeisen Bank International (RBI) skaluje architekturę opartą na zdarzeniach w całej grupie w ramach programu transformacji całego banku. Obejmuje to stworzenie architektury referencyjnej oraz ponowne wykorzystanie technologii i koncepcji w 12 krajach.
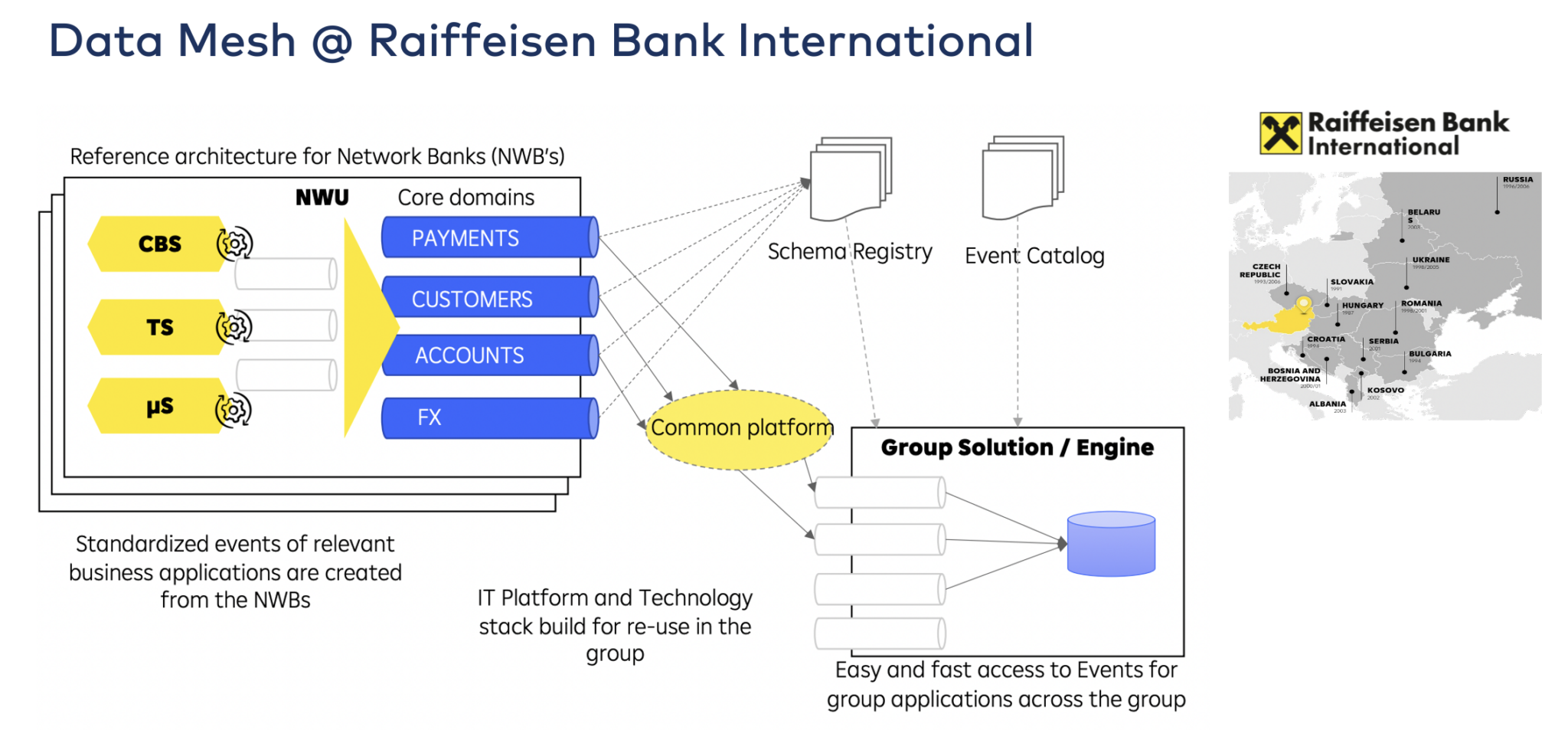
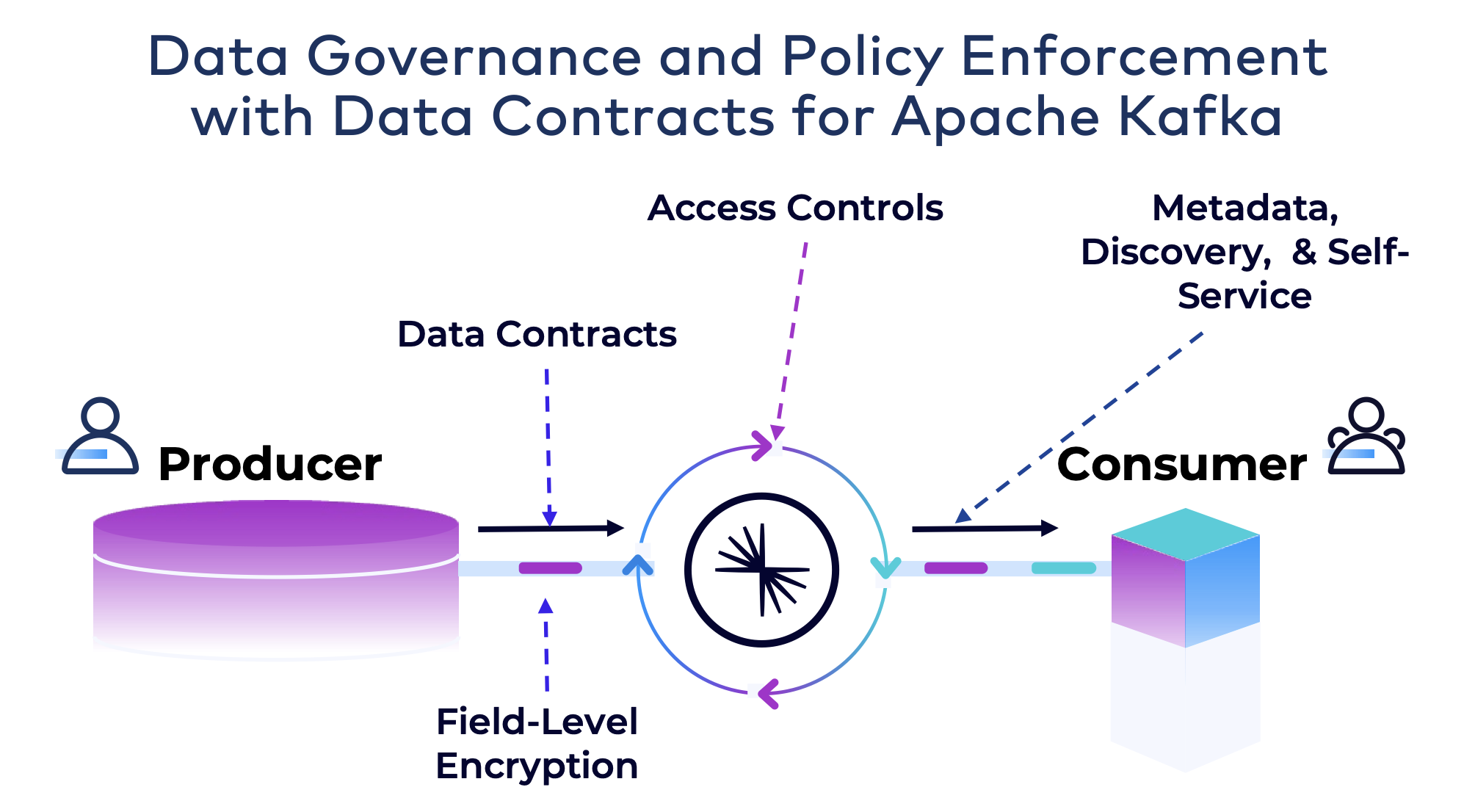
Egzekwowanie zasad i jakość danych dla Apache Kafka z rejestrem schematów
Dobra jakość danych jest jednym z najbardziej krytycznych wymagań w architekturach rozłącznych, takich jak mikrousługi lub siatki danych. Apache Kafka stał się de facto standardem dla tych architektur. Kafka jest jednak głupim brokerem, który przechowuje jedynie tablice bajtów. Schema Registry dla Apache Kafka wymusza struktury wiadomości.
Ten wpis na blogu analizuje ulepszenia Schema Registry w celu wykorzystania kontraktów danych dla polityk i reguł w celu wymuszenia dobrej jakości danych na poziomie pola i zaawansowanych przypadków użycia, takich jak kierowanie złośliwych wiadomości do kolejki martwych liter.
Bezserwerowe przetwarzanie strumieniowe z Apache Flink dla skalowalnych, elastycznych aplikacji strumieniowych
Bezserwerowe przetwarzanie strumieniowe odnosi się do architektury obliczeniowej, w której programiści mogą tworzyć i wdrażać aplikacje bez konieczności zarządzania infrastrukturą bazową.
W kontekście przetwarzania strumieniowego obejmuje ono przetwarzanie strumieni danych w czasie rzeczywistym bez konieczności jawnego udostępniania serwerów lub zarządzania nimi. Takie podejście pozwala programistom skupić się na pisaniu kodu i tworzeniu aplikacji. Usługa w chmurze zajmuje się aspektami operacyjnymi, takimi jak skalowanie, udostępnianie i utrzymywanie serwerów.
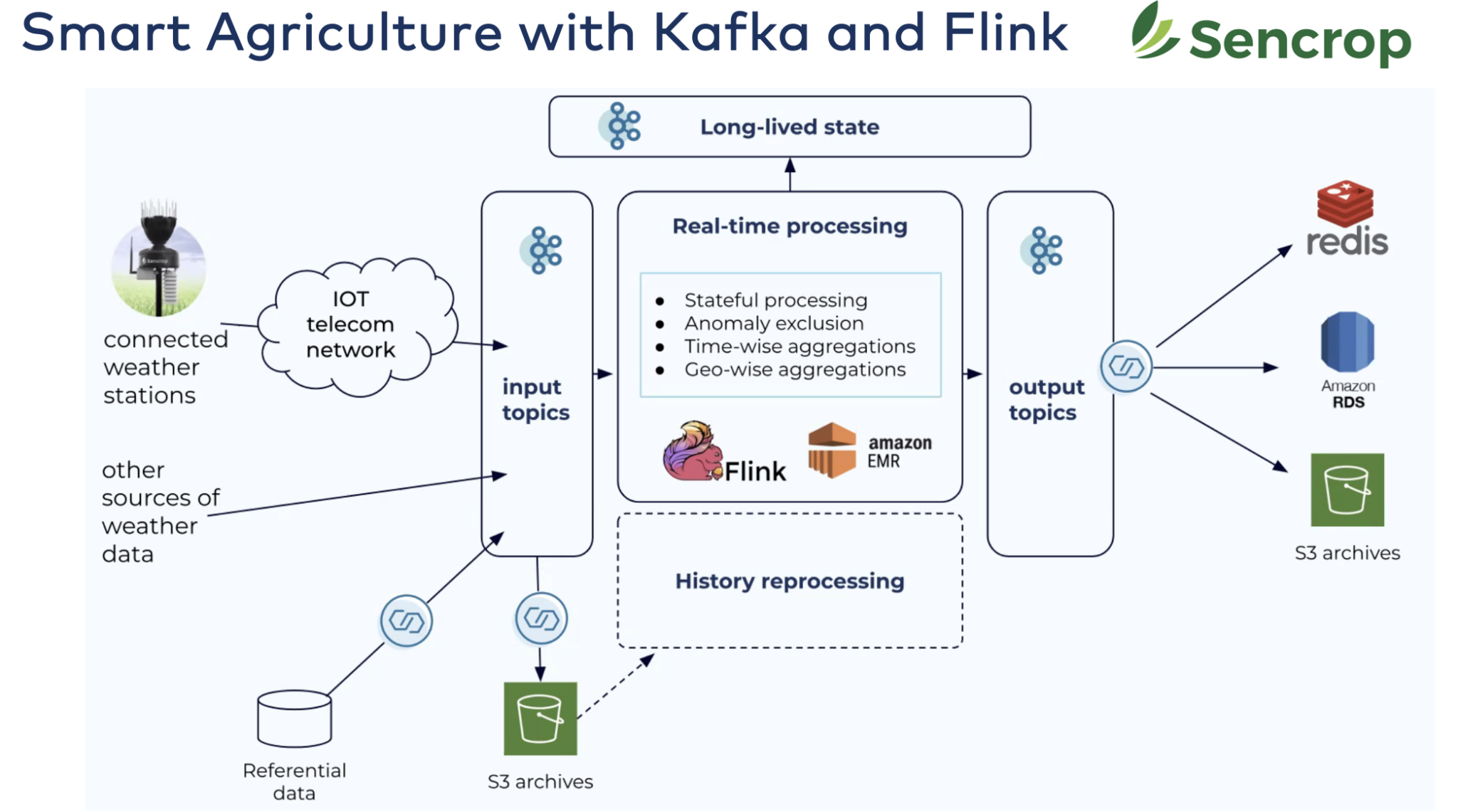
Sencrop: Inteligentne rolnictwo dzięki Apache Kafka i Apache Flink
Zaprojektowany, aby odpowiedzieć na potrzeby profesjonalnych rolników, Sencrop oferuje szereg połączonych
stacje pogodowe, które zapewnią Państwu precyzyjną pogodę w rolnictwie dane prosto z Państwa działek.
- Ponad 20 000 połączonych stacji pogodowych w całej Europie.
- Intuicyjna, przyjazna dla użytkownika aplikacja: Dostęp do dokładnych, ultra-lokalnych danych w celu optymalizacji Państwa codziennych działań.
- Zapobieganie ryzyku i redukcja kosztów: Usprawnienie wprowadzania danych i zmniejszenie wpływu na środowisko oraz związanych z tym kosztów.
Apache Flink staje się de facto standardem przetwarzania strumieniowego
Apache Kafka i Apache Flink coraz częściej łączą siły w celu tworzenia innowacyjnych aplikacji do przetwarzania strumieniowego w czasie rzeczywistym.
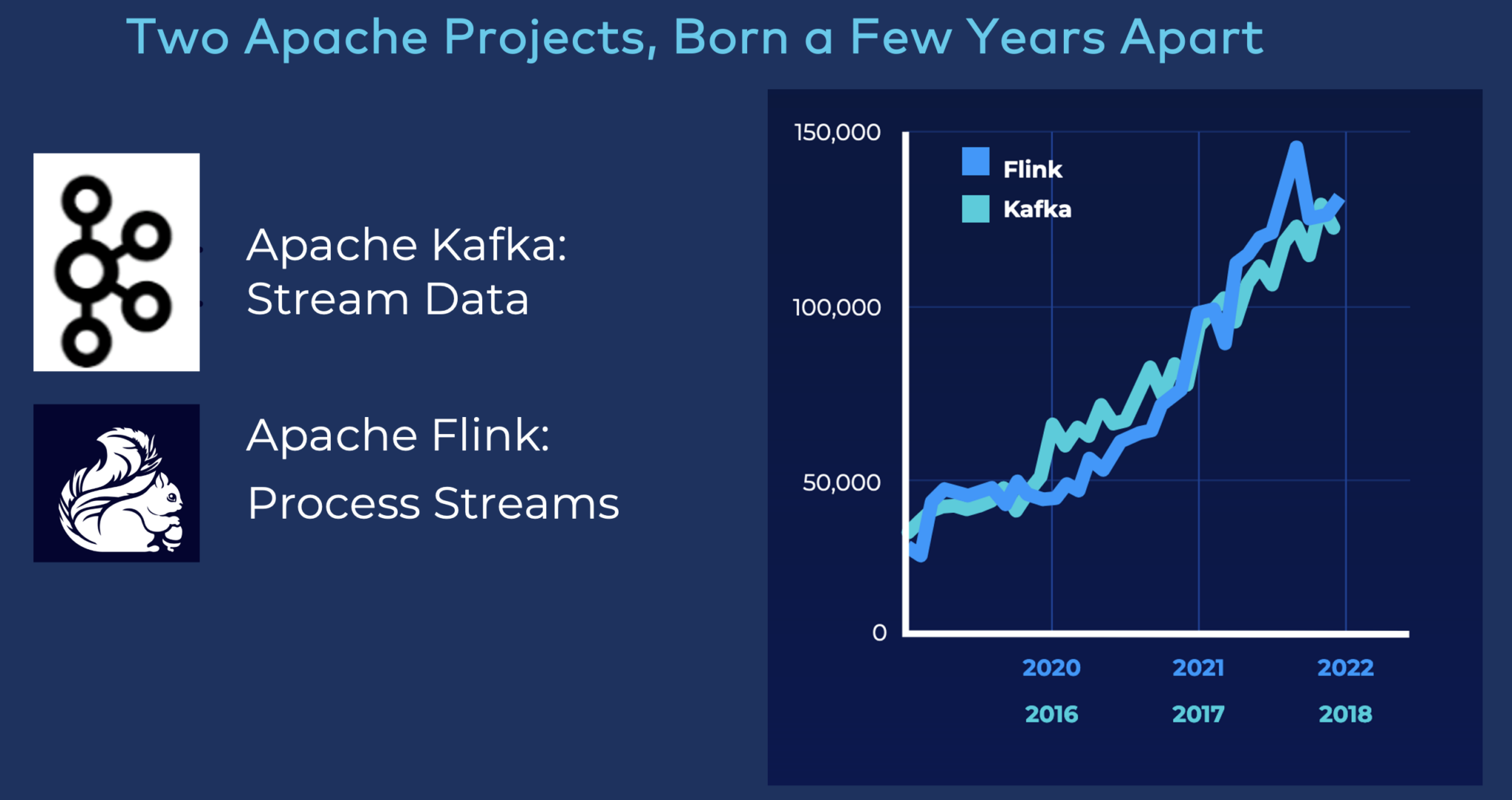
Oś Y na wykresie pokazuje miesięczną liczbę unikalnych użytkowników (na podstawie statystyk pobrań Mavena).
Niestety, obsługa klastra Flink jest naprawdę trudna. Nawet trudniejsze niż Kafka. Ponieważ Flink to nie tylko system rozproszony, musi on również utrzymywać stan aplikacji przez wiele godzin, a nawet dłużej. Dlatego też bezserwerowe przetwarzanie strumieniowe pomaga przejąć ciężar operacji. Ułatwia też życie deweloperom.
Proszę być na bieżąco z ekscytującymi produktami chmurowymi oferującymi bezserwerowe przetwarzanie Flink w 2024 roku. Proszę jednak pamiętać, że niektórzy dostawcy stosują tę samą sztuczkę, co w przypadku Kafki: Udostępnienie klastra Flink i przekazanie go Państwu NIE jest ofertą bezserwerową ani w pełni zarządzaną!
Multi-Cloud dla efektywnego kosztowo i niezawodnego doświadczenia klienta
Multi-cloud odnosi się do strategii przetwarzania w chmurze, która wykorzystuje usługi od wielu dostawców chmury w celu spełnienia określonych wymagań biznesowych lub technicznych. W środowisku wielochmurowym organizacje dystrybuują swoje obciążenia na dwie lub więcej platform chmurowych, w tym chmury publiczne, chmury prywatne lub kombinację obu.
Celem strategii multi-cloud jest uniknięcie zależności od jednego dostawcy chmury i wykorzystanie mocnych stron różnych dostawców dla różnych potrzeb. Efektywność kosztowa i przepisy regionalne (takie jak działanie w Stanach Zjednoczonych lub Chinach) wymagały różnych strategii wdrażania. Niektóre kraje nie oferują chmury publicznej. Wtedy jedyną opcją jest chmura prywatna.
New Relic: Wdrożenia Kafka w wielu chmurach w ekstremalnej skali dla obserwowalności w czasie rzeczywistym
New Relic to firma zajmująca się analizą oprogramowania, która dostarcza rozwiązania do monitorowania i zarządzania wydajnością aplikacji i infrastruktury. Zostały one zaprojektowane, aby pomóc organizacjom uzyskać wgląd w wydajność ich oprogramowania i systemów, umożliwiając im optymalizację i skuteczne rozwiązywanie problemów.
Obserwowalność ma dwa kluczowe wymagania: po pierwsze, monitorowanie danych w czasie rzeczywistym w dowolnej skali. Po drugie, należy wdrożyć rozwiązanie monitorujące tam, gdzie działają aplikacje. Oczywistą konsekwencją dla New Relic jest przetwarzanie danych za pomocą Apache Kafka i multi-cloud tam, gdzie są klienci.

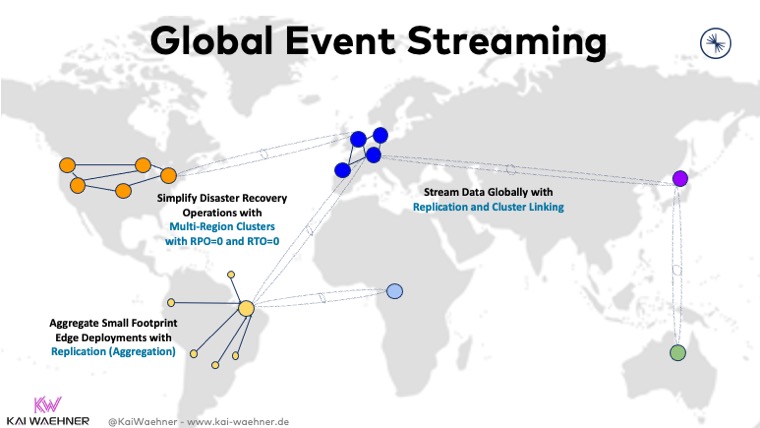
Hybrydowa i wielochmurowa replikacja danych zapewniająca efektywność kosztową, niskie opóźnienia lub odzyskiwanie danych po awarii
Wdrożenia Apache Kafka w wielu chmurach stały się raczej normą niż wyjątkiem. Kilka scenariuszy wymaga rozwiązań wieloklastrowych o określonych wymaganiach i kompromisach:
- Separacja regionalna ze względu na wymogi prawne
- Niezależność pojedynczego dostawcy usług w chmurze
- Odzyskiwanie danych po awarii
- Agregacja na potrzeby analityki
- Migracja do chmury
- Rozciągnięte wdrożenia o znaczeniu krytycznym
Niezawodna generatywna sztuczna inteligencja (GenAI) z dokładnym kontekstem, aby uniknąć halucynacji
Generatywna sztuczna inteligencja to klasa systemów sztucznej inteligencji, które generują nowe treści, takie jak obrazy, tekst, a nawet całe zbiory danych, często poprzez uczenie się wzorców i struktur z istniejących danych. Systemy te wykorzystują techniki takie jak sieci neuronowe do tworzenia treści, które nie są jawnie zaprogramowane, ale zamiast tego są generowane w oparciu o wzorce i wiedzę zdobytą podczas szkolenia.
Elemental Cognition: Platforma GenAI oparta na Apache Kafka
Platforma sztucznej inteligencji Elemental Cognition rozwija odpowiedzialną i przejrzystą sztuczną inteligencję, która pomaga rozwiązywać problemy i dostarczać wiedzę, którą można zrozumieć i której można zaufać.
Confluent Cloud zasila platformę AI, aby umożliwić skalowalne wykorzystanie danych w czasie rzeczywistym i integracji danych. Polecam zapoznać się z ich strona internetowa aby zapoznać się z różnymi imponującymi przypadkami użycia.

Apache Kafka jako platforma danych dla Genai wykorzystująca Rag, wektorową bazę danych i wyszukiwanie semantyczne
Apache Kafka służy tysiącom przedsiębiorstw jako krytyczna i skalowalna struktura danych w czasie rzeczywistym dla infrastruktur uczenia maszynowego. Ewolucja generatywnej sztucznej inteligencji (GenAI) z dużymi modelami językowymi (LLM), takimi jak ChatGPT, zmieniła sposób myślenia o inteligentnym oprogramowaniu i automatyzacji. Związek między strumieniowaniem danych a GenAI ma ogromne możliwości.
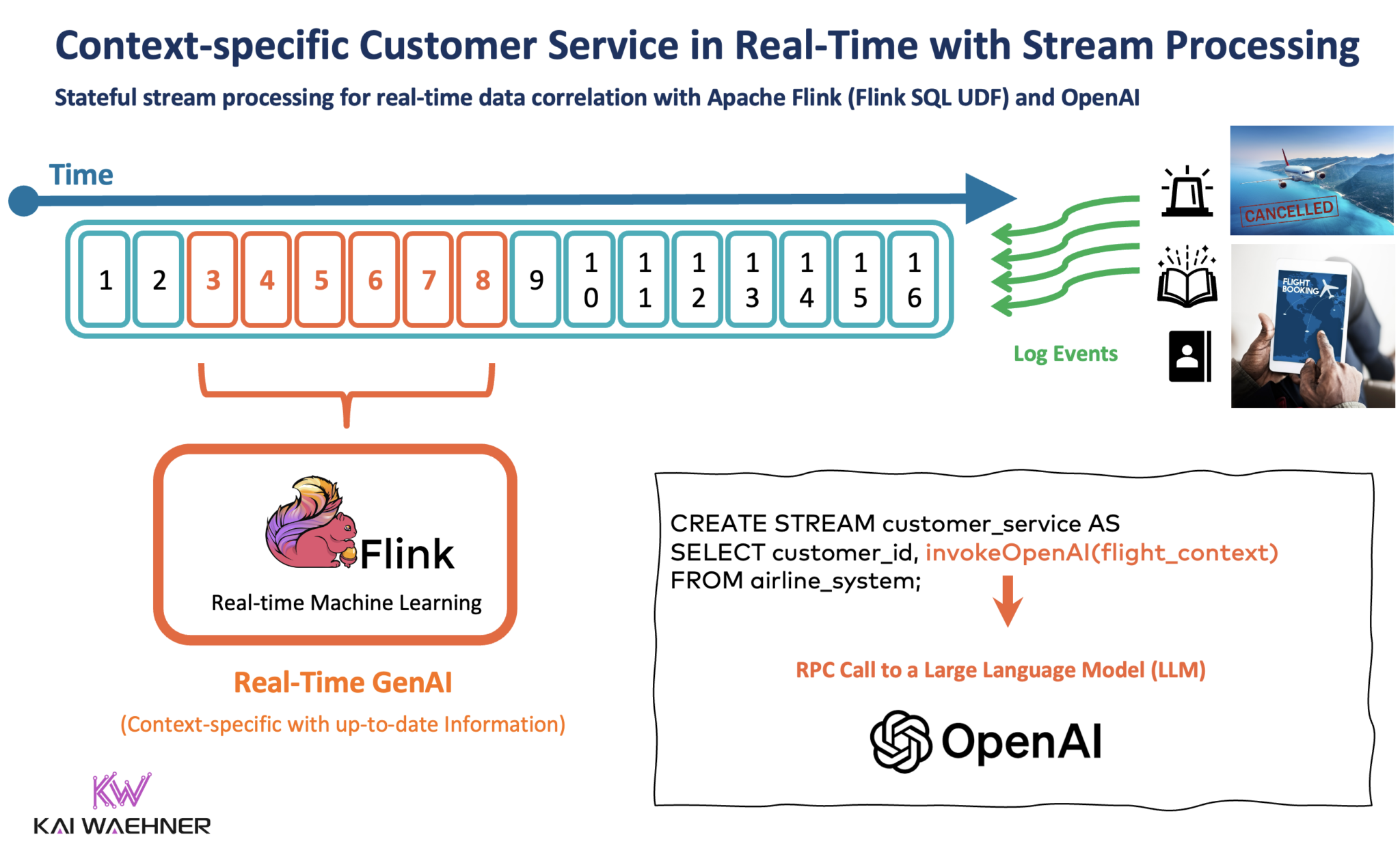
Doskonałym przykładem, szczególnie dla generatywnej sztucznej inteligencji, jest kontekstowa obsługa klienta. Poniższy diagram przedstawia architekturę korporacyjną wykorzystującą strumieniowanie danych sterowane zdarzeniami do pozyskiwania i przetwarzania danych w całym potoku GenAI:
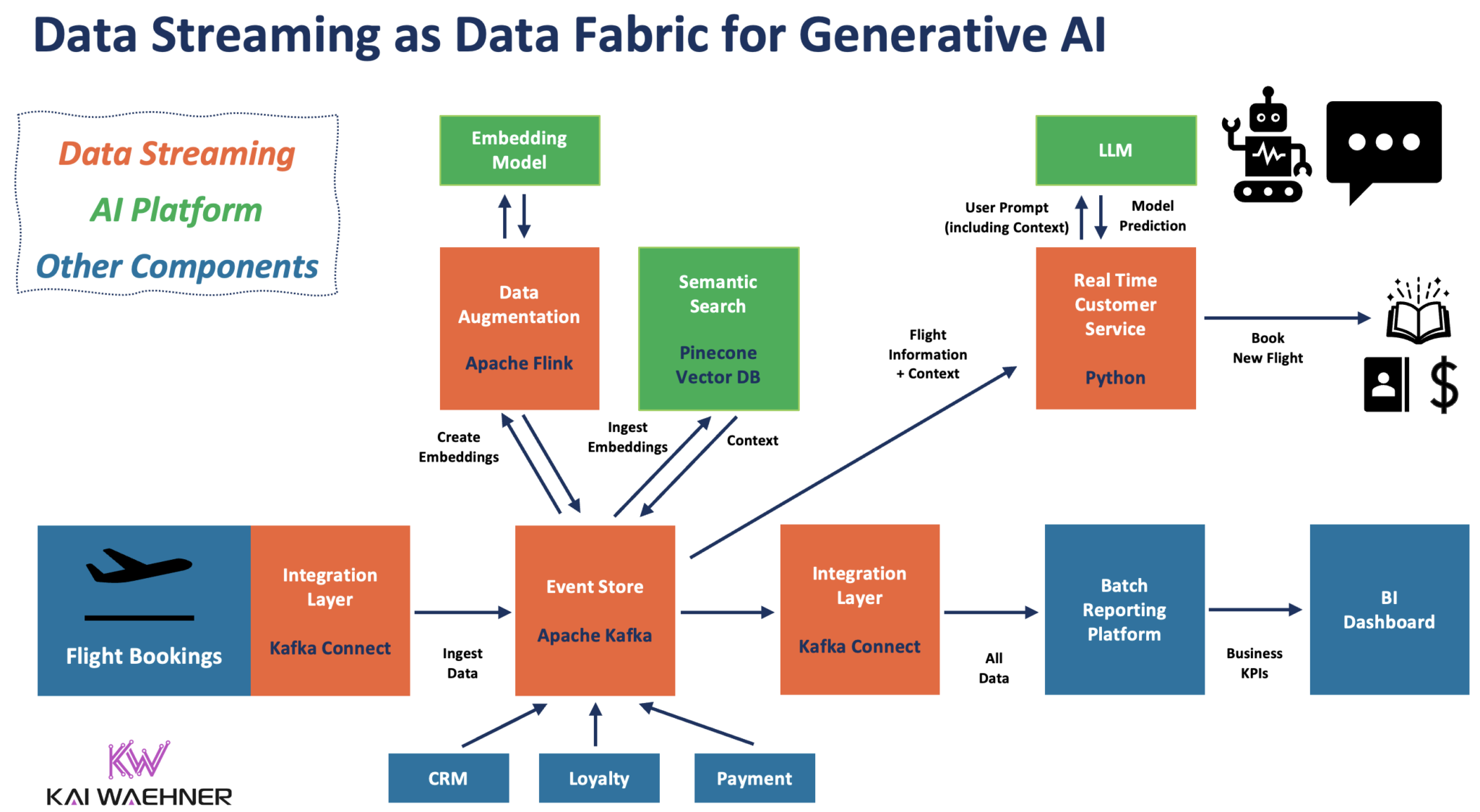
Stateful Stream Processing With Apache Flink and GenAI Using a Large Language Model (LLM)[Państwowe przetwarzanie strumieniowe z wykorzystaniem Apache Flink i GenAI przy użyciu dużego modelu językowego (LLM)]
Przetwarzanie strumieniowe za pomocą Kafki i Flink umożliwia korelację danych w czasie rzeczywistym i danych historycznych. Stanowy procesor strumieniowy pobiera istniejące informacje o kliencie z CRM, platformy lojalnościowej i innych aplikacji, koreluje je z zapytaniem od klienta do chatbota i wykonuje wywołanie RPC do LLM.
Slajdy i nagranie wideo dotyczące trendów w strumieniowym przesyłaniu danych w 2024 r. dzięki Kafka i Flink
Chcą Państwo poznać więcej szczegółów? W tej sekcji znajdą Państwo całą prezentację slajdów i nagranie wideo z omówieniem treści.
Pokład slajdów
Tutaj znajdą Państwo prezentacja slajdów z mojej prezentacji.
Nagranie wideo
A tutaj jest nagranie wideo mojej prezentacji.
Rok 2024 sprawia, że strumieniowanie danych jest bardziej dojrzałe, a Apache Flink staje się głównym nurtem
Mam dwa wnioski dotyczące trendów w strumieniowym przesyłaniu danych w 2024 roku:
- Strumieniowe przesyłanie danych idzie w górę na krzywej dojrzałości. Coraz więcej projektów tworzy aplikacje strumieniowe zamiast po prostu wykorzystywać Apache Kafka jako niemy potok danych między bazami danych, hurtowniami danych i jeziorami danych.
- Apache Flink staje się głównym nurtem. Ten open-source’owy framework wyróżnia się skalowalnym silnikiem, wieloma interfejsami API, takimi jak SQL, Java i Python, a także bezserwerową ofertą chmurową od różnych dostawców oprogramowania. To ostatnie sprawia, że tworzenie aplikacji jest znacznie bardziej dostępne.
Udostępnianie danych za pomocą umów dotyczących danych jest obowiązkowe dla udanej architektury korporacyjnej z mikrousługami lub siatką danych. Strumieniowe przesyłanie danych jest podstawą innowacji dzięki trendom technologicznym, takim jak generatywna sztuczna inteligencja. W związku z tym znajdujemy się właśnie w punkcie zwrotnym wdrażania technologii strumieniowego przesyłania danych, takich jak Apache Kafka i Apache Flink.
Jakie są Pana zdaniem najistotniejsze i najbardziej ekscytujące trendy w zakresie strumieniowego przesyłania danych z wykorzystaniem Apache Kafka i Apache Flink w 2024 r., aby wprawić dane w ruch? Jaka jest Państwa strategia i oś czasu? Czy korzystają Państwo z oferty chmury bezserwerowej lub samodzielnie zarządzanej infrastruktury? Proszę proszę połączyć się na LinkedIn i proszę dyskutować! Proszę być na bieżąco z nowymi wpisami na blogu subskrybując mój newsletter.